Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Help! Statistiek! Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Derde woensdag in de maand, uur 21 mei multiple testing 18 juni statistische aspecten van de probiotica studie 17 sept … Sprekers: Vaclav Fidler, Hans Burgerhof, Wendy Post DG Epidemiologie

2
Multiple testing Wat is het (klassieke) probleem?
“klassieke” oplossingen Recenter probleem Nieuwe oplossingen

3
Fouten van eerste en tweede soort bij het uitvoeren van een statistische toets
Hebben mannen en vrouwen gemiddeld dezelfde bloeddruk (BD)? H0: gemiddelde BD mannen = gemiddelde BD vrouwen Beslissing H0 waar H0 niet waar Werkelijkheid OK Fout van de eerste soort, kans hierop: α Fout van de tweede soort, kans hierop: β
 H0: gemiddelde BD mannen = gemiddelde BD vrouwen. Beslissing. H0 waar. H0 niet waar. Werkelijkheid. OK. Fout van de eerste soort, kans hierop: α. Fout van de tweede soort, kans hierop: β.")
4
Het klassieke probleem van de multiple testing
Bij een statistische toets hanteren we significantieniveau α (in de regel 0,05). Dat wil zeggen dat we een kans ter grootte van α accepteren om ten onrechte de nulhypothese te verwerpen Dit wordt ook wel de Comparison-wise error rate (CWER) genoemd Wat betekent het uitvoeren van meerdere onafhankelijke toetsen voor de totale kans om minstens één nulhypothese ten onrechte te verwerpen (als alle nulhypothesen waar zijn)? “Overall alpha” Family-wise error rate (FWER) Kanskapitalisatie!
. Dat wil zeggen dat we een kans ter grootte van α accepteren om ten onrechte de nulhypothese te verwerpen. Dit wordt ook wel de Comparison-wise error rate (CWER) genoemd. Wat betekent het uitvoeren van meerdere onafhankelijke toetsen voor de totale kans om minstens één nulhypothese ten onrechte te verwerpen (als alle nulhypothesen waar zijn) Overall alpha Family-wise error rate (FWER) Kanskapitalisatie!")
5
FWER en CWER Als we n onafhankelijke toetsen uitvoeren, elk met een CWER = 0,05, geldt Aantal toetsen overall alpha n FWER 3 0,143 10 0,401 ,994

6
Klassieke oplossingen
In een ANOVA worden k groepen met elkaar vergeleken met betrekking tot een normaal verdeelde responsievariabele Y. Als de ANOVA significant is, willen we weten welke groepen verschillen. Als we alle paarsgewijze vergelijkingen willen doen, moeten we toetsen uitvoeren. Bijvoorbeeld: 4 groepen 4*3/2 = 6 toetsen

