Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Hogeschool Van Hall Larensteijn Leeuwarden
Grote datasets Henry Kuipers Hogeschool Van Hall Larensteijn Leeuwarden

2
Opbouw presentaties Voorbeelden “grote” datasets
Visualiseren van de relaties tussen de variabelen d.m.v. een conceptueel model Verborgen variabelen en interacties tussen variabelen Stappenplan om te komen tot een “best passend model” met de voorspellers voor een afhankelijke variabele (Bron: “Applied logistic regression Hosmer & Lemeshow ” )
")
3
Voorbeelden grote datasets
GIS (Geografische Informatiesystemen) vegetatiekaarten, hoogtekaarten locatiegegevens (via zenders) etc. etc. Internet Klimaatgegevens digitaal enquêteren (b.v. via fora) Gedigitaliseerde gegevens van organisaties
 vegetatiekaarten, hoogtekaarten locatiegegevens (via zenders) etc. etc. Internet Klimaatgegevens digitaal enquêteren (b.v. via fora) Gedigitaliseerde gegevens van organisaties.")
4
Voorbeelden “grote” datasets
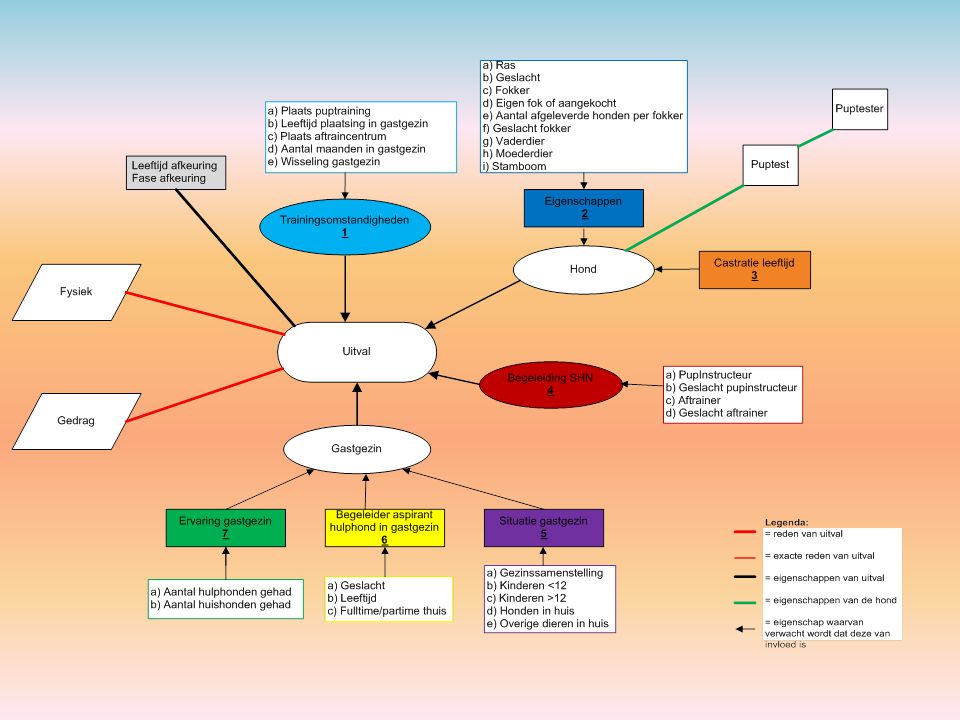
Stichting Hulphond Nederland Welke factoren hebben in welke mate een invloed op de uitval van aspirant hulphonden tijdens het opleidingstraject?

6
Voorbeeld “Stichting Hulphond”
Het bestand bestond uit 30 kenmerken van 443 honden =30*443=13290 gegevens

7
Voorbeeld “Stichting Hulphond”
Oorspronkelijk 29 voorspellers waarvan uiteindelijk 18 gebruikt voor onderzoek. Van 11 voorspellers waren bepaalde klassen ondervertegenwoordigd omdat voor de analyse die gebruikt werd je minstens 30 honden per klasse nodig had. Bijvoorbeeld: 15 van de 443 honden hadden een mannelijke trainer . Dit waren te weinig om het effect van het geslacht van de trainer op uitval te bepalen.

