Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Beschrijvende en inferentiële statistiek
College 8 – Anouk den Hamer – Hoofdstuk 11 (11.5 geen tentamenstof)
")
2
Vandaag Oude tentamenvragen Chi-square toets

9
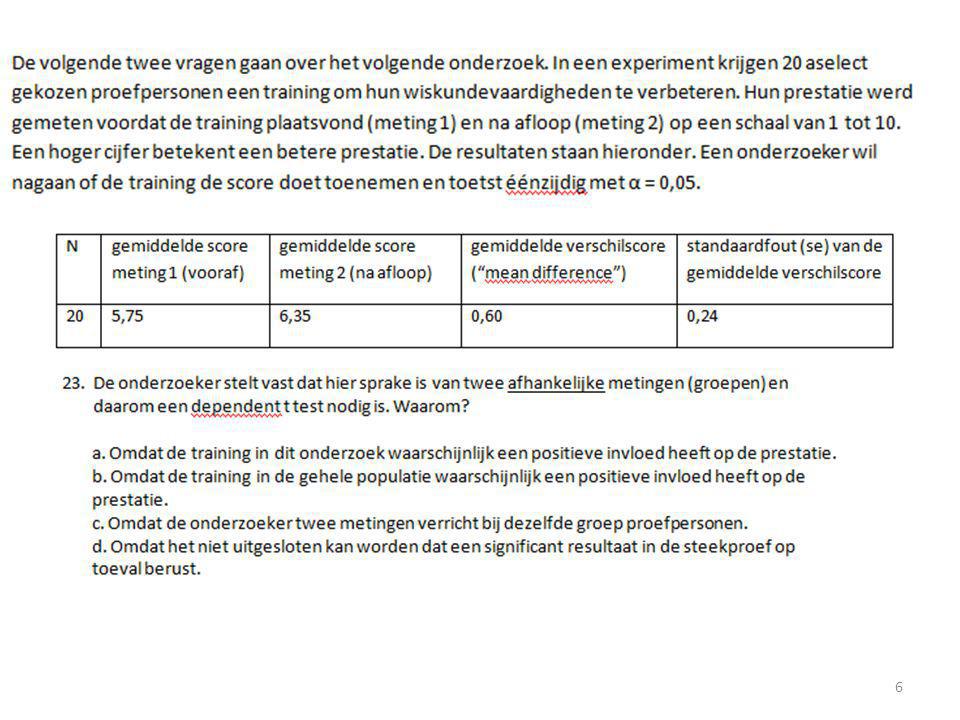
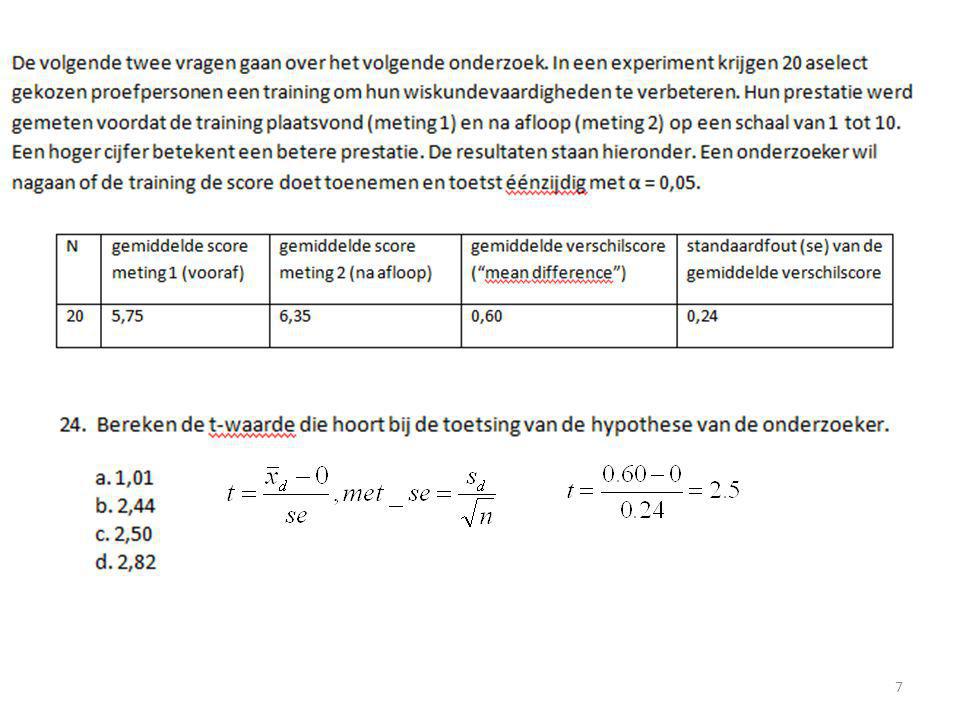
Kritieke t-waarde?

