Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
geïntegreerde zoeksystemen
verbeterde toegankelijkheid door meer verschillende bronnen in één keer doorzoekbaar te maken © eric sieverts, UB Utrecht / HvA - MIM

2
integratie van meer bronnen / zoeksystemen
waarom wil je dat? veel organisaties hebben (heel) veel verschillende bronnen ter beschikking het is dan onhandig dezelfde zoekvraag aan elk afzonderlijk systeem telkens weer opnieuw te moeten stellen <vb utrecht> het is dan gebruikersonvriendelijk dat die systemen vaak allemaal verschillende zoekinterfaces hebben © eric sieverts, UB Utrecht / HvA - MIM
 veel. verschillende bronnen ter beschikking. het is dan onhandig dezelfde zoekvraag aan elk afzonderlijk systeem telkens weer opnieuw te moeten stellen <vb utrecht> het is dan gebruikersonvriendelijk dat die systemen vaak allemaal verschillende zoekinterfaces hebben. © eric sieverts, UB Utrecht / HvA - MIM.")
3
integratie van meer bronnen / zoeksystemen
waarom wil je dat? veel organisaties hebben (heel) veel verschillende bronnen ter beschikking het is dan onhandig dezelfde zoekvraag aan elk afzonderlijk systeem telkens weer opnieuw te moeten stellen het is dan gebruikersonvriendelijk dat die systemen vaak allemaal verschillende zoekinterfaces hebben © eric sieverts, UB Utrecht / HvA - MIM
 veel. verschillende bronnen ter beschikking. het is dan onhandig dezelfde zoekvraag aan elk afzonderlijk systeem telkens weer opnieuw te moeten stellen. het is dan gebruikersonvriendelijk dat die systemen vaak allemaal verschillende zoekinterfaces hebben. © eric sieverts, UB Utrecht / HvA - MIM.")
4
integratie van meer bronnen / zoeksystemen
waarom wil je dat? bovendien nog algemene randvoorwaarde: google lijkt altijd eenvoudiger als zoeksystemen niet op zijn minst bijna net zo eenvoudig lijken als google , worden ze niet gebruikt © eric sieverts, UB Utrecht / HvA - MIM

5
hoe kun je dat integreren?
globaal twee soorten aanpak voor zogenaamde “content-integratie”: alle bronnen in je eigen centrale systeem (zoekmachine) indexeren meta-zoeksysteem dat de externe zoeksystemen van de verschillende bronnen in één keer parallel bevraagt (gedistribueerde zoekactie) © eric sieverts, UB Utrecht / HvA - MIM
 indexeren. meta-zoeksysteem dat de externe zoeksystemen van de verschillende bronnen in één keer parallel bevraagt (gedistribueerde zoekactie) © eric sieverts, UB Utrecht / HvA - MIM.")
6
eigen centrale index dat kan (technisch) ook nog weer op verschillende manieren, zoals: de van verschillende leveranciers verkregen (“gekochte”) informatie volledig op de eigen server laden en daar indexeren toegang verkrijgen (kopen) tot informatie die op servers van leveranciers staat en die door je eigen “robot” of "spider" laten indexeren (zoals webzoekmachines) zogenaamde “metadata” (in deze context meestal ook abstracts van artikelen) van verschillende leveranciers op eigen server laden en indexeren; daarin hyperlinks naar volledige documenten op servers van leveranciers © eric sieverts, UB Utrecht / HvA - MIM
 informatie volledig op de eigen server laden en daar indexeren. toegang verkrijgen (kopen) tot informatie die op servers van leveranciers staat en die door je eigen robot of spider laten indexeren (zoals webzoekmachines) zogenaamde metadata (in deze context meestal ook abstracts van artikelen) van verschillende leveranciers op eigen server laden en indexeren; daarin hyperlinks naar volledige documenten op servers van leveranciers. © eric sieverts, UB Utrecht / HvA - MIM.")
7
(volledige documenten)
geïntegreerd systeem via lokale centrale index zoeken centrale index indexer indexeer- regels voor targets internet full-text links tekstbestanden (volledige documenten) tekstbestanden
 tekstbestanden.")
