Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Week 9: Probabilistische Grammatica's Jurafsky & Martin (ed. 1), Hoofdstuk 12: Lexicalized and Probabilistic Parsing) Taaltheorie en Taalverwerking Remko Scha, ILLC Opleiding Kunstmatige Intelligentie
, Hoofdstuk 12: Lexicalized and Probabilistic Parsing) Taaltheorie en Taalverwerking Remko Scha, ILLC Opleiding Kunstmatige Intelligentie.")
2
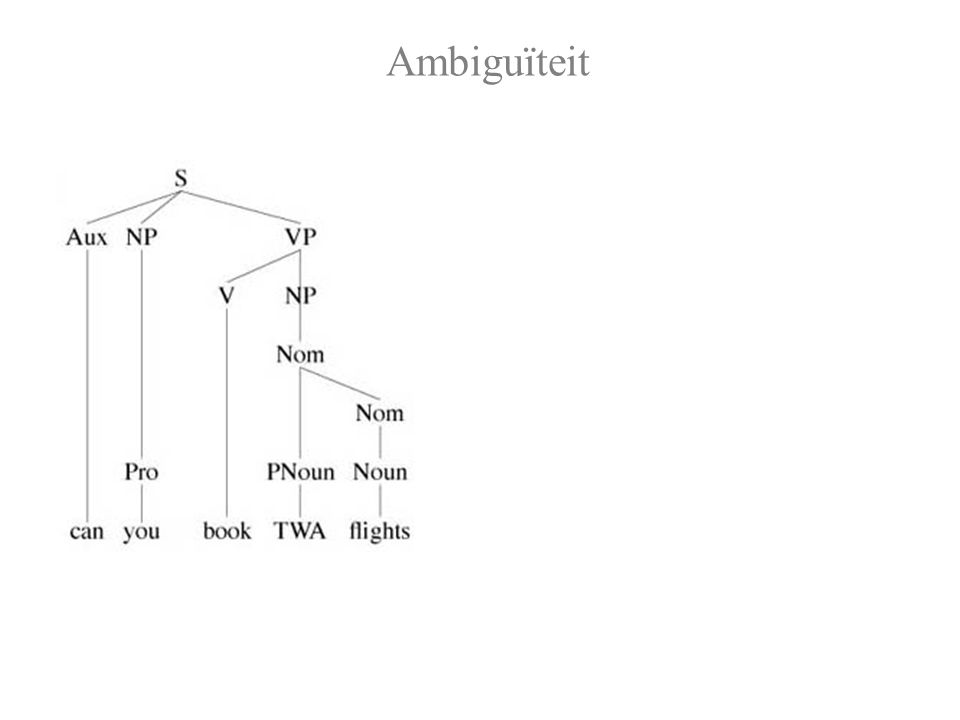
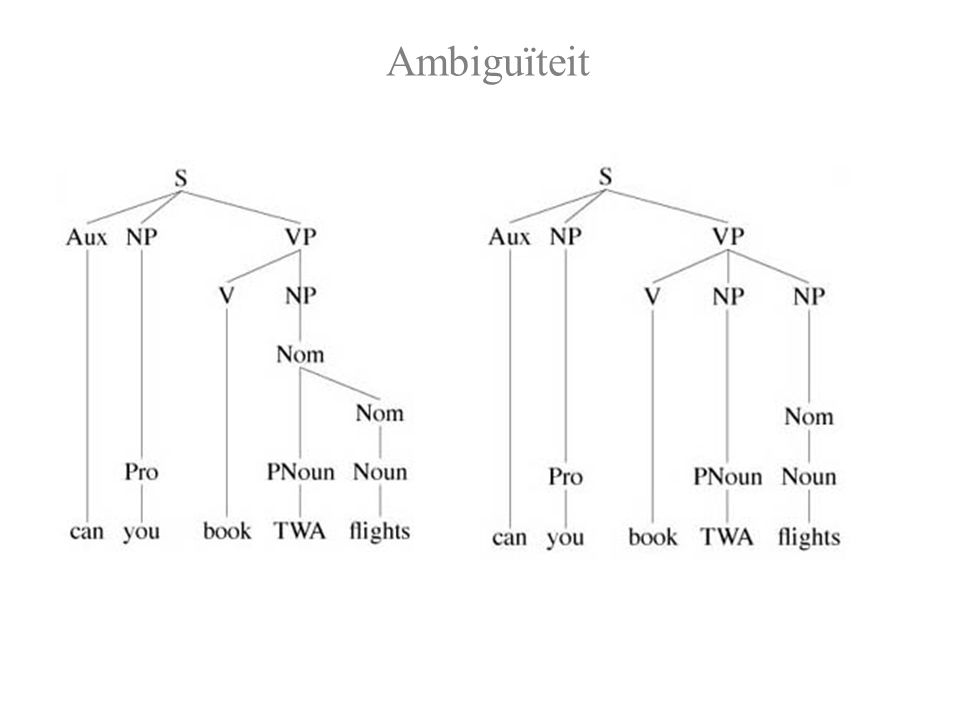
Ambiguïteit