12
Vandaag Chi-square toets

13
Inferentiële statistiek: overzicht
Aantal variabelen Soort variabele(n) Betrouwbaarheidsinterval Hypothesetoets 1 Categorisch Kwantitatief 2 (of meer) Kwantitatief en 2 onafhankelijke groepen Kwantitatief en 2 afhankelijke groepen idem. - chi-kwadraat Kwantitatief of combinatie correlatie en regressie
 Betrouwbaarheidsinterval. Hypothesetoets. 1. Categorisch. Kwantitatief. 2 (of meer) Kwantitatief en 2 onafhankelijke groepen. Kwantitatief en 2 afhankelijke groepen. idem. - chi-kwadraat. Kwantitatief of combinatie. correlatie en. regressie.")
14
Chi-square toets Met een chi-square toets kun je twee of meer categorische variabelen vergelijken Categorische variabele: variabele die uit verschillende categorieën bestaat

15
Vorige keer We keken of het hebben van een kat invloed heeft op geluk.
Soort variabelen? Categorisch (wel/geen kat) en continu (geluk)
 en continu (geluk)")
16
Vandaag Twee categorische variabelen vergelijken

17
Voorbeeld vergelijken categorische variabelen
Een onderzoeker wilt weten of flirtgedrag afhankelijk is van opleidingsjaar. Zou er verschil bestaan in het flirtgedrag tussen eerste-, tweede- en derdejaars? Maw: bestaat er een associatie tussen flirtgedrag en opleidingsjaar? opleidingsjaar flirtgedrag

18
Opleidingsjaar: eerste-, tweede-, derdejaars
Flirtgedrag: nooit, zelden, af en toe, vaak, heel vaak

19
H0: opleidingsjaar heeft geen invloed op flirtgedrag
Ha: hoe hoger het opleidingsjaar, hoe meer flirtgedrag Of: H0: flirtgedrag en opleidingsjaar zijn onafhankelijk van elkaar (er bestaat geen associatie) Ha: flirtgedrag en opleidingsjaar zijn afhankelijk van elkaar (er bestaat een associatie)
 Ha: flirtgedrag en opleidingsjaar zijn afhankelijk van elkaar (er bestaat een associatie)")
20
Chi-square test Test van onafhankelijkheid: - H0 : variabelen zijn onafhankelijk - Ha : variabelen zijn afhankelijk Doel test: als de variabelen onafhankelijk zijn, hoe groot is dan de kans dat we vinden wat we vinden?