8
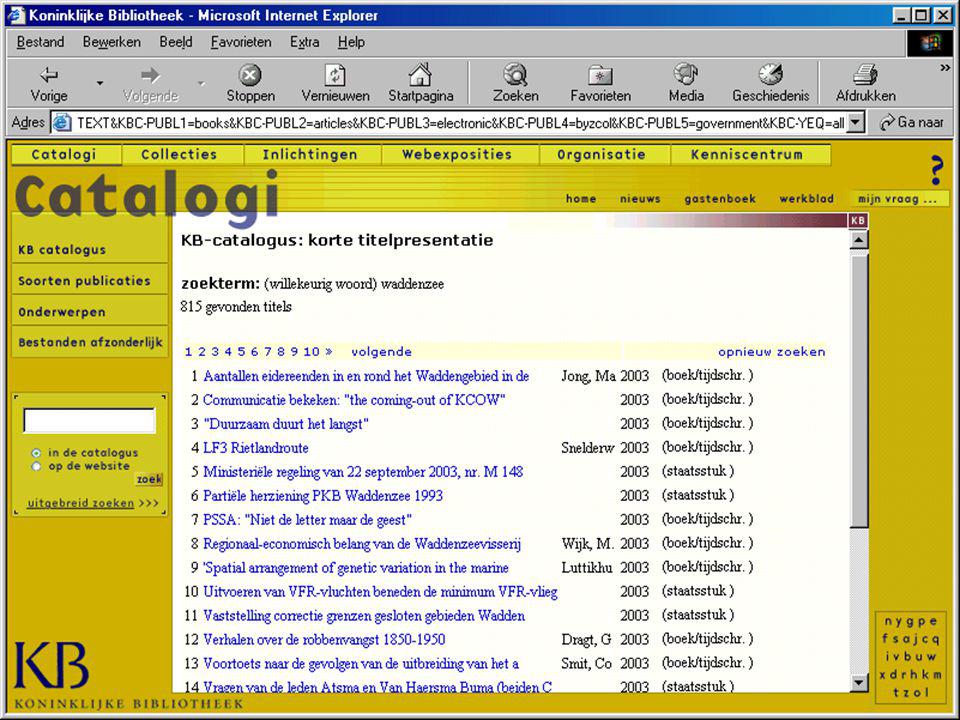
eigen centrale index voorbeeld:
koninklijke bibliotheek had dat tot 2 jaar geleden (en gaat daar in nieuwe architectuur weer naar terug) een aantal al lokaal beschikbare bestanden in verschillende systemen (incl. gewone catalogus) geconverteerd naar XML samen geïndexeerd standaard in die bestanden tezamen gezocht © eric sieverts, UB Utrecht / HvA - MIM
 een aantal al lokaal beschikbare bestanden in verschillende systemen (incl. gewone catalogus) geconverteerd naar XML. samen geïndexeerd. standaard in die bestanden tezamen gezocht. © eric sieverts, UB Utrecht / HvA - MIM.")
12
eigen centrale index ook dat kan (technisch) nog weer op verschillende manieren, zoals: de van verschillende leveranciers verkregen (“gekochte”) informatie volledig op de eigen server laden en daar indexeren toegang verkrijgen (kopen) tot informatie die op servers van leveranciers staat en die door je eigen “robot” of "spider" laten indexeren (zoals webzoekmachines) zogenaamde “metadata” (in deze context meestal ook abstracts van artikelen) van verschillende leveranciers op eigen server laden en indexeren; daarin hyperlinks naar volledige documenten op servers van leveranciers © eric sieverts, UB Utrecht / HvA - MIM
 informatie volledig op de eigen server laden en daar indexeren. toegang verkrijgen (kopen) tot informatie die op servers van leveranciers staat en die door je eigen robot of spider laten indexeren (zoals webzoekmachines) zogenaamde metadata (in deze context meestal ook abstracts van artikelen) van verschillende leveranciers op eigen server laden en indexeren; daarin hyperlinks naar volledige documenten op servers van leveranciers. © eric sieverts, UB Utrecht / HvA - MIM.")
13
indexer zoeken centrale index internet tekstbestanden tekstbestanden
geïntegreerd systeem via lokale centrale index zoeken centrale index indexer indexeer- regels voor targets internet full-text links tekstbestanden tekstbestanden

14
eigen centrale index voorbeeld:
scirus zoekmachine (Elsevier: enerzijds: bijna 6 miljoen full-text artikelen uit circa 1800 (eigen) wetenschappelijke tijdschriften daarnaast: meer dan 160 miljoen wetenschappelijke webpagina's op allerlei sites ook: 15 miljoen bibliografische Pubmed-records en: inhoud uit wetenschappelijke “repositories” standaard in die collecties tezamen gezocht © eric sieverts, UB Utrecht / HvA - MIM
 wetenschappelijke tijdschriften. daarnaast: meer dan 160 miljoen wetenschappelijke webpagina s op allerlei sites. ook: 15 miljoen bibliografische Pubmed-records. en: inhoud uit wetenschappelijke repositories standaard in die collecties tezamen gezocht. © eric sieverts, UB Utrecht / HvA - MIM.")