8
Voorbeeld “Blanding’s turtles
Invloed van biotische en abiotische factoren op het nest succes van het Blanding’s schildpad (Emydoidea blandingii) Welke biotische en abiotische factoren hebben invloed op het nest succes van het Blanding’s schildpad in Nova Scotia en hoe beïnvloeden ze het nest succes
 Welke biotische en abiotische factoren hebben invloed op het nest succes van het Blanding’s schildpad in Nova Scotia en hoe beïnvloeden ze het nest succes.")
9
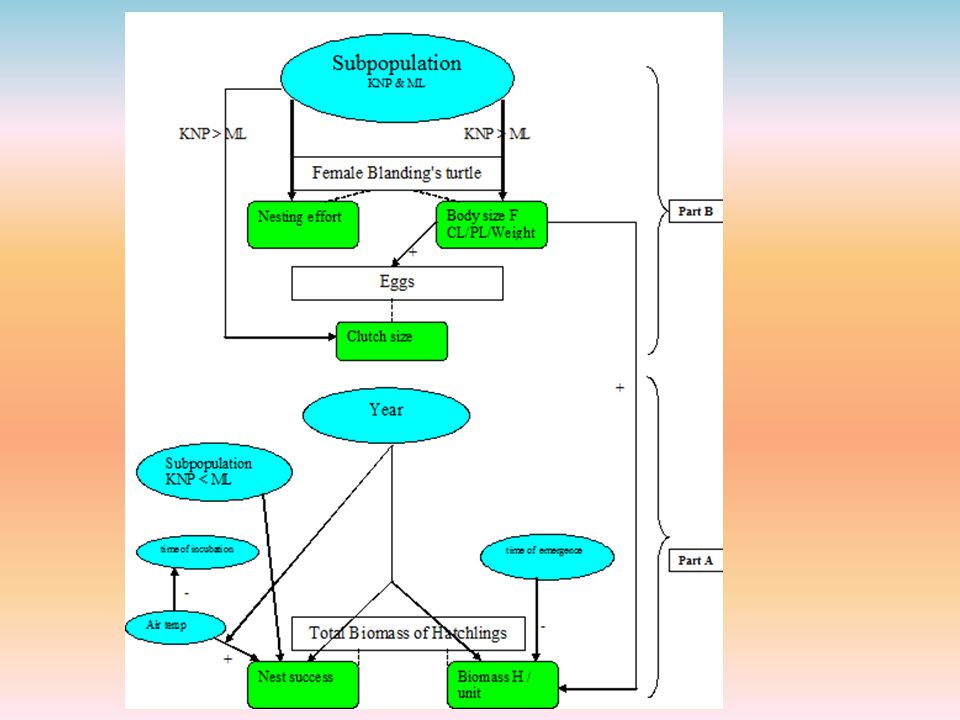
Voorbeeld “Blanding’s turtles
As these factors also had to be determined per nest to have eventually one prepared database, air temperature was determined as mean air temperature during the months of incubation. Precipitation was determined in the same way. (CL, the length of the upper part of the shell in cm.), plastron length (PL, the length of the under-part of the shell in cm.) Time of emergence was defined as the number of days elapsed between the date when the first hatchling emerged (date of first hatchling) and the date when the last hatchling emerged (date of last hatchling). Incubation time for each nest was defined as the number of days elapsed between oviposition (nesting date) and the emergence of the first hatchling (date of first hatchling) (Standing et al., 1999). Kejimkujik National Park (KNP) ; McGowan Lake (ML) Het bestand bestond uit 14 kenmerken van 162 nesten =14*162= 2268 gegevens
, plastron length (PL, the length of the under-part of the shell in cm.) Time of emergence was defined as the number of days elapsed between the date when the first hatchling emerged (date of first hatchling) and the date when the last hatchling emerged (date of last hatchling). Incubation time for each nest was defined as the number of days elapsed between oviposition (nesting date) and the emergence of the first hatchling (date of first hatchling) (Standing et al., 1999). Kejimkujik National Park (KNP) ; McGowan Lake (ML) Het bestand bestond uit 14 kenmerken van 162 nesten =14*162= 2268 gegevens.")
10
Fg 3: Conceptual model based on Herman et al. , 1995; Herman et al
Fg 3: Conceptual model based on Herman et al., 1995; Herman et al., 1999; Standing et al., 1999; Standing et al., 2000; McNeil F=Females, H=Hatchling. The blue ovals represent a-biotic factors; the green squares represent the biotic factors. The black arrows show the direct relations, and the dotted lines show the characteristics of female, eggs and total biomass hatchlings respectively. The blue lines represent the relations with year and do not have a number. Precipitation, air temperature, time of incubation, time of emergence, biomass H unit and nest success are expected to fluctuate among years. Factors present in the original database that are not shown in this figure are: soil type, nest depth, predation and flooding. The reason for their absence is a lack of accurate data.

