Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
zoeken en ontsluiten in de wereld van Google
Eric Sieverts Universiteitsbibliotheek Utrecht Instituut voor Media- en Informatie Management (Hogeschool van Amsterdam)
")
2
zoeken en ontsluiten in de wereld van Google
agenda: zoeken en ontsluiting ontsluiting en metadata metadata en zoeken zoeken en taaltechnologie taaltechnologie en ontsluiting ontsluiting, taxonomieën en ontologieën ontologieën, metadata en semantisch web Eric Sieverts | | |

3
voor het zoeken naar informatie
basis-paradigma voor het zoeken naar informatie zoeker / zoekvraag documenten zoek, zoek, zoek, match Eric Sieverts | | |

4
klassieke situatie bij ontsluiting
zoek, zoek, zoek, match klassieke situatie bij ontsluiting zoeker moet proberen "termen" te bedenken waar onderwerp mee is ontsloten ontsluiting: indexeerder moet correcte termen aan document toekennen in principe perfecte match mogelijk Eric Sieverts | | |

5
klassieke ontsluiting
gebruikersonvriendelijk dat zoeker zelf correcte termen moet ontdekken duur dat indexeerders documenten moeten analyseren om correcte termen te kunnen toekennen en die perfecte match valt in de praktijk vaak ook nog wel tegen Eric Sieverts | | |

6
match zoeken in de wereld van zoek, zoek, zoek, ......
zoeker tikt maar wat woorden in (en meestal zelfs maar één woord) zoeksysteem bevat alleen de woorden uit de documenten zelf je vindt vaak niet (alles) wat je zoekt - toch tevreden ? Eric Sieverts | | |
 zoeksysteem bevat alleen de woorden uit de documenten zelf. je vindt vaak niet. (alles) wat je zoekt. - toch tevreden Eric Sieverts | | |")
7
zoeken in de wereld van zoeker mist relevante informatie (recall-probleem) door: afwijkende spelling en woordvormen gebruik van synoniemen en andere talen aanwezigheid specifiekere begrippen .... zoeker vindt niet-relevante informatie (precisie-probleem) door: onvoldoende gespecificeerde vraag ontbrekende / onjuiste verbanden tussen zoektermen woorden die meer betekenissen kunnen hebben Eric Sieverts | | |
 door: onvoldoende gespecificeerde vraag. ontbrekende / onjuiste verbanden tussen zoektermen. woorden die meer betekenissen kunnen hebben. Eric Sieverts | | |")
8
waarom toch tevreden gebruikers ?
zoeksysteem ziet er zo lekker (simpel) uit zoeker vindt altijd wel wat (in 8 miljard webpagina's) slimme ordening van resultaten, zodat bij meeste vragen voor meerderheid van gebruikers altijd wel iets relevants bij de eerste 10 zit who cares about lousy recall & precision ? Eric Sieverts | | |
 uit. zoeker vindt altijd wel wat (in 8 miljard webpagina s) slimme ordening van resultaten, zodat bij meeste vragen. voor meerderheid van gebruikers. altijd wel iets relevants bij de eerste 10 zit. who cares about lousy recall & precision Eric Sieverts | | |")
9
wil gebruiker nog iets anders ?
zelfs wetenschappelijke bibliotheken moeten hun best doen gebruikers nog iets anders te laten gebruiken dan alleen Google of Google Scholar : dat andere, professionele systemen zeer verantwoorde gecontroleerde ontsluiting bieden, is niet meer genoeg je moet net zo simpel (en kaal?) interface bieden + one-stop shopping + direct de full-text resultaten zelf Eric Sieverts | | |
 interface bieden. + one-stop shopping. + direct de full-text resultaten zelf. Eric Sieverts | | |")
10
how about metadata ? iedereen heeft het over metadata:
"gegevens over gegevens" zowel inhoudelijke als formele ontsluiting html biedt metatags <meta name="keyword" content="retrieval"> <meta name="creator" content="eric sieverts"> in bibliotheekwereld: "dublin core" als standaardisatie afgesproken Eric Sieverts | | |