15
eigen centrale index ook dat kan (technisch) nog weer op verschillende manieren, zoals: de van verschillende leveranciers verkregen (“gekochte”) informatie volledig op de eigen server laden en daar indexeren toegang verkrijgen (kopen) tot informatie die op servers van leveranciers staat en die door je eigen “robot” of "spider" laten indexeren (zoals webzoekmachines) zogenaamde “metadata” (in deze context meestal ook abstracts van artikelen) van verschillende leveranciers op eigen server laden en indexeren; daarin hyperlinks naar volledige documenten op servers van leveranciers © eric sieverts, UB Utrecht / HvA - MIM
 informatie volledig op de eigen server laden en daar indexeren. toegang verkrijgen (kopen) tot informatie die op servers van leveranciers staat en die door je eigen robot of spider laten indexeren (zoals webzoekmachines) zogenaamde metadata (in deze context meestal ook abstracts van artikelen) van verschillende leveranciers op eigen server laden en indexeren; daarin hyperlinks naar volledige documenten op servers van leveranciers. © eric sieverts, UB Utrecht / HvA - MIM.")
16
indexer zoeken centrale index internet tekstbestanden tekstbestanden
geïntegreerd systeem via lokale centrale index zoeken centrale index indexer indexeer- regels voor targets internet full-text links tekstbestanden (metadata) tekstbestanden
 tekstbestanden.")
17
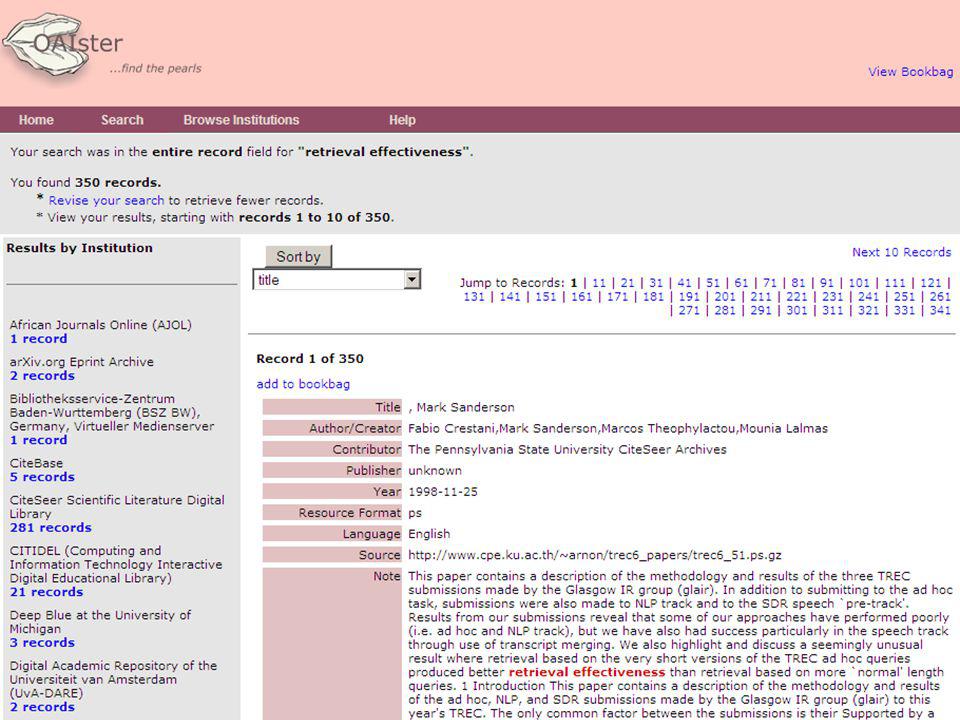
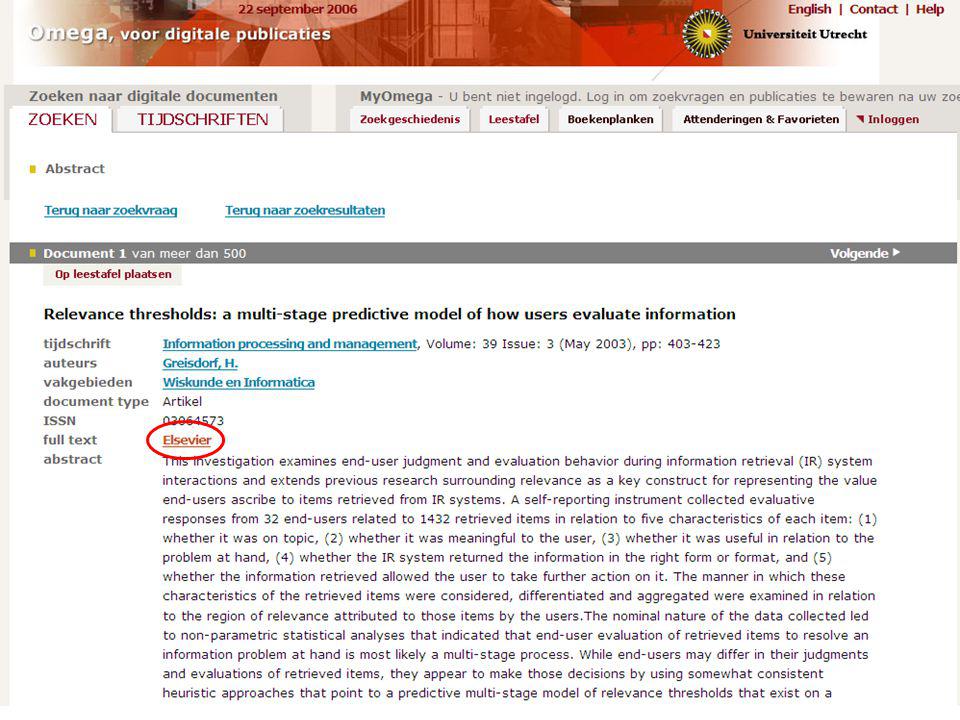
eigen centrale index voorbeelden
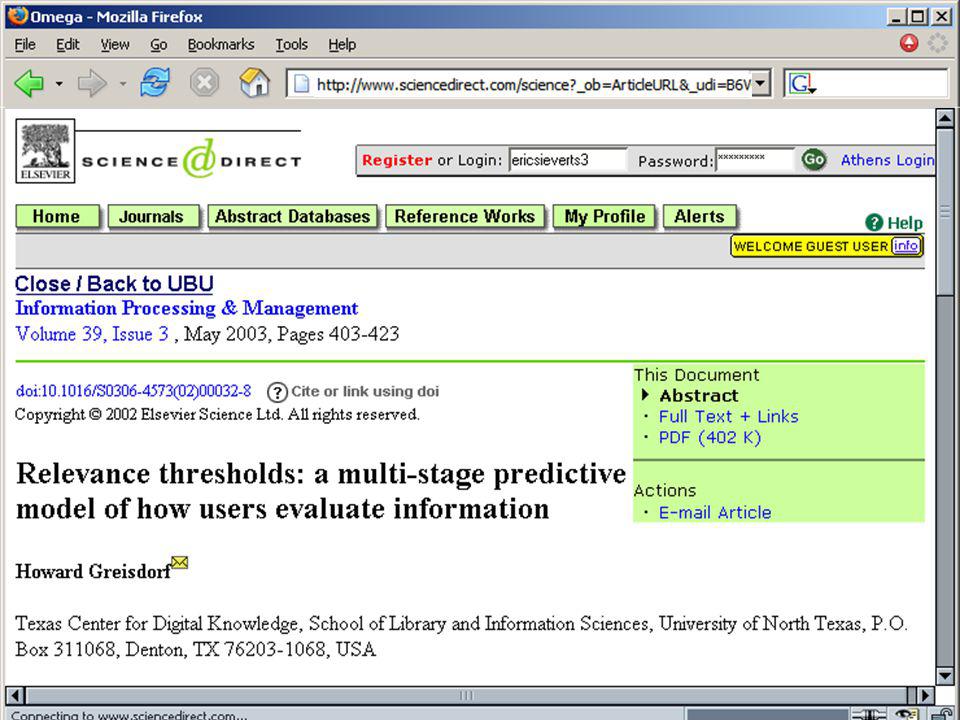
(waar dus alleen metadata doorzoekbaar; niet de full-text) OAIster <link> volgens Open Archive protocol “ge-harveste” metadata (volgens Dublin Core), uit allerlei “archieven” met wetenschappelijke publikaties UB Utrecht - Omega-systeem <link> metadata van artikelen uit groot aantal tijdschriften van diverse leveranciers © eric sieverts, UB Utrecht / HvA - MIM
 OAIster <link> volgens Open Archive protocol ge-harveste metadata (volgens Dublin Core), uit allerlei archieven met wetenschappelijke publikaties. UB Utrecht - Omega-systeem <link> metadata van artikelen uit groot aantal tijdschriften van diverse leveranciers. © eric sieverts, UB Utrecht / HvA - MIM.")
