Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Gegevensverwerving en verwerking
Bibliotheek Staalname - aantal stalen/replicaten - grootte staal - apparatuur Statistiek - beschrijvend - variantie-analyse - correlatie - regressie - ordinatie - classificatie Experimentele setup Websites : => electronic statistic textbook allserv.rug.ac/ ~katdhond/ => reservatie PC zalen / ~gdsmet/MarBiolwebsite/ => lesnota’s

2
Y = a + bX SSregr. SSY SSres SSregr. R² = -------- SSY
Eenvoudige lineaire regressie Y = a + bX Vergelijking van een rechte : => residuelen zo klein mogelijk houden bij bepalen van a en b door de METHODE van de KLEINSTE KWADRATEN SSregr. SSY SSres Volgt bij benadering een F-distributie met 1 en n-2 vrijheidsgraden indien b=0 Dus indien F > F tabel => Regressie is significant SSregr. R² = SSY R² geeft weer hoeveel % variatie in Y kan worden toegeschreven aan een lineaire relatie met X De overige variatie is willekeurig.

3
Voorwaarden : (zelfde als bij parametrische testen => F-test en t-test
- alle variabelen zijn normaal verdeeld - er zijn geen residuele uitbijters => residuele analyse * e is een willekeurige variabele met een constante variantie * e ‘s zijn onderling onafhankelijk * e’s zijn normaal verdeeld. => op zoek naar uitbijters : sterke impact op regressielijn - wanneer e > gemiddelde e waarde ± 3 SD - ‘deleted residual’ = residuele van een waarneming, indien deze niet in de analyse zou zijn inbegrepen plot van residuelen tov ‘deleted residuals’

4
Test van residuelen

5
Voorbeeld : eenvoudige lineaire regressie

7
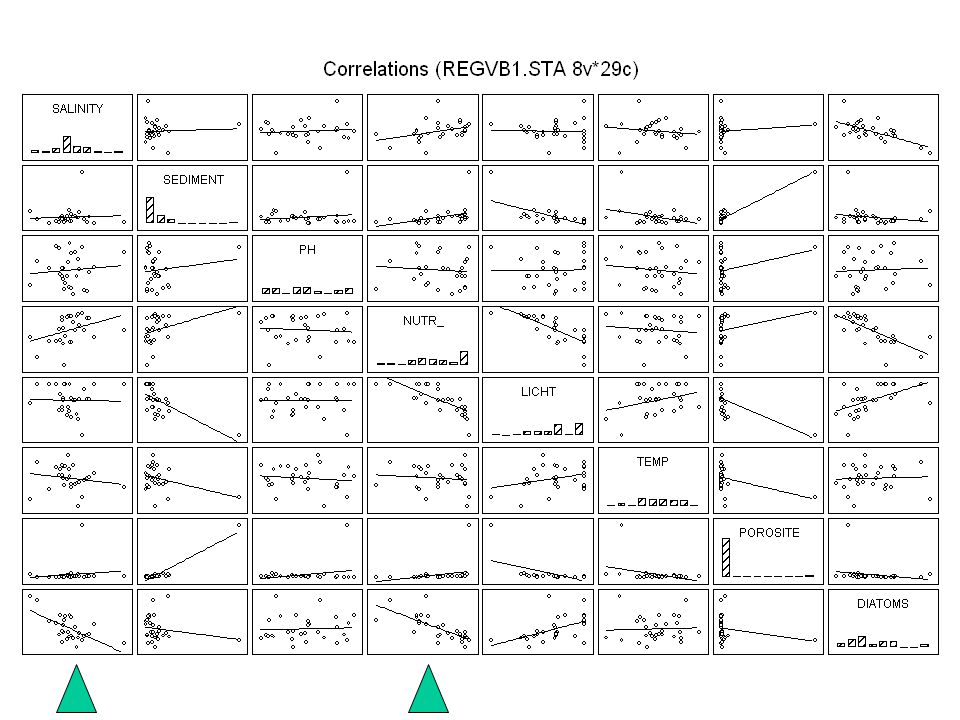
Correlations (regvb1.sta)
SALINITY SEDIMENT PH NUTR_ LICHT TEMP POROSITE DIATOMS SALINITY SEDIMENT PH NUTR_ LICHT TEMP POROSITE DIATOMS