11
dublin core standaard afspraken over gebruik van "Dublin Core" ( ) met 15 "velden" voor formele en inhoudelijke elementen, voortkomend uit, maar ook geadopteerd buiten bibliotheekwereld inhoudelijk (onderwerp) formeel (inhoud) formeel (intellectueel eigendom) formeel (fysieke weergave) title source creator date subject language publisher type description relation contributor format coverage rights identifier intussen nog 3 aanvullingen: audience, provenance, rightsHolder voorbeelden: <META NAME="DC.Creator" CONTENT="Eric Sieverts"> <META NAME="DC.Subject" CONTENT="metadata"> <META NAME="DC.Type" CONTENT="text/html"> Eric Sieverts | | |
 formeel (inhoud) formeel (intellectueel eigendom) formeel (fysieke weergave) title. source. creator. date. subject. language. publisher. type. description. relation. contributor. format. coverage. rights. identifier. intussen nog 3 aanvullingen: audience, provenance, rightsHolder. voorbeelden: <META NAME= DC.Creator CONTENT= Eric Sieverts > <META NAME= DC.Subject CONTENT= metadata > <META NAME= DC.Type CONTENT= text/html > Eric Sieverts | | |")
12
dublin core - verfijningen
verfijningen van syntax en semantiek van "velden" via qualificaties/subelementen van Dublin Core bij "coverage": specificatie of het plaats- of tijd-aanduiding is <META NAME="DC.Coverage.Spatial" CONTENT="Frankrijk"> <META NAME="DC.Coverage.Temporal" CONTENT="1914"> bij "relation": specificatie van aard van relatie tussen bij elkaar horende webpagina's (of andere objecten) <META NAME="DC.Relation.IsPartOf" CONTENT="......"> <META NAME="DC.Relation.HasPart" CONTENT="......"> <META NAME="DC.Relation.IsVersionOf" CONTENT="......"> <META NAME="DC.Relation.HasVersion" CONTENT="......"> Eric Sieverts | | |
 <META NAME= DC.Relation.IsPartOf CONTENT= > <META NAME= DC.Relation.HasPart CONTENT= > <META NAME= DC.Relation.IsVersionOf CONTENT= > <META NAME= DC.Relation.HasVersion CONTENT= > Eric Sieverts | | |")
13
dublin core - inhoud voor semantiek van metadata-inhoud:
daarvoor wordt geen standaardisatie opgelegd !! wel gebruikte standaard vermelden (in "scheme"-attribuut) voorbeelden <META NAME="DC.Date" CONTENT=" " SCHEME="ISO8601"> <META NAME="DC.Subject" CONTENT="567.2" SCHEME="SISO"> <META NAME="DC.Subject" CONTENT="hay fever" SCHEME="MeSH"> <META NAME="DC.Language" CONTENT="nl" SCHEME="ISO639-1"> <META NAME="DC.Source" CONTENT=" " SCHEME="ISBN"> Eric Sieverts | | |
 voorbeelden. <META NAME= DC.Date CONTENT= SCHEME= ISO8601 > <META NAME= DC.Subject CONTENT= SCHEME= SISO > <META NAME= DC.Subject CONTENT= hay fever SCHEME= MeSH > <META NAME= DC.Language CONTENT= nl SCHEME= ISO639-1 > <META NAME= DC.Source CONTENT= SCHEME= ISBN > Eric Sieverts | | |")
14
metadata & zoekmachines ?
zoek, zoek, zoek, match metadata & zoekmachines ? gebruiker kent geen metadata-standaarden google indexeert geen metadata op het vrije web heb je (bijna) niets aan metadata Eric Sieverts | | |
 niets. aan metadata. Eric Sieverts | | |")
15
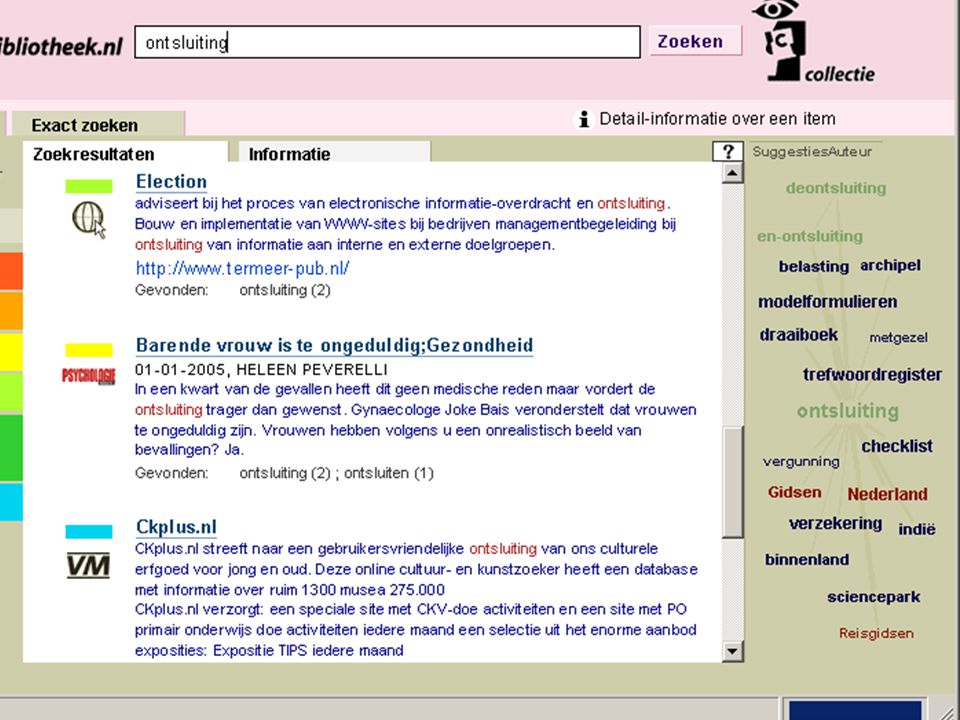
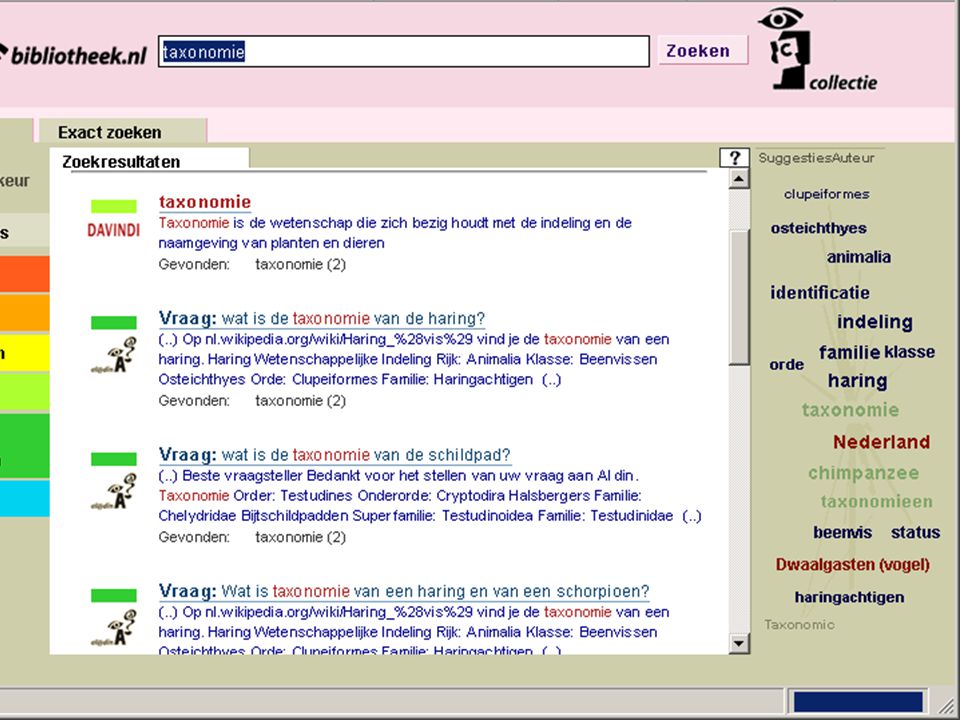
hoezo dan metadata ? eigenlijk alleen voor lokaal of specialistisch gebruik voorbeeld: Open Archive Initiative gebruikt Dublin Core (in XML) om beschrijvingen uit elkaars document-archieven (repositories) te kunnen uitwisselen en (her)gebruiken, zoals in OAIster zoekmachine Dublin Core gaat niet verder dan "veld"-specificaties en -syntax (simpeler dan ISBD, MARC of AACR2) zelfs lokaal vaak nog geen standaardisatie van daarbinnen gebruikt ontsluitingssysteem maar in het semantisch web wil men wel metadata kunnen gebruiken ! ! Eric Sieverts | | |
 om beschrijvingen uit elkaars document-archieven (repositories) te kunnen uitwisselen en (her)gebruiken, zoals in OAIster zoekmachine. Dublin Core gaat niet verder dan veld -specificaties en -syntax (simpeler dan ISBD, MARC of AACR2) zelfs lokaal vaak nog geen standaardisatie van daarbinnen gebruikt ontsluitingssysteem. maar in het semantisch web wil men wel metadata kunnen gebruiken ! ! Eric Sieverts | | |")
17
taaltechnologie bij zoeker
zoek, zoek, zoek, match taaltechnologie bij zoeker simpele zoekvraag automatisch geëxpandeerd en gedisambigueerd door ontologie of semantisch netwerk zoeksysteem bevat alleen de woorden uit de documenten zelf door verbeterde zoekvraag een beter antwoord ? Eric Sieverts | | |