22
voordelen eigen centrale index
garantie van uniforme zoekmogelijkheden geavanceerde zoekfunctionaliteit mogelijk (dus concurrentie met Google aan te gaan), want de "aanbieder" heeft zelf in de hand welke zoekmachine software te installeren, hoe die te configureren, welke functionaliteit aan te bieden, hoe het gebruikersinterface te ontwerpen © eric sieverts, UB Utrecht / HvA - MIM
, want de aanbieder heeft zelf in de hand. welke zoekmachine software te installeren, hoe die te configureren, welke functionaliteit aan te bieden, hoe het gebruikersinterface te ontwerpen. © eric sieverts, UB Utrecht / HvA - MIM.")
23
problemen bij centrale index
problemen met leverancier van de “content”: mogelijkheid staat niet in contract / licentie leverancier begrijpt niet precies wat de klant wil technische problemen format van geleverde content inconsistent (velden, tags, ...) spider van zoekmachine wordt “toch” toegang geweigerd .... “logistieke” problemen ontbrekende / incomplete / dubbele gegevens metadata ontvangen waarvoor geen full-text toegang is © eric sieverts, UB Utrecht / HvA - MIM
 spider van zoekmachine wordt toch toegang geweigerd logistieke problemen. ontbrekende / incomplete / dubbele gegevens. metadata ontvangen waarvoor geen full-text toegang is. © eric sieverts, UB Utrecht / HvA - MIM.")
24
problemen bij centrale index
problemen met "inhoud": interne consistentie van geleverde format velden (aanwezigheid, veldtags) bijzondere tekens (diacrieten) verschil tussen leveranciers in hoeveelheid digitale tekst in de metadata veldconcordantie tussen bronnen / leveranciers content laten zoals die is ontvangen: apart indexeerscript per bron content converteren naar eigen format in "data-repository" (bijv. in xml en volgens DC): apart import-filter per bron © eric sieverts, UB Utrecht / HvA - MIM
 bijzondere tekens (diacrieten) verschil tussen leveranciers in hoeveelheid digitale tekst in de metadata. veldconcordantie tussen bronnen / leveranciers. content laten zoals die is ontvangen: apart indexeerscript per bron. content converteren naar eigen format in data-repository (bijv. in xml en volgens DC): apart import-filter per bron. © eric sieverts, UB Utrecht / HvA - MIM.")
25
problemen bij centrale index
problemen met techniek: benodigde schijfruimte voor de content + de index(en) beheer en configuratie van eigen zoekmachine beheer en configuratie van conversiefilters en/of indexeer-scripts problemen met zoekfunctionaliteit: geen thesaurus zoekfunctie (zonder grote investering) © eric sieverts, UB Utrecht / HvA - MIM
 beheer en configuratie van eigen zoekmachine. beheer en configuratie van conversiefilters en/of indexeer-scripts. problemen met zoekfunctionaliteit: geen thesaurus zoekfunctie (zonder grote investering) © eric sieverts, UB Utrecht / HvA - MIM.")
26
meta-search oplossing
moet kunnen communiceren met allerlei verschillende soorten zoeksystemen (o.a. vraag- en antwoord-syntax daarvan kennen) Z39.50 protocol (vooral voor bibliografische databases) xml-gebaseerde systemen (SRU: vooral voor bibliografische databases, OpenSearch: vooral voor "gewone" zoekmachines) http-protocol / web-formulieren ("screen-scraping" van gewone webinterfaces) vereist database met configuratie-gegevens van de te doorzoeken systemen © eric sieverts, UB Utrecht / HvA - MIM
 Z39.50 protocol. (vooral voor bibliografische databases) xml-gebaseerde systemen. (SRU: vooral voor bibliografische databases, OpenSearch: vooral voor gewone zoekmachines) http-protocol / web-formulieren. ( screen-scraping van gewone webinterfaces) vereist database met configuratie-gegevens van de te doorzoeken systemen. © eric sieverts, UB Utrecht / HvA - MIM.")