8
Y as X as

9
Besluit: 41.5 % van variatie in aantal diatomeeën wordt verklaard
Regression Summary for Dependent Variable: DIATOMS R= R²= Adjusted R²= F(1,27)= p< Std.Error of estimate: St. Err St. Err. BETA of BETA B of B t(27) p-level Intercpt SALINITY Besluit: % van variatie in aantal diatomeeën wordt verklaard door saliniteit. Daar p <0.05 kan de regressielijn gezien worden als een betrouwbare schatting diat. = saliniteit. => model , voorspellingen ????
= p< Std.Error of estimate: St. Err. St. Err. BETA of BETA B of B t(27) p-level. Intercpt SALINITY Besluit: 41.5 % van variatie in aantal diatomeeën wordt verklaard. door saliniteit. Daar p <0.05 kan de regressielijn gezien worden als een betrouwbare schatting. diat. = saliniteit. => model , voorspellingen")
10
Y = a + b1X1 + b2X2+…….bkXk Multiple lineaire regressie
Twee of meer (k) onafhankelijke variabelen Y = a + b1X1 + b2X2+…….bkXk Vergelijking : Licht X1 temperatuurX2 nutrientenXk…….. Groei Y Onafhankelijke Afhankelijke variabelen
 onafhankelijke variabelen. Y = a + b1X1 + b2X2+…….bkXk. Vergelijking : Licht X1. temperatuurX2. nutrientenXk…….. Groei Y. Onafhankelijke. Afhankelijke. variabelen.")
11
Y = a + bX Y = a + b1X1 + b2X2+…….bkXk
a en b zijn parameters of constanten a = waarde van Y als X = 0 ; = snijpunt Y as b = aantal eenheden dat Y verandert als X met één eenheid verandert; = helling of REGRESSIE-COEFFICIENT Y = a + b1X1 + b2X2+…….bkXk b1 = verwachte verandering in Y wanneer X1 met één eenheid verandert terwijl X2 constant is b2 =idem voor X2 met X1 constant => PARTIËLE REGRESSIE-COËFFICIENTEN

12
Gestandardiseerde partiële regressie-coëfficienten , ’s
Y en Xen uitgedrukt in verschillende eenheden=> a en b’s onderling niet vergelijkbaar. Daarom Y en Xen gestandardiseerd (naar dezelfde éénheid-variantie) ==> afgeleide regressie-coëfficienten zijn een maat voor relatief belang van elke onafhankelijke variabele op de afhankelijke variabele. =0 Y = 1X1 + 2X2+……. kXk
 ==> afgeleide regressie-coëfficienten zijn een maat voor relatief belang. van elke onafhankelijke variabele op de afhankelijke variabele. =0. Y = 1X1 + 2X2+……. kXk.")
13
- meer data dan onafhankelijke variabelen (10 tot 20 maal)
Beperkingen - meer data dan onafhankelijke variabelen (10 tot 20 maal) - de onafhankelijke variabelen mogen niet overlappend zijn (‘redundancy’) Tolerantie-waarde : 1-R² R² van de regressie met één bepaalde onafhankelijke variabele als afhankelijke variabele, en de overige onafhankelijke variabelen als onafhankelijke variabelen Hoe kleiner de tolerantie-waarde, hoe meer overlap er is tussen deze variabele met de overige onafhankelijke variabelen. => aanvaardbaar minimum van 0.01 => er is een overlap van 99%
 - de onafhankelijke variabelen mogen niet overlappend zijn (‘redundancy’) Tolerantie-waarde : 1-R². R² van de regressie met één bepaalde onafhankelijke variabele als. afhankelijke variabele, en de overige onafhankelijke variabelen als. onafhankelijke variabelen. Hoe kleiner de tolerantie-waarde, hoe meer overlap er is tussen deze. variabele met de overige onafhankelijke variabelen. => aanvaardbaar minimum van 0.01 => er is een overlap van 99%")
14
Betrouwbaarheid van de schatting :
ANOVA : F-test => totale significantie t-test => partiële significantie standard error van de schatting R² ratio (aangepast naar aantal vrijheidsgraden) => neemt aantal waarnemingen en aantal onafhankelijke variabelen in rekening = betere maat voor de variatie verklaard door de regressie dan R²
 => neemt aantal waarnemingen en aantal onafhankelijke variabelen in rekening. = betere maat voor de variatie verklaard door de regressie dan R².")
15
t-test => partiële significantie
t-test kan grebruikt worden om na te gaan of b=0 In geval van één onafhankelijke variabele is t-test gelijk aan F-test meer partiële significantie test voor elke onafhankelijke variabele apart H0 b=0 t =(geschatte b - verwachte b) / SEb Deze t waarde wordt vergeleken met een getabelleerde t-waarde van een Student’s t distributie met n-2 vrijheidsgraden. Indien t > t (tabel) => b is niet gelijk aan 0 => sigificante bijdrage van X < b is gelijk aan 0 => geen significante bijdrage van X
 / SEb. Deze t waarde wordt vergeleken met een getabelleerde t-waarde. van een Student’s t distributie met n-2 vrijheidsgraden. Indien t > t (tabel) => b is niet gelijk aan 0 => sigificante bijdrage van X. < b is gelijk aan 0 => geen significante bijdrage van X.")
16
Selectie van de onafhankelijke variabelen :
Stel groot aantal potentiële onafhankelijke variabelen => welke set van onafhankelijke variabelen geeft de beste voorspelling van Y? Voorwaartse selectie => F to enter Achterwaartse selectie => F to remove (al of niet stapsgewijze selectie) Diverse strategieën : Selectie-criteria: t-waarde tolerantie > 0.1 Voorwaarts : => selectie van de beste predictor (grootste F waarde) => vervolgens wordt de volgende onafhankelijke variabele geselecteerd die de F waarde het meest verhoogt; enzovoort to de selectie criteria niet langer voldaan zijn.
 Diverse strategieën : Selectie-criteria: t-waarde. tolerantie > 0.1. Voorwaarts : => selectie van de beste predictor (grootste F waarde) => vervolgens wordt de volgende onafhankelijke variabele geselecteerd. die de F waarde het meest verhoogt; enzovoort to de selectie criteria niet. langer voldaan zijn.")
17
Voorbeeld : multiple lineaire regressie

