Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Eric Sieverts Universiteitsbibliotheek Utrecht Instituut voor Media- & Informatiemanagement Hogeschool van Amsterdam februari 2007 Toegankelijk zijn of toegankelijk maken methoden van ontsluiting en retrieval (2)
")
2
als handmatig ontsluiten (door specialist) te duur wordt –gebruikers het werk laten doen (“social tagging”, “user generated content”) –automatisch classificeren / verrijken –retrieval i.p.v. ontsluiting Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl als handmatig ontsluiten te duur is

3
de (eind)gebruiker aan de macht? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl belangrijkste karakteristieken van WEB 2.0 : “doe het zelf” (de eindgebruiker aan de macht) samenwerking (social software, collaboration) op het terrein van inhoudelijk toegankelijk maken leidt dat tot: –tagging –social bookmarking –folksonomies –.... (d.w.z.: zelf “trefwoorden” toekennen)
 samenwerking (social software, collaboration) op het terrein van inhoudelijk toegankelijk maken leidt dat tot: –tagging –social bookmarking –folksonomies –.... (d.w.z.: zelf trefwoorden toekennen).")
4
de (eind)gebruiker aan de macht? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl bij web-2.0 diensten kan iedereen zijn eigen tags (= trefwoorden) toekennen aan: –webpagina's als bookmarks (del.icio.us, connotea, furl, citeulike, yahoo-myweb,...) om zoekmachine te "tunen" (wink, yoono,...) –foto's en video's (flickr, youtube) –blogposts (allemaal) –nieuws (digg) –....
 toekennen aan: –webpagina s als bookmarks (del.icio.us, connotea, furl, citeulike, yahoo-myweb,...) om zoekmachine te tunen (wink, yoono,...) –foto s en video s (flickr, youtube) –blogposts (allemaal) –nieuws (digg) –.....")
5
de (eind)gebruiker aan de macht? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl waarom kan tagging belangrijk worden? –iedereen bepaalt zelf hoe iets te karakteriseren ("people powered") –gebruiker kent eigen jargon het beste –gericht op samenwerking in virtuele gemeenschappen ("collaboration, sharing,...") –visualisatie van gebruikte tags met "tag clouds“ –bijna 30% van internet-gebruikers “doet er intussen aan”
 –gebruiker kent eigen jargon het beste –gericht op samenwerking in virtuele gemeenschappen ( collaboration, sharing,... ) –visualisatie van gebruikte tags met tag clouds –bijna 30% van internet-gebruikers doet er intussen aan .")
6
de (eind)gebruiker aan de macht? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl waarom is tagging (nog) niks? –geen enkele standaardisatie en controle, dus alle problemen terug die gecontroleerd vocabulair oploste –nu vooral nog voor "populaire" toepassingen (?) –tag clouds tonen alleen wat de grote massa leuk vindt; is populariteit wel maat voor relevantie of belang?
 niks. –geen enkele standaardisatie en controle, dus alle problemen terug die gecontroleerd vocabulair oploste –nu vooral nog voor populaire toepassingen ( ) –tag clouds tonen alleen wat de grote massa leuk vindt; is populariteit wel maat voor relevantie of belang .")
7
de (eind)gebruiker aan de macht? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl kan tagging toch interessant worden? –voor publiekstoepassingen is het dat al –voor professionele toepassing misschien: binnen (tijdelijke) samenwerkingsverbanden met zelfde "woordgebruik" waar recall niet zo cruciaal is als informatie-professional supervisie houdt over consistentie van gebruikte terminologie (maar staat dat niet haaks op gedachte achter tagging?) als we tags kunnen “mappen” op thesaurus (?) –en in de bibliotheek?
 samenwerkingsverbanden met zelfde woordgebruik waar recall niet zo cruciaal is als informatie-professional supervisie houdt over consistentie van gebruikte terminologie (maar staat dat niet haaks op gedachte achter tagging ) als we tags kunnen mappen op thesaurus ( ) –en in de bibliotheek .")
8
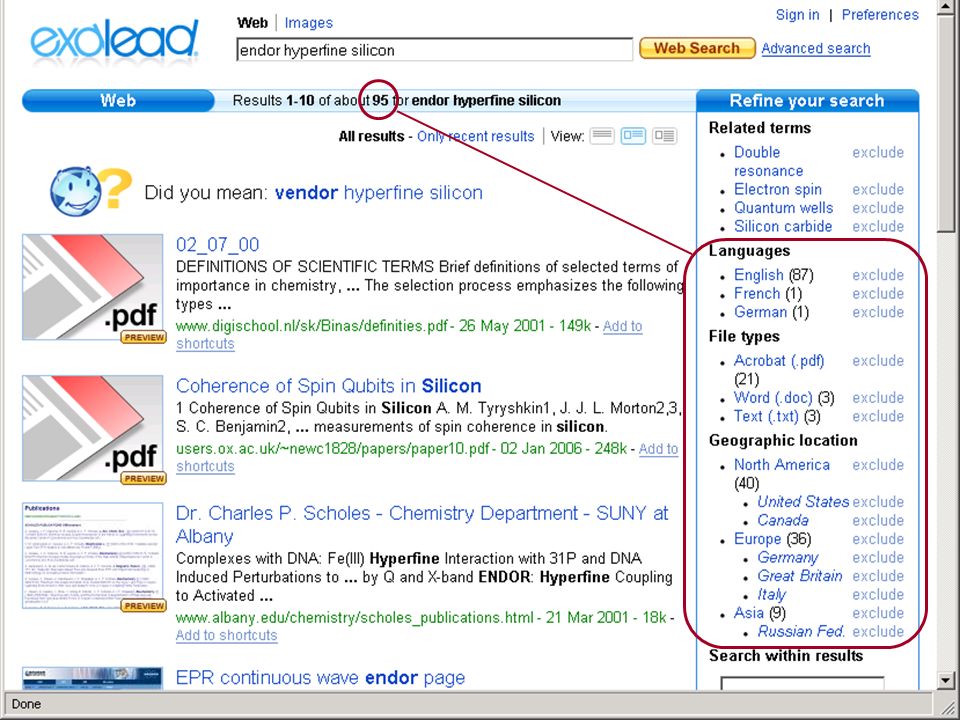
tags gesorteerd op DDC-ranges