27
query-generator / antwoord-inzamelaar
geïntegreerd systeem via meta-zoekmethode zoeken query-generator / antwoord-inzamelaar configuratie gegevens van targets Z39.50 http Z39.50 intern api internet Z39.50 http http xml Z39.50 zoek zoek zoek zoek zoek zoek index index index index index index be- stand be- stand be- stand be- stand be- stand be- stand

28
meta-search oplossing
Z39.50 standaard protocol voor communicatie tussen lokale client-software en server voor: opsturen query (en andere opdrachten) in juiste syntax gewenste actie (browsen / zoeken / tonen / …) veldnamen booleaanse operatoren .... interpretatie van ontvangen antwoorden / gegevens stuk uit index aantal hits resultatenlijst (velden) detailpresentatie van resultaten (velden, structuur) © eric sieverts, UB Utrecht / HvA - MIM
 in juiste syntax. gewenste actie (browsen / zoeken / tonen / …) veldnamen. booleaanse operatoren interpretatie van ontvangen antwoorden / gegevens. stuk uit index. aantal hits. resultatenlijst (velden) detailpresentatie van resultaten (velden, structuur) © eric sieverts, UB Utrecht / HvA - MIM.")
29
meta-search oplossing
Z39.50 protocol voordeel: in de tijd stabiele interfaces velden “in principe” gestandaardiseerd nadeel: inflexibel lastige implementatie velden in praktijk vaak niet echt gestandaardiseerd weinig geavanceerde zoekfunctionaliteit (bijv. geen relevance ranking) © eric sieverts, UB Utrecht / HvA - MIM
 © eric sieverts, UB Utrecht / HvA - MIM.")
30
meta-search oplossing
http-protocol / webformulieren queries (ingevoerd via zoekregel of meer complex webformulier) worden doorgegeven via een URL, volgens door zoeksysteem gespecificeerde syntax antwoorden (zoekresultaten) moeten worden geïnterpreteerd; er is geen standaard structuur: elementen uit antwoordscherm moeten worden herkend op basis van schermopmaak - toevallig aanwezige kenmerkende stukjes html-code - z.g.n. "screen-scraping" © eric sieverts, UB Utrecht / HvA - MIM
 worden doorgegeven via een URL, volgens door zoeksysteem gespecificeerde syntax. hl=en&ie=UTF-8&q=mim+idm. antwoorden (zoekresultaten) moeten worden geïnterpreteerd; er is geen standaard structuur: elementen uit antwoordscherm moeten worden herkend. op basis van schermopmaak. - toevallig aanwezige kenmerkende stukjes html-code - z.g.n. screen-scraping © eric sieverts, UB Utrecht / HvA - MIM.")
31
meta-search oplossing
http-protocol / webformulieren voordeel: alle functionaliteit van betreffende zoekfunctie nadeel: url-based query-syntax moet geanalyseerd worden lastige filter-scripts schrijven voor “screen-scraping” t.b.v. verwerken gegevens uit antwoordschermen (zoekresultaten) interfaces van zoeksystemen niet erg stabiel in de tijd (telkens opnieuw "screen-scraping" filters aanpassen) © eric sieverts, UB Utrecht / HvA - MIM
 interfaces van zoeksystemen niet erg stabiel in de tijd (telkens opnieuw screen-scraping filters aanpassen) © eric sieverts, UB Utrecht / HvA - MIM.")
32
meta-search oplossing
voorbeelden voor alleen webzoeken: web-metasearchers: ixquick, clusty, mamma, search.com, kartoo, goshme, … <vb goshme> desktop metasearchers (op eigen pc te installeren): copernic © eric sieverts, UB Utrecht / HvA - MIM
: copernic. © eric sieverts, UB Utrecht / HvA - MIM.")
33
meta-search oplossing
xml-gebaseerde standaarden SRU/SRW (ook wel ZING - Z39.50 next-generation; xml-variant op Z39.50) SRU-protocol (search & retrieval by url) queries in url verpakken (volgens standaard syntax) antwoorden van systemen komen standaard in xml terug, zodat elementen daarin eenduidig herkenbaar zijn SRW-protocol (search & retrieval by the web) gebruikt daarvoor SOAP-protocol openSearch (XML protocol voor -gewone- zoekmachines) <zie voor uitleg de serie “De Standaard” in Informatie Professional> © eric sieverts, UB Utrecht / HvA - MIM
 SRU-protocol (search & retrieval by url) queries in url verpakken (volgens standaard syntax) antwoorden van systemen komen standaard in xml terug, zodat elementen daarin eenduidig herkenbaar zijn. SRW-protocol (search & retrieval by the web) gebruikt daarvoor SOAP-protocol. openSearch (XML protocol voor -gewone- zoekmachines) <zie voor uitleg de serie De Standaard in Informatie Professional> © eric sieverts, UB Utrecht / HvA - MIM.")