21
Om te zien of er wel of geen associatie is vergelijk je de:
Observed counts: de waardes die je vindt in je steekproef Expected counts: de waardes die je zou verwachten als de nulhypothese waar zou zijn H0: flirtgedrag en opleidingsjaar zijn onafhankelijk van elkaar (er bestaat geen associatie)
")
22
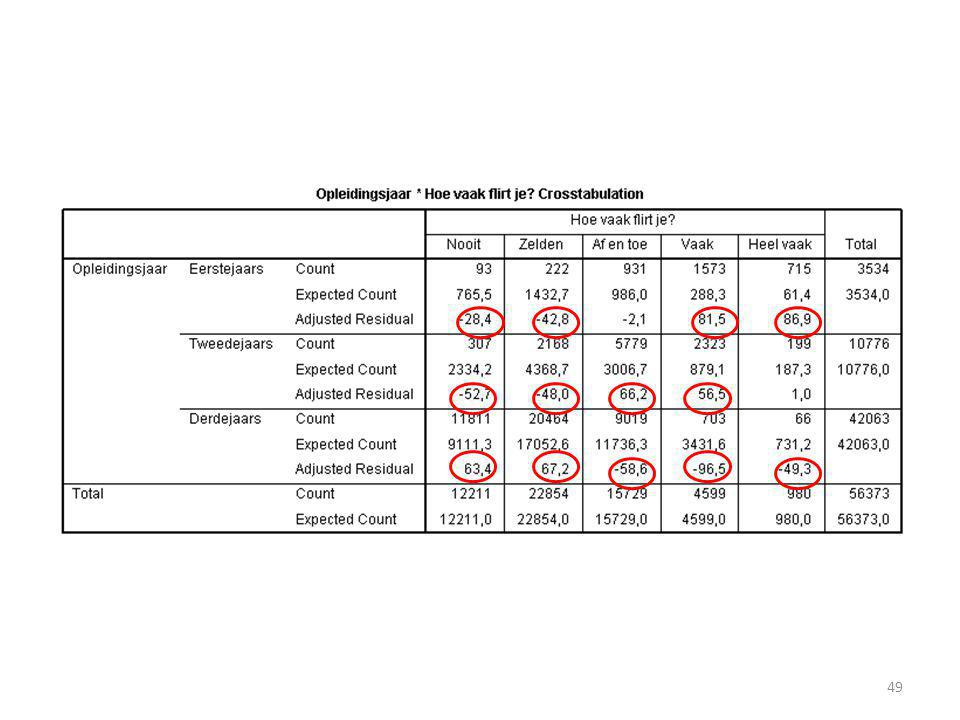
Kruistabel met observed counts

23
Kruistabel met expected count
765.5 Expected count = (rij totaal x kolom totaal) / totaal aantal respondenten Expected count eerstejaars die nooit flirten = (3534 x 12211) / = 765.5
 / totaal aantal respondenten. Expected count eerstejaars die nooit flirten = (3534 x 12211) / =")
24
Kruistabel met expected counts

25
Observed en expected counts

26
Waarom? Waarom observed en expected counts bekijken?
Als de observed counts erg afwijken van de expected counts dan zou er een associatie kunnen bestaan tussen flirtgedrag en opleidingsjaar. Associatie significant? Chi-square test.

27
Chi-square De chi-square statistic geeft aan hoe veel de observed counts van de expected counts afwijken. In SPSS vind ik dat de chi-square is. Hoe hoger de chi-square, hoe groter de kans dat er sprake is van een significante associatie

28
Observed en expected counts

29
Hoe weet je of de chi-square significant is?
Je rekent eerst de degrees of freedom (df) uit: df = (rij – 1 ) x (kolom – 1) (3 – 1) x (5 – 1) = 8
 uit: df = (rij – 1 ) x (kolom – 1) (3 – 1) x (5 – 1) = 8.")
30
Degrees of freedom Vrijheidsgraden in chi-square toets: het minimaal aantal cellen waarvan je de uitkomst moet kennen om de overige cellen te kunnen berekenen.

31
df = (rij – 1 ) x (kolom – 1) Df = (3 – 1) x (5 – 1) = 8 We moeten dus van 8 cellen de waardes weten willen we de andere cellen kunnen berekenen