5
Cf.: Can you book me a flight? Can you book Mr. Jones some flights?

6
Syntactische Ambiguïteit Wat voor redenen zijn er om Can you [book [TWA flights]]? te verkiezen boven Can you [book TWA flights]? 1. Pragmatisch: Men vraagt niet vaak of je voor een specifiek iemand vluchten kunt boeken. Of: men vraagt niet vaak over vluchten zonder verdere specificaties. 2. Semantisch: Vluchten boeken voor een vliegmaatschappij is onzinnig in dit domein. 3. Syntactisch: Werkwoorden worden meestal zonder meewerkend voorwerp gebruikt; of: "to book" wordt meestal zonder meewerkend voorwerp gebruikt; of: "flights" wordt vaak met een modifier gebruikt; etc.
![Syntactische Ambiguïteit Wat voor redenen zijn er om Can you [book [TWA flights]].](http://images.slideplayer.nl/7/1896092/slides/slide_6.jpg "te verkiezen boven Can you [book TWA flights]. 1. Pragmatisch: Men vraagt niet vaak of je voor een specifiek iemand vluchten kunt boeken. Of: men vraagt niet vaak over vluchten zonder verdere specificaties. 2. Semantisch: Vluchten boeken voor een vliegmaatschappij is onzinnig in dit domein. 3. Syntactisch: Werkwoorden worden meestal zonder meewerkend voorwerp gebruikt; of: to book wordt meestal zonder meewerkend voorwerp gebruikt; of: flights wordt vaak met een modifier gebruikt; etc..")
7
Syntactische Ambiguïteit Disambiguërings-methodes: 1./2. Pragmatisch/Semantisch: Bepaal betekenis-representaties voor elk van de mogelijke interpretaties. Redeneer over wat iemand kan willen weten en over wat zinnig is in dit domein. [Ouderwetse symbolische A.I.]

8
Syntactische Ambiguïteit Disambiguërings-methodes: 1./2. Pragmatisch/Semantisch: Bepaal betekenis-representaties voor elk van de mogelijke interpretaties. Redeneer over wat iemand kan willen weten en over wat zinnig is in dit domein. 2. Syntactisch: Doe statistiek over syntactische structuren.

9
Syntactische Ambiguïteit Disambiguërings-methodes: 1./2. Pragmatisch/Semantisch: Bepaal betekenis-representaties voor elk van de mogelijke interpretaties. Redeneer over wat iemand kan willen weten en over wat zinnig is in dit domein. 2. Syntactisch: Doe statistiek over syntactische structuren. Merk op: distributie van syntactische structuren kan correleren met pragmatisch/semantische regelmatigheden

10
Syntactische Ambiguïteit Disambiguërings-methodes: 1./2. Pragmatisch/Semantisch: Bepaal betekenis-representaties voor elk van de mogelijke interpretaties. Redeneer over wat iemand kan willen weten en over wat zinnig is in dit domein. 2. Syntactisch: Doe statistiek over syntactische structuren. Merk op: distributie van syntactische structuren correleert met pragmatisch/semantische regelmatigheden, vooral als we ook informatie over specifieke lexicale items meenemen.