18
taaltechnologie voor betere "query"
door "word stemming" en "fuzzy zoeken" automatisch op meer woordvormen gezocht >> betere recall semantisch netwerk (of ontologie) bevat relaties tussen begrippen waardoor inhoudelijk verwante termen aan vraag kunnen worden toegevoegd >> betere recall bij woord met meer betekenissen, bevat semantisch netwerk (of ontologie) verschillende relaties voor verschillende betekenissen >> disambigueren >> betere precisie geleerden zijn het er nog niet over eens hoeveel dit verbetert Eric Sieverts | | |
 bevat relaties tussen begrippen waardoor inhoudelijk verwante termen aan vraag kunnen worden toegevoegd >> betere recall. bij woord met meer betekenissen, bevat semantisch netwerk (of ontologie) verschillende relaties voor verschillende betekenissen >> disambigueren >> betere precisie. geleerden zijn het er nog niet over eens hoeveel dit verbetert. Eric Sieverts | | |")
19
taaltechnologie bij zoeker
zoek, zoek, zoek, match taaltechnologie bij zoeker uit resultaat van simpele zoekvraag gegenereerde specifiekere termen worden zoeker ter keuze voorgelegd zoeksysteem bevat alleen de woorden uit de documenten zelf doordat zoeker vraag verbetert, beter antwoord ? Eric Sieverts | | |