32
Chi-square significant?
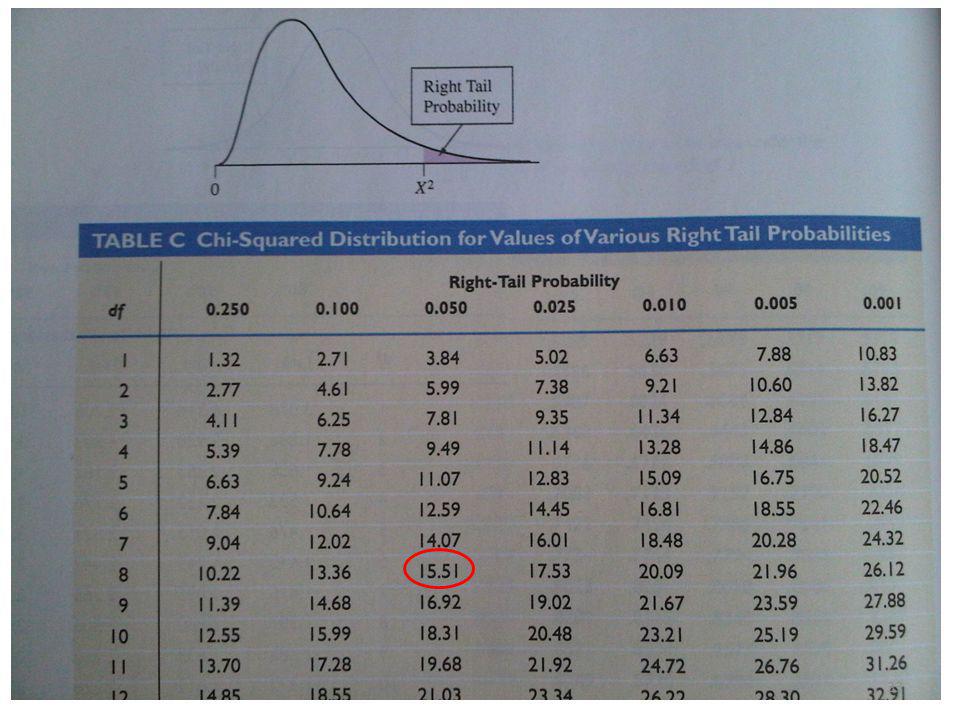
Tabel C (p. 736) In die tabel zie je welke waarde de chi-square minimaal aan moet nemen wil deze significant zijn (de kritieke waarde).
 In die tabel zie je welke waarde de chi-square minimaal aan moet nemen wil deze significant zijn (de kritieke waarde).")
34
Met df = 8 moet de chi-square minimaal 15. 51 zijn (als je met α = 0
Met df = 8 moet de chi-square minimaal zijn (als je met α = 0.05 toetst) Onze chi-square is en dus significant
 Onze chi-square is en dus significant.")
35
Dus chi-square De chi-square statistic geeft aan hoeveel de observed counts van de expected counts afwijken. Als deze significant afwijken, dan bestaat er een associatie tussen de twee variabelen. Want: dat wat je vindt in je steekproef (observed counts) is anders dan wat je op basis van de nulhypothese had verwacht (expected counts). Daardoor kun je de nulhypothese verwerpen als je een significante chi-square vindt.
 is anders dan wat je op basis van de nulhypothese had verwacht (expected counts). Daardoor kun je de nulhypothese verwerpen als je een significante chi-square vindt.")
36
Onze nulhypothese zei dat opleidingsjaar en flirtgedrag onafhankelijk van elkaar waren. Dat ze dus niks met elkaar te maken zouden hebben. Echter significante chi-square, dus nulhypothese verwerpen.

37
In SPSS Assumptie chi-square toets: iedere cel moet een expected value hebben van minimaal 5. Zo niet, dan is je steekproef te klein.

38
Conclusie voorbeeld Als flirtgedrag onafhankelijk is van opleidingsjaar, dan is het erg onwaarschijnlijk dat we een chi-square van vinden (kans namelijk kleiner dan 5%). Het flirtgedrag is inderdaad afhankelijk van het opleidingsjaar. Eerste- en tweedejaars flirten vaker dan derdejaars (dat zagen we in de tabel met de observed counts). Er bestaat dus een significante associatie tussen flirtgedrag en opleidingsjaar.
. Het flirtgedrag is inderdaad afhankelijk van het opleidingsjaar. Eerste- en tweedejaars flirten vaker dan derdejaars (dat zagen we in de tabel met de observed counts). Er bestaat dus een significante associatie tussen flirtgedrag en opleidingsjaar.")
39
Eigenschappen chi-square
Chi-square is altijd positief getal Hoe hoger de chi-square, hoe groter het bewijs tegen H0 : onafhankelijkheid De chi-square is een goodness-of-fit statistic: het geeft aan hoe goed de expected values (de H0) de observed values hebben voorspeld De laagst mogelijke waarde van chi-sqaure is 0, in dat geval zijn de observed counts en de expected counts precies gelijk.
 de observed values hebben voorspeld. De laagst mogelijke waarde van chi-sqaure is 0, in dat geval zijn de observed counts en de expected counts precies gelijk.")
40
Tabel C Hoe groter het verschil tussen de observed values en de expected values, hoe meer bewijs we hebben tegen H0. Daarom kijk je alleen naar de rechterstaart.

