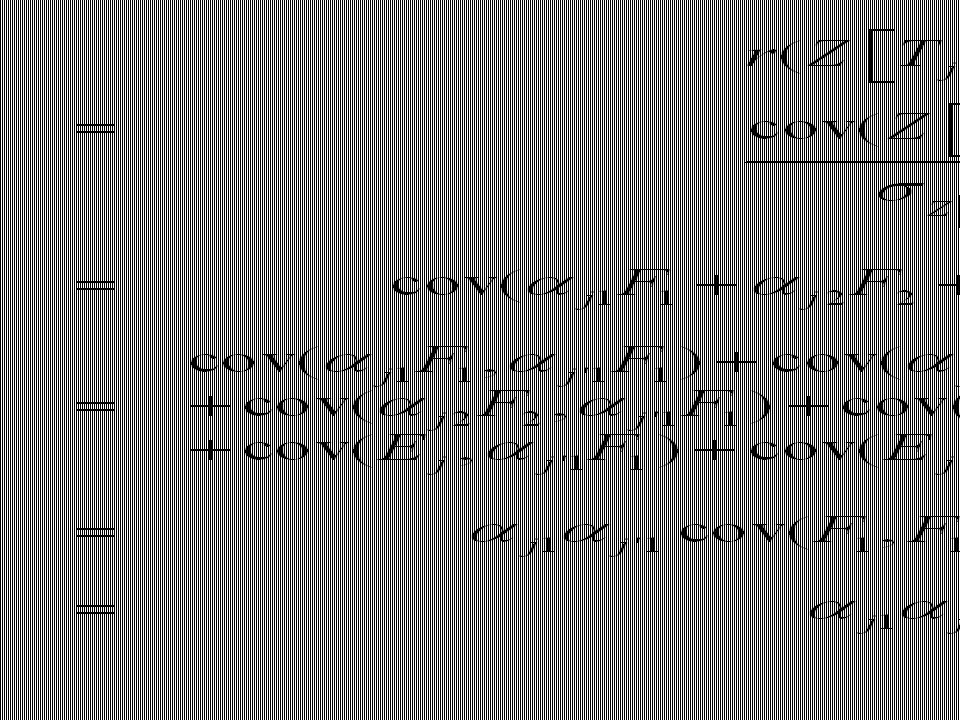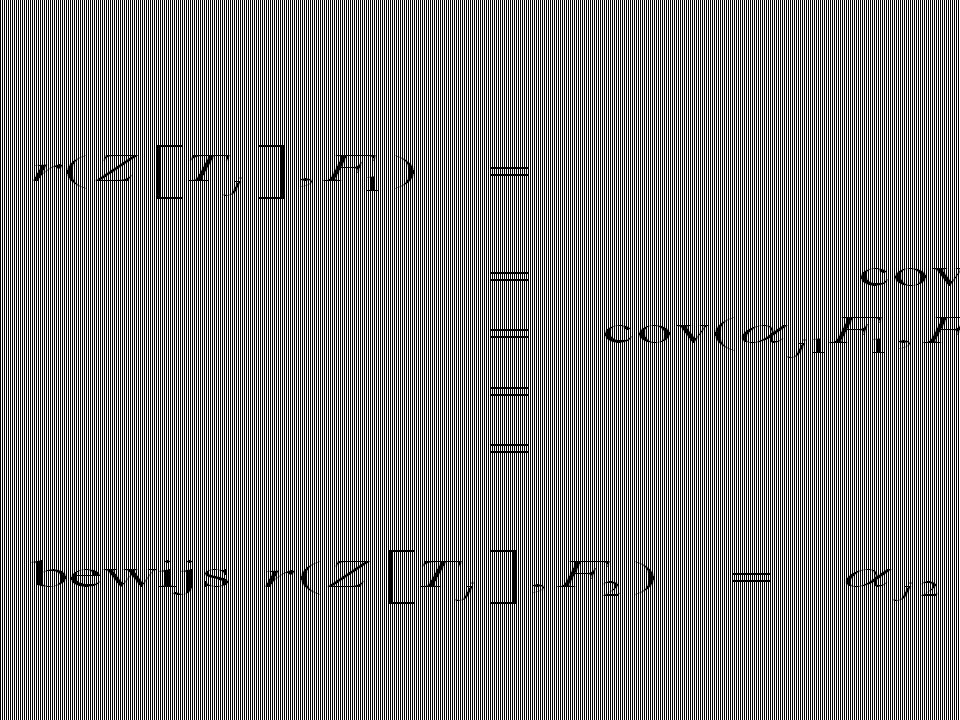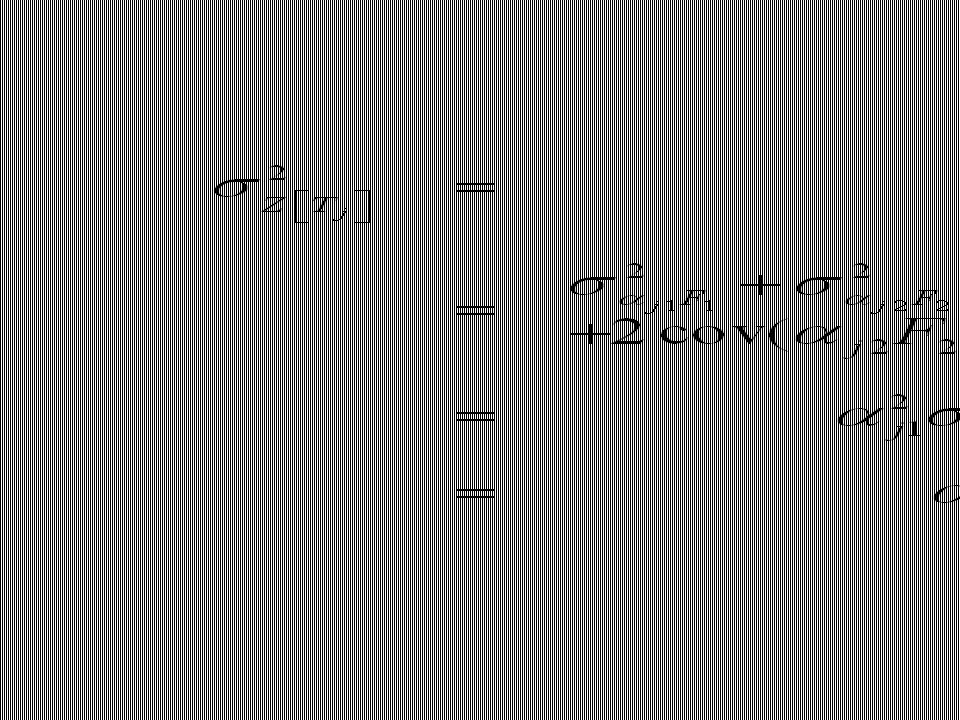Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
DEEL I: Psychologie van Individuele Verschillen: WAT & HOE?
2. Methoden in de PID

2
Vragen Hoe kunnen we verschillen tussen mensen meten?
Hoe kunnen we verbanden leggen tussen verschillen? Welke wetenschappelijke technieken gebruikt men in de PID?

3
Overzicht Verzamelen van informatie over verschillen tussen mensen
- Soorten gegevens in de PID Verbanden leggen tussen verschillen tussen mensen - soorten verbanden - de correlatie - factoranalyse Evaluatie van informatie over verschillen tussen mensen Correlationele vs. experimentele methode Factoranalyse

4
Soorten gegevens in de PID
Mensen kunnen op allerlei manieren van elkaar verschillen - lengte, haarkleur, gezondheid, persoonlijkheid, intelligentie In de PID: Verschillen op het vlak van psychologische kenmerken: Persoonlijkheid, intelligentie Probleem: niet direct of makkelijk meetbaar of observeerbaar - Illustratie: leugendetectie - relatief eenvoudig probleem - groot belang - geen oplossing Methoden nodig om informatie te verzamelen over (verschillen tussen mensen inzake) deze psychologische kenmerken
 deze psychologische kenmerken.")
5
Soorten gegevens in de PID
Methoden nodig om informatie te verzamelen over (verschillen tussen mensen inzake) deze psychologische kenmerken Noem enkele methoden die onderzoekers/leken/praktijkpsychologen gebruiken om informatie te bekomen inzake psychologische eigenschappen?
 deze psychologische kenmerken. Noem enkele methoden die onderzoekers/leken/praktijkpsychologen gebruiken om informatie te bekomen inzake psychologische eigenschappen")
6
Soorten gegevens in de PID
PID maakt gebruik van 4 soorten bronnen/soorten gegevens voor informatie over verschillen tussen mensen: S-data: Zelfrapportering O-data: observeerdersrapportering T-data: testgegevens L-data: levensgegevens

7
Soorten gegevens in de PID
S-data: Zelfrapportering persoon rapporteert direct over zichzelf vele verschillende manieren On- of semigestructureerd: - interview, open vragen - autobiografie - bv. “20 statement test”, “Mijn leven als een dier” “Ik ben …..” o.a. interessant voor meten van centrale aspecten van iemands identiteit (en gebruikt in bv crosscultureel onderzoek)
")
8
Soorten gegevens in de PID
S-data: Zelfrapportering persoon rapporteert direct over zichzelf vele verschillende manieren On- of semigestructureerd : - interview, open vragen - autobiografie - Projectieve technieken bv. Rorschach, TAT: aanbieden weinig gestructureerd, ambigu materiaal. Antwoorden vooral bepaald door eigenschappen van persoon.

9
Soorten gegevens in de PID
Voorbeeld Rorschach: Wat zie je hierin?

10
Soorten gegevens in de PID
Voorbeeld TAT: Wat is hier gebeurd?

11
Soorten gegevens in de PID
S-data: Zelfrapportering persoon rapporteert direct over zichzelf vele verschillende manieren On- of semigestructureerd : MAAR: nood aan objectieve coderingsschemas om gegevens vergelijkbaar te maken over personen zeer moeilijk te bewerkstelligen gegeven hoog subjectief karakter van beoordelingen Bovendien: betrouwbaarheid en validiteit van projectieve technieken worden dikwijls in twijfel getrokken (zie artikel Lilienfeld et al.) Nochthans: veel gebruikt
 Nochthans: veel gebruikt.")
12
Soorten gegevens in de PID
S-data: Zelfrapportering Gestructureerd: - zelfrapporteringsvragenlijst Uitspraken of adjectieven, … items worden aan persoon voorgelegd en gevraagd om aan te geven in welke mate dit henzelf beschrijft bv. “Ik ben een gewetensvol persoon” helemaal helemaal niet wel = Likert rating schaal Antwoorden op meerdere items worden opgeteld of gemiddeld (rekening houdende met de inhoud van de items)
")
13
Soorten gegevens in de PID
S-data: Zelfrapportering Gestructureerd: - zelfrapporteringsvragenlijst vb: dromerigheid 1 = past helemaal niet bij me 2 = past eigenlijk niet bij me 3 = past een beetje bij me 4 = past goed bij me Ik verlies mezelf dikwijls helemaal in mijn gedachten Ik betrap mezelf dikwijls op dagdromen Ik kan me steeds goed concentreren zonder mijn gedachten te laten afdwalen Ik ben in staat om uren voor mij uit te staren en te surfen op enkel mijn gedachten Ik ben geen dagdromer OPDRACHT: vul in en bereken je dagdroomscore adhv het gemiddelde

14
Soorten gegevens in de PID
S-data: Zelfrapportering Gestructureerd: - zelfrapporteringsvragenlijst bestaan in vele vormen - klassieke persoonlijkheidsvragenlijst - gecontextualizeerde vragenlijst: vraagt naar gedrag/gedachten/gevoelens in verschillende contexten - met herhaalde metingen: bv. Experience Sampling onderzoek, dagboekonderzoek verzameling gebeurt in dagdagelijkse leven!