9
web 2.0 in de bibliotheek ? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl niet alleen maar voor ontsluiting kan gebruikers bij de organisatie betrekken tags in de catalogus als aanvulling op "echte" ontsluiting? beoordelingen van boeken geo-tagging van materiaal dat daarvoor in aanmerking komt (mashup met Google Earth?)....
.....")
11
formele kenmerken –titel, auteur, uitgever, jaartal, etc. –besteladres, prijs inhoudelijke karakteristieken –trefwoorden, domein-code –“signature”: identificerende termen uit document –samenvatting oordeel (beoordelend, kwaliteit van document binnen bepaalde context) –recensie –kwalificatie in bedrijfsproces automatisch classificeren - soorten ontsluiting moeilijk zonder xml-tags gaat intussen al redelijk experimenten onderweg
 –recensie –kwalificatie in bedrijfsproces automatisch classificeren - soorten ontsluiting moeilijk zonder xml-tags gaat intussen al redelijk experimenten onderweg.")
12
automatisch classificeren - stappen in het proces meestal: systeem analyseert trainingsdocumenten systeem wordt getraind door matchen van trainingsdocumenten met “klassen” (of handmatig opstellen van kennisregels) systeem analyseert nieuwe documenten systeem matcht nieuwe documenten met “klassen” systeem moet bijleren bij probleemgevallen Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 systeem analyseert nieuwe documenten systeem matcht nieuwe documenten met klassen systeem moet bijleren bij probleemgevallen Eric Sieverts | | |")
13
automatisch classificeren technieken voor analyse van documenten statistiek van document wordt “vingerafdruk” gemaakt door extractie van meest karakteristieke woorden op basis van relatieve woordfrequenties (tf idf : term-frequentie x inverse document frequentie; in document vaker voorkomende termen die verder zeldzaam zijn) Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 Eric Sieverts | | |")
14
voorbeeld van het maken van “fingerprints” met Collexis

15
automatisch classificeren technieken voor analyse van documenten statistiek regels op basis van vaste - handmatig ingestelde - regels bepaalt de computer welke termen karakteristiek zijn voor (bepaalde aspecten van) de inhoud van een document omdat ze in de titel staan omdat ze met hoofdletters zijn geschreven omdat ze in een vastgelegd rijtje woorden voorkomen vanwege XML-tags …... Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl

16
automatisch classificeren technieken voor analyse van documenten statistiek regels taaltechnologie / linguistische analyse op basis van taalregels herkent de computer samengestelde begrippen, wat zelfstandige naamwoorden zijn, enz. vooral ten behoeve van "normalisatie”: – Morfologisch: manager, gemanaged – Compounds: hockeytoernooi, hockeystick – Syntactisch: energiebesparing, besparing van energie – Semantisch: transport, vervoer Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl

17
automatisch classificeren technieken voor analyse van documenten statistiek regels taaltechnologie / linguistische analyse in de praktijk worden meestal combinaties van deze drie basistechnieken toegepast Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl

18
automatisch classificeren - training van systeem Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl thesaurus trainingsdocumenten analyse module “vinger- afdrukken” trainings module Joop van Gent, Irion

19
automatisch classificeren - training van systeem Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl thesaurus trainingsdocumenten analyse module “vinger- afdrukken” trainings module verrijking van thesaurus Joop van Gent, Irion

20
automatisch classificeren - matchen trainingsdocument met klasse Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl handmatig (per document door “documentalist”) automatisch (op basis van al eerder aan documenten toegekende klassen; het was ooit al eens door iemand ontsloten / ingedeeld)
 automatisch (op basis van al eerder aan documenten toegekende klassen; het was ooit al eens door iemand ontsloten / ingedeeld)")
21
automatisch classificeren - vastlegging karakteristieken Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl karakteristieken voor klassen / thesaurustermen kunnen zijn vastgelegd: in “black-box” (geheel automatisch) in formele “kennis”-regels -automatisch gegenereerd, maar wel handmatig aan te passen -geheel handmatig vastgelegd
 in formele kennis -regels -automatisch gegenereerd, maar wel handmatig aan te passen -geheel handmatig vastgelegd")
22
automatisch classificeren - classificeren met systeem Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl verrijkte thesaurus nieuwe documenten analyse module “vinger- afdrukken” classificatie module verrijkte documenten Joop van Gent, Irion