11
Kansrekening: Basics. [Russell & Norvig, pp. 466-478.]
![Kansrekening: Basics. [Russell & Norvig, pp ]](http://images.slideplayer.nl/7/1896092/slides/slide_11.jpg "Kansrekening: Basics. [Russell & Norvig, pp ]")
12
Kansrekening: Basics. Het begrip kans veronderstelt een partitie van een ruimte van mogelijkheden. Een kans beschrijft de relatieve grootte van een deel van die ruimte. B.v.: een meting met k mogelijke uitkomsten: P(1) + P(2) +... + P(k) = 1.
 + P(2) P(k) = 1..")
13
Kansrekening: Basics. Joint probabilities. Als A en B uitkomsten zijn van 2 verschillende onafhankelijke metingen, dan is de kans op A en B: P(A & B) = P(A) P(B)
 = P(A) P(B).")
14
Kansrekening: Basics. Conditionele waarschijnlijkheden. De kans op A gegeven B schrijven we als: P(A|B)
.")
15
Kansrekening: Basics. Algemeen geldt: P(A & B) = P(A|B) P(B) P(A & B) = P(B|A) P(A) Als A en B onafhankelijk zijn, dan is P(A|B) = P(A) P(B|A) = P(B) dus P(A & B) = P(A) P(B)
 = P(A|B) P(B) P(A & B) = P(B|A) P(A) Als A en B onafhankelijk zijn, dan is P(A|B) = P(A) P(B|A) = P(B) dus P(A & B) = P(A) P(B).")
16
Statistische syntactische desambiguëring.

17
Eenvoudigste idee: Probabilistische Contextvrije Grammatica (PCFG)
")
18
Voeg aan elke herschrijfregel (A ) een conditionele kans toe: P(A | A)
 een conditionele kans toe: P(A | A)")
19
Probabilistische Contextvrije Grammatica (PCFG) Voeg aan elke herschrijfregel (A ) een conditionele kans toe: P(A | A) Eis: P(A ) = 1
 Voeg aan elke herschrijfregel (A ) een conditionele kans toe: P(A | A) Eis: P(A ) = 1")
20
CFG: 4-tupel N: eindige verzameling non-terminale symbolen (b.v.: {S, NP, VP, noun, article,...}) : eindige verzameling terminale symbolen (b.v.: {the, a, boy, wumpus,...}) N = S: startsymbool; S N P: eindige verzameling herschrijfregels { A ,.....} A N, (N )* Cf. Jurafsky & Martin: Hoofdstuk 9 (Context-Free Grammars for English), p. 331
, p")
21
PCFG: 5-tupel N: eindige verzameling non-terminale symbolen (b.v.: {S, NP, VP, noun, article,...}) : eindige verzameling terminale symbolen (b.v.: {the, a, boy, wumpus,...}) N = S: startsymbool; S N P: eindige verzameling herschrijfregels { A ,.....} A N, (N )* D: functie die aan elke regel p P een getal tussen 0 en 1 toekent. A N P(A ) = 1 Cf. Jurafsky & Martin: Hoofdstuk 12, pp. 448/449
 = 1 Cf. Jurafsky & Martin: Hoofdstuk 12, pp. 448/449.")
22
PCFG Kans op een parse-tree = Product van de kansen van alle toegepaste regels