15
Soorten gegevens in de PID
S-data: Zelfrapportering VOORDELEN: - persoon is enige met directe kennis over eigen interne wereld cfr. Pronin: wijzelf kennen enkel onze eigen interne wereld en de externe wereld van anderen: fundamenteel onevenwicht - makkelijk en snel een veelheid aan informatie NADELEN: - afhankelijk van motivatie & capaciteit van persoon - bv. alexithymie - gevoelig voor (opzettelijke en onopzettelijke) vervormingen: BIAS - sociale wenselijkheid, zelfrepresentatie - geheugenbiassen
 vervormingen: BIAS. - sociale wenselijkheid, zelfrepresentatie. - geheugenbiassen.")
16
Soorten gegevens in de PID
O-data: observeerdersrapportering Ipv aan persoon zelf, vraagt men anderen om over iemand te rapporteren aan de hand van zelfde technieken als S-data Mensen maken continu beoordelingen van anderen (Opm: terrein van sociale cognitie: onderzoek naar verrichten, opslaan, en verwerken van informatie over anderen): hierop beroep doen Verschillende wijzen - getrainde beoordelaars vs. gekenden bv. assessment, Facial Action Coding Ssystem (Ekman), familie of partner (zelfde?) - in naturalistische setting of in laboratorium afhankelijk van doel van onderzoek of nodige info
: hierop beroep doen. Verschillende wijzen. - getrainde beoordelaars vs. gekenden. bv. assessment, Facial Action Coding Ssystem (Ekman), familie of partner (zelfde ) - in naturalistische setting of in laboratorium. afhankelijk van doel van onderzoek of nodige info.")
17
Soorten gegevens in de PID
O-data: observeerdersrapportering VOORDELEN: - sommige biassen minder aanwezig bv. zelfrepresentatie - toegang tot andere info bv. indruk op anderen - meerdere observatoren: interbeoordelaarsbetrouwbaarheid middelen: wegwerken van idiosyncratische elementen NADELEN: - andere biassen komen weer in spel, nl. van observator, bv. trends in diagnoses, hostile attribution bias - cfr Pronin

18
Soorten gegevens in de PID
T-data: testgegevens Gegevens van gestandaardizeerde tests: personen worden in gestandaardizeerde omstandigheden geplaatst en hun reactie op bepaalde stimuli worden gemeten Bv. Taken - intelligentie-items (zie later) - experimentele manipulaties bv. Stress-test, provocatie, lampje gaat aan, emotionele films of fotos ….
 - experimentele manipulaties. bv. Stress-test, provocatie, lampje gaat aan, emotionele films of fotos. ….")
19
Soorten gegevens in de PID
T-data: testgegevens Wat wordt gemeten? Door gestandaardizeerde omstandigheden een onuitputtelijk arsenaal aan metingen: - Gedrag - observatie, reactietijden, gelaatsuitdrukkingen - Zelfrapportering (dus enigszins overlap) - antwoorden op items, open antwoorden (projectieve technieken), video mediated recall - Fysiologie - hartslag, bewegingen van gelaatsspieren (facial EMG), hersenactiviteit (bv. fMRI)
 - antwoorden op items, open antwoorden (projectieve technieken), video mediated recall. - Fysiologie. - hartslag, bewegingen van gelaatsspieren (facial EMG), hersenactiviteit (bv. fMRI)")
20
Soorten gegevens in de PID
T-data: testgegevens Voorbeeld: de IAT: ontwikkeld in de jaren 90 door Greenwald et al. Meting van attitudes etc (bv. houding tov bepaalde andere groepen, racisme) dikwijls beinvloed door sociale wenselijkheid, zelfrepresentatie, etc. Ontwikkelen van meting die deze bewuste zelfrepresentatie kan omzeilen: de IAT
 dikwijls beinvloed door sociale wenselijkheid, zelfrepresentatie, etc. Ontwikkelen van meting die deze bewuste zelfrepresentatie kan omzeilen: de IAT.")
21
Soorten gegevens in de PID
T-data: testgegevens IAT: Idee: de opvattingen over onszelf en andere zijn opgeslagen in associatieve netwerken: netwerken van associaties tussen verschillende concepten bv. goed, slecht, mezelf, buitenlanders, vrouwen, ouderen, etc.. Attitude = sterkte van associatie tussen twee concepten bv. buitenlanders/binnenlanders en goed/slecht Als we deze associatiesterkte kunnen meten op een manier die directe zelfrapportering omzeilt: impliciete associatie tussen concepten

22
Soorten gegevens in de PID
T-data: testgegevens IAT: bv 2 concepten “zwart/blank” en “goed/slecht” S1: S die verwijzen naar zwart of blank S2: goed of slecht bv. fotos bv. pos en neg woorden 1. Categorizeer S1 als “zwart” of “blank” 2. Categorizeer S2 als “goed” of “slecht” 3. Categorizeer S1+S2 als “blank of goed” of “zwart of slecht” 4. Categorizeer S1+S2 als “blank of slecht” of “zwart of goed” als sneller “blank of goed” dan “blank of slecht”: sterkere impliciete associatie tussen blank en goed dan slecht = sterkte van impliciete associatie

23
ZWART BLANK

24
ZWART BLANK

25
GOED SLECHT oorlog

26
GOED SLECHT mooi

27
GOED of BLANK SLECHT of ZWART mooi

28
GOED of BLANK SLECHT of ZWART

29
GOED of ZWART SLECHT of BLANK

30
Soorten gegevens in de PID
IAT: Meten van associaties tussen concepten bv. zelfbeeld. racisme, attitides tov ouderen, politieke voorkeuren, vrouwen/mannen, homos/heteros, etc… Op een manier waarbij zelf-representatie omzeild wordt correleert slechts matig positief met expliciete meting Veel succes, veel gebruikt, veel onderzoek MAAR ook veel kritiek Kan gefaket worden Psychometrische kritiek Wordt beinvloed door allerlei factoren: eerder familiariteit, cult. omgeving? Predictieve validiteit? Wordt in vraag getrokken (cfr meta-analyse Oswald et al., 2013, JPSP Meer info of eens zelf proberen:

31
Soorten gegevens in de PID
VOORDELEN: - direct vergelijkbaar: verstorende factoren worden zoveel mogelijk uitgesloten - laboratoriumsituatie geeft mogelijkheid tot vele mogelijke (objectievere) metingen - laboratoriumsituatie geeft de mogelijkheid om causale factoren te manipuleren NADELEN: - ecologische validiteit: - is situatie levensecht genoeg? - is gesteld gedrag representatief voor alledaags gedrag ? (cfr. Social baseline theory) - in realiteit allerlei interacties met “storende variabelen”
 metingen. - laboratoriumsituatie geeft de mogelijkheid om causale factoren te manipuleren. NADELEN: - ecologische validiteit: - is situatie levensecht genoeg - is gesteld gedrag representatief voor alledaags gedrag (cfr. Social baseline theory) - in realiteit allerlei interacties met storende variabelen")
32
Soorten gegevens in de PID
L-data: levensgegevens gegevens over het leven van individuen obv hun activiteiten Bv. opleiding, werk, burgerlijke stand, ouderschap, ongevallen, supermarktaankopen, internetgebruik (zeer hot deze dagen) Dikwijls worden andere data gebruikt om deze te voorspellen Bv. welke persoonlijkheids- of intelligentie kenmerken hangen samen met welke beroepen, muziekkeuzes, huisinrichting? VOORDELEN: - objectieve, levensechte gegevens NADEEL: - soms moeilijk beschikbaar (komt met internet verandering in)
 Dikwijls worden andere data gebruikt om deze te voorspellen. Bv. welke persoonlijkheids- of intelligentie kenmerken hangen samen met welke beroepen, muziekkeuzes, huisinrichting VOORDELEN: - objectieve, levensechte gegevens. NADEEL: - soms moeilijk beschikbaar (komt met internet verandering in)")
33
Soorten gegevens in de PID
Deze soorten gegevens leveren verschillende soorten informatie op over deze personen en de verschillen tussen de personen = variabelen: een kenmerk dat verschillende waarden kan aannemen In PID: Variabelen beschrijven doorgaans verschillen tussen de mensen

34
Soorten gegevens in de PID
Variabelen (die verschillen aangeven) kunnen van verschillende aard zijn: 1. kwantitatief: waarden drukken verschillen uit in gradatie bv. van meer tot minder agressief, van veel tot weinig zelfvertrouwen, van hoge tot lage intelligentie verschillen kunnen betekenisvol in cijfers uitgedrukt of geordend worden
 kunnen van verschillende aard zijn: 1. kwantitatief: waarden drukken verschillen uit in gradatie. bv. van meer tot minder agressief, van veel tot weinig zelfvertrouwen, van hoge tot lage intelligentie. verschillen kunnen betekenisvol in cijfers uitgedrukt of geordend worden.")
35
kwantitatieve variabelen
graad van agressie nagegaan via vragenlijst 1.Ik ben impulsief ja neen 2.Mijn potje kookt snel over ja neen 3.Ik speel graag gewelddadige spelletjes ja neen ja neen ja neen ja neen ja neen ja neen ja neen ja neen

36
agressie (score van 0 tot 10)
persoon agressie (score van 0 tot 10) 1 6 2 3 8 4 7 5 Per persoon een score: Verschillen tussen scores drukken kwantitatieve verschillen tussen mensen uit Gemiddelde, SD, geven informatie over de verdeling van deze verschillen
 Per persoon een score: Verschillen tussen scores drukken kwantitatieve verschillen tussen mensen uit. Gemiddelde, SD, geven informatie over de verdeling van deze verschillen.")
37
Soorten gegevens in de PID
Kwantitatieve verschillen tussen mensen nemen dikwijls de vorm aan van een NORMAALDISTRIBUTIE (zie ook later) Reflecteert dat meeste mensen een waarde rond het gemiddelde hebben, en dat er steeds minder mensen zijn met een waarde meer extreem verwijderd van het gemiddelde bv. lichaamslengte Maar ook vele psychologische kenmerken: extraversie, IQ, … Wordt dikwijls grafisch voorgesteld :
 Reflecteert dat meeste mensen een waarde rond het gemiddelde hebben, en dat er steeds minder mensen zijn met een waarde meer extreem verwijderd van het gemiddelde. bv. lichaamslengte. Maar ook vele psychologische kenmerken: extraversie, IQ, … Wordt dikwijls grafisch voorgesteld :")
38
Normaalverdeling

39
Normaalverdeling Enkele kenmerken:
50% van de mensen scoren boven/onder het gemiddelde ong. 68% heeft een score tussen -1/+1 SD van het gemiddelde ong. 95% heeft een score tussen -2/+2 SD van het gemiddelde slechts 2,3% heeft score 2SD boven gemiddelde, etc. Dus voor vele psychologische kenmerken lijkt het zo te zijn dat Meeste mensen hebben waarde dichtbij gemiddelde Minderheid heeft extremere scores (Opm: niet noodzakelijk het geval, bv. aantal kinderen, frequentie van ervaren verschillende intensiteiten negatieve emoties: scheef verdeeld)
")
40
Soorten gegevens in de PID
- kwalitatief: waarden drukken verschillende soorten of groepen uit bv. mannen vs. vrouwen, verschillen kunnen niet betekenisvol in cijfers uitgedrukt of geordend worden

41
kwalitatieve variabelen
1 iemand geslagen 2 niet 3 iemand geslagen 4 niet 5 niet 6 niet .. … .. … 800 niet frequentietabel 760 niet 40 iemand geslagen jongeren

42
Verbanden tussen verschillen
Andere doel van PID: beschrijven van verbanden tussen verschillen Dikwijls tussen verschillende soorten gegevens bv. hoe voorspelt intelligentie (T) levensoutcomes (L), hoe verhouden reacties op laboratoriumtaken (T) zich tot persoonlijkheidsvragenlijsten (S), vragen rond triangulatie: zelfde fenomeen terugvinden in andere soorten gegevens? bv agressie methoden nodig om verbanden tussen verschillen, variabelen te beschrijven
 levensoutcomes (L), hoe verhouden reacties op laboratoriumtaken (T) zich tot persoonlijkheidsvragenlijsten (S), vragen rond triangulatie: zelfde fenomeen terugvinden in andere soorten gegevens bv agressie. methoden nodig om verbanden tussen verschillen, variabelen te beschrijven.")
43
Verbanden tussen verschillen
Beschrijven van verbanden tussen verschillen: verschillende combinaties mogelijk afhankelijk van het soort variabelen 1. kwalitatief-kwalitatief 2. kwalitatief-kwantitatief 3. kwantitatief-kwantitatief

44
1. kwalitatief-kwalitatief
1 iemand geslagen man 2 niet man 3 iemand geslagen man 4 niet vrouw 5 niet vrouw 6 niet man .. … … .. … … 800 niet vrouw bivariate frequentietabel man vrouw iemand geslagen 40 niet 360 400 Als 0: implicationeel verband: ALS iemand geslagen, DAN man

45
kwalitatief-kwalitatief: interindividuele verschillen
patiënt hallucinaties wanen 1 2 3 4 kwalitatief-kwalitatief: intraindividuele verschillen tijdstip hallucinaties wanen 1 2 3 4

46
DUS: kwalitatief-kwalitatief:
Overlap tussen groepen In kaart brengen adhv bivariate frequentietabel Geeft zicht op implicationele verbanden: Als…dan…

47
patiënt hallucinaties wanen 1 2 3 4 Oefening:
4 Oefening: Maak de bivariate frequentietabel Welk implicationeel verband kan je uit deze tabel afleiden?

