Download de presentatie
1
Beschrijvende en inferentiële statistiek
College 7 – Anouk den Hamer – Hoofdstuk 10 (10.1, 10.3 geen tentamenstof, van 10.4 is alleen het stuk over gemiddeldes tentamenstof, het stuk over proporties niet)
")
2
Vandaag Korte quiz stof vorige week Oude tentamenvragen bespreken
Independent T-test Dependent T-test

3
Vorige week Betrouwbaarheidsintervallen Hypothesetoetsing

4
Vraag 1 Je wilt een 99% betrouwbaarheidsinterval maken van een populatiegemiddelde. Je steekproef bestaat uit 250 respondenten. Welke formule gebruik je voor het interval? a) Gemiddelde ± z1.96(se) b) Gemiddelde ± z2.58(se) c) Gemiddelde ± t1.96(se) d) Gemiddelde ± t2.58(se)
 Gemiddelde ± z1.96(se) b) Gemiddelde ± z2.58(se) c) Gemiddelde ± t1.96(se) d) Gemiddelde ± t2.58(se)")
5
Vraag 2 Je steekproef bestaat uit 25 respondenten. Welke verdeling gebruik je voor je betrouwbaarheidsinterval? De z-verdeling De t-verdeling

6
Vraag 3 Je vraagt je af of de colleges op dinsdag drukker bezocht worden dan de colleges op woensdag. Je hypothese is dat de dinsdagcolleges meer bezocht worden dan de woensdagcolleges. Nadat je onderzoekgegevens verzameld hebt, vind je in SPSS een p-waarde van 0.09 (2-tailed). Wat doe je met de nulhypothese? Die kun je verwerpen Die kun je niet verwerpen
. Wat doe je met de nulhypothese Die kun je verwerpen. Die kun je niet verwerpen.")
7
Vraag 4 Op welke drie manieren kun je in SPSS zien of je de nulhypothese wel of niet kunt verwerpen? Antwoord: t-score, p-waarde, betrouwbaarheidsinterval

12
Eenzijdig of tweezijdig?

13
95% Tweezijdig: t.025 Eenzijdig: t.05

15
Tot nu toe geleerd Beschrijvende statistiek Populatie- en
Week 1: o.a. proporties, gemiddeldes, standaarddeviaties en z-scores Populatie- en kansverdelingen Week 2: steekproevenverdeling, op basis daarvan betrouwbare schattingen maken van populatiewaarde Inferentiële statistiek Week 3: voor één variabele berekend hoe ver de populatiewaarde waarschijnlijk van de steekproefwaarde af ligt (het CI) en getoetst of het waarschijnlijk is dat de populatiewaarde een bepaalde waarde NIET is (de hypothesetoets)
 en getoetst. of het waarschijnlijk is dat de populatiewaarde een bepaalde waarde. NIET is (de hypothesetoets)")
16
Univariate toetsen: Toetsen waarbij je één enkele variabele onderzoekt
Univariate toetsen: Toetsen waarbij je één enkele variabele onderzoekt. Bivariate toetsen: Toetsen waarbij je onderzoekt of er een relatie bestaat tussen 2 variabelen. Multivariate toetsen: Relatie tussen meer dan 2 variabelen.