23
automatisch classificeren - matchen van documenten met klassen Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl vergelijking van vingerafdruk van (nieuw) document met vingerafdrukken van alle klassen (thesaurustermen) –matching bijvoorbeeld met “vector-model” ingestelde drempelwaarden bepalen vaak –betrouwbaarheid van toekenning denk ook hier aan 80/20-achtige regel –hoeveelheid handmatig te verwerken twijfelgevallen omgekeerd evenredig met mate van betrouwbaarheid
 document met vingerafdrukken van alle klassen (thesaurustermen) –matching bijvoorbeeld met vector-model ingestelde drempelwaarden bepalen vaak –betrouwbaarheid van toekenning denk ook hier aan 80/20-achtige regel –hoeveelheid handmatig te verwerken twijfelgevallen omgekeerd evenredig met mate van betrouwbaarheid")
25
automatisch classificeren - enkele voorwaarden Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl uit ervaringen bij Irion (Joop van Gent) zijn nodig: een goede thesaurus/taxonomie, –met niet te veel categorieën (< 5000) en niet te veel lagen (< 4) (gebruik voor specifiekere begrippen full-text retrieval) –zo veel mogelijk “orthogonale” categorieën (geen overlap) –gelaagdheid in balans (klassieke modulatie-eis) een representatieve trainingsset in het juiste formaat –voldoende groot (>5 documenten per klasse) –voldoende distributief (voor elke klasse even veel documenten) –losse xml- of txt- documenten een representatieve testset
 zijn nodig: een goede thesaurus/taxonomie, –met niet te veel categorieën (< 5000) en niet te veel lagen (< 4) (gebruik voor specifiekere begrippen full-text retrieval) –zo veel mogelijk orthogonale categorieën (geen overlap) –gelaagdheid in balans (klassieke modulatie-eis) een representatieve trainingsset in het juiste formaat –voldoende groot (>5 documenten per klasse) –voldoende distributief (voor elke klasse even veel documenten) –losse xml- of txt- documenten een representatieve testset")
26
automatisch classificeren - enkele grootschalige voorbeelden Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl OCLC doet dit met DDC-codes voor classificeren van webpagina’s (in “connexion”) NorthernLicht deed dit met webpagina’s op basis van een classificatie met 16.000 onderwerpscategorieën + nog wat soorten formele categorieën, om daarmee gewone zoekresultaten in categorieën uit te splitsen Thunderstone genereert op deze wijze een webgids http://search.thunderstone.com/texis/websearch
 NorthernLicht deed dit met webpagina’s op basis van een classificatie met onderwerpscategorieën + nog wat soorten formele categorieën, om daarmee gewone zoekresultaten in categorieën uit te splitsen Thunderstone genereert op deze wijze een webgids")
27
alternatieven voor automatisch classificeren Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl als je thesaurus zo groot is dat trainen te veel werk ìs: –systeem eenvoudiger methode laten toepassen om potentiële termen te genereren als ondersteuning voor menselijke indexeerder als je (nog) geen classificatie of thesaurus hebt: –automatische clustering van hele digitale documentcollectie –(ook on-the-fly voor resultaat van webmetasearch )
 geen classificatie of thesaurus hebt: –automatische clustering van hele digitale documentcollectie –(ook on-the-fly voor resultaat van webmetasearch )")
28
retrieval en ontsluiting kunnen we niet gewoon de digitale tekst doorzoeken? (het Google-paradigma) maar: free-text zoeken impliceert allerlei zoekproblemen wat zijn die problemen? welke retrieval- en taal-technologische oplossingen zijn daar al voor? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 maar: free-text zoeken impliceert allerlei zoekproblemen wat zijn die problemen. welke retrieval- en taal-technologische oplossingen zijn daar al voor. Eric Sieverts | | |")
29
waarin uiten zoekproblemen zich? (in variabele mate in uiteenlopende soorten systemen - bibliografische databases, full-text bestanden, het web, … ) –onvoldoende recall met zoekvraag mis je te veel relevante informatie –onvoldoende precisie zoekvraag levert (te) veel niet-relevante informatie Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 –onvoldoende recall met zoekvraag mis je te veel relevante informatie –onvoldoende precisie zoekvraag levert (te) veel niet-relevante informatie Eric Sieverts | | |")
30
oorzaken voor lage recall (recall-killers) inherent aan free-text zoeken in documenten: variatie in gebruikte woorden (spelling, woordvorm, taal) in tekst staan synoniemen, impliciete aanduidingen, … variëteit aan woorden voor generieke begrippen term-armoede van documenten (catalogus) zoeker "doet het fout": verkeerde zoekterm (spelling, betekenis) te weinig varianten met OR gecombineerd te veel zoek-elementen met AND gecombineerd Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 inherent aan free-text zoeken in documenten: variatie in gebruikte woorden (spelling, woordvorm, taal) in tekst staan synoniemen, impliciete aanduidingen, … variëteit aan woorden voor generieke begrippen term-armoede van documenten (catalogus) zoeker doet het fout : verkeerde zoekterm (spelling, betekenis) te weinig varianten met OR gecombineerd te veel zoek-elementen met AND gecombineerd Eric Sieverts | | |")
31
oorzaken voor lage precisie (precisie-killers) inherent aan free-text zoeken in documenten : verkeerde relatie tussen ge-AND-e termen niet eenduidige betekenis (homoniemen, acroniemen) term-rijkdom van full-text documenten (laag term-gewicht) zoeker "doet het fout" : verkeerde zoekterm (betekenis, te algemeen) te weinig concepten met AND gecombineerd Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 inherent aan free-text zoeken in documenten : verkeerde relatie tussen ge-AND-e termen niet eenduidige betekenis (homoniemen, acroniemen) term-rijkdom van full-text documenten (laag term-gewicht) zoeker doet het fout : verkeerde zoekterm (betekenis, te algemeen) te weinig concepten met AND gecombineerd Eric Sieverts | | |")