48
2. kwalitatief-kwantitatief
persoon agressie geslacht 1 6 man 2 vrouw 3 8 4 7 5 6 2 8 7 3 4 Vergelijking van gemiddelden: mannen zijn agressiever

49
DUS: kwantitatief-kwalitatief:
verschil tussen groepen In kaart brengen adhv verschillen tussen gemiddelden Geeft zicht op groepsverschillen

50
3. kwantitatief-kwantitatief
vragenlijst wantrouwen: 1.ik krijg niet steeds wat ik verdien ja neen 2.ik word soms achteruitgesteld ja neen 3.ik word soms aangetast in mijn eer ja neen 4.mensen zijn niet altijd te vertrouwen ja neen 5.als er iets fout loopt, is dat de schuld van een ander ja neen 6.mensen lopen soms over me heen ja neen 7.arrogantie kan ik niet hebben ja neen 8.voor schut staan is het ergste ja neen 9.ik word geregeld gekwetst ja neen 10.ik wil gerespecteerd worden ja neen

51
kwantitatief-kwantitatief: Interindividuele verschillen
persoon agressie (op 10) wantrouwen (op 10) 1 3 4 2 7 8 6 5
 wantrouwen (op 10)")
52
kwantitatief-kwantitatief: Intraindividuele verschillen
Situaties gepercipieerde belediging agressie 1 3 4 2 7 8 6 5

53
De correlatie Verband tussen twee kwantitatieve variabelen wordt doorgaans uitgedrukt in een correlatie = essentiele methode in PID (Verschillen tussen mensen in psychologie worden dikwijls kwantitatief uitgedrukt) Meest gebruikte is de Pearson produkt-moment correlatiecoefficient: een goed begrip en inzicht hierin is essentieel voor de DP
 Meest gebruikte is de Pearson produkt-moment correlatiecoefficient: een goed begrip en inzicht hierin is essentieel voor de DP.")
54
De correlatie Meest gebruikte is de Pearson produkt-moment correlatiecoefficient: Koppelt afwijkingen in 1 variabele van diens gemiddelde aan afwijkingen in andere variabele van diens gemiddelde (gedeeld door SD’s hetgeen waarde brengt tussen -1 en 1):
:")
55
De correlatie Meest gebruikte is de Pearson produkt-moment correlatiecoefficient: Als afwijkingen van gemiddelde voor beide variabelen gelijklopen: hoge positieve waarde (r = .98) X Y 1 21 2 32 3 39 4 45 5 61 >> << < > ≈ ≈ < > << >>
 X. Y >> << < > ≈ ≈ < > << >>")
56
De correlatie Meest gebruikte is de Pearson produkt-moment correlatiecoefficient: Als afwijkingen van gemiddelde voor beide variabelen tegengesteld verlopen: hoge negatieve waarde (r = -.98) X Y 1 61 2 45 3 39 4 32 5 21 >> >> > > ≈ ≈ < < << <<
 X. Y >> >> > > ≈ ≈ < < << <<")
57
De correlatie Meest gebruikte is de Pearson produkt-moment correlatiecoefficient: Als afwijkingen van gemiddelde niet samenhangen: rond 0 (r = .04) X Y 1 32 2 61 3 21 4 39 5 45 >> < >> > ≈ << < ≈ << >

58
De correlatie Drukt verband uit tussen verschillen op het vlak van 1 variabele met verschillen op het vlak van een tweede variabele als een grootheid -1 r 1 1. RICHTING van verband als correlatie r > 0 : positieve samenhang : verschillen in de ene variabele hangen positief samen met verschillen in de andere variabele OF: Hoge score op de ene variabele hangt samen met hoge score op de andere variabele, en omgekeerd bv. r(schoenmaat,lengte), r(intelligentie, schoolse prestaties)
, r(intelligentie, schoolse prestaties)")
59
De correlatie hoger hoger lager lager r=0.86 wantrouwen agressie 3 4 7
5 2 1 hoger hoger lager lager r=0.86

60
De correlatie Drukt verband uit tussen verschillen op het vlak van 1 variabele met verschillen op het vlak van een tweede variabele als een grootheid -1 r 1 1. RICHTING van verband als correlatie r < 0 : negatieve samenhang : verschillen in de ene variabele hangen omgekeerd samen met verschillen in de andere variabele OF: Hoge score op de ene variabele hangt samen met lage score op de andere variabele, en omgekeerd, bv. r(neuroticisme, geluk)
")
61
De correlatie hoger lager lager hoger r=-0.91 neuroticisme geluk 3 8 7
2 5 6 hoger lager lager hoger r=-0.91

62
De correlatie correlatie is dus afhankelijk van/drukt uit:
Hoe verschillen op 1 variabele samenhangen met verschillen op andere variabele Als verschillen veranderen, dan ook de r Als verschillen tussen mensen veranderen, dan ook de correlatie? enkel als dit de SAMENHANG tussen verschillen beinvloedt twee belangrijke uitzonderingen

63
De correlatie correlatie is NIET afhankelijk van
wantrouwen agressie 13 14 17 18 16 15 12 11 correlatie is NIET afhankelijk van het gemiddelde van de variabelen Cfr. r(schoenmaat, lengte) Zie ook formule de standaarddeviatie van de variabelen cfr. r (schoenmaat, lengte) Maw: r is invariant onder lineaire transformatie r=0.86 r=0.86 wantrouwen agressie 6 8 14 16 12 10 4 2
 Zie ook formule. de standaarddeviatie van de variabelen. cfr. r (schoenmaat, lengte) Maw: r is invariant onder lineaire transformatie. r=0.86. r=0.86. wantrouwen. agressie")
64
De correlatie 2. STERKTE van verband
Interpretatie van de grootte van een correlatie: wat is een sterk en wat is een zwak verband? Vuistregels Cohen (1988) - |r| < .10 : triviaal < |r| < .30 : klein verband < |r| < .50 : medium verband < |r| : sterk verband 2. Verklaarde variantie Er kan aangetoond worden dat r2 x 100 = % verklaarde variantie DUS: r = .50 25% van variantie in ene variabele is “te verklaren” aan de hand van de variantie in de andere variabele (lopen perfect samen)
 - |r| < .10 : triviaal < |r| < .30 : klein verband < |r| < .50 : medium verband < |r| : sterk verband. 2. Verklaarde variantie. Er kan aangetoond worden dat r2 x 100 = % verklaarde variantie. DUS: r = .50 25% van variantie in ene variabele is te verklaren aan de hand van de variantie in de andere variabele (lopen perfect samen)")
65
De correlatie 2. STERKTE van verband
Interpretatie van de grootte van een correlatie: wat is een sterk en wat is een zwak verband? 2. Verklaarde variantie Er kan aangetoond worden dat r2 x 100 = % verklaarde variantie DUS: r = .50 25% van variantie in ene variabele is “te verklaren” aan de hand van de variantie in de andere variabele (lopen perfect samen) “verklaring”: statistische term, op zich verklaart het verband niets causaals
 verklaring : statistische term, op zich verklaart het verband niets causaals.")
66
Verklaarde variantie PUNTEN DIFF PSYCH AANTAL STUDIE-UREN 15 7.5 12 6
3 10 5 14 7
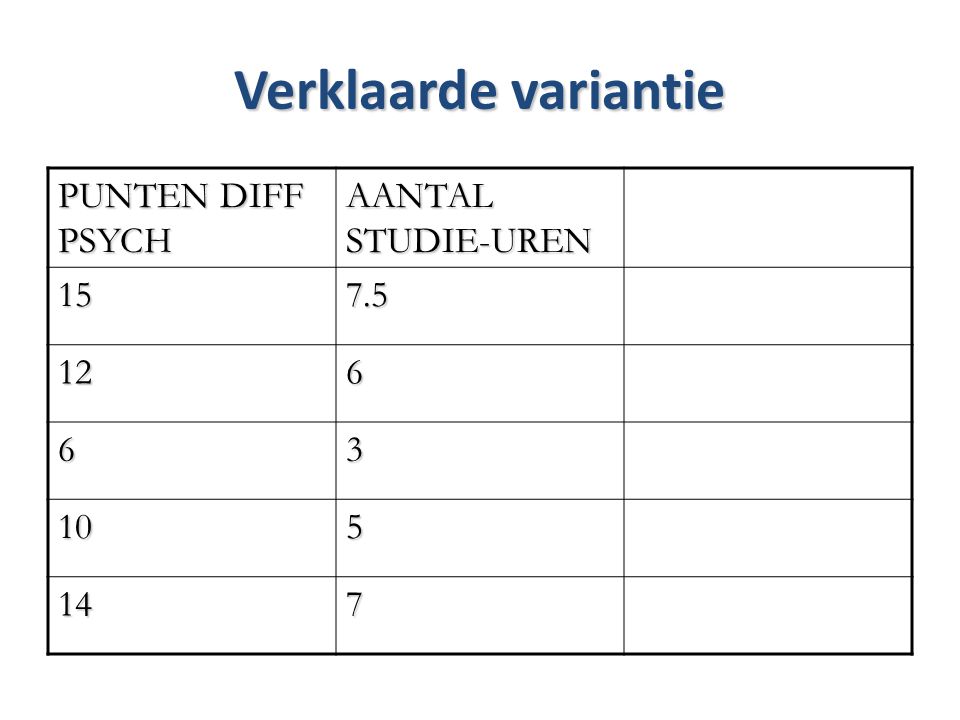
67
Verklaarde variantie PUNTEN DIFF PSYCH AANTAL STUDIE-UREN IQ 15 5 150
12 120 6 60 10 100 14 140
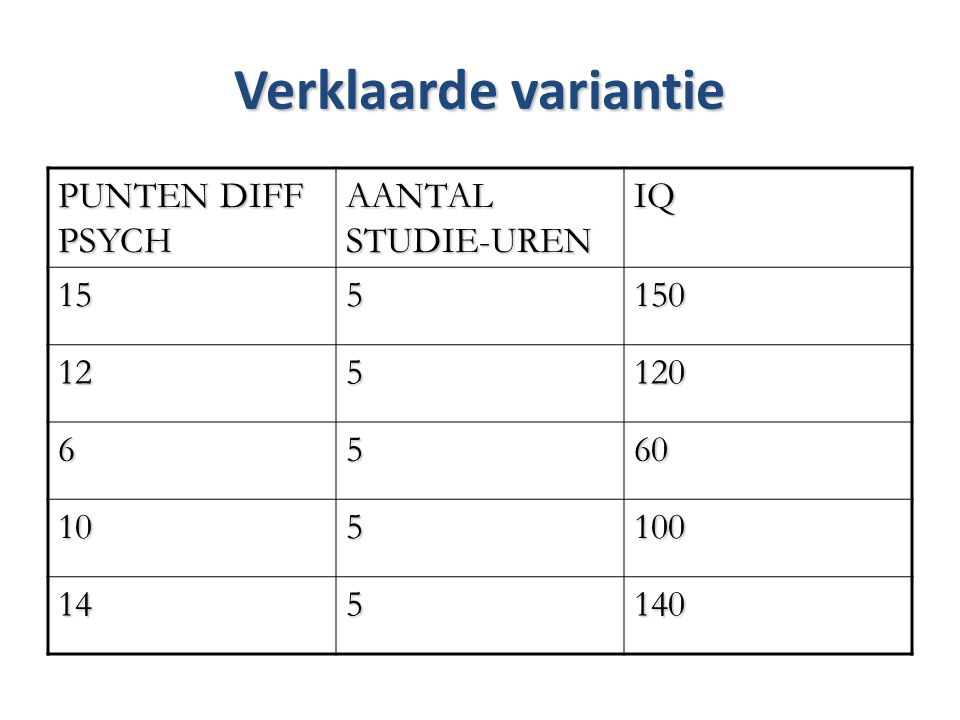
68
Verklaarde variantie PUNTEN AANTAL STUDIE-UREN IQ 15 10 120 12 7 6 3
60 100 14
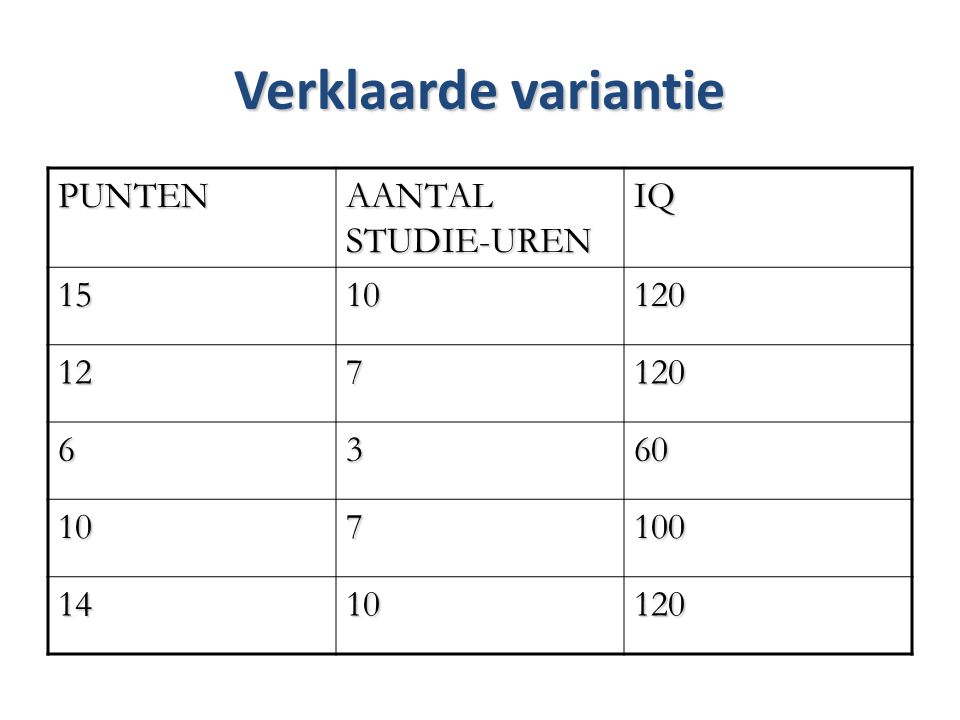
69
De correlatie 3. Soorten correlaties
CATTELL: taxonomie van soorten correlaties Gegevens: personen (doorgaans object in de psychologie) omstandigheden: tijdstippen, situaties, condities etc... variabelen: naarwaar je kijkt; gedrag, test, antwoord op vraag, etc... Gegevenskubus: In elk “hokje” zit een observatie 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 personen emily pete belogen kapot liz ongeluk situaties/tijdstippen beledigd woede frustr wantr oneerlijk variabelen
 omstandigheden: tijdstippen, situaties, condities etc... variabelen: naarwaar je kijkt; gedrag, test, antwoord op vraag, etc... Gegevenskubus: In elk hokje zit een observatie simon personen. emily. pete. belogen. kapot. liz. ongeluk. situaties/tijdstippen. beledigd. woede. frustr. wantr. oneerlijk. variabelen.")
70
De correlatie 3. Soorten correlaties
CATTELL: taxonomie van soorten correlaties Afhankelijk van welke gegevens je beschouwd kunnen er verschillende r’s berekend worden die elk verschillende soort info opleveren: Gegevenskubus: In elk “hokje” zit een observatie 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 personen emily pete belogen kapot liz ongeluk situaties/tijdstippen beledigd woede frustr wantr oneerlijk variabelen