17
Beschrijvende statistieken: univariaat
Variabelen Categorisch Kwantitatief (discreet en continu) Verdeling van de data (data distribution) Uni-/ bimodaal Scheefheid Normaalverdeling Grafische weergaven Pie chart; bar chart Kwantitatief Histogram Stem-and-leaf plot Dot plot/ scatterplot Box plot Centrum Gemiddelde Mediaan Modus Spreiding Standaard deviatie Range Kwartielen Interkwartielafstand (IQR) Positie Deviatie z-score / t-score Percentiel Outlier
 Verdeling van de data (data distribution) Uni-/ bimodaal. Scheefheid. Normaalverdeling. Grafische weergaven. Pie chart; bar chart. Kwantitatief. Histogram. Stem-and-leaf plot. Dot plot/ scatterplot. Box plot. Centrum. Gemiddelde. Mediaan. Modus. Spreiding. Standaard deviatie. Range. Kwartielen. Interkwartielafstand (IQR) Positie. Deviatie. z-score / t-score. Percentiel. Outlier.")
18
Beschrijvende statistieken: bivariaat
Variabelen Afhankelijk Onafhankelijk Categorisch Kruistabel (contingency tabel/ cross table) Marginale proporties Conditionele proporties Kwantitatief Scatterplot Associatie (positief/ negatief) Correlatie Regressie Causaliteit Geen kinderen Wel kinderen Totaal aantal Proportie (marginaal) Niet getrouwd 0.26 0.15 5.027 0.40 Wel getrouwd 0.06 0.53 7.418 0.60 3.977 8.468 12.445 0.32 0.68 1
 Marginale proporties. Conditionele proporties. Kwantitatief. Scatterplot. Associatie (positief/ negatief) Correlatie. Regressie. Causaliteit. Geen kinderen. Wel kinderen. Totaal aantal. Proportie (marginaal) Niet getrouwd Wel getrouwd")
19
Inferentiële statistiek: overzicht
Aantal variabelen Soort variabele(n) Betrouwbaarheidsinterval Hypothesetoets 1 Categorisch Kwantitatief 2 (of meer) Kwantitatief en 2 onafhankelijke groepen Kwantitatief en 2 afhankelijke groepen idem. - chi-kwadraat Kwantitatief of combinatie correlatie en regressie
 Betrouwbaarheidsinterval. Hypothesetoets. 1. Categorisch. Kwantitatief. 2 (of meer) Kwantitatief en 2 onafhankelijke groepen. Kwantitatief en 2 afhankelijke groepen. idem. - chi-kwadraat. Kwantitatief of combinatie. correlatie en. regressie.")
20
T-toets Vergelijken van gemiddelden van twee groepen
Independent T-test Dependent T-test Geslacht: man/vrouw Inkomen

21
Independent samples Bij een independent sample worden groepen vergeleken die niks met elkaar van doen hebben.

22
Dependent samples Bij een dependent sample worden groepen vergeleken die wel wat met elkaar van doen hebben, zoals echtparen. Bv inkomen van de man vergeleken met het inkomen van de vrouw. Een dependent sample kan ook bestaan uit een voor- en een nameting van dezelfde respondenten. Bv het inkomen van een man voordat hij getrouwd is en het inkomen nadat hij getrouwd is.

23
Independent T-test Vergelijken van twee groepen die onafhankelijk van elkaar zijn.

24
Voorbeeld independent t-test
Voorbeeldhypothese: Mensen met een kat zijn gelukkiger dan mensen zonder kat.

25
Mensen met een kat zijn gelukkiger dan mensen zonder kat.
Variabele: het wel of niet hebben van een kat Groep 1: heeft geen kat Groep 2: heeft wel een kat Nulhypothese: Mensen met een kat zijn net zo gelukkig als mensen zonder kat.

27
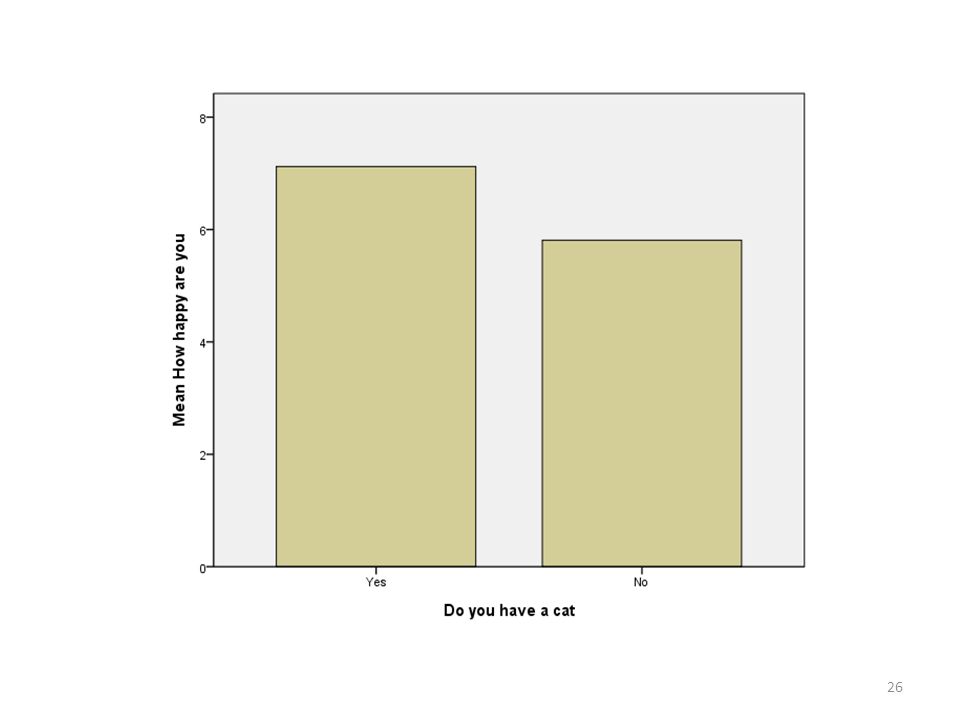
Katten en geluk (independent sample)
Test statistic: S1 is de standaarddeviatie van groep 1 en s2 van groep 2. Waarom – 0? Dat is de waarde van de nulhypothese. De nulhypothese zegt dat er geen verschil is tussen beide groepen.