41
Homogeniteit De chi-square test wordt vaak “test of homogeneity” genoemd, omdat je wilt weten of de expected counts en observed counts homogeen (hetzelfde) zijn Als ze homogeen zijn dan zijn de variabelen waar je op getest hebt onafhankelijk van elkaar
 zijn. Als ze homogeen zijn dan zijn de variabelen waar je op getest hebt onafhankelijk van elkaar.")
42
Associatie Met een chi-square toets weet je of er een statistisch significante associatie is, je weet echter nog niet hoe sterk deze associatie is. Een hoge chi-square betekent niet direct een sterke associatie! Waarom? Omdat grotere steekproeven ook grotere chi-squares hebben.

43
Verschillende manieren om te zien hoe sterk de associatie is:
Kruistabel percentages Adjusted residuals Correlatie (kan alleen bij ordinale variabelen, niet bij categorische variabelen)
")
44
Eerste manier om sterkte associatie te zien: kruistabel percentages
A. Perfecte associatie Republican Democrat Total Men 100% Women 46% 54% B. Gemiddelde associatie 70% 30% 48% 52% C. Geen associatie 40% 60%

45
Is hier sprake van een sterke associatie?
Er is geen verschil tussen mannen en vrouwen in wat ze stemmen. SP VVD Totaal Mannen 65% 35% 100% Vrouwen

46
Tweede manier om sterkte associatie te zien: adjusted residuals
Met de adjusted residuals vinden we welke cellen “verantwoordelijk” zijn voor de associatie Adjusted residual: hoeveel standaardfouten de observed count van de expected count afwijkt

47
Adjusted residuals Residual: verschil tussen de observed count en de expected count, dus observed count – expected count. Standardized residual: residual / se Waarom zou je de gestandaardiseerde residual (ook wel adjusted residual genoemd) willen weten? Omdat je dan weet hoeveel standaardfouten de observed count van de expected count afwijkt en je daarmee kunt interpreteren hoe sterk de associatie in die cel is. Als de adjusted residuals groter zijn dan 3 of -3 dan is er een associatie in die cel.
 willen weten Omdat je dan weet hoeveel standaardfouten de observed count van de expected count afwijkt en je daarmee kunt interpreteren hoe sterk de associatie in die cel is. Als de adjusted residuals groter zijn dan 3 of -3 dan is er een associatie in die cel.")
48
Dus alleen bij de democraten is er een verschil tussen stemgedrag van mannen en vrouwen.
Bij de vrouwen werd er 4 se’s meer op democraten gestemd dan verwacht. En bij mannen 4 se’s minder dan verwacht. Stemgedrag is dus afhankelijk van geslacht, ook al zien we alleen een effect bij de democraten.

50
Derde manier om sterkte associatie te zien: correlatie

51
Dus: Is er een associatie? – chi-square test
Waar is de associatie? – (1e manier) procenten, maar beter nog (2e manier): adjusted residuals (ook wel standardized residuals genoemd) Hoe sterk is de associatie? – correlatie (alleen bij ordinale variabelen!)
 procenten, maar beter nog (2e manier): adjusted residuals (ook wel standardized residuals genoemd) Hoe sterk is de associatie – correlatie (alleen bij ordinale variabelen!)")
52
Kruistabel met observed counts
Marginale distributies