32
klassieke oplossing redenen waarom we verwachten dat gebruik van taxonomie of thesaurus een oplossing biedt –formaliseert betekenissen –uniformeert term-rijkdom (dus term-gewicht) –legt semantische relaties tussen onderwerpen/termen –kan syntactisch verband leggen tussen facetten van onderwerp (precoördinatie) Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 –legt semantische relaties tussen onderwerpen/termen –kan syntactisch verband leggen tussen facetten van onderwerp (precoördinatie) Eric Sieverts | | |")
33
nadelen van klassieke oplossing gebrek aan flexibiliteit (schrik van de gebruiker/vakspecialist, maar niet meer bij folksonomy / tagging) je moet (kunstmatige) informatietaal gebruiken (schrik van de ergonoom, maar daar zijn wel oplossingen voor) duur omdat mensen termen moeten toekennen (schrik van de manager, en ook automatische toekenning vergt nog veel handwerk) Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 je moet (kunstmatige) informatietaal gebruiken (schrik van de ergonoom, maar daar zijn wel oplossingen voor) duur omdat mensen termen moeten toekennen (schrik van de manager, en ook automatische toekenning vergt nog veel handwerk) Eric Sieverts | | |")
34
(taal)technologische alternatieven best-match zoeken met relevantie-ordening truncatie, woordstemming, fuzzy search semantische kennis toevoegen zoekresultaat in "domeinen/contexten” laten clusteren genereren van suggesties voor aanvullende zoektermen terugkoppeling van zoekersoordeel Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
technologische alternatieven best-match zoeken met relevantie-ordening truncatie, woordstemming, fuzzy search semantische kennis toevoegen zoekresultaat in domeinen/contexten laten clusteren genereren van suggesties voor aanvullende zoektermen terugkoppeling van zoekersoordeel Eric Sieverts | | |")
35
relevance ranking factoren Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl 1.meer van de gevraagde termen in een document 2.gevraagde termen op belangrijke plek in document (titel, koppen, eerste paar regels, ….) 3.gevraagde termen komen in document herhaald voor 4.gevraagde termen staan in document dicht bij elkaar 5.termen in document staan in zelfde volgorde als in vraag 6.zeldzame termen krijgen zwaarder gewicht dan algemene 7.hoeveelheid hyperlinks die naar document verwijst 8.hoe vaak een document wordt "bezocht" google bewijst dat dat op het web goed werkt, maar ook op een intranet?
 3.gevraagde termen komen in document herhaald voor 4.gevraagde termen staan in document dicht bij elkaar 5.termen in document staan in zelfde volgorde als in vraag 6.zeldzame termen krijgen zwaarder gewicht dan algemene 7.hoeveelheid hyperlinks die naar document verwijst 8.hoe vaak een document wordt bezocht google bewijst dat dat op het web goed werkt, maar ook op een intranet")
36
relevance ranking factoren Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl 1.meer termen 2.termen in titel/kop/begin 3.termen herhaald 4.termen dicht bij elkaar 5.termen in volgorde 6.zeldzame termen zwaarder 7.hyperlinks naar document 8.bezoek aan document meer concepten ge-AND hoger term-gewicht juiste verband belang specifieke term (kwaliteit) [alleen als er links zijn] (kwaliteit)
![relevance ranking factoren Eric Sieverts | | | 1.meer termen 2.termen in titel/kop/begin 3.termen herhaald 4.termen dicht bij elkaar 5.termen in volgorde 6.zeldzame termen zwaarder 7.hyperlinks naar document 8.bezoek aan document meer concepten ge-AND hoger term-gewicht juiste verband belang specifieke term (kwaliteit) [alleen als er links zijn] (kwaliteit)](http://images.slideplayer.nl/26/8863082/slides/slide_36.jpg "relevance ranking factoren Eric Sieverts | | | 1.meer termen 2.termen in titel/kop/begin 3.termen herhaald 4.termen dicht bij elkaar 5.termen in volgorde 6.zeldzame termen zwaarder 7.hyperlinks naar document 8.bezoek aan document meer concepten ge-AND hoger term-gewicht juiste verband belang specifieke term (kwaliteit) [alleen als er links zijn] (kwaliteit)")
37
relevance ranking factoren Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl 1.meer van de gevraagde termen in een document 2.gevraagde termen op belangrijke plek in document (titel, koppen, eerste paar regels, ….) 3.gevraagde termen komen in document herhaald voor 4.gevraagde termen staan in document dicht bij elkaar 5.termen in document staan in zelfde volgorde als in vraag 6.zeldzame termen krijgen zwaarder gewicht dan algemene 7.hoeveelheid hyperlinks die naar document verwijst 8.hoe vaak een document wordt "bezocht" allemaal gericht op hogere relevantie voor "de eerste tien", dus op precisie
 3.gevraagde termen komen in document herhaald voor 4.gevraagde termen staan in document dicht bij elkaar 5.termen in document staan in zelfde volgorde als in vraag 6.zeldzame termen krijgen zwaarder gewicht dan algemene 7.hoeveelheid hyperlinks die naar document verwijst 8.hoe vaak een document wordt bezocht allemaal gericht op hogere relevantie voor de eerste tien , dus op precisie")
38
trunkatie / stemming / fuzzy zoeken trunceren computer computeronderwijs stemming computer computing, computation, computers communism community, communication ?? sieverts sievert?? fuzzy duivendak duijvendak serajevo sarajevo chebychev chebyshev, chebyschef, kok kop, kak,... ?? Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl

39
trunkatie / stemming / fuzzy zoeken Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl trunceren computer computeronderwijs stemming computer computing, computation, computers communism community, communication ?? sieverts sievert?? fuzzy duivendak duijvendak serajevo sarajevo chebychev chebyshev, chebyschef, kok kop, kak,... ?? compenseert variatie in woordvorm & spelling betere recall maar pas op voor ongewenste effecten !!

40
semantische kennis toevoegen in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen (woorden binnen bepaalde "semantische afstand" van zoekwoord) Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl bijvoorbeeld: irion-21
 door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen (woorden binnen bepaalde semantische afstand van zoekwoord) Eric Sieverts | | | bijvoorbeeld: irion-21")
41
visualisatie van “wordnet”

42
semantische kennis Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen verbeteren van precisie verbeteren van recall maar semantisch netwerk voor specialistisch domein moet je zelf nog bouwen !
 door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen verbeteren van precisie verbeteren van recall maar semantisch netwerk voor specialistisch domein moet je zelf nog bouwen !")
43
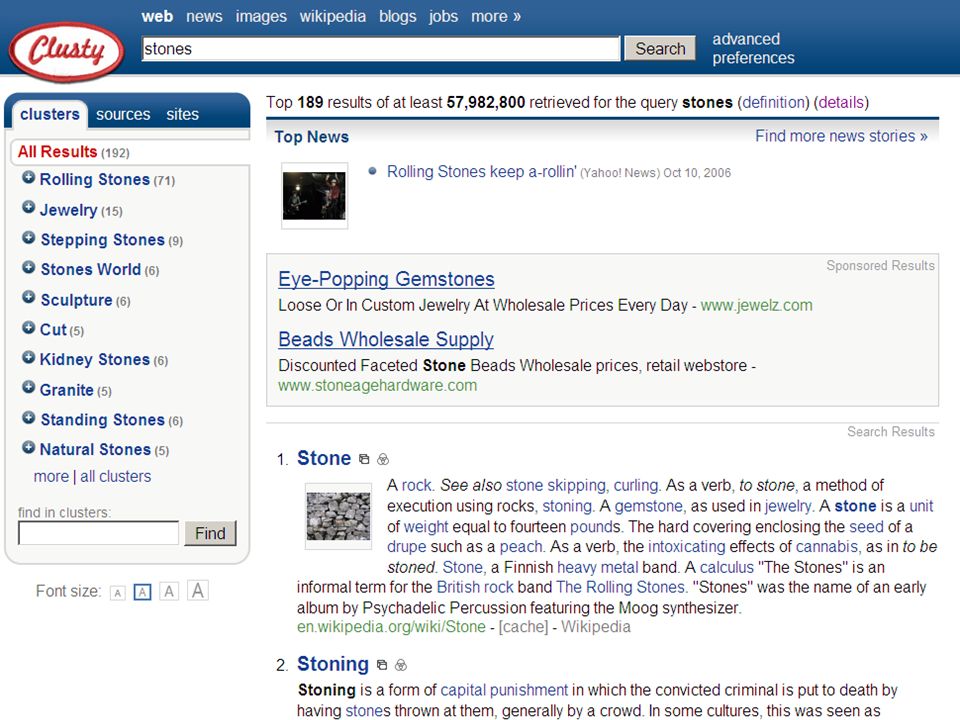
automatisch clusteren/classificeren op grond van kennisregels (en bestaande “taxonomie”) in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen op grond van statistiek of patronen –Ask, Clusty, Quintura, Collarity, …. –Autonomy Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl

48
automatisch clusteren/classificeren Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl op grond van kennisregels (en bestaande “taxonomie”) in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen op grond van statistiek of patronen –Ask, Clusty, Quintura, Collarity, …. –Autonomy kiezen van juiste betekenis of context betere precisie werkt niet gegarandeerd altijd goed