34
meta-search oplossing
voorbeeld van SRU-gebaseerd systeem TEL - The European Library <link> project van Europese Nationale Bibliotheken, waarbij al hun uiteenlopende catalogi in één keer doorzocht kunnen worden prototype ontwikkeld door KB zie ook artikel van Theo van Veen in: Informatie Professional - maart 2004 wordt nu intern al in veel meer systemen toegepast © eric sieverts, UB Utrecht / HvA - MIM

35
meta-search oplossing
enkele algemene voorbeelden van producten: metalib (van bibliotheekautomatiseerder ExLibris) museglobal fretwell-downing portal ihs portal suite v-spaces (van bibliotheekautomatiseerder Infor) webfeat (webservice) bij vrijwel allemaal (nog) nadruk op Z39.50 targets zie kritisch artikel van Marten Hofstede: “Portals op de pijnbank” in: Informatie Professional - oktober 2002 © eric sieverts, UB Utrecht / HvA - MIM
 museglobal. fretwell-downing portal. ihs portal suite. v-spaces (van bibliotheekautomatiseerder Infor) webfeat (webservice) bij vrijwel allemaal (nog) nadruk op Z39.50 targets. zie kritisch artikel van Marten Hofstede: Portals op de pijnbank in: Informatie Professional - oktober © eric sieverts, UB Utrecht / HvA - MIM.")
36
meta-search oplossing
enkele voordelen: lokale software stelt geen heel hoge eisen aan server geen (nauwelijks) problemen met leveranciers geen problemen met indexeer- of filter-scripts (vergeleken met eigen indexerings-oplossing) © eric sieverts, UB Utrecht / HvA - MIM
 problemen met leveranciers. geen problemen met indexeer- of filter-scripts (vergeleken met eigen indexerings-oplossing) © eric sieverts, UB Utrecht / HvA - MIM.")
37
meta-search oplossing
nadelen van huidige generatie metazoekers: geen uniformiteit in beschikbare zoekfunctionaliteit grootste gemene veelvoud van functionaliteit geen geavanceerde zoekfuncties [relevance ranking, thesaurus, …] (al biedt SRU in principe wel mogelijkheden) onvergelijkbare aantallen resultaten / incomplete antwoorden vaak slechte responsetijden (van achterliggende systemen) beperking van aantal gelijktijdig te doorzoeken systemen slechte "usability" [onduidelijk interface, hoe voorselectie van bestanden? …] database met configuratiegegevens bijhouden/updaten (al zorgt leverancier daar meestal voor) © eric sieverts, UB Utrecht / HvA - MIM
 onvergelijkbare aantallen resultaten / incomplete antwoorden. vaak slechte responsetijden (van achterliggende systemen) beperking van aantal gelijktijdig te doorzoeken systemen. slechte usability [onduidelijk interface, hoe voorselectie van bestanden …] database met configuratiegegevens bijhouden/updaten. (al zorgt leverancier daar meestal voor) © eric sieverts, UB Utrecht / HvA - MIM.")