23
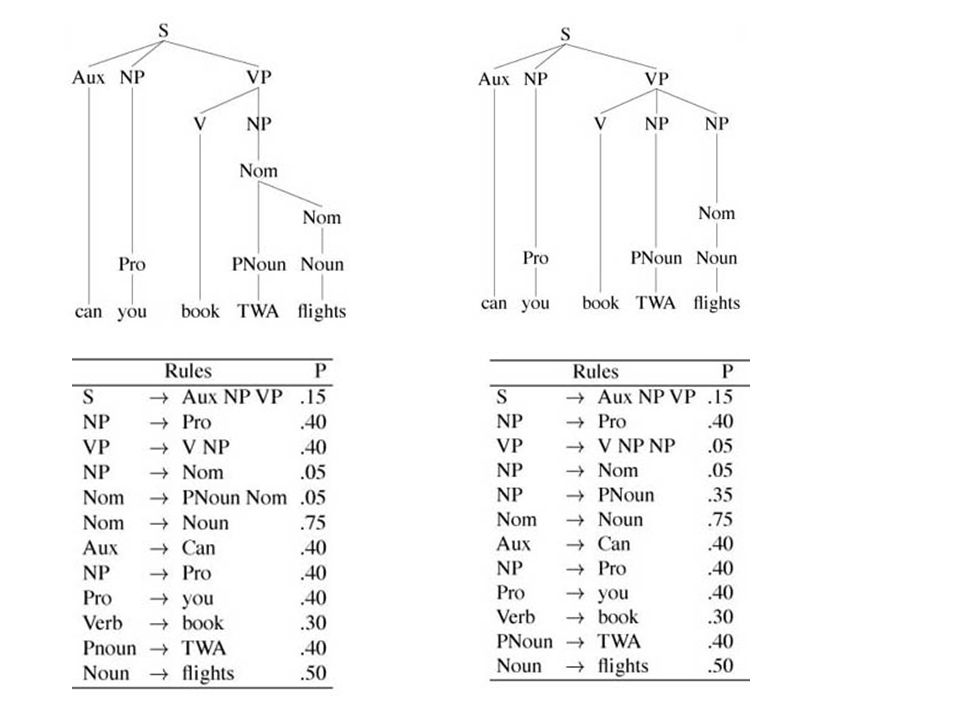
Example PCFG

25
P =.15 *.40 *.05 *.05 *.35 *.75 *.40 *.40 *.40 *.30 *.40 *.50 = 1.5 * 10 -6 P =.15 *.40 *.40 *.05 *.05 *.75 *.40 *.40 *.40 *.30 *.40 *.50 = 1.7 * 10 -6 Statistische Desambiguëring: Kies de boom met de hoogste waarschijnlijkheid

26
Kans op een zin = Som van de kansen van de verschillende bomen van die zin. (Toepassing: Spraakherkenning.)
.")
27
Hoe bepaal je de kansen van de CFG-regels? • Schatting op basis van de relatieve frequenties in een "treebank" (syntactisch geannoteerd corpus). • "Expectation Maximization": Gegeven een "plat" corpus (collectie zinnen): stel de waarschijnlijkheden zodanig in, dat de kans om dat corpus te genereren zo groot mogelijk is.
. • Expectation Maximization : Gegeven een plat corpus (collectie zinnen): stel de waarschijnlijkheden zodanig in, dat de kans om dat corpus te genereren zo groot mogelijk is..")
28
Beperking van PCFG's: De toepassingen van de herschrijfregels worden behandeld als statistisch onafhankelijk.

29
Een PCFG kent aan deze beide analyses altijd dezelfde waarschijnlijkheid toe!

30
Oplossing: • PCFG's met verrijkte labels die niet-locale informatie coderen • Stochastic Tree Substitution Grammars

31
Lexicalized PCFG's: Head-features (Collins et al.)
")
32
Lexicalized PCFG's: Head-features VP(dumped) VBD(dumped) NP(sacks) PP(into) waarschijnlijk NP(sacks) NP(sacks) PP(into) onwaarschijnlijk VP(dumped) VBD(dumped) NP(sacks) PP(with) niet heel waarschijnlijk NP(sacks) NP(sacks) PP(with) heel waarschijnlijk
 VBD(dumped) NP(sacks) PP(into) waarschijnlijk NP(sacks) NP(sacks) PP(into) onwaarschijnlijk VP(dumped) VBD(dumped) NP(sacks) PP(with) niet heel waarschijnlijk NP(sacks) NP(sacks) PP(with) heel waarschijnlijk")
33
Data-Oriented Parsing (DOP) (Scha, Bod, Sima'an) Gebruik een geannoteerd corpus ("treebank"). Lees een Stochastic Tree Substitution Grammar rechtstreeks af uit het corpus. (PPT-presentatie van Guy De Pauw, Universiteit Antwerpen)
.")
34
Data-Oriented Parsing (DOP) Gebruik een geannoteerd corpus. Gebruik een Stochastic Tree Substitution Grammar Lees deze STSG rechtstreeks af uit het corpus (PPT van Guy De Pauw, Universiteit Antwerpen)
.")
37
Treebank