20
taaltechnologie voor betere "query"
door statistische analyse van zoekresultaat, genereert software lijstje mogelijke specifieke(re) zoektermen, waarmee gebruiker naar eigen inzicht zoekvraag kan verfijnen (of anderszins verbeteren) zulke woorden kunnen ook uit woordenlijstje, thesaurus, semantisch netwerk e.d. worden afgeleid meestal >> betere precisie Eric Sieverts | | |
 zoektermen, waarmee gebruiker naar eigen inzicht zoekvraag kan verfijnen (of anderszins verbeteren) zulke woorden kunnen ook uit woordenlijstje, thesaurus, semantisch netwerk e.d. worden afgeleid. meestal >> betere precisie. Eric Sieverts | | |")
24
taaltechnologie bij zoeker
zoek, zoek, zoek, match taaltechnologie bij zoeker simpele zoekvraag automatisch vertaald naar "correcte" zoektermen documenten ontsloten: er zijn "correcte" termen aan toegekend in principe perfecte match mogelijk Eric Sieverts | | |

25
zoekvraag vertalen naar juiste term
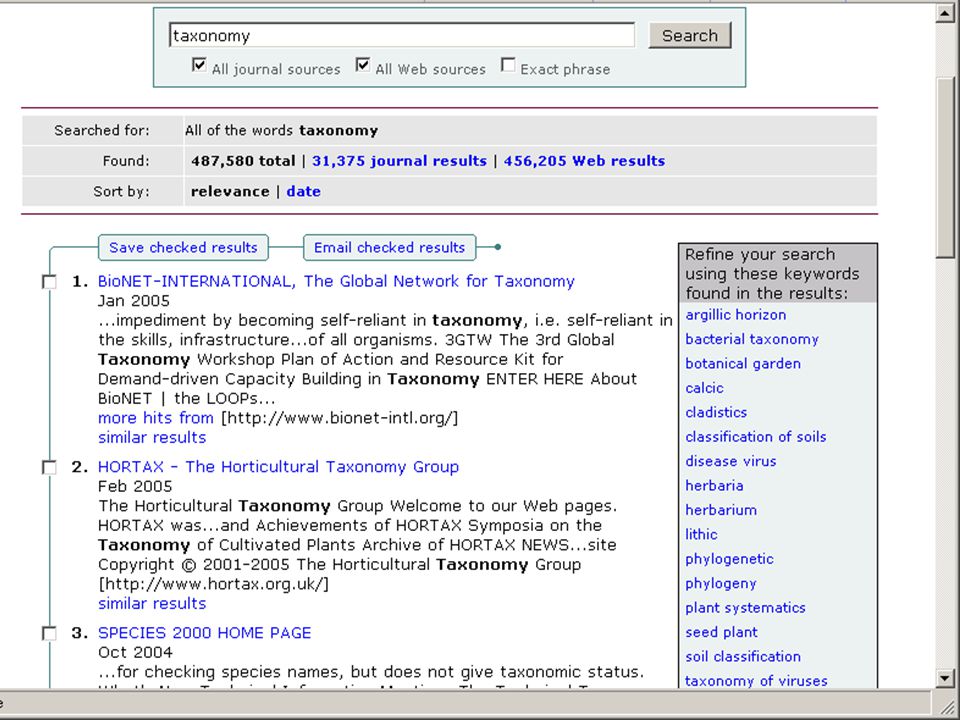
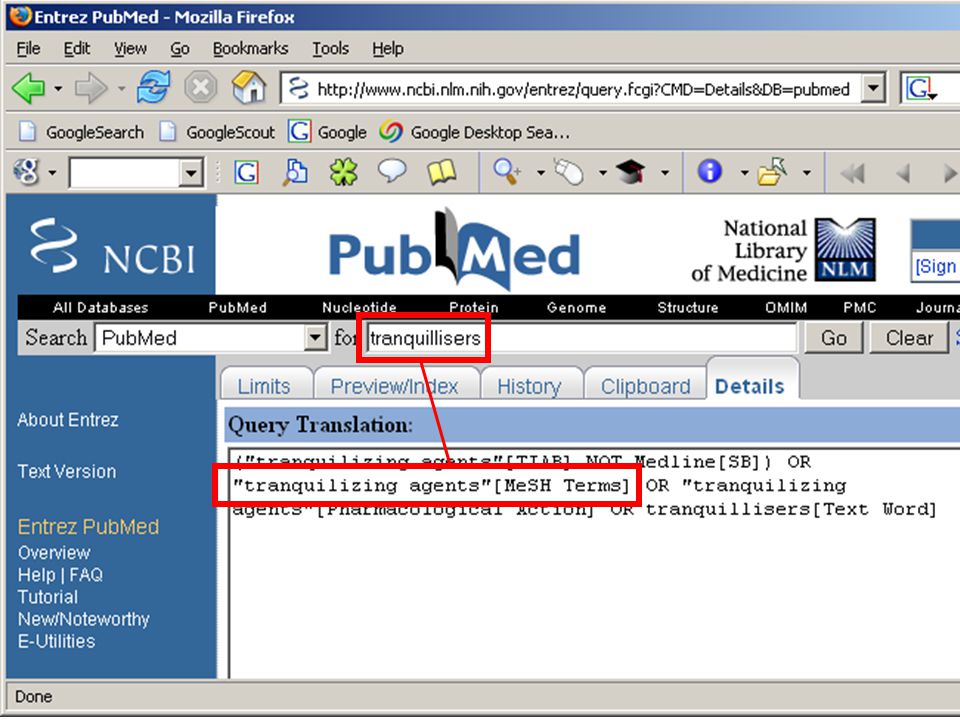
met behulp van semantisch netwerk, user thesaurus, concordantie, e.d., of dialoog-systeem dat gebruiker meer informatie over zijn vraag ontfutselt, of andere taaltechnologie kan systeem de juiste zoektermen vinden bij door gebruiker ingetikte zoekwoorden voorbeeld: Pubmed database op internet Eric Sieverts | | |

27
taaltechnologie bij document
zoek, zoek, zoek, match taaltechnologie bij document zoeken met "correcte" term of browsen naar "juiste" categorie taaltechnologie verrijkt document met "correcte" ontsluitingstermen (thesaurusterm, klasse uit taxonomie) in principe perfecte match mogelijk Eric Sieverts | | |
 in principe. perfecte match. mogelijk. Eric Sieverts | | |")
28
automatische "verrijking" van documenten
met combinaties van linguistische statistische regelgebaseerde technieken kan inhoud van documenten door computer worden geanalyseerd en op basis daarvan worden verrijkt met termen uit thesaurus, of worden ingedeeld in categorie van taxonomie ondanks wat beperkingen gaat dat al steeds beter Eric Sieverts | | |