49
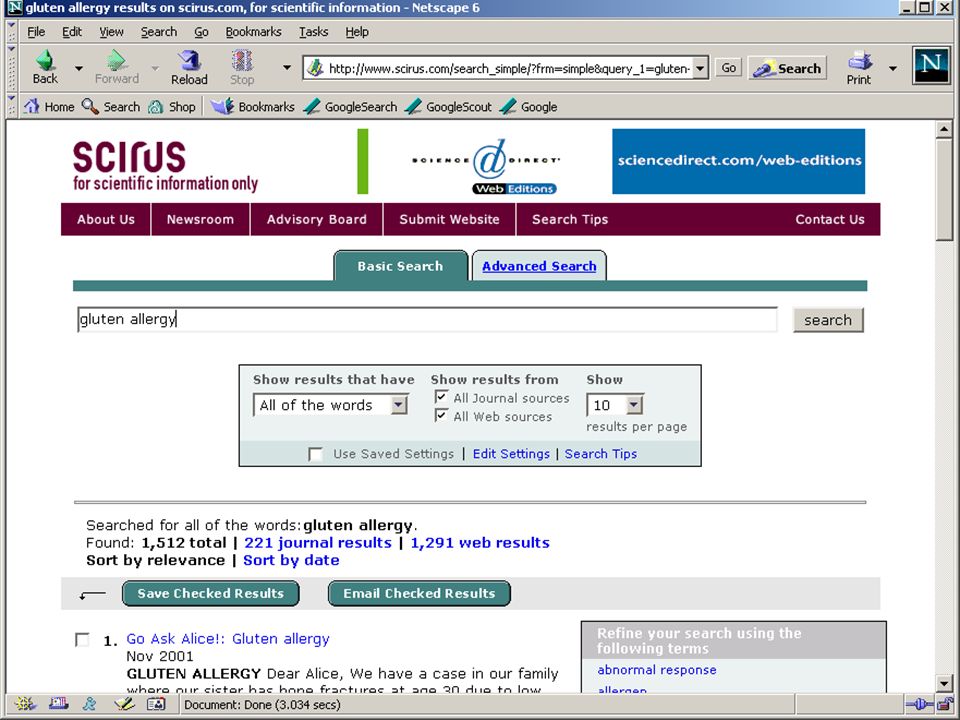
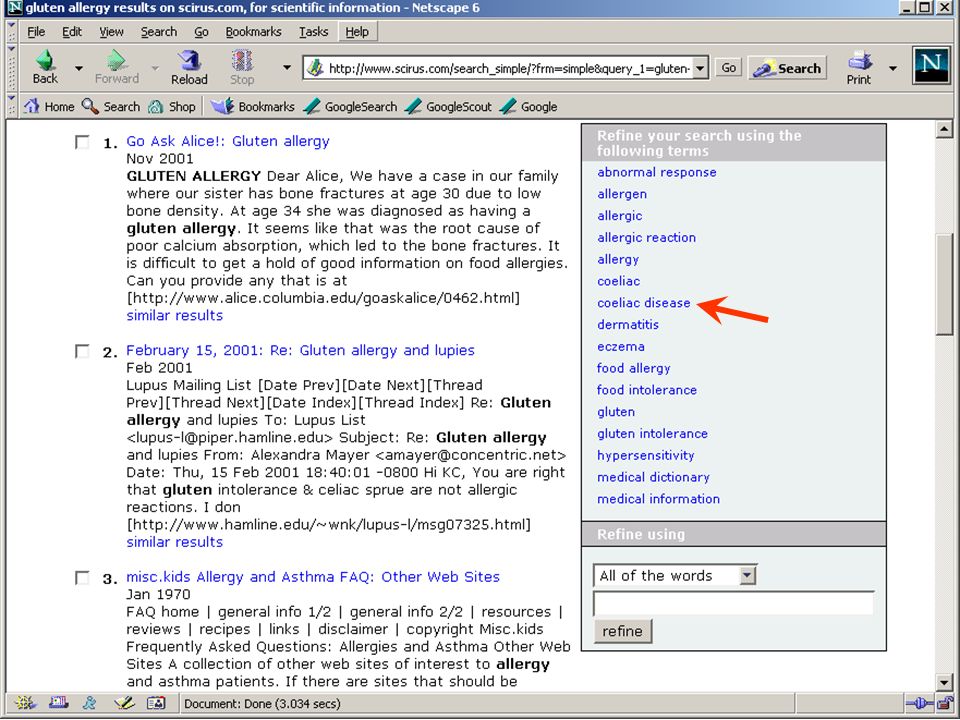
termen extraheren computer haalt karakteristieke (andere) woorden/begrippen uit eerste N zoekresultaten (statistiek - tf idf) –gebruiker kiest daaruit termen om de zoekactie in te perken of uit te breiden bijv.: Scirus database van Elsevier Aquabrowser (o.a. bij Bibliotheek.nl) Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 Eric Sieverts | | |")
52
OR