71
De correlatie Telkens 1 schijf uit de kubus nemen:
Correlaties tussen gegevens bekomen bij 1 persoon O-correlatie: tussen twee momenten, over variabelen bv. r(belogen, kapot): mate waarin deze twee situaties gelijkaardig patroon van reacties uitlokken in persoon 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 emily pete belogen kapot liz ongeluk beledigd woede frustr wantr oneerlijk
: mate waarin deze twee situaties gelijkaardig patroon van reacties uitlokken in persoon simon emily. pete. belogen. kapot. liz. ongeluk. beledigd. woede. frustr. wantr. oneerlijk.")
72
De correlatie Telkens 1 schijf uit de kubus nemen:
Correlaties tussen gegevens bekomen bij 1 persoon P-correlatie: tussen twee variabelen, over momenten bv. r(woede, frustratie): mate waarin woede en frustratie gelijklopen doorheen verschillende situaties in persoon 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 emily pete belogen kapot liz ongeluk beledigd woede frustr wantr oneerlijk
: mate waarin woede en frustratie gelijklopen doorheen verschillende situaties in persoon simon emily. pete. belogen. kapot. liz. ongeluk. beledigd. woede. frustr. wantr. oneerlijk.")
73
De correlatie Telkens 1 schijf uit de kubus nemen:
Correlaties tussen gegevens bekomen op zelfde moment/situatie Q-correlatie: tussen twee personen, over variabelen bv. r(emily, pete): mate waarin ze gelijkaardig patroon van reacties vertonen in deze situatie 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 emily pete belogen kapot liz ongeluk beledigd woede frustr wantr oneerlijk
: mate waarin ze gelijkaardig patroon van reacties vertonen in deze situatie simon emily. pete. belogen. kapot. liz. ongeluk. beledigd. woede. frustr. wantr. oneerlijk.")
74
De correlatie Telkens 1 schijf uit de kubus nemen:
Correlaties tussen gegevens bekomen op zelfde moment/situatie R-correlatie: tussen twee variabelen, over personen bv. r(woede, frustratie): mate waarin individuele verschillen in woede samenhangen met individuele verschillen in frustratie Opm: meest typische 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 emily pete belogen kapot liz ongeluk beledigd woede frustr wantr oneerlijk
: mate waarin individuele verschillen in woede samenhangen met individuele verschillen in frustratie. Opm: meest typische simon emily. pete. belogen. kapot. liz. ongeluk. beledigd. woede. frustr. wantr. oneerlijk.")
75
De correlatie Telkens 1 schijf uit de kubus nemen:
Correlaties tussen gegevens bekomen voor 1 variabele S-correlatie: tussen twee personen, over momenten bv. r(emily, liz): mate waarin deze twee personen gelijk patroon van frustratie vertonen over situaties 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 emily pete belogen kapot liz ongeluk beledigd woede frustr wantr oneerlijk
: mate waarin deze twee personen gelijk patroon van frustratie vertonen over situaties simon emily. pete. belogen. kapot. liz. ongeluk. beledigd. woede. frustr. wantr. oneerlijk.")
76
De correlatie Telkens 1 schijf uit de kubus nemen:
Correlaties tussen gegevens bekomen voor 1 variabele T-correlatie: tussen twee momenten, over personen bv. r(belogen, kapot): mate waarin de 2 situaties gelijkaardige individele verschillen uitlokken 5 8 9 1 3 6 4 7 2 5 3 7 6 8 2 2 8 9 3 6 7 5 4 simon 5 8 9 2 3 6 4 7 1 emily pete belogen kapot liz ongeluk beledigd woede frustr wantr oneerlijk
: mate waarin de 2 situaties gelijkaardige individele verschillen uitlokken simon emily. pete. belogen. kapot. liz. ongeluk. beledigd. woede. frustr. wantr. oneerlijk.")
77
De correlatie Soorten correlaties:
Welke zeggen iets over interindividuele verschillen?? T en R correlaties: correlatie over personen: in welke mate hangen individuele verschillen samen? Q en S correlaties: correlatie tussen personen in welke mate hangt profiel van 1 persoon samen met profiel van andere persoon?

78
De correlatie 2 belangrijke opmerkingen:
Correlatie is geen causaliteit! - samenhang kan in eender beider richtingen zijn bv. r(succes, geluk), r(kip,ei) - samenhang kan zijn als gevolg van derde variabele, of toevallig bv. r(ooievaars, geboortes), r(4:2 finger ratio, agressie) Correlatie drukt enkel lineair verband uit!
, r(kip,ei) - samenhang kan zijn als gevolg van derde variabele, of toevallig. bv. r(ooievaars, geboortes), r(4:2 finger ratio, agressie) 2. Correlatie drukt enkel lineair verband uit!")
79
De correlatie Dikwijls hebben we informatie over meerdere variabelen
bv. prestaties op een reeks taken, antwoorden op een reeks items, etc. Levert soms een groot aantal correlaties op! Hoe hier inzicht in krijgen? FACTORANALYSE! = statistische techniek die toelaat om de verbanden tussen een groter aantal variabelen inzichtelijk te maken aan de hand van een kleiner aantal variabelen, genaamd factoren = zie straks

80
Evaluatie van informatie over verschillen tussen mensen
Verschillende soorten gegevens (L, T, S, O) leveren info op over verschillen tussen mensen in verschillende omstandigheden, met verschillende metingen, etc. De correlatie laat ons toe om verbanden tussen deze verschillen te beschrijven Dit kan in eerste instantie belangrijke informatie opleveren over de waarde en betekenis van de gemeten verschillen! 1. betrouwbaarheid 2. validiteit 3. links tussen data en triangulatie
 leveren info op over verschillen tussen mensen in verschillende omstandigheden, met verschillende metingen, etc. De correlatie laat ons toe om verbanden tussen deze verschillen te beschrijven. Dit kan in eerste instantie belangrijke informatie opleveren over de waarde en betekenis van de gemeten verschillen! 1. betrouwbaarheid. 2. validiteit. 3. links tussen data en triangulatie.")
81
Evaluatie van informatie over verschillen tussen mensen
Betrouwbaarheid = de mate waarin een bepaalde maat een betrouwbare meting is “Hoe betrouwbaar is de test in het meten?”, ongeacht hoe goed het iets specifieks meet Bv. stel meten van dominantie: O-data vs. S-data vs. T-data (4:2 vingerratio) Ongeacht de mate waarin ze elk dominantie meten, kunnen we nagaan hoe betrouwbaar elke meting is Verschillende soorten: a. test-hertest betrouwbaarheid b. interne consistentie c. interbeoordelaarsbetrouwbaarheid
 Ongeacht de mate waarin ze elk dominantie meten, kunnen we nagaan hoe betrouwbaar elke meting is. Verschillende soorten: a. test-hertest betrouwbaarheid. b. interne consistentie. c. interbeoordelaarsbetrouwbaarheid.")
82
Evaluatie van informatie over verschillen tussen mensen
a. test-hertest betrouwbaarheid = r tussen afname van test op 1 moment en afname van zelfde test op ander moment, over personen Als hoog: individuele verschillen op 1 moment komen sterk overeen met individuele verschillen op ander moment: de test meet individuele verschillen op een consistente manier doorheen de tijd Als laag: individuele verschillen veranderen doorheen de tijd Opm: kan ook indicatie zijn dat mensen veranderen… (zie later) b. interne consistentie c. interbeoordelaarsbetrouwbaarheid
 b. interne consistentie. c. interbeoordelaarsbetrouwbaarheid.")
83
Evaluatie van informatie over verschillen tussen mensen
b. interne consistentie Test = verzameling van items die zelfde onderliggende eigenschap zouden moeten meten Interne consistentie: mate waarin items van zelfde test onderling correleren over personen geeft aan hoezeer individuele verschillen op verschillende items met elkaar samenhangen als items zelfde meten, zouden correlaties hoog moeten zijn Bv. items intelligentietest, extraversie: sociale dominantie EN expressie emoties