11
No Relation Known Hypothesis Literature 2b Location Nesting effort The slate substrate outcrops (inlands), in which many of the turtles nest are apparently difficult for the females to nest in, resulting in increased effort from the female, both in nest duration and number of nest attempts. Nesting effort differs per nesting location with a higher nesting effort of females nesting inlands than at lakeshores. McNeil 2002 8b Air temperature biomass hatchling unit The influence of the environment, like air temperature, on the development in embryonic turtles has been shown to affect nesting survival, duration of incubation, sexual differences, and size and composition of hatchlings. There is a significant positive relation between air temperature and body size of hatchlings. Bull and Vogt, 1979; Packard et al., 1980, 1981; Gutzke, 1984. 13 Body size F body size H unit According to a study by Congdon and van Loben Sels in 1990 in Michigan (U.S.A). The linear relationship of hatchling mass (weight) with female parent size (CL) was not significant. They found this result not surprising because the relationship of egg size to body size was weak. They suggest that variation in hatchling size caused by differences in thermal and hydric conditions of natural nests could mask all but the strongest correlations of hatchling size with body size of females. There is a positive linear relation between body size of adult females and body size of hatchlings. Congdon and van Loben Sels, 1990; Packard et al. 1982
, in which many of the turtles nest are apparently difficult for the females to nest in, resulting in increased effort from the female, both in nest duration and number of nest attempts. Nesting effort differs per nesting location with a higher nesting effort of females nesting inlands than at lakeshores. McNeil b. Air temperature biomass hatchling unit. The influence of the environment, like air temperature, on the development in embryonic turtles has been shown to affect nesting survival, duration of incubation, sexual differences, and size and composition of hatchlings. There is a significant positive relation between air temperature and body size of hatchlings. Bull and Vogt, 1979; Packard et al., 1980, 1981; Gutzke, Body size F body size H unit. According to a study by Congdon and van Loben Sels in 1990 in Michigan (U.S.A). The linear relationship of hatchling mass (weight) with female parent size (CL) was not significant. They found this result not surprising because the relationship of egg size to body size was weak. They suggest that variation in hatchling size caused by differences in thermal and hydric conditions of natural nests could mask all but the strongest correlations of hatchling size with body size of females. There is a positive linear relation between body size of adult females and body size of hatchlings. Congdon and van Loben Sels, 1990; Packard et al")
13
Conceptueel model Via een conceptueel model kun je grafisch weergeven hoe de variabelen onderling samenhangen Zoek literatuur om je verwachtingen te onderbouwen

14
Modelontwikkeling Waarom kun je niet simpel via een enkelvoudige analyse bepalen welke voorspellers (onafhankelijke variabelen) van invloed zijn op de afhankelijke variabele? Verborgen (confounding) variabelen Interactie tussen de onafhankelijke variabelen
 van invloed zijn op de afhankelijke variabele Verborgen (confounding) variabelen. Interactie tussen de onafhankelijke variabelen.")
15
Verborgen variabelen Via een enkelvoudige analyse heb je bepaald dat mannen significant gemiddeld meer verdienen dan vrouwen. Het blijkt dat de mannen in de steekproef gemiddeld ouder zijn dan de vrouwen Ook geldt dat hoe ouder men is des te meer men verdient. Dan kun je je afvragen of de gevonden relatie tussen geslacht en inkomen niet veroorzaakt wordt door het feit dat de vrouwen in de steekproef gemiddeld jonger zijn.