38
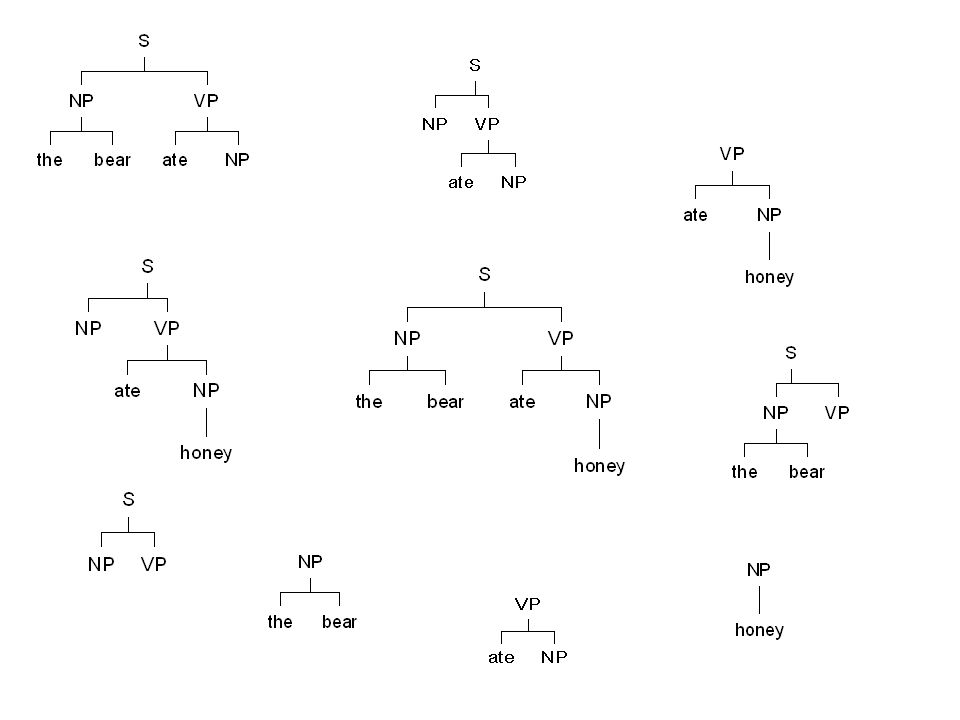
Sentence to be parsed: Peter killed the bear 1 parse-tree; meerdere afleidingen Data-Oriented Parsing

39
An annotated corpus defines a Stochastic Tree Substitution Grammar Probability of a Derivation: Product of the Probabilities of the Subtrees

40
Probability of a Derivation: Product of the Probabilities of the Subtrees Probability of a Parse: Sum of the Probabilities of its Derivations An annotated corpus defines a Stochastic Tree Substitution Grammar

41
Probability of a Derivation: Product of the Probabilities of the Subtrees Probability of a Parse: Sum of the Probabilities of its Derivations Disambiguation: Choose the Most Probable Parse An annotated corpus defines a Stochastic Tree Substitution Grammar

42
Human parsing continued.

43
•Center-embedding (J&M, § 13.4)
")
44
Human parsing continued. •Center-embedding (J&M, § 13.4) •Garden-path sentences (J&M, § 12.5)
 •Garden-path sentences (J&M, § 12.5)")
45
Garden-path sentences "The horse raced past the barn

46
Garden-path sentences "The horse raced past the barn fell."

47
Garden-path sentences "The complex houses

48
Garden-path sentences "The complex houses graduate students."

49
Garden-path sentences "The student forgot the solution

50
Garden-path sentences "The student forgot the solution was in the back of the book."

51
Garden-path sentences •Desambiguëring gebeurt incrementeel. •Desambiguëringsbeslissing kan te vroeg genomen worden.

52
Opgave: (1) Gebruik waarschijnlijkheden aan toe aan je CFG. (2) Zorg dat je parser alle mogelijke analyses van de input-zin oplevert. (3) Zorg dat je parser de waarschijnlijkheden van alle analyses berekent, en de meest waarschijnlijke boom als output geeft.
 Zorg dat je parser alle mogelijke analyses van de input-zin oplevert. (3) Zorg dat je parser de waarschijnlijkheden van alle analyses berekent, en de meest waarschijnlijke boom als output geeft..")
54
Spraak & Taal: "Language Modelling" Spraak: Giswerk. Corpus-gebaseerde aanpak: Sla heel veel geluiden op en kijk waar het input-signaal het meest op lijkt. Men doet dit met statistiek: Men schat de kans dat aan een stukje input-signaal een bepaald foneem ten grondslag ligt.