53
Kruistabel met observed counts
Conditionele distributie voor eerstejaars

54
Kruistabel met observed counts
Joint distribution: gezamelijke verdeling

55
Bij expected counts van de totalen is de conditionele verdeling gelijk aan de geobserveerde marginale distributie, want de conditionele verdeling wordt gemaakt o.b.v. de marginale verdeling

56
Chi-Square verdeling

57
Chi-square verdeling Test is gebaseerd op de steekproevenverdeling van de statistic. Positief. Right-skewed. Afhankelijk van degrees of freedom. Hoe meer degrees of freedom, hoe meer bell-shaped (klokvormig) de verdeling.
 de verdeling.")
58
Tabel C

60
Oefening

61
Op een rijtje Met de chi-square test toets je of twee categorische variabelen onafhankelijk zijn van elkaar (je kijkt of je nulhypothese waar zou kunnen zijn). De chi-square waarde geeft aan hoeveel de observed counts van de expected counts afwijken. De chi-square is altijd een positief getal en hoe hoger de chi-square, hoe groter de kans dat deze significant is. Bij een significante chi-square verwerpen we de nulhypothese en zijn de variabelen dus niet onafhankelijk, maar afhankelijk. Waardoor er associatie is zie je in de kruistabel: adjusted residuals. Hoe sterk de associatie is zie je (in geval van ordinale variabelen) met de correlatie.
. De chi-square waarde geeft aan hoeveel de observed counts van de expected counts afwijken. De chi-square is altijd een positief getal en hoe hoger de chi-square, hoe groter de kans dat deze significant is. Bij een significante chi-square verwerpen we de nulhypothese en zijn de variabelen dus niet onafhankelijk, maar afhankelijk. Waardoor er associatie is zie je in de kruistabel: adjusted residuals. Hoe sterk de associatie is zie je (in geval van ordinale variabelen) met de correlatie.")
62
Relative risk Inkomen en opleidingsniveau
Wat is de relative risk op lager dan gemiddeld inkomen, wanneer we < high school met college vergelijken? Proportie < high school en < gem inkomen: 222/437=0.508 Proportie college en < gem inkomen: 124/789=0.157 Relative risk: 0.508/0.157 = 3.236 Inkomen < gemiddeld gemiddeld > gemiddeld Totaal < High school 222 193 22 437 High school 578 893 264 1735 College 124 336 329 789

63
Vraag 1 Met de chi-square test toets je of continue variabelen onafhankelijk zijn van elkaar. Goed Fout

64
Vraag 2 De chi-square waarde kan zowel positief als negatief zijn.
Goed Fout

65
Vraag 3 We vonden een p-waarde van Het juiste om te doen is de nulhypothese verwerpen. Goed Fout

66
Vraag 4 Als we de nulhypothese verwerpen, dan betekent dit dat de variabelen afhankelijk zijn van elkaar. Goed Fout

67
Vraag 5 De chi-square geeft aan hoe sterk de associatie is tussen de variabelen. Goed Fout

68
Vraag 6 De adjusted residuals zijn de gestandaardiseerde residuals. Dus het verschil tussen de observed count en de expected count gedeeld door de standaarfout. Goed Fout

69
Hoe in SPSS? Analyze – Descriptive Statistics – Crosstabs. Variabele in row en variabele in colom (maakt niet uit welke waar). Bij statistics chi-square aanvinken. Bij cells observed, expected en adjusted standardized aanvinken.
. Bij statistics chi-square aanvinken. Bij cells observed, expected en adjusted standardized aanvinken.")
Verwante presentaties