16
Verborgen variabelen Dus bij het bepalen van de relatie tussen geslacht en inkomen zou leeftijd een verborgen variabele kunnen zijn. Een variabele kan alleen een verborgen variabele zijn als: De variabele van invloed is op de afhankelijke variabele (dus leeftijd moet invloed hebben op inkomen) De verdeling van de verborgen variabele is niet gelijk voor elke waarde van de onafhankelijke variabele (ofwel de verdeling van leeftijd verschilt voor de beide geslachten)
 De verdeling van de verborgen variabele is niet gelijk voor elke waarde van de onafhankelijke variabele (ofwel de verdeling van leeftijd verschilt voor de beide geslachten)")
17
Interactie tussen 2 onafhankelijke variabelen
Uit enkelvoudige analyses blijkt dat Opleiding heeft een significant invloed op besteed bedrag aan boeken (P <0,001) Geslacht heeft geen invloed op besteed bedrag aan boeken (P=0,194)
 Geslacht heeft geen invloed op besteed bedrag aan boeken (P=0,194)")
18
Interactie tussen 2 onafhankelijke variabelen
Wat we hier zien is dat het effect van geslacht op besteed bedrag aan boeken afhangt van de opleiding (bij hoge opgeleiden zien we een groot verschil tussen mannen en vrouwen terwijl dit bij de ander 2 opleidingen niet zo is) Er is dan sprake van een interactie tussen opleiding en geslacht wat betreft het effect op besteed bedrag aan boeken
 Er is dan sprake van een interactie tussen opleiding en geslacht wat betreft het effect op besteed bedrag aan boeken.")
19
Modelbouw Doelstelling: te komen tot een “best” passend model met voorspellers voor de afhankelijke variabele binnen de wetenschappelijke context van het probleem Men probeert vaak het aantal voorspellers te minimaliseren om zo een numeriek stabiel model te krijgen . Des te meer variabelen je in een model neemt des te meer het model afhangt van de gebruikte data. De verhouding tussen het aantal variabelen en de steekproefgrootte moet dus niet te klein zijn

20
Selectie van variabelen
Er zijn geautomatiseerde methoden om tot een eindmodel te komen met de “beste” voorspellers : backward-, forward- of stepwise selectie; best subset selectie ( aantal mogelijke subsets=2 𝑘 −1, met k het aantal voorspellers). Nadelen geautomatiseerde methoden: Het eindmodel bevat niet de voor het onderzoek belangrijke variabelen maar alleen maar irrelevante controle variabelen. De onderzoeker assisteert de computer om te komen tot een eindmodel terwijl het natuurlijk het omgekeerde moet gelden.
. Nadelen geautomatiseerde methoden: Het eindmodel bevat niet de voor het onderzoek belangrijke variabelen maar alleen maar irrelevante controle variabelen. De onderzoeker assisteert de computer om te komen tot een eindmodel terwijl het natuurlijk het omgekeerde moet gelden.")
21
Stappenplan modelselectie “Hosmer & Lemeshow”
Voer een enkelvoudige analyse uit voor elke voorspeller. Selecteer de voorspellers die voor het onderzoek belangrijk zijn en alle andere voorspellers (vaak controle variabelen) met een significantie P<0,25 (Bendel en Afifi (1977)) Stap 2: Voer een meervoudige analyse uit met alle voorspellers die geselecteerd zijn uit stap 1 (=model1) Verwijder niet-significante controle variabelen (P>0,05) uit het model en voer opnieuw een meervoudige analyse uit met de overgebleven voorspellers (=model2) Vergelijk het effect van elke variabele in model 2 met die van model 1. Indien hier grote verschillen tussen bestaan moet je controleren of eerder verwijderde variabelen teruggeplaatst moeten worden Stap3: Indien je verwacht dat het effect van een voorspeller op de afhankelijke variabele afhangt van een andere voorspeller voeg dan deze interactie aan het model toe en bepaal de significantie. Doe dit voor elke interactieterm apart. Alleen interactietermen die biologisch belangrijk zijn en die een P<0,1 hebben toevoegen aan het eindmodel.
 met een significantie P<0,25 (Bendel en Afifi (1977)) Stap 2: Voer een meervoudige analyse uit met alle voorspellers die geselecteerd zijn uit stap 1 (=model1) Verwijder niet-significante controle variabelen (P>0,05) uit het model en voer opnieuw een meervoudige analyse uit met de overgebleven voorspellers (=model2) Vergelijk het effect van elke variabele in model 2 met die van model 1. Indien hier grote verschillen tussen bestaan moet je controleren of eerder verwijderde variabelen teruggeplaatst moeten worden. Stap3: Indien je verwacht dat het effect van een voorspeller op de afhankelijke variabele afhangt van een andere voorspeller voeg dan deze interactie aan het model toe en bepaal de significantie. Doe dit voor elke interactieterm apart. Alleen interactietermen die biologisch belangrijk zijn en die een P<0,1 hebben toevoegen aan het eindmodel.")