84
Evaluatie van informatie over verschillen tussen mensen
c. interbeoordelaarsbetrouwbaarheid als informatie over zelfde eigenschap/variabele bekomen is van verschillende observators: = r tussen scores van verschillende observators over personen geeft aan in welke mate individuele verschillen volgens 1 (soort) observator samenhangen met individuele verschillen volgens andere observator
 observator samenhangen met individuele verschillen volgens andere observator.")
85
Evaluatie van informatie over verschillen tussen mensen
Validiteit = de mate waarin een test meet wat het bedoelt te meten “Hoe goed meet de test wat het wil meten” = niet eenvoudig na te gaan, omdat te meten eigenschap dikwijls niet (objectief) observeerbaar is Bv. dominantie: welke reflecteert best echte niveaus van dominantie? Verschillende soorten: Gezichtsvaliditeit Predictieve validiteit Convergente validiteit Discriminante validiteit Constructvaliditeit
 observeerbaar is. Bv. dominantie: welke reflecteert best echte niveaus van dominantie Verschillende soorten: Gezichtsvaliditeit. Predictieve validiteit. Convergente validiteit. Discriminante validiteit. Constructvaliditeit.")
86
Evaluatie van informatie over verschillen tussen mensen
Gezichtsvaliditeit (face vailidity) = meet de test, op het eerste zicht, wat het bedoelt te meten? Als je de items bekijkt, lijkt de test zinvol? = belangrijke eerste evaluatie voor psycholoog Predictieve validiteit (of criteriumvaliditeit) = kan de test een extern criterium voorspellen? bv. agressievragenlijst: samenhang met agressie in dagelijkse leven?: r tussen test en uiting van agressie over personen Convergente validiteit = correleert de test met andere tests van zelfde eigenschap? bv. twee agressievragenlijsten: r tussen tests over personen
 = meet de test, op het eerste zicht, wat het bedoelt te meten Als je de items bekijkt, lijkt de test zinvol = belangrijke eerste evaluatie voor psycholoog. Predictieve validiteit (of criteriumvaliditeit) = kan de test een extern criterium voorspellen bv. agressievragenlijst: samenhang met agressie in dagelijkse leven : r tussen test en uiting van agressie over personen. Convergente validiteit. = correleert de test met andere tests van zelfde eigenschap bv. twee agressievragenlijsten: r tussen tests over personen.")
87
Evaluatie van informatie over verschillen tussen mensen
d. Discriminante validiteit = meet de test niet wat het niet zou moeten meten? zorgen dat test niet iets anders meet bv. levenstevredenheid en sociale wenselijkheid: r tussen tests over personen Construct validiteit = overkoepelend: meet de test het theoretische construct dat het bedoelt te meten onderliggende trekken zijn niet zichtbaar: is de test een goede meting van het onderliggende theoretische contruct bv. extraversie, intelligentie: niet zichtbaar. Als we een test hebben, is de test in staat tot theoretische voorspellingen? Correleert de test (niet) met andere tests? Etc.
 met andere tests Etc.")
88
Evaluatie van informatie over verschillen tussen mensen
Links tussen data en triangulatie Betrouwbaarheid en validiteit gaan dikwijls over hoe een soort gegevens , bekomen in 1 context, samenhangen met een ander soort gegevens , in een andere context bv. interbeoordelaarsbetrouwbaarheid, convergente valditeit = belangrijk om waarde van meting te onderzoeken Triangulatie: zelfde bevindingen obv informatie uit verschillende bronnen bv. verband zelfwaarde en agressie: experiment, vragenlijst, hypothetische situatie, etc… MAAR: als geen overeenkomst, wijst dit niet noodzakelijk op falen van meting, maar kan interessante informatie opleveren over theoretische constructen bv. cross-situationele consistentie in PH, personality coefficient (zie later) imperfecte correlaties tussen intelligentietests (culture-free)
 imperfecte correlaties tussen intelligentietests (culture-free)")
89
Correlationeel vs. experimenteel onderzoek
In psychologie wordt dikwijls onderscheid gemaakt tussen experimenteel en correlationeel onderzoek: Experimentele methode: Manipulatie van variabele Between subjects: ! Van random toewijzing (condities moeten volledig gelijk zijn op gemanipuleerde variabele na) Within subjects: ! Van contrabalanceren Meting van AV Causale uitspraken, maar ecologische validiteit/natuurlijke variatie? Bv. effect van lawaai op studeren Correlationele methode: samenhang tussen variabelen Meting van 1 variabele en van tweede variabele: samenhang Geen causale uitspraken mogelijk, maar ecologische validiteit/natuurlijke variatie Bv. samenhang lawaai en studeren
 Within subjects: ! Van contrabalanceren. Meting van AV. Causale uitspraken, maar ecologische validiteit/natuurlijke variatie Bv. effect van lawaai op studeren. Correlationele methode: samenhang tussen variabelen. Meting van 1 variabele en van tweede variabele: samenhang. Geen causale uitspraken mogelijk, maar ecologische validiteit/natuurlijke variatie. Bv. samenhang lawaai en studeren.")
90
Correlationeel vs. experimenteel onderzoek
In psychologie wordt dikwijls onderscheid gemaakt tussen experimenteel en correlationeel onderzoek: PID wordt soms gelijk gesteld met correlationele methode, en functieleer met experimentele methode. Hoewel er een correlatie is tussen beide (;-)), is deze opsplitsing niet volledig gerechtvaardigd: - PID maakt tevens gebruik van experimentele methode of combinatie bv. effect van lawaai tijdens studeren ifv persoonlijkheid, zie later - vragen in PID gaan echter dikwijls over natuurlijke variatie: moeilijk (of weinig ethisch) enkel met exp methoden te bestuderen bv. effecten op PH, kinderen opvoeden met bepaalde eigenschappen, in bepaalde omstandigheden, etc.
), is deze opsplitsing niet volledig gerechtvaardigd: - PID maakt tevens gebruik van experimentele methode of combinatie. bv. effect van lawaai tijdens studeren ifv persoonlijkheid, zie later. - vragen in PID gaan echter dikwijls over natuurlijke variatie: moeilijk (of weinig ethisch) enkel met exp methoden te bestuderen. bv. effecten op PH, kinderen opvoeden met bepaalde eigenschappen, in bepaalde omstandigheden, etc.")
91
Samenvatting In PID maakt men gebruik van verschillende soorten gegevens die info opleveren over verschillen tussen mensen Gegevens kunnen afkomstig zijn van persoon zelf, observator, lab, of leven Kunnen kwantitatief of kwalitatief van aard zijn en kunnen gebruikt worden om verband met andere variabelen na te gaan - als check van B of V - als test van theoretisch verband Naast gebruik van exp methode in PID

92
Extra oefening 1 patiënt hallucinaties wanen houterig
sociaal geïsoleerd 1 2 3 4 Oefening: Bereken de correlaties tussen de vier variabelen over patiënten. Welk implicationele verbanden kan je uit deze tabel afleiden? Wat kan je concluderen over de band tussen correlaties en implicaties?

93
DEEL I PID: WAT EN HOE? Factoranalyse

94
Vragen Hoe krijgen we inzicht in samenhang tussen vele variabelen?
Hoe kunnen we informatie verkrijgen over trekken of vaardigheden die mogelijks onderliggend zijn aan correlaties tussen tests? Hoe kunnen we achterhalen welke de belangrijke, fundamentele dimensies zijn waarop mensen van elkaar verschillen in een bepaald domein?

95
Overzicht Inleiding 1.1. Doelstelling 1.2. Methode 1.3. Nut
Factoranalyse met 1 factor Factoranalyse met 2 factoren Factoranalyse met meerdere factoren: Aantal factoren? Factoranalyse: opmerkingen

96
1. Inleiding PID = psychologie van verschillen tussen mensen
Centrale aanname in vele centrale theorieen van PID (zie later): Mensen verschillen op het vlak van eigenschappen die niet direct observeerbaar zijn die relatief stabiel zijn doorheen de tijd (zgn, structuureigenschappen: kenmerken stabiele structuur van menselijk informatieverwerkend apparaat, maar zie later) die onderliggend zijn aan ons gedrag, gedachten, gevoelens, en mentale capiciteiten =“trekken”, “vaardigheden” Bv. extraversie, intelligentie
: Mensen verschillen op het vlak van eigenschappen die. niet direct observeerbaar zijn. die relatief stabiel zijn doorheen de tijd (zgn, structuureigenschappen: kenmerken stabiele structuur van menselijk informatieverwerkend apparaat, maar zie later) die onderliggend zijn aan ons gedrag, gedachten, gevoelens, en mentale capiciteiten. = trekken , vaardigheden Bv. extraversie, intelligentie.")
97
1. Inleiding Bv. extraversie, intelligentie
Deze eigenschappen vormen continue DIMENSIES waarop mensen van elkaar kunnen verschillen: Emily Pete Simon Weinig Veel elke persoon neemt positie in op een dimensie positie kan verschillend zijn tussen personen positie op deze dimensie bepaalt mee de mate waarin mensen gedrag (gevoelens, gedachten, prestaties) stellen op taken, gedragingen waar de dimensie relevant voor is : bepaalt individuele verschillen!
 stellen op taken, gedragingen waar de dimensie relevant voor is : bepaalt individuele verschillen!")
98
1.1 Doelstelling “Heilige graal” van PID bestaat er deels uit te achterhalen welke deze dimensies zijn. METHODE: zoveel mogelijk informatie verzamelen van manieren waarop mensen van elkaar kunnen verschillen inzake een bepaald domein bv. intelligentie: prestaties op allerlei taken persoonlijkheid: allerlei gedragingen, PHkenmerken agressie: allerlei soorten uitingen Op basis van deze info: HOE kunnen we de onderliggende dimensies achterhalen? FACTORANALYSE! = statistische techniek die toelaat om de verbanden tussen een groter aantal variabelen inzichtelijk te maken aan de hand van een kleiner aantal onderliggende variabelen, genaamd factoren

99
1.1 Doelstelling Voorbeeld: Vertrekpunt: correlaties tussen enkelvoudige taakjes, items over personen: bv =? kwaad 124/6=? irritatie 25*12=? blij 45-154=? opgewekt Cognitieve- of persoonlijkheidstests vertonen onderling (meestal) correlaties onderliggende cognitieve vaardighe(i)d(en)/trekken die r’s verklaren? vaardigheid/trek= structuureigenschap van het organisme in S-O-R schema die niet observeerbaar is (latente dimensie) cognitieve vaardigheden/trek zijn individuele verschildimensies: voor elke persoon kan je aangeven hoeveel hij/zij van de vaardigheid/trek bezit individuele verschillen in een cognitieve vaardigheid/trek zijn (mee) de oorzaak van individuele verschillen in concrete cognitieve taken of gedrag in situaties waarin de vaardigheid/trek meespeelt hoeveel cognitieve vaardigheden/trekken zijn er en welke zijn ze?
 correlaties. onderliggende cognitieve vaardighe(i)d(en)/trekken die r’s verklaren vaardigheid/trek= structuureigenschap van het organisme in S-O-R schema die niet observeerbaar is (latente dimensie) cognitieve vaardigheden/trek zijn individuele verschildimensies: voor elke persoon kan je aangeven hoeveel hij/zij van de vaardigheid/trek bezit. individuele verschillen in een cognitieve vaardigheid/trek zijn (mee) de oorzaak van individuele verschillen in concrete cognitieve taken of gedrag in situaties waarin de vaardigheid/trek meespeelt. hoeveel cognitieve vaardigheden/trekken zijn er en welke zijn ze")
100
1.1 Doelstelling student 133+47 blij X1 opgewekt X2 tevreden X3 1 X1(pp1) X2(pp1) X3(pp1) 2 X1(pp2) X2(pp2) X3(pp2) 3 X1(pp3) X2(pp3) X3(pp3) 4 X1(pp4) X2(pp4) X3(pp4) 5 X1(pp5) X2(pp5) X3(pp5) .56 .72 .63 Verklaring correlaties: Misschien zijn correlaties gevolg van onderliggende vaardigheid die meespeelt in de drie tests?
 X2(pp1) X3(pp1) 2. X1(pp2) X2(pp2) X3(pp2) 3. X1(pp3) X2(pp3) X3(pp3) 4. X1(pp4) X2(pp4) X3(pp4) 5. X1(pp5) X2(pp5) X3(pp5) Verklaring correlaties: Misschien zijn correlaties gevolg van onderliggende vaardigheid die meespeelt in de drie tests")
101
X2(pp)=.8 vaardigh stud + rest
Student 133+47 blij X1 opgewekt X2 tevreden X3 latente dimensie Y 1 X1(pp1) X2(pp1) X3(pp1) Y(pp1) 2 X1(pp2) X2(pp2) X3(pp2) Y(pp2) 3 X1(pp3) X2(pp3) X3(pp3) Y(pp3) 4 X1(pp4) X2(pp4) X3(pp4) Y(pp4) 5 X1(pp5) X2(pp5) X3(pp5) Y(pp5) Rekenvaardigheid Geluk .56 .72 .63 Mits bepaalde bijkomende assumpties kan men aan de hand van bovenstaand model geobserveerde correlaties verklaren: bv. r(X2,X3) .8 ×.9
 X2(pp1) X3(pp1) Y(pp1) 2. X1(pp2) X2(pp2) X3(pp2) Y(pp2) 3. X1(pp3) X2(pp3) X3(pp3) Y(pp3) 4. X1(pp4) X2(pp4) X3(pp4) Y(pp4) 5. X1(pp5) X2(pp5) X3(pp5) Y(pp5) Rekenvaardigheid. Geluk Mits bepaalde bijkomende assumpties kan men aan de hand van bovenstaand model geobserveerde correlaties verklaren: bv. r(X2,X3) .8 ×.9.")
102
1.2 Methode DUS: Correlaties tussen tests, persoonlijkheidsscores, prestaties, … Hoe verklaren? Misschien zijn er enkele onderliggende dimensies die de correlaties veroorzaken? Op zoek gaan met FA