28
Katten en geluk (independent sample)
respondenten ondervraagd: Formule test statistic invullen:

29
Katten en geluk (independent sample)
De test statistic is -10 De p-waarde is kleiner dan 0.05 (anders had de test statistic tussen en 1.96 gelegen), de nulhypothese blijkt dus niet op te gaan. -10
, de nulhypothese blijkt dus niet op te gaan")
30
Katten en geluk (independent sample)
Zijn mensen met kat gelukkiger dan mensen zonder kat? Ja, want mensen met kat scoren significant hoger op de vraag hoe gelukkig ze zijn (p < .05).
.")
31
Hoe ziet dat er uit in SPSS?
Kijk eerst bij vak Levene’s test. Als die p-waarde (onder sig.) lager is dan 0.05 dan hadden de groepen niet dezelfde standaarddeviatie en moet je in de onderste regel van de rest van de tabel kijken (equal variances not assumed). NB: merk op dat de se hetzelfde is als we hadden berekend met de formule. De test statistic wijkt af (wij kwamen op -10), maar ligt waarschijnlijk aan afronding.
 lager is dan 0.05 dan hadden de groepen niet dezelfde standaarddeviatie en moet je in de onderste regel van de rest van de tabel kijken (equal variances not assumed). NB: merk op dat de se hetzelfde is als we hadden berekend met de formule. De test statistic wijkt af (wij kwamen op -10), maar ligt waarschijnlijk aan afronding.")
32
Dus: Bij output eerst naar Levene’s test kijken: Die test of variantie van de twee groepen gelijk is Niet gelijk? Dus p < .05? Dan equal variances not assumed

33
Degrees of freedom Df bij t-toets (bij gelijke variantie): df = n1 + n2 – 2 Formule df bij ongelijke variantie is anders (GEEN tentamenstof):
: .")
34
Dependent T-test Vergelijken van groepen die afhankelijk van elkaar zijn.

35
Voorbeeld dependent t-test
Voorbeeldhypothese: Mensen die nu een kat hebben zijn gelukkiger dan toen ze nog geen kat hadden. Variabele: eerst geen kat, later wel een kat Groep 1: eerst geen kat Groep 2: later wel een kat Nulhypothese: Mensen die nu een kat hebben zijn net zo gelukkig als toen ze nog geen kat hadden.

36
Katten en geluk (paired sample)
Hierbij is µd het verschil in gemiddelde Test statistic: Hierbij: Sd is hoeveel men gemiddeld van afwijkt. Let op: dus niet s1 – s2. Sd berekent SPSS voor ons.