22
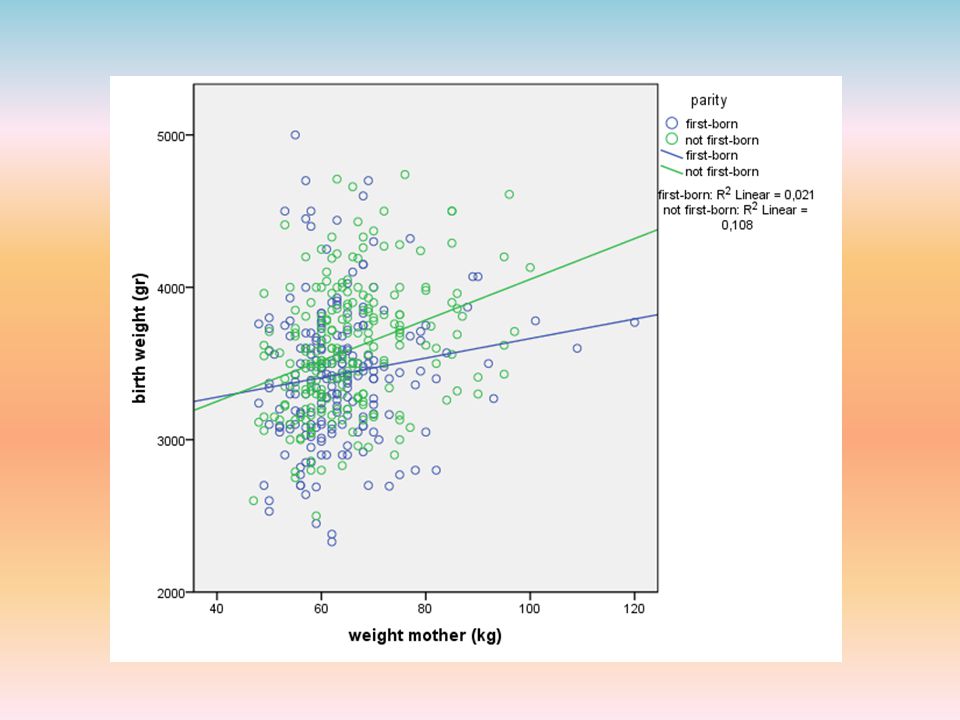
Voorbeeld stappenplan
In hoeverre hangt het geboortegewicht van een baby af van de levensstijl van de moeder? levensstijl: wel/niet roken; wel/geen alcoholgebruik controlevariabelen: kenmerken baby: geslacht; eerstgeboren (ja/nee); kenmerken moeder : lengte; gewicht; leeftijd; opleidingsniveau; stad (Groningen/Rotterdam)
; kenmerken moeder : lengte; gewicht; leeftijd; opleidingsniveau; stad (Groningen/Rotterdam)")
23
Voorbeeld stappenplan

24
Voorbeeld stappenplan
Variabele waarden meetschaal type variable GLM birth weight (gr) ratio Afhankelijke variabele age mother (yr) covariaat length mother (cm) weight mother (kg) education level mother 1<Mavo 2=Mavo 3>Mavo ordinaal fixed factor smoking mother 0=No 1=Yes nominaal use of alcohol mother sex child 0=Boy 1=Girl parity 0=First Born 1 Not First Born city 0=Groningen 1=Rotterdam
 ratio. Afhankelijke variabele. age mother (yr) covariaat. length mother (cm) weight mother (kg) education level mother. 1<Mavo 2=Mavo 3>Mavo. ordinaal. fixed factor. smoking mother. 0=No 1=Yes. nominaal. use of alcohol mother. sex child. 0=Boy 1=Girl. parity. 0=First Born 1 Not First Born. city. 0=Groningen 1=Rotterdam.")