103
1.2 Methode 1.2. Methode neem zoveel mogelijk ‘cognitieve vaardigheden’/’persoonlijkheid’-tests af bereken de correlaties tussen de tests ga na hoeveel en welke niet geobserveerde cognitieve vaardigheden /persoonlijkheidstrekken er nodig zijn om de correlaties te verklaren HOE “naieve” methode: niet geobserveerde eigenschappen afleiden uit correlatiematrix aan de hand van visuele inspectie

104
1.2 Methode voorbeeld: trein intelligentie
eerste methode: bereken correlaties tussen tijden over personen Keulen Londen Overpelt Diksmuide 1 .9 .8 .85 één dimensie: vaardigheid om met de trein te reizen

105
1.2 Methode Keulen Londen Overpelt Diksmuide 1 .9 .1 twee dimensies:
vaardigheid om in het binnenland met de trein te reizen vaardigheid om naar het buitenland te reizen met de trein

106
1.2 Methode Dit is nog overzichtelijk. Maar wat als Meerdere tests
Minder eenduidig correlatiepatroon? voorbeeld: correlaties tussen standaard subtests van intelligentietest

107
intercorrelaties van 11 subtests van WAIS (berekend over 2100 personen)
OT BP PO FL Informatie 1 Begrijpen .66 Rekenen .57 .52 Overeenkomsten .67 .53 Cijferreeksen .43 .40 .48 .41 Woordenschat .75 .71 .55 .72 .44 Substitutie .45 .39 .49 Onvolledige tekeningen .50 .47 .34 Blokpatronen .42 .37 .46 Plaatjes ordenen .35 .31 .26 Figuurleggen .33 .28 .36 .21 .38

108
1.2 Methode Dit is al minder overzichtelijk!
Gebruik van FACTORANALYSE: = statistische techniek die toelaat om de verbanden tussen een groter aantal variabelen inzichtelijk te maken aan de hand van een kleiner aantal onderliggende variabelen, genaamd factoren FACTORANALYSE?

109
1.3 Nut Theoretisch: structuur van individuele verschillen in cognitieve vaardigheden/persoonlijkheid kennen (verschilsdimensies) Praktisch: als we deze fundamentele dimensies kennen: gebruiken voor optimaal voorspellen van schoolsucces of jobsucces, geluk, relatietevredenheid, etc etc

110
2. Factor-analyse met 1 factor 2.1. Model
n tests: n*(n-1)/2 correlaties tussen deze test factoranalytisch model = model om correlaties te verklaren op basis van onderliggende, latente dimensies (cognitieve vaardigheden/ persoonlijkheidstrekken) alle scores zijn uitgedrukt in Z-scores
/2 correlaties tussen deze test. factoranalytisch model = model om correlaties te verklaren op basis van onderliggende, latente dimensies (cognitieve vaardigheden/ persoonlijkheidstrekken) alle scores zijn uitgedrukt in Z-scores.")
111
2. Factor-analyse met 1 factor 2.1. Model
Model met 1 onderliggende factor: Basis uitgangspunt: Score van een persoon op een test wordt bepaald door Mate waarin persoon onderliggende algemene vaardigheid/trek bezit die meespeelt de test Mate waarin test deze vaardigheid/trek meet + 3. Specifieke vaardigheden/trek voor de test + meetfout Nu in formules! - beter, preciezer inzicht - geeft toegang tot allerlei extra informatie

112
2. Factor-analyse met 1 factor 2.1. Model
gekend geobserveerd niet gekend niet geobserveerd te schatten, hoe valt buiten cursus

113
2. Factor-analyse met 1 factor Model 2.1. Model
gemeenschappelijke factor F : gemeenschappelijk voor alle n tests Bv. in intelligentiedomein te interpreteren als cogn. vaardigheid elke persoon bezit vaardigheid in bep. mate: factorscore

114
2. Factor-analyse: model met 1 factor 2.1. Model
factorladingen: geven aan in welke mate vaardigheid F meespeelt in resp. testen -1 ≤ αj ≤ 1

115
2. Factor-analyse: model met 1 factor 2.1. Model
n specifieke variabelen, één per test: bevat specifieke vaardigheid voor test, die niet meespeelt in andere tests foutencomponent

116
2. Factor-analyse: model met 1 factor 2.1. Model
DUS: score van persoon i op test j wordt bepaald door: Mate waarin i algemene vaardigheid bezit die meespeelt in test x mate waarin deze vaardigheid meespeelt in test j + Restcomponent: specifieke vaardigheid + meetfout

117
2. Factor-analyse met 1 factor 2.1. Model
T1 = liedje K3; T2 = liedje Gaga; T3 = liedje Pavarotti zangprestatie zangtalent vermoeidheid, ziekte, specifieke vaardigheden in welke mate speelt zangtalent een rol in elk liedje?

118
2. Factor-analyse: model met 1 factor 2.2. Assumpties
factorscore op gemeenschappelijke factor specifieke vaardigheid + error geobserveerde score van pp i op test j factorlading

119
2. Factor-analyse: model met 1 factor 2.3. Implicatie 1
(1) =1 =1
 =1. =1.")
120
2. Factor-analyse: model met 1 factor 2.3. Implicatie 1
DUS: Als je factorladingen kent, kan je correlaties tussen tests herberekenen: “Bestaan van onderliggende factor verklaart correlaties tussen tests” TERZIJDE: schattingsmethode is hierop gebaseerd: zoeken naar ladingen zodat deze de correlaties tussen de tests ZO GOED MOGELIJK verklaren

121
2. Factor-analyse: model met 1 factor 2.4. Implicatie 2
(2) =1 =1
 =1. =1.")
122
2. Factor-analyse: model met 1 factor 2.5. Implicatie 3
(3) =1
 =1.")
123
2. Factor-analyse: model met 1 factor 2.5. Implicatie 3
(3) communaliteit van test (hj2) specificiteit grootte communaliteit bepaald door andere tests erg heterogene tests → lage communaliteit erg homogene tests → hoge communaliteit
 communaliteit van test (hj2) specificiteit. grootte communaliteit bepaald door andere tests. erg heterogene tests → lage communaliteit. erg homogene tests → hoge communaliteit.")
124
2. Factor-analyse: model met 1 factor 2.5. Implicatie 3
DUS: Als je factorladingen kent, kan je berekenen hoeveel van de test bepaald wordt door de factor = de mate waarin de factor de score bepaalt op de test, meespeelt in de test = “communaliteit van test”: mate waarin gemeenschappelijke factor(en) meespeelt in de test (= 2; zie r2 = verklaarde variantie)
 meespeelt in de test. (= 2; zie r2 = verklaarde variantie)")
125
2. Factor-analyse: model met 1 factor 2.6. Implicatie 4
(4) = de mate waarin de gemeenschappelijke factor een rol speelt in alle tests (proportie)
 = de mate waarin de gemeenschappelijke factor een rol speelt in alle tests (proportie)")
126
2. Factor-analyse: model met 1 factor 2.7. Interpretatie van factor
Factor = onderliggende WISKUNDIGE dimensie die scores op tests bepaalt (zie later) Betekenis? geïnduceerd vanuit gemeenschappelijke kenmerken van tests die hoog laden op F
 Betekenis geïnduceerd vanuit gemeenschappelijke kenmerken van tests die hoog laden op F.")
127
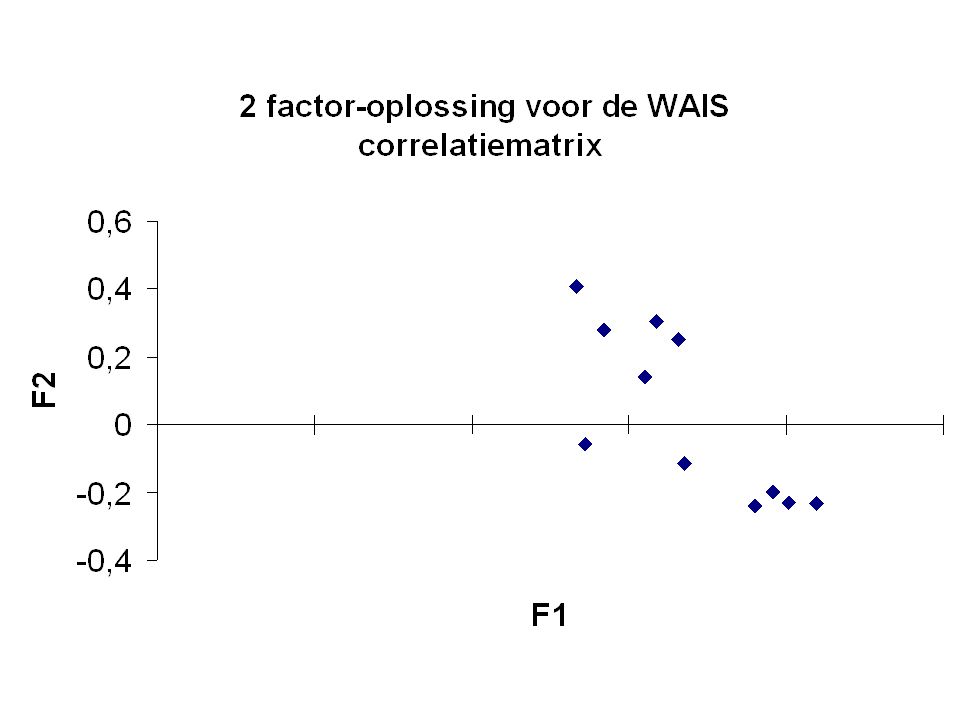
1 factor-oplossing voor WAIS correlatiematrix
subtests factorladingen Informatie .80277 Begrijpen .75961 Rekenen .66999 Overeenkomsten .78335 Cijferreeksen .54402 Woordenschat .83885 Substitutie .61990 Onvolledige tekeningen .66249 Blokpatronen .63483 Plaatjes ordenen .56793 Figuurleggen .53325

128
Oefening: Gegeven de 1 factor-oplossing voor de WAIS correlatiematrix: Bereken de communaliteit van Cijferreeksen en Blokpatronen. Mag men besluiten dat Cijferreeksen een minder betrouwbare test is dan Blokpatronen? Schat de correlaties tussen Woordenschat en Informatie, en tussen Blokpatronen en Figuurleggen. Vergelijk je uitkomst met de geobserveerde correlaties. Wat is de prop. totale variantie verklaard door F?

129
Oefening: 1. Hoe groot zijn 1, 2 en 3, als r(T1, T2)=.30, r(T2,T3)=.42 en r(T1,T3)=.35? 2. Hoe groot zijn de zes ’s als de eerste drie tests onderling .49 correleren en als de laatste drie tests onderling .64 correleren? En hoe groot zijn de correlaties tussen één van de eerste drie tests en één van de laatste drie tests?