18
Regression Summary for Dependent Variable: DIATOMS
R= R²= Adjusted R²= F(7,21)= p< Std.Error of estimate: St. Err St. Err. BETA of BETA B of B t(21) p-level Intercpt SALINITY SEDIMENT PH NUTR_ LICHT TEMP POROSITE Analysis of Variance; DV: DIATOMS (regvb1.sta) Sums of Mean Squares df Squares F p-level Regress Residual Total
= p< Std.Error of estimate: St. Err. St. Err. BETA of BETA B of B t(21) p-level. Intercpt SALINITY SEDIMENT PH NUTR_ LICHT TEMP POROSITE Analysis of Variance; DV: DIATOMS (regvb1.sta) Sums of Mean. Squares df Squares F p-level. Regress Residual Total")
19
Achterwaartse selectie
Regression Summary for Dependent Variable: DIATOMS R= R²= Adjusted R²= F(5,23)= p< Std.Error of estimate: St. Err St. Err. BETA of BETA B of B t(23) p-level Intercpt NUTR_ SALINITY LICHT SEDIMENT TEMP Voorwaartse selectie Regression Summary for Dependent Variable: DIATOMS R= R²= Adjusted R²= F(2,26)= p< Std.Error of estimate: St. Err St. Err. BETA of BETA B of B t(26) p-level Intercpt SALINITY LICHT Achterwaartse selectie
= p< Std.Error of estimate: St. Err. St. Err. BETA of BETA B of B t(23) p-level. Intercpt NUTR_ SALINITY LICHT SEDIMENT TEMP Voorwaartse selectie. Regression Summary for Dependent Variable: DIATOMS. R= R²= Adjusted R²= F(2,26)= p< Std.Error of estimate: St. Err. St. Err. BETA of BETA B of B t(26) p-level. Intercpt SALINITY LICHT Achterwaartse selectie.")
20
Tolerantie waarde : 1 – R²
Redundancy of Independent Variables; DV: DIATOMS (regvb1.sta) R-square column contains R-square of respective variable with all other independent variables Partial Semipart Toleran. R-square Cor. Cor. SALINITY LICHT PH NUTR_ POROSITE TEMP SEDIMENT
 R-square column contains R-square of respective. variable with all other independent variables. Partial Semipart. Toleran. R-square Cor. Cor. SALINITY LICHT PH NUTR_ POROSITE TEMP SEDIMENT")
21
Regression Summary for Dependent Variable: DIATOMS
R= R²= Adjusted R²= F(2,26)= p< Std.Error of estimate: St. Err St. Err. BETA of BETA B of B t(26) p-level Intercpt SALINITY LICHT Diatom. = –0.393sal licht Analysis of Variance; DV: DIATOMS (regvb1.sta) Sums of Mean Squares df Squares F p-level Regress Residual Total
= p< Std.Error of estimate: St. Err. St. Err. BETA of BETA B of B t(26) p-level. Intercpt SALINITY LICHT Diatom. = –0.393sal licht. Analysis of Variance; DV: DIATOMS (regvb1.sta) Sums of Mean. Squares df Squares F p-level. Regress Residual Total")
22
Residuelen normaal verdeeld ?