7
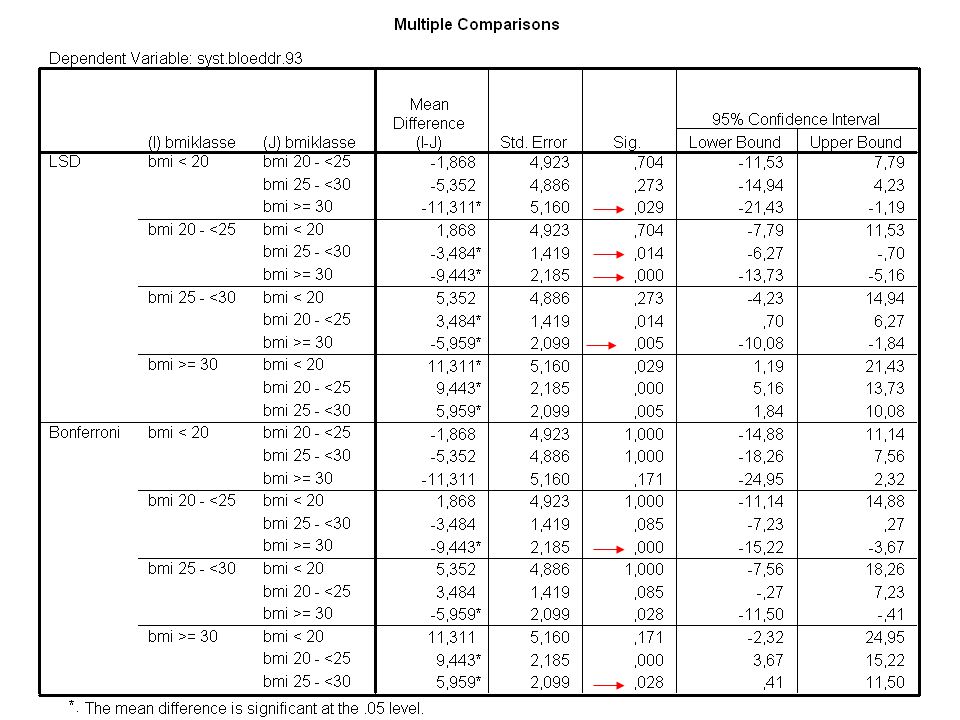
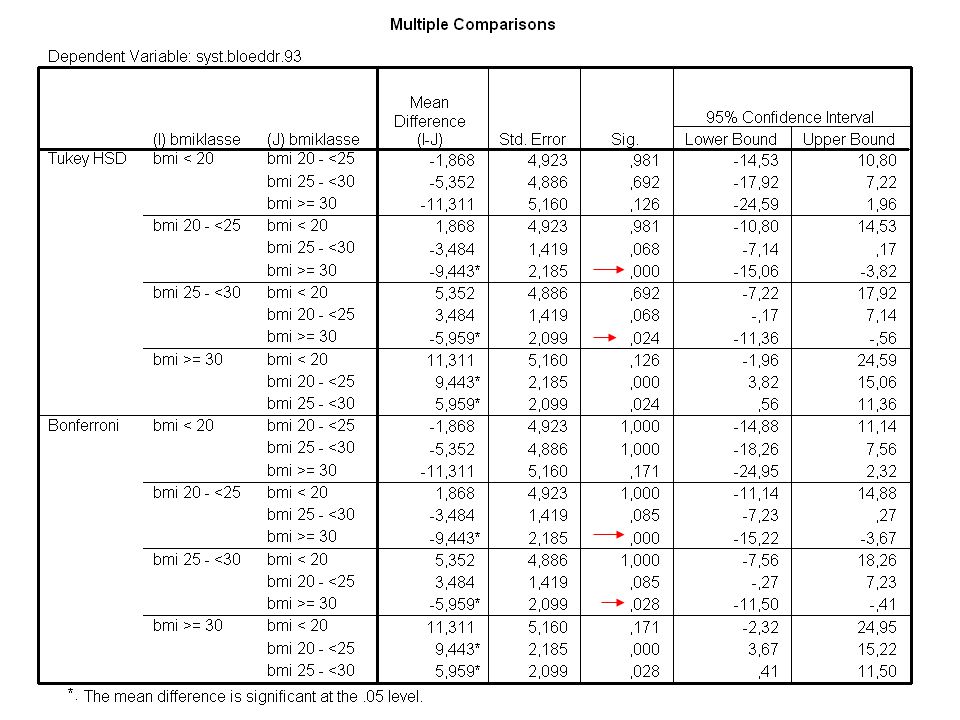
Post-hoc toetsen Zorg dat je de FWER (overall-alpha) beheerst na een ANOVA Er zijn vele Post-hoc toetsen, optimaal onder verschillende omstandigheden, o.a. - LSD: paarsgewijze t-toetsen met SD op basis van alle groepen - Bonferroni: als LSD met aangepaste α per toets CWER = α / (aantal uitgevoerde toetsen) (in SPSS aangepaste P-waarde) - Bonferroni-Holm: step-down procedure op geordende P-waarden (verschillende α per toets) - Tukey: gebaseerd op kritieke waarden uit de “studentized range statistic” - Scheffé: voor lineaire combinaties van gemiddelden
 (in SPSS aangepaste P-waarde) - Bonferroni-Holm: step-down procedure op geordende P-waarden (verschillende α per toets) - Tukey: gebaseerd op kritieke waarden uit de studentized range statistic - Scheffé: voor lineaire combinaties van gemiddelden.")
8
Post-hoc toetsen in SPSS

11
Multiple testing is niet alleen een ANOVA probleem
Bij meervoudige lineaire regressie speelt eveneens het probleem van kanskapitalisatie Vergelijk ANOVA met lineaire regressie met een nominale verklarende variabele Toetsen van diverse lineaire modellen geeft ook kanskapitalisatie