37
Katten en geluk (paired sample)
252 respondenten ondervraagd: In een andere tabel vind ik Sd = Formule test statistic invullen:

38
Katten en geluk (paired sample)
Aan het gemiddelde zien we dat de mensen eerst een 7.10 scoorden en toen ze een kat hadden Aan de p-waarde (<.05) zien we dat dit verschil in gemiddelde significant is. Mensen die nu een kat hebben zijn significant gelukkiger dan toen ze nog geen kat hadden (p < .05).
 zien we dat dit verschil in gemiddelde significant is. Mensen die nu een kat hebben zijn significant gelukkiger dan toen ze nog geen kat hadden (p < .05).")
39
Katten en geluk (paired sample)
Test statistic:

40
Katten en geluk (paired sample)
Df bij dependent t-test: n - 1

41
Conclusie Mensen die nu een kat hebben zijn significant gelukkiger dan toen ze nog geen kat hadden (p < .05).
.")
42
Stappenplan t-toets Bepaal of het om onafhankelijke of afhankelijke groepen gaat Benoem de Ho en Ha Bereken de test statistic Vind de p-waarde Bepaal wat je doet met H0

43
Betrouwbaarheidsintervallen
We hadden ipv de t-test ook betrouwbaarheidsintervallen kunnen maken Independent t-test:

44
CI bij independent sample
Zijn mensen met kat gelukkiger dan mensen zonder kat? (6.89 – 7.07) ± 1.96(0.018), dus ± CI95 = en Komt geen 0 in voor, dus significant verschil tussen de groepen
 ± 1.96(0.018), dus ± CI95 = en Komt geen 0 in voor, dus significant verschil tussen de groepen")
45
Wij vonden CI: en

46
Kunnen weer op 3 manieren zien dat er significant verschil tussen de groepen is: T-statistic, p-waarde en CI van het verschil

47
CI bij dependent sample
Sed is in dit geval .090 (zagen we in eerdere output). Aantal df: n – 1 = 252 – 1 = 251 Groot genoeg om voor t aan te houden Verschil in gemiddelden: .74 .74 ± 1.96(.090) CI95 = en .9164 Komt geen 0 in voor, dus significant verschil tussen groepen
. Aantal df: n – 1 = 252 – 1 = 251. Groot genoeg om voor t aan te houden. Verschil in gemiddelden: ± 1.96(.090) CI95 = en Komt geen 0 in voor, dus significant verschil tussen groepen.")
48
Confounding (achterliggende) variabelen
Stel nu dat mensen niet zozeer gelukkig worden van het hebben van een kat, maar dat er een andere reden is waarom mensen met een kat zo gelukkig zijn. Confounding variabele: variabele die zowel invloed heeft op de onafhankelijke als de afhankelijke variabele.

49
Confounder katten en geluk?
Kat (ja/nee) Geluk (op schaal van 1-10) ?
 Geluk (op schaal van 1-10)")
50
Confounder roken en gezondheid?
Roken (ja/nee) Gezondheid (op schaal van 1-10) Sporten (ja/nee)
 Gezondheid (op schaal van 1-10) Sporten (ja/nee)")
51
Controlevariabele We gaan controleren voor de variabele ‘sporten’, dat noemen we een controlevariabele. Controlevariabele: een variabele die je resultaten zou kunnen beïnvloeden, en waar je rekening mee houdt. Bedenk dit vóór aanvang van je onderzoek, zodat je het kunt meten.

52
Gemiddelde gezondheid zonder controlevariabele
Rokers Ongeveer 6.1 Niet rokers Ongeveer 6.7

53
Gemiddelde gezondheid
Als we controleren voor ‘sporten’ vinden we de volgende gemiddeldes: Hoe je dit toetst in SPSS leer je later Gemiddelde gezondheid Sport wel Sport niet Rokers 6.95 6.42 Niet rokers 7.11

54
Samenvatting Bij onafhankelijke steekproeven:
Steekproeven hebben niks met elkaar te maken We bestuderen het verschil tussen gemiddelden Bij afhankelijke steekproeven: Steekproeven hebben wel wat met elkaar te maken We bestuderen de mean difference van de gepaarde observaties

55
Vraag 1 Independent of dependent t-toets:
Eten mannen meer fruit dan vrouwen? Independent t-toets Dependent t-toets

56
Vraag 2 Independent of dependent t-toets:
Je wilt weten of relatietherapie werkt. Je ondervraagt mensen die wel therapie volgen en mensen die geen therapie volgen. Independent t-toets Dependent t-toets

57
Vraag 3 Independent of dependent t-toets :
Je wilt weten of relatietherapie werkt. Je ondervraagt koppels en meet of ze na de therapie gelukkiger zijn dan ervoor. Independent t-toets Dependent t-toets