38
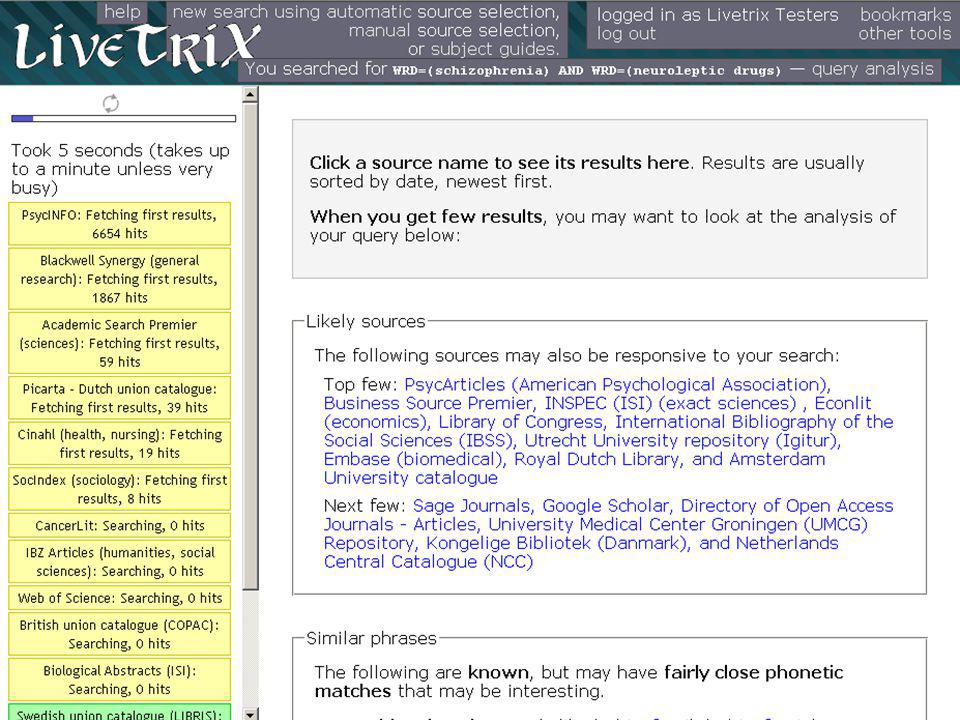
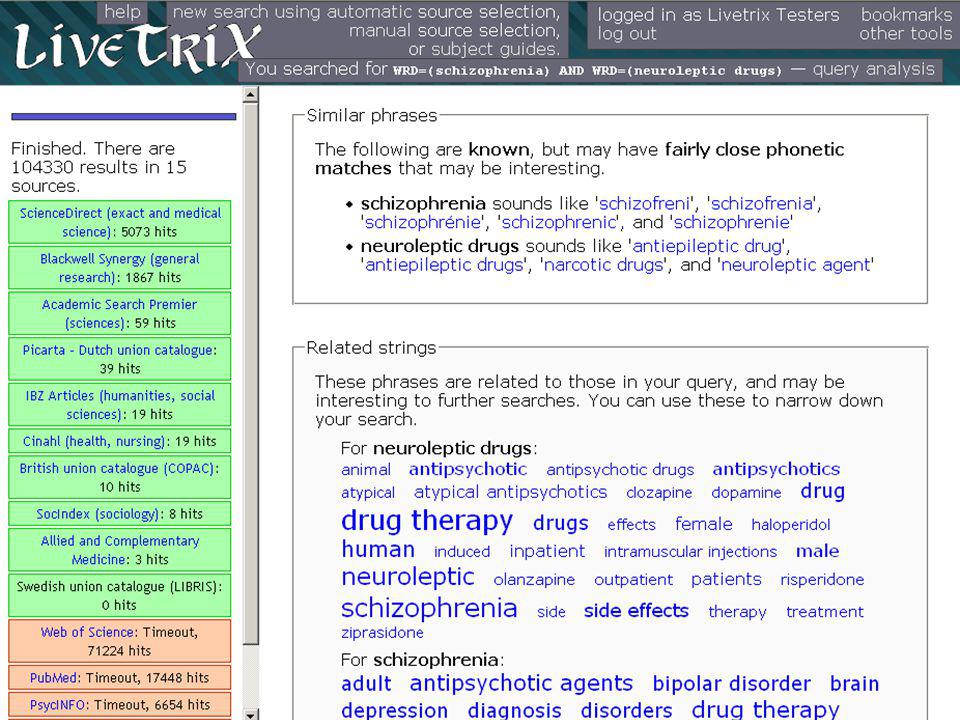
wat nieuwe ontwikkelingen
expertsysteem voor bestandskeuze inbouwen in metasearch ("Livetrix" bij UB Groningen) user experience van metasearch verbeteren, o.a. door response "schijnbaar" te versnellen door toepassing van bijvoorbeeld AJAX-technologie (scherm wordt geleidelijk opgebouwd en veranderd, zonder hele reloads zoals bij klassieke HTML) combinatie van zoeken via centrale index met metasearch voor niet lokaal te indexeren gegevens ("Primo" van ExLibris, "Summa" van Deense bibliotheken) © eric sieverts, UB Utrecht / HvA - MIM
 user experience van metasearch verbeteren, o.a. door response schijnbaar te versnellen door toepassing van bijvoorbeeld AJAX-technologie (scherm wordt geleidelijk opgebouwd en veranderd, zonder hele reloads zoals bij klassieke HTML) combinatie van zoeken via centrale index met metasearch voor niet lokaal te indexeren gegevens ( Primo van ExLibris, Summa van Deense bibliotheken) © eric sieverts, UB Utrecht / HvA - MIM.")
Verwante presentaties