30
taaltechnologie aan beide kanten
zoek, zoek, zoek, match taaltechnologie aan beide kanten gebruiker tikt maar wat in, maar systeem zoekt toch op "goede" termen computer kan documenten inhoudelijk karakteriseren (metadata toekennen) beter zoekresultaat & lagere kosten ? Eric Sieverts | | |
 beter zoekresultaat. & lagere kosten Eric Sieverts | | |")
31
taaltechnologie aan beide kanten
zoek, zoek, zoek, match taaltechnologie aan beide kanten voor veel van die technieken blijft het wel nodig dat een thesaurus / taxonomie / classificatie beschikbaar is en voor het semantisch web geldt dat al evenzeer Eric Sieverts | | |

32
Resource Description Framework
RDF is gespecificeerd voor (vooral) XML-omgeving om in het algemeen betekenis/semantiek aan documenten te kunnen toevoegen XML-tags (gedefinieerd via dtd of schema) kunnen al betekenis geven aan onderdelen van document-inhoud zelf RDF maakt dat je op meer gestandaardiseerde en beter georganiseerde wijze betekenis kunt meegeven, ook los van het document/object zelf met RDF kunnen dan bijvoorbeeld volgens Dublin Core gestructureerde metadata worden toegevoegd Eric Sieverts | | |
 XML-omgeving om in het algemeen betekenis/semantiek aan documenten te kunnen toevoegen. XML-tags (gedefinieerd via dtd of schema) kunnen al betekenis geven aan onderdelen van document-inhoud zelf. RDF maakt dat je op meer gestandaardiseerde en beter georganiseerde wijze betekenis kunt meegeven, ook los van het document/object zelf. met RDF kunnen dan bijvoorbeeld volgens Dublin Core gestructureerde metadata worden toegevoegd. Eric Sieverts | | |")
33
Resource Description Framework
RDF definieert een infrastructuur om zulke semantiek gestandaardiseerd te definiëren waarbij documenten zelf-verklarend worden zodanig dat computers hun betekenis kunnen afleiden waarbij verwezen wordt naar computerleesbare beschrijvingen van de semantiek en de standaarden die ze gebruiken zodat samenwerking en (her)gebruik van elders ontwikkelde standaarden mogelijk wordt Eric Sieverts | | |
gebruik van elders ontwikkelde standaarden mogelijk wordt. Eric Sieverts | | |")
34
het rdf-model bedoeld voor beschrijven van bronnen (resources / objecten) die identificeerbaar zijn via een uniform resource identifier (URI) middels eigenschappen (property-types / attributen) die een waarde (value) kunnen hebben property-types definiëren relaties tussen values en resources voorbeeld: "Jan is de auteur van document1" (of eigenlijk: "document1 heeft als auteur Jan") of zelfs Eric Sieverts | | |
 die een waarde (value) kunnen hebben. property-types definiëren relaties tussen values en resources. voorbeeld: Jan is de auteur van document1 (of eigenlijk: document1 heeft als auteur Jan ) of zelfs. Eric Sieverts | | |")
35
het rdf-model dat wordt in rdf-syntax dan iets ingewikkelds als:
<rdf:RDF xmlns:rdf=" xmlns=" <rdf:Description rdf:about=" <author> <rdf:Description rdf:about=" <name>John Smith</name> <affiliation>Home Inc.</affiliation> </rdf:Description> </author> </rdf:RDF> xml namespace verwijzingen, o.a. naar definitie voor RDF rdf:description wordt gebruikt voor identificatie van de resources (kan ook verwijzen naar html-document) en daarbinnen de elementen Eric Sieverts | | |
 en daarbinnen de elementen. Eric Sieverts | | |")
36
het rdf-model dublin core metadata worden in rdf-syntax iets als:
<rdf:RDF xmlns:rdf=" xmlns:dc=" <rdf:Description rdf:about=" <dc:title>Minicursus RDF</dc:title> <dc:description>In dit document wordt uitgelegd hoe rdf werkt </dc:description> <dc:date> </dc:date> <dc:format>text/ppt</dc:format> <dc:language>nl</dc:language> <dc:publisher>HvA - MIM</dc:publisher> <dc:contributor>Eric Sieverts</dc:contributor> </rdf:Description> </rdf:RDF> Eric Sieverts | | |