12
Parametervrije toetsen
Wat te doen na een significante Kruskal-Wallis? Paarsgewijze Mann-Whitney toetsen met Bonferroni gecorrigeerde P-waarden? Conover (Practical nonparametric statistics, 1999):
:")
13
Recenter probleem: Micro-array analyse
Bij toetsen op duizenden genen is de klassieke manier (beheersen van FWER) te conservatief Voorselectie van interessante genen: een vals positief resultaat is niet zo’n ramp terwijl een vals negatief resultaat als meer vervelend wordt ervaren Hedenfalk e.a. (2001); 3226 genen bij vrouwen met borstkanker (BRCA1-gen versus BRCA2-gen) We zoeken een ander criterium: de FDR (false discovery rate)
 te conservatief. Voorselectie van interessante genen: een vals positief resultaat is niet zo’n ramp terwijl een vals negatief resultaat als meer vervelend wordt ervaren. Hedenfalk e.a. (2001); 3226 genen bij vrouwen met borstkanker (BRCA1-gen versus BRCA2-gen) We zoeken een ander criterium: de FDR (false discovery rate)")
14
Sequentiële FDR (Benjamini en Hochberg, 1995)
FDR = de verwachte proportie van de verworpen nulhypotheses die ten onrechte verworpen is niet significant totaal significant Ware nulhypothesen U V m0 Niet ware nulhypothesen T S m1 m – R R m Alleen m bekend Alleen R wordt waargenomen! FDR = E(V/R)
")
15
De FDR niet significant totaal significant Ware nulhypothesen U V m0
Niet ware nulhypothesen T S m1 m – R R m Benjamini en Hochberg (1995): als alle nulhypothesen waar zijn, dus T = S = m1 = 0, heeft het controleren van de FDR tot gevolg dat de FWER gecontroleerd wordt (dus de overall-alpha blijft binnen de gedefinieerde grens)
: als alle nulhypothesen waar zijn, dus T = S = m1 = 0, heeft het. controleren van de FDR tot gevolg dat de FWER gecontroleerd wordt. (dus de overall-alpha blijft binnen de gedefinieerde grens)")
16
Over de FDR Als er in werkelijkheid wel nulhypothesen onwaar zijn, is FDR kleiner of gelijk aan FWER. Controle van FDR betekent niet langer controle van FWER, maar geeft meer power. Hoe meer nulhypotheses onwaar zijn, hoe groter de winst in power

17
Multiple testing volgens Benjamini en Hochberg: Sequentiële FDR procedure
m nulhypothesen: H1, H2, … , Hm m P-waarden: P1, P2, … , Pm Geordend: P(1) ≤ P(2) ≤ … ≤ P(m) Zoek de grootste i waarvoor geldt q = gekozen niveau van controle (bv 0,05) En verwerp alle H(i) i = 1, 2, … , k Vergelijk Bonferroni (Holm)
 ≤ P(2) ≤ … ≤ P(m) Zoek de grootste i waarvoor geldt. q = gekozen niveau van controle (bv 0,05) En verwerp alle H(i) i = 1, 2, … , k. Vergelijk. Bonferroni (Holm)")
18
Voorbeeld (Benjamini en Hochberg)
15 toetsen Geordende P-waarden: P(1) P(2) P(3) P(4) P(5) P(6) P(14) P(15) 0, , , , , ,0278 … 0, ,00 Vergelijk iedere P(i) met (i/15)*0,05, te beginnen met P(15) (stepup) 1 > (15/15)*0,05 0,7590 > (14/15)*0,05 = 0,047 … 0,0201 > (5/15)*0,05 = 0,017 0,0095 < (4/15)*0,05 = 0,013 Bonferroni: α = 0,05/15 = 0,0033 Verwerp H(1) t/m H(4)
 P(2) P(3) P(4) P(5) P(6) P(14) P(15) 0,0001 0,0004 0,0019 0,0095 0,0201 0,0278 … 0,7590 1,00. Vergelijk iedere P(i) met (i/15)*0,05, te beginnen met P(15) (stepup) 1 > (15/15)*0,05. 0,7590 > (14/15)*0,05 = 0,047. … 0,0201 > (5/15)*0,05 = 0,017. 0,0095 < (4/15)*0,05 = 0,013. Bonferroni: α = 0,05/15 = 0,0033. Verwerp H(1) t/m H(4)")
19
FDR nader bekeken Sequentiële FDR conservatief, met name als het aantal onware nulhypothesen relatief groot is Benjamini e.a. (2001): tweestapsprocedure waarbij na de eerste stap de proportie ware nulhypothesen (π0) wordt geschat en in de tweede wordt gebruikt om de grens q aan te passen Storey (2002): directe wijze om π0 te schatten
: tweestapsprocedure waarbij na de eerste stap de proportie ware nulhypothesen (π0) wordt geschat en in de tweede wordt gebruikt om de grens q aan te passen. Storey (2002): directe wijze om π0 te schatten.")
20
Het schatten van π0 We willen π0 = m0/m schatten
niet significant totaal significant Ware nulhypothesen U V m0 Niet ware nulhypothesen T S m1 m – R R m