25
Voorbeeld stappenplan (stap 1)
Variabele gebruikte enkelvoudige toets coëfficiënt (±se) significantie birth weight (gr) age mother enkelvoudige lineaire regressie -2,1±5,7 gr/yr (1) 0,714 weight mother (kg) 10,7±2,0 gr/kg (1) <0,001 length mother (cm) 14,1±3,6 gr/cm (1) education level mother variantie analyse -96,2±60,5 gr (3) -73,4±58,8 gr (4) 22,9±48,7 gr (5) 0,275 smoking mother t-toets 2 onafh. steekproeven 77,4±49,6 gr (2) 0,119 use of alcohol mother -61,1±50,0 gr (2) 0,223 sex child 93,3±43,4 gr (2) 0,032 parity -160,9±42,8 gr (2) city 98,4±43,3 gr (2) 0,023 1) richtingscoëfficiënt 2) gemiddelde verschil groep=0 en groep=1 3) gemiddeld verschil < MAVO en =MAVO 4) gemiddelde verschil <MAVO en >MAVO 5) gemiddelde verschil =MAVO en >MAVO
 significantie. birth weight (gr) age mother. enkelvoudige lineaire regressie. -2,1±5,7 gr/yr (1) 0,714. weight mother (kg) 10,7±2,0 gr/kg (1) <0,001. length mother (cm) 14,1±3,6 gr/cm (1) education level mother. variantie analyse. -96,2±60,5 gr (3) -73,4±58,8 gr (4) 22,9±48,7 gr (5) 0,275. smoking mother. t-toets 2 onafh. steekproeven. 77,4±49,6 gr (2) 0,119. use of alcohol mother. -61,1±50,0 gr (2) 0,223. sex child. 93,3±43,4 gr (2) 0,032. parity. -160,9±42,8 gr (2) city. 98,4±43,3 gr (2) 0,023. 1) richtingscoëfficiënt. 2) gemiddelde verschil groep=0 en groep=1. 3) gemiddeld verschil < MAVO en =MAVO. 4) gemiddelde verschil <MAVO en >MAVO. 5) gemiddelde verschil =MAVO en >MAVO.")
26
Voorbeeld stappenplan (stap 2)
")
27
Voorbeeld stappenplan (stap 2)
")
28
Voorbeeld stappenplan (stap 2)
Variabele coëfficiënt (±se) enkelvoudig model sign. (±se) GLM1 age mother -2,1±5,7 gr/yr 0,714 - length mother (cm) 14,1±3,6 gr/cm <0,001 6,7±3,7 gr/cm 0,076 weight mother (kg) 10,7±2,0 gr/kg 9,5±2,2 gr/kg education level mother 0,275 smoking mother (groep nee – groep ja) 77,4±49,6 gr 0,119 102,6±47,4 gr 0,031 use of alcohol mother (groep nee – groep ja) -61,1±50,0 gr 0,223 -62,5±48,5 gr 0,198 sex child (boy – girl) 93,3±43,4 gr 0,032 108,2±41,7 gr 0,010 Parity (eerstgeborene- niet 1e geborene) -160,9±42,8 gr -144,2±41,4 gr 0,001 City (groningen-rotterdam) 98,4±43,3 gr 0,023 66,3±42,6 gr 0,120
 enkelvoudig model. sign. (±se) GLM1. age mother. -2,1±5,7 gr/yr. 0, length mother (cm) 14,1±3,6 gr/cm. <0,001. 6,7±3,7 gr/cm. 0,076. weight mother (kg) 10,7±2,0 gr/kg. 9,5±2,2 gr/kg. education level mother. 0,275. smoking mother (groep nee – groep ja) 77,4±49,6 gr. 0, ,6±47,4 gr. 0,031. use of alcohol mother. (groep nee – groep ja) -61,1±50,0 gr. 0, ,5±48,5 gr. 0,198. sex child. (boy – girl) 93,3±43,4 gr. 0, ,2±41,7 gr. 0,010. Parity. (eerstgeborene- niet 1e geborene) -160,9±42,8 gr. -144,2±41,4 gr. 0,001. City (groningen-rotterdam) 98,4±43,3 gr. 0, ,3±42,6 gr. 0,120.")