23
Geen residuele uitbijters ??

24
Gezien aan de assumpties is voldaan=> Besluit :
% van de variatie in aantal diatomeeën wordt verklaard door de combinatie van licht en saliniteit. Adjusted R²= de regressie is significant (totaal F > Ftab en partieel (t-testen) Diatom. = –0.393sal licht het belang van beide onafhankelijke variabelen is ongeveer even groot. BETA SALINITY LICHT
 Diatom. = –0.393sal licht. het belang van beide onafhankelijke variabelen. is ongeveer even groot. BETA. SALINITY LICHT")
25
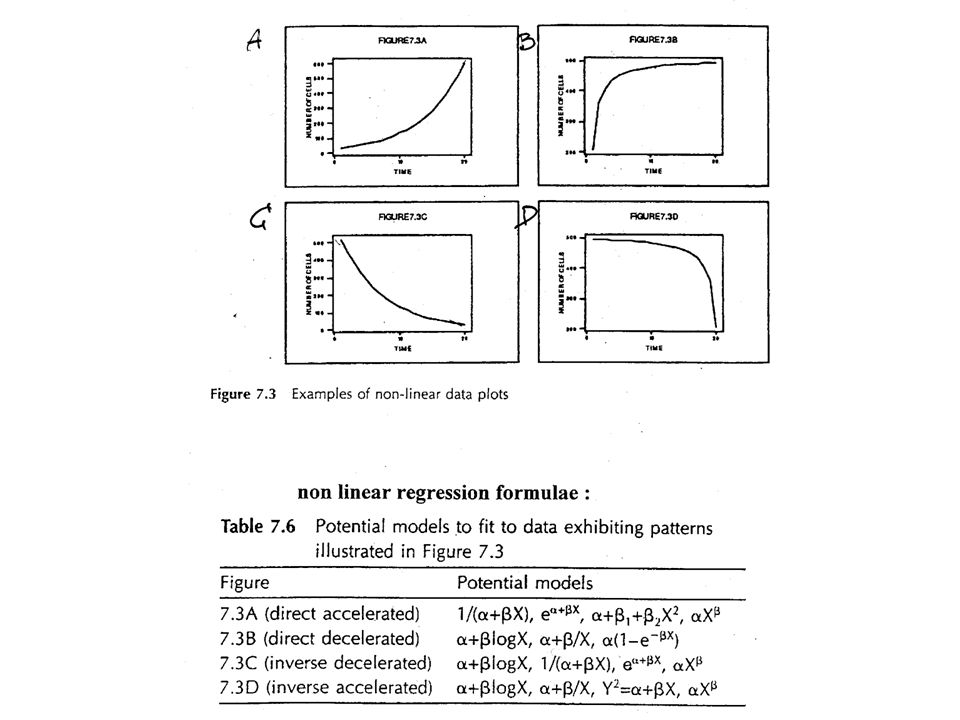
Bemerkingen : - Y vertoont willekeurige variatie X niet (of voldoende klein) : Model I X wel : Model II - stel geen lineaire relatie tussen X en Y => transformatie (indien intrinsiek lineair) => andere dan lineaire functie
 => andere dan lineaire functie.")
Verwante presentaties








>")