55
Spraak & Taal: "Language Modelling" De spraakherkennings-technologie stelt ons in staat om voor elk kandidaat-woord W en elk input-signaal te schatten: de kans dat iemand W uitspreekt als S: P(S | W)
")
56
Spraak & Taal: "Language Modelling" De spraakherkennings-technologie stelt ons in staat om voor elk kandidaat-woord W en elk input-signaal te schatten: de kans dat iemand W uitspreekt als S: P(S | W) Wat we willen weten is: De kans dat aan het gegeven input-signaal S een kandidaat-woord W ten grondslag ligt: P(W | S)
 Wat we willen weten is: De kans dat aan het gegeven input-signaal S een kandidaat-woord W ten grondslag ligt: P(W | S)")
57
Spraak & Taal: "Language Modelling" De spraakherkennings-technologie stelt ons in staat om voor elk kandidaat-woord W en elk input-signaal te schatten: de kans dat iemand W uitspreekt als S: P(S | W) Wat we willen weten is: De kans dat aan het gegeven input-signaal S een kandidaat-woord W ten grondslag ligt: P(W | S) Wat nu?
 Wat we willen weten is: De kans dat aan het gegeven input-signaal S een kandidaat-woord W ten grondslag ligt: P(W | S) Wat nu")
58
Elementaire kansrekening: de regel van Bayes

59
P(W & S) = P(W|S) P(S) P(W & S) = P(S|W) P(W)
 = P(W|S) P(S) P(W & S) = P(S|W) P(W)")
60
Elementaire kansrekening: de regel van Bayes P(W & S) = P(W|S) P(S) P(W & S) = P(S|W) P(W) P(W|S) P(S) = P(S|W) P(W)
 = P(W|S) P(S) P(W & S) = P(S|W) P(W) P(W|S) P(S) = P(S|W) P(W)")
61
Elementaire kansrekening: de regel van Bayes P(W & S) = P(W|S) P(S) P(W & S) = P(S|W) P(W) P(W|S) P(S) = P(S|W) P(W) P(W|S) = P(S|W) P(W) / P(S)
 = P(W|S) P(S) P(W & S) = P(S|W) P(W) P(W|S) P(S) = P(S|W) P(W) P(W|S) = P(S|W) P(W) / P(S)")
62
Elementaire kansrekening: de regel van Bayes P(W & S) = P(W|S) P(S) P(W & S) = P(S|W) P(W) P(W|S) P(S) = P(S|W) P(W) P(W|S) = P(S|W) P(W) / P(S) P(W|S) ≈ P(S|W) P(W) P(W) is de a priori kans op woord W
 = P(W|S) P(S) P(W & S) = P(S|W) P(W) P(W|S) P(S) = P(S|W) P(W) P(W|S) = P(S|W) P(W) / P(S) P(W|S) ≈ P(S|W) P(W) P(W) is de a priori kans op woord W")
63
Spraak & Taal: "Language Modelling" Voor de spraakherkenning willen we weten: de a priori kansen op alle mogelijke woorden.

64
Spraak & Taal: "Language Modelling" Voor de spraakherkenning willen we weten: de a priori kansen op alle mogelijke woorden. Hoe komen we daar achter? Tellen in een representatief corpus.

65
Statistical Language Model P(the cat is on the mat) = P(the | ) * P(cat | the) * P(is | the cat) * P(on | the cat is) * P(the | the cat is on) * P (mat | the cat is on the) * P( | the cat is on the mat)
 = P(the | ) * P(cat | the) * P(is | the cat) * P(on | the cat is) * P(the | the cat is on) * P (mat | the cat is on the) * P( | the cat is on the mat)")
66
P(W 1,…,W N ) =
 =")
67
Bigram models P(the cat is on the mat) = P(the | ) * P(cat | the) * P(is | cat) * P(on | is) * P(the | on) * P (mat | the) * P( | mat)
 = P(the | ) * P(cat | the) * P(is | cat) * P(on | is) * P(the | on) * P (mat | the) * P( | mat)")
68
Example: Bigrams

69
Example: Bigrams (continued) P(I want to eat British food) = P(I| )P(want|I)P(to|want)P(eat|to)P(British|eat) P(food|British) =.25 *.32 *.65 *.26 *.002 *.60 =.000016
 P(I want to eat British food) = P(I| )P(want|I)P(to|want)P(eat|to)P(British|eat) P(food|British) =.25 *.32 *.65 *.26 *.002 *.60 =")
70
Trigram models P(the cat is on the mat) = P(the | ) * P(cat | the) * P(is | the cat) * P(on | cat is) * P(the | is on) * P (mat | on the) * P( | the mat)
 = P(the | ) * P(cat | the) * P(is | the cat) * P(on | cat is) * P(the | is on) * P (mat | on the) * P( | the mat)")
71
Estimating bigram probabilities e.g. P (book | the) =C(the,book) C(the)
 =C(the,book) C(the)")
Verwante presentaties







>")













 2. Unificatie grammatica Natuurlijke taalverwerking week 7.>")