58
Vraag 4 Zijn de jongens in mijn dataset significant ouder dan de meisjes? Ja Nee

59
Vraag 5 Zijn de respondenten meer gaan internetten in hun vrije tijd? (1 = minder dan één keer per maand, 2 = één keer per maand, 3 = één keer per week, 4 = meerdere keren per week, 5 = elke dag) Ja Nee Noot toegevoegd na college: aangezien we eenzijdig toetsen, moet de p-waarde nog wel door 2 gedeeld worden. Ook dan trekken we de conclusie dat we de nulhypothese niet kunnen verwerpen.
 Ja. Nee. Noot toegevoegd na college: aangezien we eenzijdig toetsen, moet de p-waarde nog wel door 2 gedeeld worden. Ook dan trekken we de conclusie dat we de nulhypothese niet kunnen verwerpen.")
60
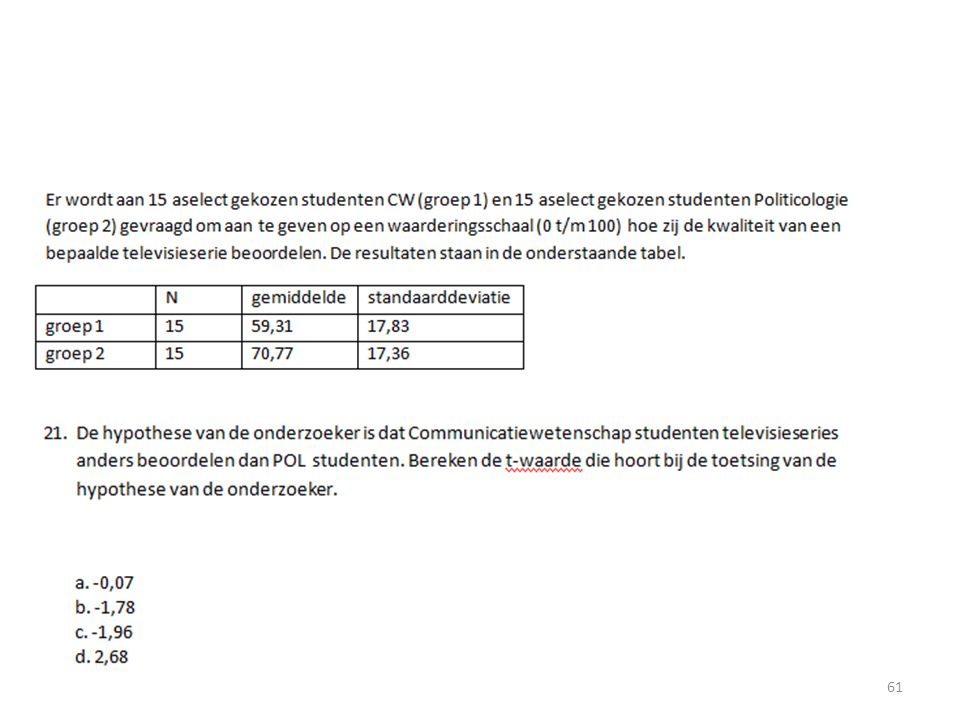
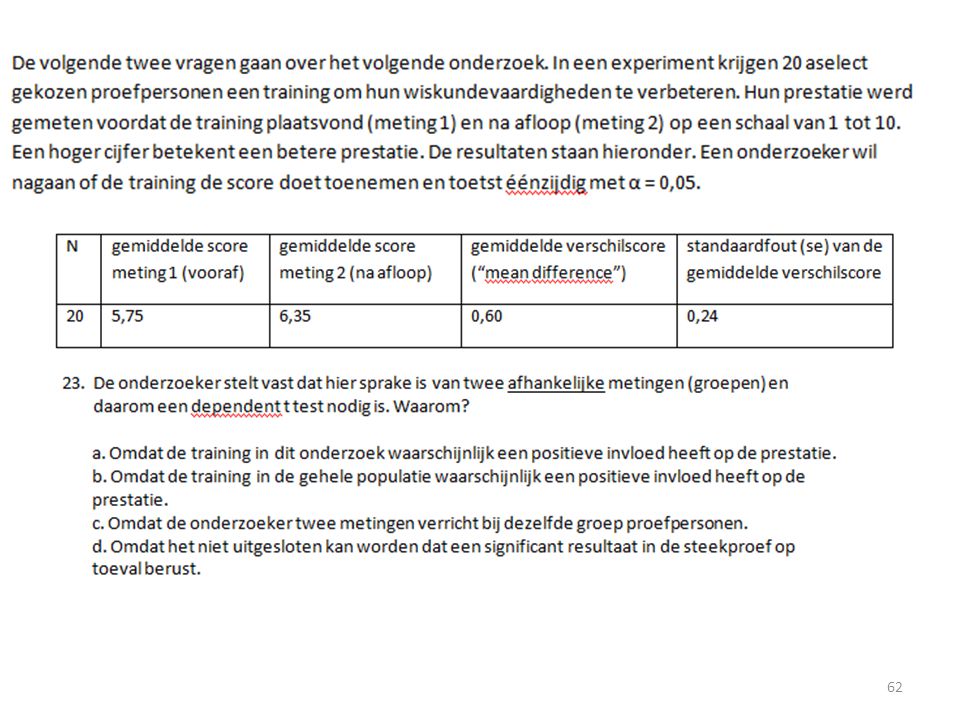