130
3. Factor-analyse: model met 2 factoren 3.1. Model
Model met meerdere onderliggende factoren: Basis uitgangspunt: Score op een test wordt bepaald door meer dan 1 factor die meespeelt in alle tests, dus Score van een persoon op een test wordt bepaald door Mate waarin persoon onderliggende vaardigheden/trekken bezit die meespelen in alle tests Mate waarin tests meespelen in test + 2. Specifieke vaardigheden/trek voor de test + meetfout DUS: scores op intelligentie/ persoonlijkheidstests worden bepaald door meerdere factoren

131
3. Factor-analyse: model met 2 factoren 3.1. Model
Model met meerdere onderliggende factoren: Basis uitgangspunt: Score op een test wordt bepaald door meer dan 1 factor die meespeelt in alle tests, dus Voorbeelden: voetbal, handbal, volleybal, tennis, …: lichamelijke conditie, balgevoel, spelinzicht (onafhankelijke vaardigheden die min of meer rol spelen in alle sporten) Lachen, deur openhouden, met twee woorden spreken, knikken: vriendelijkheid en onderdanigheid (onafhankelijke factoren)
 Lachen, deur openhouden, met twee woorden spreken, knikken: vriendelijkheid en onderdanigheid (onafhankelijke factoren)")
132
3. Factor-analyse: model met 2 factoren 3.1. Model
gekend geobserveerd niet gekend niet geobserveerd: worden geschat

133
3. Factor-analyse: model met 2 factoren 3.1. Model
gemeenschappelijke factoren F1 en F2 voor alle n tests Bv. cognitieve factoren in intelligentiedomein elke persoon heeft een score op elke factor = factorscores = mate waarin persoon deze vaardigheden bezit

134
3. Factor-analyse: model met 2 factoren 3.1. Model
factorladingen van tests op F1 en F2 = mate waarin factor/vaardigheid meespeelt in test -1 ≤ αij ≤ 1

135
3. Factor-analyse: model met 2 factoren 3.1. Model
n specifieke variabelen, één per test: specifieke vaardigheid die niet meespeelt in andere tests foutencomponent

136
3. Factor-analyse: model met 2 factoren 3.2. Assumpties
factorscores op gemeenschappelijke factoren geobserveerde score van pp i op test j factorladingen specifieke vaardigheid + error F1 F2 1 intercorrelatiematrix van gemeenschappelijke factoren=identiteitsmatrix

137
3. Factor-analyse: model met 2 factoren 3.3. Implicatie 1
(1)
")
139
3. Factor-analyse: model met 2 factoren 3.3. Implicatie 1
DUS: Als je factorladingen kent, kan je correlaties tussen tests herberekenen: Bestaan van onderliggende factoren verklaart correlaties tussen tests Opmerking: schattingsmethode is hierop gebaseerd: zoeken naar ladingen zodat deze de correlaties tussen de tests ZO GOED MOGELIJK verklaren

140
3. Factor-analyse: model met 2 factoren 3.4. Implicatie 2
(2)
")
142
3. Factor-analyse: model met 2 factoren 3.5. Implicatie 3
(3) communaliteit (hj2) specificiteit communaliteit v. test is som van gekwadrateerde factorladingen
 communaliteit (hj2) specificiteit. communaliteit v. test is som van gekwadrateerde factorladingen.")
144
3. Factor-analyse: model met 2 factoren 3.5. Implicatie 3
DUS: Als je factorladingen kent, kan je berekenen hoeveel van de test bepaald wordt door de factoren = de mate waarin de factoren de score bepalen op de test, meespelen in de test = “communaliteit van test”: mate waarin gemeenschappelijke factoren meespelen in de test (zie r2 = verklaarde variantie)
")
145
3. Factor-analyse: model met 2 factoren 3.6. Implicatie 4
(4) =n =n
 =n. =n.")
146
3. Factor-analyse: model met 2 factoren 3.7. Interpretatie van factor
interpretatie van factoren: Factoren= onderliggende dimensies die scores op tests bepalen Betekenis? geïnduceerd vanuit gemeenschappelijke kenmerken van tests die hoog laden op de resp. factor

147
2 factor-oplossing voor WAIS correlatiematrix
subtests factorladingen F1 factorladingen F2 Informatie .80277 Begrijpen .75961 Rekenen .66999 Overeenkomsten .78335 Cijferreeksen .54402 Woordenschat .83885 Substitutie .61990 .14148 Onvolledige tekeningen .66249 .25279 Blokpatronen .63483 .30396 Plaatjes ordenen .56793 .27953 Figuurleggen .53325 .40720

148
Oefening: Gegeven de 2 factor-oplossing: Bereken de communaliteit van Cijferreeksen en Blokpatronen. Vergelijk met de communaliteit gegeven de 1 factor-oplossing. Schat de correlaties tussen Woordenschat en Informatie, en tussen Blokpatronen en Figuurleggen. Vergelijk je uitkomst met de geobserveerde correlaties en met de geschatte correlaties op basis van de 1 factor-oplossing. Wat is de prop. totale variantie verklaard door F1 en F2? Schrijf ’s op voor de volgende correlaties in het geval van twee factoren: r12=.64, r13=.00, r14=.00, r23=.00, r24=.00, r34=.56 (Er zijn oneindig veel juiste oplossingen)
")
149
3. Factor-analyse: model met 2 factoren 3.8. Grafische representatie
Kan grafisch gerepresenteerd worden als 1 dimensie: Emily Pete Simon Weinig Veel Model met 2 (of meerdere factoren): kan voorgesteld worden in 2(meer)-dimensionele ruimte: Test 1 Test 2
: kan voorgesteld worden in 2(meer)-dimensionele ruimte: Test 1. Test 2.")
150
3. Factor-analyse: model met 2 factoren 3.8. Grafische representatie
Factorladingen = coordinaten in assenstelsel Simon Emily T2 F1

151
3. Factor-analyse: model met 2 factoren 3.8. Grafische representatie
Deze figuurlijke voorstelling herbergt heel wat informatie: F2 T1 c b a F1

152
3. Factor-analyse: model met 2 factoren 3.8. Grafische representatie
1. gekwadrateerde lengte van test-vector is gelijk aan communaliteit van die test ( ) cfr. stelling van Pythagoras c2=a2+b2 = mate waarin factoren test bepalen! F2 T1 c b a F1
 cfr. stelling van Pythagoras. c2=a2+b2. = mate waarin factoren test bepalen! F2. T1. c. b. a. F1.")
153
3. Factor-analyse: model met 2 factoren 3.8. Grafische representatie
gekwadrateerde lengte van test-vector is gelijk aan communaliteit van die test DUS: lengte van de vector ~ hoeveel de factoroplossing verklaart in de test F2 T1 c b a F1

154
3. Factor-analyse: model met 2 factoren 3.8. Grafische representatie
2. geschatte correlatie tussen twee tests is gelijk aan scalair product van overeenkomstige test-vectoren, te berekenen aan de hand van de lengte van de vectoren en cos(θ) r(T1,T2)=||T1|| ||T2|| cos θ F2 T1 θ T2 F1
 r(T1,T2)=||T1|| ||T2|| cos θ. F2. T1. θ. T2. F1.")
155
3. Factor-analyse: model met 2 factoren 3.8. Grafische representatie
2. geschatte correlatie tussen twee tests is gelijk aan scalair product van overeenkomstige test-vectoren DUS: hoek tussen twee tests weerspiegelt hun correlatie = 90 : r = 0 < 90 : r > 0 > 90 : r < 0 F2 T1 θ T2 F1

156
3. Factor-analyse: model met 2 factoren 3.9. Uniciteit van schattingen
schattingen van factormodellen met meerdere factoren zijn niet uniek: er bestaan oneindig veel verzamelingen factorladingen, gemeenschappelijke factoren en specifieke factoren met dezelfde geschatte correlaties tussen tests: (.5 x .8) + (.4 x .4) = .56 (.2 x .41)+(.61 x .784) = .56 dezelfde communaliteiten: h12= = .41 h1’2 = = .41 oplossing 1 oplossing 2 F1 F2 test 1 .5 .4 .2 .61 test 2 .8 .41 .784
 + (.4 x .4) = .56 (.2 x .41)+(.61 x .784) = .56. dezelfde communaliteiten: h12= = .41 h1’2 = = .41. oplossing 1. oplossing 2. F1. F2. test test")
157
3. Factor-analyse: model met 2 factoren 3.9. Uniciteit van schattingen
grafisch komen verschillende oplossingen overeen met verschillende rotaties van assenstelsel! T1 T2

158
3. Factor-analyse: model met 2 factoren 3.9. Uniciteit van schattingen
grafisch komen verschillende oplossingen overeen met verschillende rotaties van assenstelsel F2’ T1 T2 -dezelfde communaliteiten (cfr. Pythagoras)! -dezelfde geschatte correlaties (scalair product invariant onder orthogonale rotatie)! F1’
! -dezelfde geschatte correlaties (scalair product invariant onder orthogonale rotatie)! F1’")
159
3. Factor-analyse: model met 2 factoren 3.9. Uniciteit van schattingen
hoe kiezen tussen al die verschillende oplossingen / rotaties? voor de hand liggend criterium: interpreteerbaarheid / psychologische begrijpbaarheid simple structure: elke test heeft op slechts 1 gemeenschappelijke factor een hoge lading in intelligentieonderzoek: geen negatieve ladingen

160
voorbeeld simple structure
gemeenschappelijke factoren test F1 F2 F3 T1 1 T2 T3 T4 T5 T6 T7 T8 T9

162
substitutie, onvolledige tekeningen,
blokpatronen, plaatjes ordenen, figuurleggen informatie, begrijpen, rekenen, overeenkomsten, cijferreeksen, woordenschat

163
2 factor-oplossing voor WAIS correlatiematrix:
orthogonale rotatie naar simple structure subtests factorladingen F1 factorladingen F2 Informatie .77552 .31073 Begrijpen .74644 .27783 Rekenen .59804 .32251 Overeenkomsten .73914 .32583 Cijferreeksen .46438 .28911 Woordenschat .80471 .33197 Substitutie .40213 .49253 Onvolledige tekeningen .36734 .60651 Blokpatronen .31407 .62988 Plaatjes ordenen .27630 .56951 Figuurleggen .17049 .64892 Verbale intelligentie Performantie intelligentie

164
Voorbeeld: ingrediënten
Factor1 Factor2 Factor3 Factor4 Pasta .78 .12 .13 Tomaat .74 .14 .40 .11 Gehakt .71 .04 -.65 Parmesan .91 .02 .07 Aardappel .75 .42 .05 Vlees .60 -.67 .21 Mayonaise .08 .80 .45 Selder .15 -.32 .85 .03 Prei -.22 .88 .09 Soja -.42 .76 .01 Tofu .06 -.50 .84 Brood .86 Gouda .87 Hesp -.60

165
Voorbeeld: factorladingen persoonlijkheidsbeschrijvende woorden
E V C N O 1. Enthousiast 2. Ruziezoekend 3. Betrouwbaar 4. Angstig 5. openstaand 6. Stil 7. Vriendelijk 8. Chaotisch 9. Stabiel 10. Oncreatief

166
Oefening: Gegeven de orthogonaal geroteerde 2 factor-oplossing: Bereken de communaliteit van Cijferreeksen en Blokpatronen. Vergelijk met de communaliteit gegeven de ongeroteerde 2 factor-oplossing. Schat de correlaties tussen Woordenschat en Informatie, en tussen Blokpatronen en Figuurleggen. Vergelijk je uitkomst met de geschatte correlaties op basis van de ongeroteerde 2 factor-oplossing. Wat is de prop. totale variantie verklaard door F1 en F2?