29
Voorbeeld stappenplan (stap 2)
")
30
Voorbeeld stappenplan (stap 2)
Variabele coëfficiënt (±se) enkelvoudig model sign. (±se) GLM1 GLM2 age mother -2,1±5,7 gr/yr 0,714 - length mother (cm) 14,1±3,6 gr/cm <0,001 6,7±3,7 gr/cm 0,076 weight mother (kg) 10,7±2,0 gr/kg 9,5±2,2 gr/kg 11,0±2,0 gr/kg education level mother 0,275 smoking mother (groep nee – groep ja) 77,4±49,6 gr 0,119 102,6±47,4 gr 0,031 102,4±47,5gr 0,032 use of alcohol mother (groep nee – groep ja) -61,1±50,0 gr 0,223 -62,5±48,5 gr 0,198 -88,0 ±47,4 0,064 sex child (boy – girl) 93,3±43,4 gr 108,2±41,7 gr 0,010 117,0±41,6 gr 0,005 Parity (eerstgeborene- niet 1e geborene) -160,9±42,8 gr -144,2±41,4 gr 0,001 -140,5±41,5 gr City (groningen-rotterdam) 98,4±43,3 gr 0,023 66,3±42,6 gr 0,120
 enkelvoudig model. sign. (±se) GLM1. GLM2. age mother. -2,1±5,7 gr/yr. 0, length mother (cm) 14,1±3,6 gr/cm. <0,001. 6,7±3,7 gr/cm. 0,076. weight mother (kg) 10,7±2,0 gr/kg. 9,5±2,2 gr/kg. 11,0±2,0 gr/kg. education level mother. 0,275. smoking mother (groep nee – groep ja) 77,4±49,6 gr. 0, ,6±47,4 gr. 0, ,4±47,5gr. 0,032. use of alcohol mother. (groep nee – groep ja) -61,1±50,0 gr. 0, ,5±48,5 gr. 0, ,0 ±47,4. 0,064. sex child. (boy – girl) 93,3±43,4 gr. 108,2±41,7 gr. 0, ,0±41,6 gr. 0,005. Parity. (eerstgeborene- niet 1e geborene) -160,9±42,8 gr. -144,2±41,4 gr. 0, ,5±41,5 gr. City (groningen-rotterdam) 98,4±43,3 gr. 0, ,3±42,6 gr. 0,120.")
31
Voorbeeld stappenplan (stap 3)
Interactie sign. R2adj alleen hoofdeffecten (GLM2) 0,112 smoking mother*use alcohol 0,790 0,110 smoking mother* parity 0,255 smoking mother* weight mother 0,838 smoking mother* sex child 0,789 use alcohol*sex 0,931 use alcohol*parity 0,378 0,111 use alcohol* weight mother 0,995 sex child *parity 0,554 sex child* weight mother 0,824 parity*weight mother 0,023 0,121
 0,112. smoking mother*use alcohol. 0,790. 0,110. smoking mother* parity. 0,255. smoking mother* weight mother. 0,838. smoking mother* sex child. 0,789. use alcohol*sex. 0,931. use alcohol*parity. 0,378. 0,111. use alcohol* weight mother. 0,995. sex child *parity. 0,554. sex child* weight mother. 0,824. parity*weight mother. 0,023. 0,121.")
32
Voorbeeld stappenplan (stap 3)
")
33
Voorbeeld stappenplan (stap 3)
")
35
Veel voorkomende problemen
multicollineariteit (sterke relaties tussen de voorspellers). Deze zorgt voor hogere waarden van de standaard errors van de coëfficiënten van de voorspellers in het model waardoor deze minder snel significant van nul verschillen. Factoren waarbij bepaalde klassen ondervertegenwoordigd zijn. Covariaten waarbij je niet over het hele bereik waarnemingen hebt. Covariaten die een heel scheve verdeling bezitten. Niet lineaire relaties tussen de voorspeller (covariaat) en de afhankelijke variabele. Afhankelijke waarnemingen of meerdere waarnemingen aan 1 subject Uitbijters (outliers) Niet voldoen aan de eisen van de multivariate techniek (ook vaak het gevolg van bovenstaande problemen)
. Deze zorgt voor hogere waarden van de standaard errors van de coëfficiënten van de voorspellers in het model waardoor deze minder snel significant van nul verschillen. Factoren waarbij bepaalde klassen ondervertegenwoordigd zijn. Covariaten waarbij je niet over het hele bereik waarnemingen hebt. Covariaten die een heel scheve verdeling bezitten. Niet lineaire relaties tussen de voorspeller (covariaat) en de afhankelijke variabele. Afhankelijke waarnemingen of meerdere waarnemingen aan 1 subject. Uitbijters (outliers) Niet voldoen aan de eisen van de multivariate techniek (ook vaak het gevolg van bovenstaande problemen)")
Verwante presentaties



















![Deltion College Engels B1 Schrijven [Edu/004]/ subvaardigheid lezen thema: reporting a theft can-do : kan formulieren waarin meer informatie gevraagd wordt,](/9/2250314/big_thumb.jpg "Deltion College Engels B1 Schrijven [Edu/004]/ subvaardigheid lezen thema: reporting a theft can-do : kan formulieren waarin meer informatie gevraagd wordt,>")