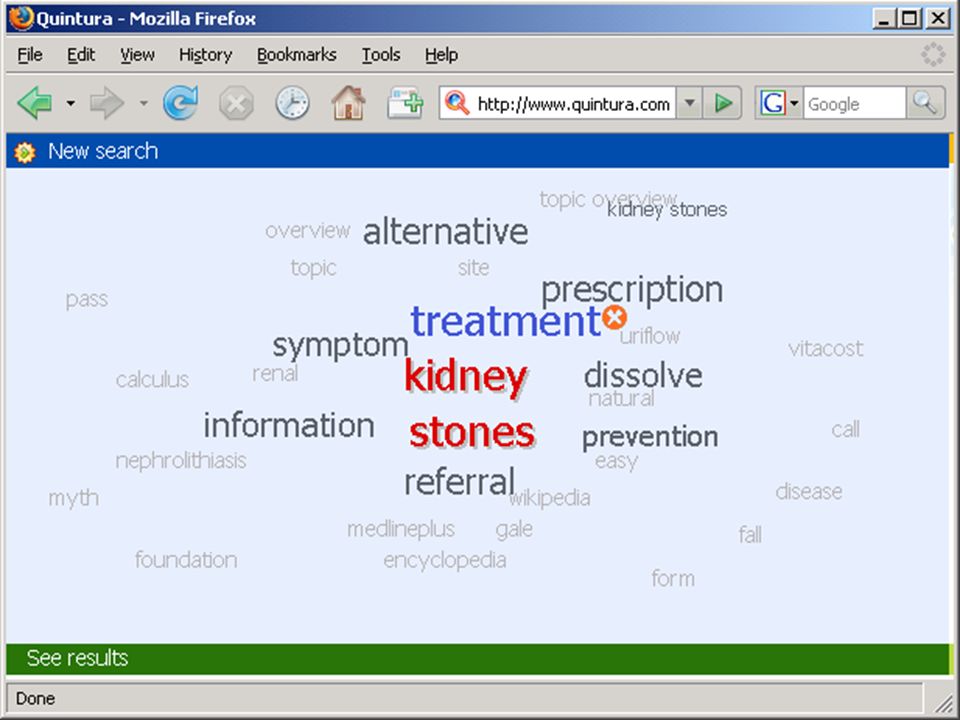
53
wolk van termen in Aquabrowser: die termen kunnen uit statistische analyse, woordenlijst, thesaurus, semantisch netwerk o.i.d. komen

55
termen extraheren Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl computer haalt karakteristieke (andere) woorden/begrippen uit eerste N zoekresultaten (statistiek - tf idf) –gebruiker kiest daaruit termen om de zoekactie in te perken of uit te breiden bijv.: Scirus database van Elsevier Aquabrowser (o.a. bij Bibliotheek.nl) inperken op juiste betekenis of context verbetert precisie uitbreiden met meer “synoniemen” verbetert recall
 inperken op juiste betekenis of context verbetert precisie uitbreiden met meer synoniemen verbetert recall.")
56
terugkoppeling gebruiker klikt bij relevante hit op “more like this” –computer zoekt naar daarop lijkende documenten, op grond van in document aanwezige termen of patronen (bijvoorbeeld linking-patroon bij Google) bijv.:Scirus, Google Autonomy Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 bijv.:Scirus, Google Autonomy Eric Sieverts | | |")
57
terugkoppeling gebruiker markeert relevante hits systeem houdt bij welke resultaten door gebruiker worden bekeken –zoektermen of patronen die in die documenten voorkomen krijgen hoger gewicht bij toekomstige zoekacties krijgen documenten met die termen of patronen een hogere berekende relevantie bijv.: Autonomy Google (sinds kort) Eric Sieverts | e.sieverts@library.uu.nl | http://www.library.uu.nl/medew/it/eric | e.g.sieverts@hva.nl
 Eric Sieverts | | |")
Verwante presentaties





>")

 Module 4 College “Big Picture” Universiteitsbibliotheek UM 2002, 10 juni.>")