167
3. Factor-analyse: model met 2 factoren 3.7. Oblieke rotaties
soms niet mogelijk om via orthogonale rotatie goed interpreteerbare oplossing te vinden assumptie r(F1,F2)=0 laten vallen; is vaak ook inhoudelijk zinvol (bv verschillende soorten agressie, intelligentie) grafisch: F2 r(F1,F2)=cos(θ) F1 θ
=0 laten vallen; is vaak ook inhoudelijk zinvol (bv verschillende soorten agressie, intelligentie) grafisch: F2. r(F1,F2)=cos(θ) F1. θ.")
168
F2’ F1’ θ=ca. 53°

169
2 factor-oplossing voor WAIS correlatiematrix:
oblieke rotatie naar simple structure subtests factorladingen F1 factorladingen F2 Informatie .81872 .02607 Begrijpen .79685 Rekenen .59688 .12038 Overeenkomsten .76797 .06075 Cijferreeksen .44740 .14028 Woordenschat .84556 .03860 Substitutie .28672 .41444 Onvolledige tekeningen .19679 .56803 Blokpatronen .12196 .62033 Plaatjes ordenen .10090 .56432 Figuurleggen .70813 Verbale intelligentie Performantie intelligentie

170
3. Factor-analyse: model met 2 factoren 3.10. Oblieke rotaties
Gevolgen van het laten vallen van assumptie r(F1,F2)=0: ladingen zijn niet langer te interpreteren als correlaties tussen test en gemeenschappelijke factor =1
=0: ladingen zijn niet langer te interpreteren als correlaties tussen test en gemeenschappelijke factor. =1.")
171
3. Factor-analyse: model met 2 factoren 3.10. Oblieke rotaties
bij oblieke gemeenschappelijke factoren is correlatiematrix niet langer gelijk aan identiteitsmatrix: op de correlatiematrix kan je opnieuw factor-analyse toepassen = hogere orde factoranalyse (op correlaties tussen factorscores over personen) F1 F2 1 cos(θ)
 F1. F2. 1. cos(θ)")
172
3. Factor-analyse: model met 2 factoren 3.10. Oblieke rotaties
geschatte correlaties zijn niet langer de som van de producten van de overeenkomstige factorladingen

173
3. Factor-analyse: model met 2 factoren 3.10. Oblieke rotaties
Oefening: Bepaal de formule voor het schatten van de correlatie tussen twee tests op basis van het factoranalytisch model met oblieke factoren. Controleer dan deze formule (moet zelfde resultaten opleveren als formule voor orthogonale factoren) door de geschatte correlatie tussen Woordenschat en Informatie te berekenen (r(F1,F2)=.63225; ladingen Informatie: en ; Woordenschat: en ).
 door de geschatte correlatie tussen Woordenschat en Informatie te berekenen (r(F1,F2)=.63225; ladingen Informatie: en ; Woordenschat: en ).")
174
4. Factor-analyse: Model met meerdere factoren: Aantal factoren?
(1) Tot nu: Factor analyse met 2 factoren. Echter: gemakkelijk uit te breiden naar meer factoren Vraag: Hoeveel gemeenschappelijke factoren kiezen?
 Tot nu: Factor analyse met 2 factoren. Echter: gemakkelijk uit te breiden naar meer factoren. Vraag: Hoeveel gemeenschappelijke factoren kiezen")
175
4. Factor-analyse: Model met meerdere factoren: Aantal factoren?
Vergelijking FA model met 1 versus 2 factoren 1 factor model 2 factoren model Communaliteit cijferreeksen .29596 .29923 Communaliteit blokpatronen .40301 .49539 Proportie verklaarde variantie F1: F2:

176
4. Factor-analyse: Model met meerdere factoren: Aantal factoren?
Vergelijking FA model met 1 versus 2 factoren Correlatie tussen 1 factor model 2 factoren model geobserveerd Woordenschat en informatie .67340 .72722 .746 Blokpatronen en figuurleggen .33852 .46229 .489

177
4. Factor-analyse: Model met meerdere factoren: Aantal factoren?
Conclusie: geschatte correlaties tussen tests zijn slechts benadering van geobserveerde correlaties hoe meer gemeenschappelijke factoren, hoe beter de benadering indien evenveel gemeenschappelijke factoren als tests zullen voorspelde correlaties gelijk zijn aan geobserveerde correlaties MAAR niet spaarzaam. Factoren moeten inzichtelijk zijn; gemakkelijk te interpreteren Dus: Compromis zoeken tussen kwaliteit van benadering (veel factoren) en inzichtelijkheid/spaarzaamheid (weinig factoren). Dit is voor een stuk subjectief
 en inzichtelijkheid/spaarzaamheid (weinig factoren). Dit is voor een stuk subjectief.")
178
4. Factor-analyse: Model met meerdere factoren: Aantal factoren?
Veelgebruikt criterium: Scree test (ontwikkeld door Cattell): Obv Eigenwaarde = totale variantie verklaard door factor Geeft aan hoeveel factor uit het model verklaart Eigenwaarde daalt monotoon met aantal factoren (hoe meer factoren, hoe minder een bijkomende factor kan verklaren) Keuze = die oplossing met N factoren die een pak meer verklaart dan een oplossing met N-1 factoren, en die niet veel minder verklaart dan een oplossing met N+1 factoren = model VOOR de “elleboog” in een figuur die aantal factoren uitzet tegen eigenwaardes van oplossingen
: Obv Eigenwaarde = totale variantie verklaard door factor. Geeft aan hoeveel factor uit het model verklaart. Eigenwaarde daalt monotoon met aantal factoren (hoe meer factoren, hoe minder een bijkomende factor kan verklaren) Keuze = die oplossing met N factoren die een pak meer verklaart dan een oplossing met N-1 factoren, en die niet veel minder verklaart dan een oplossing met N+1 factoren. = model VOOR de elleboog in een figuur die aantal factoren uitzet tegen eigenwaardes van oplossingen.")
179
4. Factor-analyse: Model met meerdere factoren: Aantal factoren?
Veelgebruikt criterium: Scree test (ontwikkeld door Cattell): = model VOOR de “elleboog”: 1ste F verklaart 4.8 2de F verklaart 1.1 (samen 5.9) 3de F verklaart 0.9 (samen 6.8) Model met 1 factor verklaart veel, extra factoren toevoegen verklaart niet veel meer extra Keuze = model met 1 factor
: = model VOOR de elleboog : 1ste F verklaart de F verklaart 1.1 (samen 5.9) 3de F verklaart 0.9 (samen 6.8) Model met 1 factor verklaart veel, extra factoren toevoegen verklaart niet veel meer extra. Keuze = model met 1 factor.")
180
4. Factor-analyse: Model met meerdere factoren: Aantal factoren?
Veelgebruikt criterium: Scree test (ontwikkeld door Cattell): = model VOOR de “elleboog”: 1ste F verklaart 5.2 2de F verklaart 3.3 (samen 8.5) 3de F verklaart 1.2 (samen 9.7) 4de F verklaart 1 (samen 10.7) Model met 2 factor verklaart pak meer dan met 1 factor, extra factoren toevoegen verklaart niet veel meer extra, factor weglaten betekent groot verlies Keuze = model met 2 factoren
: = model VOOR de elleboog : 1ste F verklaart de F verklaart 3.3 (samen 8.5) 3de F verklaart 1.2 (samen 9.7) 4de F verklaart 1 (samen 10.7) Model met 2 factor verklaart pak meer dan met 1 factor, extra factoren toevoegen verklaart niet veel meer extra, factor weglaten betekent groot verlies. Keuze = model met 2 factoren.")
181
4. Factor-analyse: Model met meerdere factoren: welke factoren?
(2) Gegeven bepaalde keuze voor gemeenschappelijk aantal factoren: Welke rotatie kiezen? Ongeroteerde oplossing, orthogonale rotatie, oblieke rotatie = oneindig veel wiskundig equivalente oplossingen (cfr. geen uniciteit)
 Gegeven bepaalde keuze voor gemeenschappelijk aantal factoren: Welke rotatie kiezen Ongeroteerde oplossing, orthogonale rotatie, oblieke rotatie. = oneindig veel wiskundig equivalente oplossingen (cfr. geen uniciteit)")
182
Ongeroteerde 2 factor-oplossing voor WAIS correlatiematrix
subtests factorladingen F1 factorladingen F2 Informatie .80277 Begrijpen .75961 Rekenen .66999 Overeenkomsten .78335 Cijferreeksen .54402 Woordenschat .83885 Substitutie .61990 .14148 Onvolledige tekeningen .66249 .25279 Blokpatronen .63483 .30396 Plaatjes ordenen .56793 .27953 Figuurleggen .53325 .40720

183
2 factor-oplossing voor WAIS correlatiematrix:
orthogonale rotatie naar simple structure subtests factorladingen F1 factorladingen F2 Informatie .77552 .31073 Begrijpen .74644 .27783 Rekenen .59804 .32251 Overeenkomsten .73914 .32583 Cijferreeksen .46438 .28911 Woordenschat .80471 .33197 Substitutie .40213 .49253 Onvolledige tekeningen .36734 .60651 Blokpatronen .31407 .62988 Plaatjes ordenen .27630 .56951 Figuurleggen .17049 .64892

184
2 factor-oplossing voor WAIS correlatiematrix:
oblieke rotatie naar simple structure subtests factorladingen F1 factorladingen F2 Informatie .81872 .02607 Begrijpen .79685 Rekenen .59688 .12038 Overeenkomsten .76797 .06075 Cijferreeksen .44740 .14028 Woordenschat .84556 .03860 Substitutie .28672 .41444 Onvolledige tekeningen .19679 .56803 Blokpatronen .12196 .62033 Plaatjes ordenen .10090 .56432 Figuurleggen .70813

185
4. Factor-analyse: Model met meerdere factoren: welke factoren?
Deze drie getoonde oplossingen zijn wiskundig equivalent: voorspelde correlaties hetzelfde, communaliteit van tests hetzelfde, totaal verklaarde variantie door factoren hetzelfde. Keuze? - Interpretatie van de factoren gebeurt op basis van de ladingen van de tests op de factoren - In cognitief domein: geen negatieve ladingen - Rotatie naar ‘simple structure’ - Inhoudelijke interpretatie staat centraal; dit is voor een stuk subjectief

186
5. Factor-analyse: opmerkingen
De output van FA wordt volledig bepaald door de input a. Op vlak van proefpersonen Kenmerken proefgroep bepalen sterk gevonden structuur - allemaal zeer intelligent - allemaal sociaal voelend, etc. heeft invloed op welke structuur er gevonden wordt b. Op vlak van variabelen de onderliggende dimensies die je vindt hangen helemaal af van welke items of tests je oorspronkelijk hebt meegenomen in je analyse Bv. Dominant, bazig, assertief, machtig, krachtig, invloedrijk, autoritair, … Belangrijk dat je goede selectie maakt van items die het domein dat je wil onderzoeken goed reflecteren cfr. Lexicale methode

187
5. Factor-analyse: opmerkingen
2. Statuut van de latente, onderliggende factor? Het feit dat je een factor vindt (=wiskundige zekerheid) betekent nog niet dat er dan ook echt een onderliggende factor bestaat bv. FA op lengtes van lichaamsdelen, FA op mijn leeftijd, de prijs van zwitserse kaas, de lengte van mijn huisdierschildpad, en de afstand tussen melkwegen: 1 factor 1 onderliggende causale oorzaak? + oplossing heeft telkens oneindig veel equivalente varianten: wat zegt dit over werkelijkheidswaarde van “gevonden factoren” Factoranalyse is een van de meest gebruikte maar ook een van de meest misbruikte technieken in de psychologie! ALS onderliggende factor DAN correlaties, maar niet per se ALS correlaties DAN onderliggende factor
 betekent nog niet dat er dan ook echt een onderliggende factor bestaat. bv. FA op lengtes van lichaamsdelen, FA op mijn leeftijd, de prijs van zwitserse kaas, de lengte van mijn huisdierschildpad, en de afstand tussen melkwegen: 1 factor. 1 onderliggende causale oorzaak + oplossing heeft telkens oneindig veel equivalente varianten: wat zegt dit over werkelijkheidswaarde van gevonden factoren Factoranalyse is een van de meest gebruikte maar ook een van de meest misbruikte technieken in de psychologie! ALS onderliggende factor DAN correlaties, maar niet per se. ALS correlaties DAN onderliggende factor.")
188
5. Factor-analyse: opmerkingen
Rol van subjectiviteit FA-proces vergt verschillende subjectieve beslissingen (aantal factoren, rotatie): uiteindelijke uitkomst is hier dus ook van afhankelijk! Belang van starten met goede theorie ZELF-EVALUATIE!!! + WC
: uiteindelijke uitkomst is hier dus ook van afhankelijk! Belang van starten met goede theorie. ZELF-EVALUATIE!!! + WC.")
189
Factor-analyse: studeren
College/notas/oefeningen Zelf-evaluatie sessie DOS Werkcolleges

190
Extra oefeningen De correlaties tussen de drie oblieke factoren van eerste orde bedragen .06 (factor 1 en 2), .08 (factor 2 en 3), .12 (factor 1 en 3). Hoe groot zijn de ladingen van deze factoren op de gemeenschappelijke factor van tweede orde? Als de tekens van de ladingen per factor omgekeerd worden, dan is dat zonder gevolgen voor de correlaties --- juist? waarom wel / niet? voor de interpretatie van de factoren ---- idem
, .08 (factor 2 en 3), .12 (factor 1 en 3). Hoe groot zijn de ladingen van deze factoren op de gemeenschappelijke factor van tweede orde Als de tekens van de ladingen per factor omgekeerd worden, dan is dat zonder gevolgen. voor de correlaties --- juist waarom wel / niet voor de interpretatie van de factoren ---- idem.")
191
Extra oefeningen Hoe groot zijn r(T1,T2), r(T2,T3), r(T1,T3) als de ’s de volgende zijn? T T T en hoe groot zijn ?

Verwante presentaties