21
H0: µ = 100 steekproef Wat verwacht je van de P-waarde? Als H0 waar is

22
is de P-waarde uniform verdeeld op [0,1]
H0: µ = 100 Gebieden met gelijke oppervlaktes Als H0 waar is … is de P-waarde uniform verdeeld op [0,1]
![is de P-waarde uniform verdeeld op [0,1]](http://slideplayer.nl/slide/2178724/8/images/22/is+de+P-waarde+uniform+verdeeld+op+%5B0%2C1%5D.jpg "H0: µ = 100. Gebieden met. gelijke oppervlaktes. Als H0 waar is … is de P-waarde uniform verdeeld op [0,1]")
23
Als de nulhypothese niet waar is
Is de P-waarde niet uniform verdeeld op het interval [0 ; 1], maar zul je relatief vaker een kleine P-waarde vinden Aantal P-waarden P-waarden uit m1 P-waarden uit m0 1

24
3226 genen (BRCA data) Verwacht aantal P-waarden >
is (1 - )*m0 + klein deel m1, dus m0 ≈ #{P>} / (1-)
*m0 + klein deel m1, dus. m0 ≈ #{P>} / (1-) ")
25
π0 als functie van

26
Concreet voorbeeld (Hedenfalk)
3226 toetsen P < 0,001: 51 significant P < 0,0001: 10 significant Bonferroni: α = 0,05/3226 = 0,000015 FDR (Storey): q = 0,05 geeft 160 significante genen (waarvan er vermoedelijk 8 ten onrechte)
: q = 0,05 geeft 160 significante genen (waarvan er vermoedelijk 8 ten onrechte)")
27
Gebruik FDR FDR wordt gebruikt voor
Correctie multiple testing (sequentiële FDR, Benjamini en Hochberg) Variabele selectie (Ghosh) Vergelijken van (nieuwe) statistische methoden. Bij gelijk aantal verworpen nulhypothesen is de methode met de kleinste FDR de beste methode
 Variabele selectie (Ghosh) Vergelijken van (nieuwe) statistische methoden. Bij gelijk aantal verworpen nulhypothesen is de methode met de kleinste FDR de beste methode.")
28
literatuur Conover, Practical nonparametric statistics (Wiley 1999)
Benjamini en Hochberg, Controlling the False Discovery Rate: a practical and powerful approach to multiple testing (Journal Royal Stat. Soc. B, 1995) Benjamini, Krieger, Yekutieli: Two staged linear step up FDR controlling procedure (Technical report 2001) Nguyen, On estimating the proportion of true null hypotheses for false discovery rate controlling procedures in exploratory DNA microarray studies (Computational statistics and data analysis, 2004) Storey, A direct approach to false discovery rates (Journal Royal Stat. Soc. B, 2002) Ghosh e.a., the false discovery rate: a variable selection perspective (J. Stat. Plan. Infer., 2004)
 Benjamini, Krieger, Yekutieli: Two staged linear step up FDR controlling procedure (Technical report 2001) Nguyen, On estimating the proportion of true null hypotheses for false discovery rate controlling procedures in exploratory DNA microarray studies (Computational statistics and data analysis, 2004) Storey, A direct approach to false discovery rates (Journal Royal Stat. Soc. B, 2002) Ghosh e.a., the false discovery rate: a variable selection perspective (J. Stat. Plan. Infer., 2004)")
29
Volgende lezing 18 juni statistische aspecten van de probiotica studie

Verwante presentaties