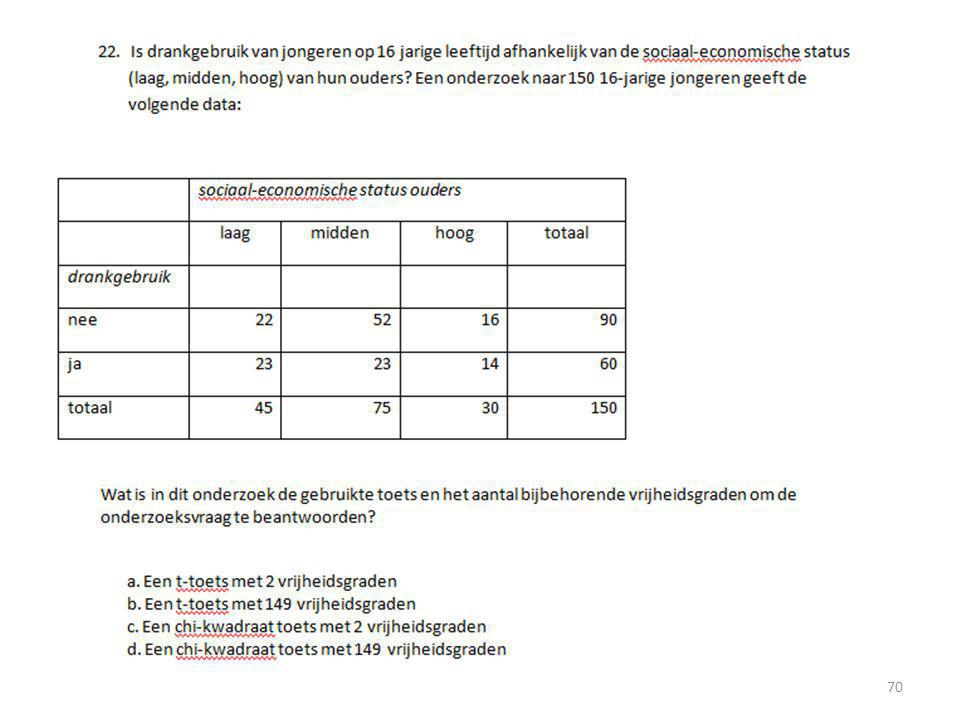
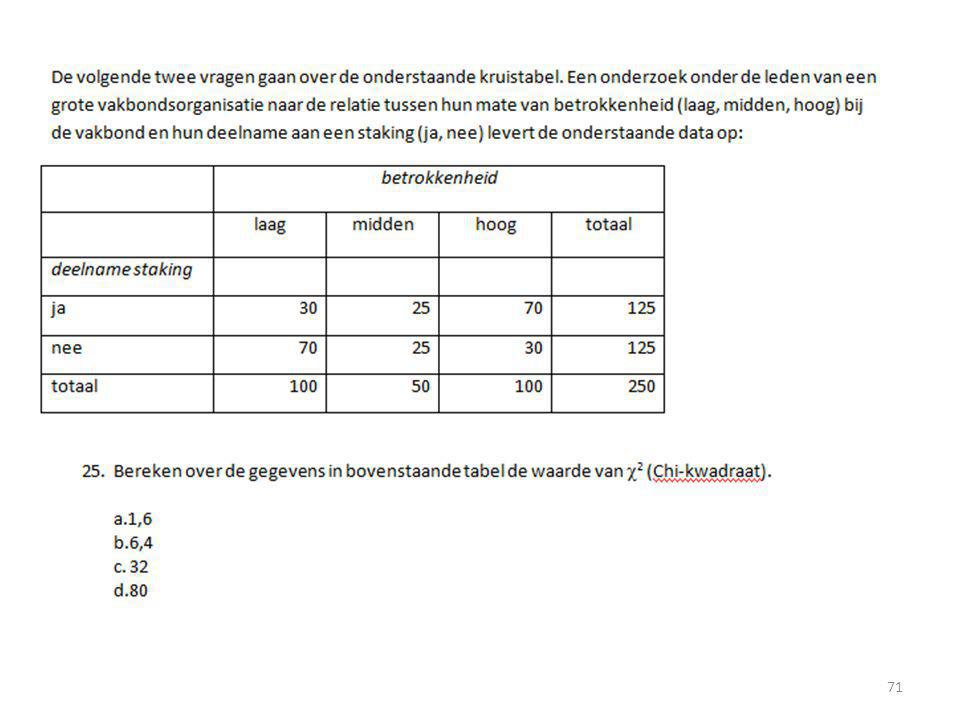



>")





 23 januari 2013 Bodegraven.>")