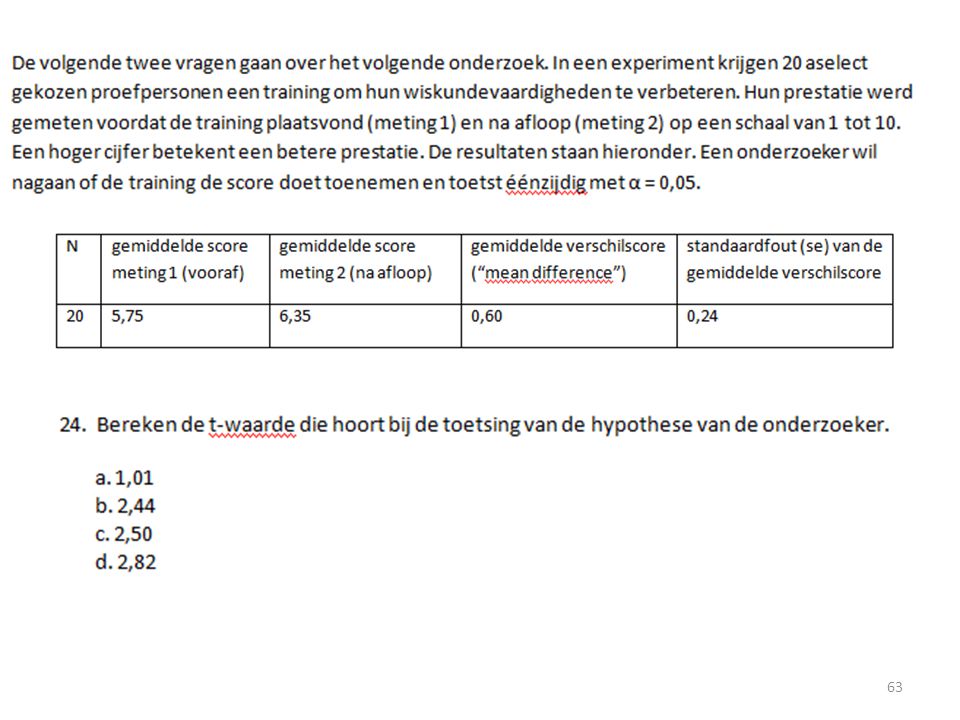
Hoe in SPSS? Independent T-test: Analyze – Compare Means – Independent T-test. De variabele die uit de 2 groepen bestaat is je grouping variable. Vul bij define groups de waarden van deze groepen in (vaak 1 en 2). De afhankelijke variabele komt in test variabele. Dependent T-test: Analyze – Compare Means – Paired Samples T-test. Dubbelklik op de variabele van de voormeting en dubbelklik daarbij op de variabele van de nameting.
. De afhankelijke variabele komt in test variabele. Dependent T-test: Analyze – Compare Means – Paired Samples T-test. Dubbelklik op de variabele van de voormeting en dubbelklik daarbij op de variabele van de nameting.")


















 Quiz Night !>")