37
waar het bij rdf wezenlijk om draait
computerinterpreteerbaar relaties leggen tussen objecten, eigenschappen en waarden computerinterpreteerbaar betekenis toekennen aan die relaties via "namespace"-verwijzingen doorlinken naar plekken op het web waar "systemen" computerinterpreteerbaar gedefinieerd zijn (metadata-standaarden, inhoudelijke ontsluitingssystemen, betekenissen van begrippen daarin, …) gebruik kunnen maken van elders geïnvesteerde moeite, zonder dat zelf nog eens over te hoeven doen en: dat is ook de basis waar het semantisch web op voort wil bouwen Eric Sieverts | | |
 gebruik kunnen maken van elders geïnvesteerde moeite, zonder dat zelf nog eens over te hoeven doen. en: dat is ook de basis waar het semantisch web op voort wil bouwen. Eric Sieverts | | |")
38
ontologieën en semantisch web
wat betekenen “ontologieën” eigenlijk ? begrip oorspronkelijk afkomstig uit de filosofie en daarna ook uit de wereld van de kunstmatige intelligentie: in ontologie wordt kennis van (een stukje van) de wereld vastgelegd het dient als "kennis-representatie" wordt in semantisch web-wereld zeer ruim opgevat: in het algemeen aanduiding voor allerlei soorten ontsluitings-systemen wel essentieel: ontologie moet computerleesbaar, -interpreteerbaar en -verwerkbaar beschikbaar zijn (er zijn dus formele beschrijvingstalen voor nodig; men werkt onder meer aan "OWL" - web ontology language) Eric Sieverts | | |
 de wereld vastgelegd. het dient als kennis-representatie wordt in semantisch web-wereld zeer ruim opgevat: in het algemeen aanduiding voor allerlei soorten ontsluitings-systemen. wel essentieel: ontologie moet computerleesbaar, -interpreteerbaar en -verwerkbaar beschikbaar zijn. (er zijn dus formele beschrijvingstalen voor nodig; men werkt onder meer aan OWL - web ontology language) Eric Sieverts | | |")
39
ontologieën en semantisch web
voorbeelden van gebruikte ontologieën in kunstdocumentatie-systeem: vanuit één systeem namespace-verwijzingen naar: Art & Architecture Thesaurus (thesaurus) IconClass (beeld-classificatie) WordNet (semantisch netwerk) Union List of Artist Names (authority list) AAT Wordnet equivalenties (concordantie) Dublin Core voor annotaties (metadata-systeem) uiteindelijk doel: met betere precisie en recall kunnen zoeken naar (afbeeldingen en/of beschrijvingen van) kunstwerken Eric Sieverts | | |
 IconClass (beeld-classificatie) WordNet (semantisch netwerk) Union List of Artist Names (authority list) AAT Wordnet equivalenties (concordantie) Dublin Core voor annotaties (metadata-systeem) uiteindelijk doel: met betere precisie en recall kunnen zoeken naar (afbeeldingen en/of beschrijvingen van) kunstwerken. Eric Sieverts | | |")
41
annotating with a concept : term disambiguation

42
typisch semantisch web voorbeeld: zoeken naar plaatje
© Guus Schreiber UvA / VU A person searches for photos of an “orange ape” An image collection of animal photographs contains snapshots of orang-utans. The search engine finds the photos, despite the fact that the words “orange” and “ape” do not appear in annotations Eric Sieverts | | |

43
semantische annotatie

44
rdf annotatie van een web-bron
© Guus Schreiber UvA / VU Eric Sieverts | | |

45
de "species ontology" © Guus Schreiber UvA / VU
zie: Eric Sieverts | | |

46
zoek, zoek, zoek, match ook voor het semantisch web zal dus nog volop moeten worden "ontsloten", maar: met slimme systemen die domme documenten (helpen) ontsluiten en slimme systemen die domme zoekvragen (kunnen) verbeteren zal zelfs een aap goede informatie kunnen vinden Eric Sieverts | | |
 ontsluiten. en slimme systemen die domme zoekvragen (kunnen) verbeteren. zal zelfs een aap goede informatie kunnen vinden. Eric Sieverts | | |")
Verwante presentaties







 SQL – een begin.>")


>")

 Module 4 College “Big Picture” Universiteitsbibliotheek UM 2002, 10 juni.>")





 C-DSD 2011-2012 Martine de Bruin.>")


