Hidden Markov Models Introductie Project: 1. Initializatie 2. Training
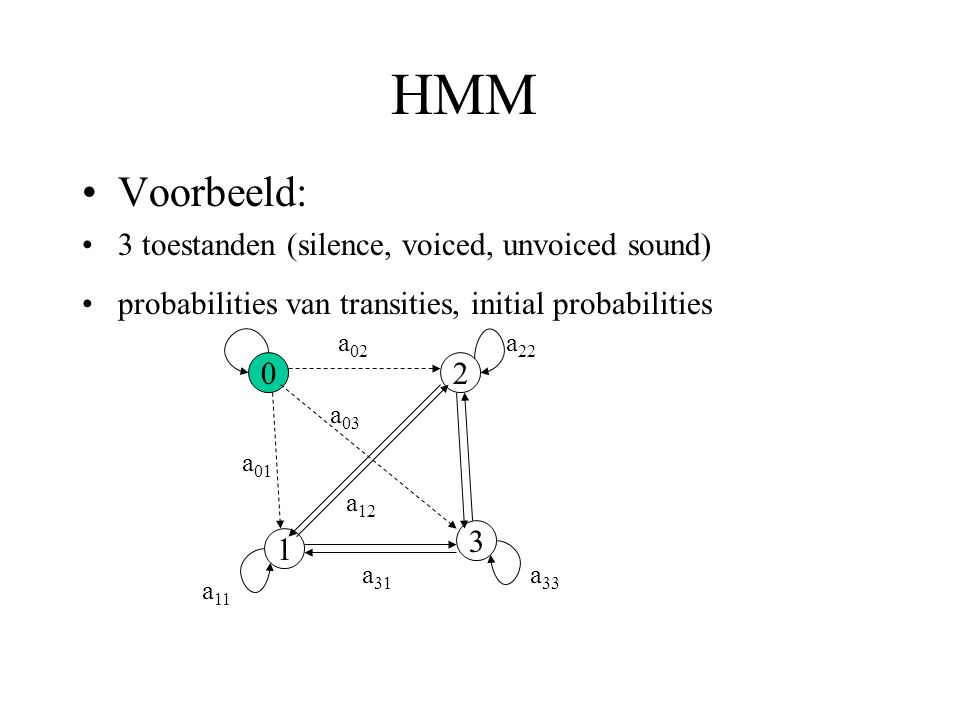
HMM Voorbeeld: 3 toestanden (silence, voiced, unvoiced sound) probabilities van transities, initial probabilities a 02 a 03 a 01 a 31 a 12 a 22 a 33 a 11
HMM in spraak herkennen Recognition Feature extraction Training HMM Y S Θ Y S*S* Y-feature vector of observations, S-sequence of linguistic units Find the correct sequence of linguistic units S for given Y. Bouwen van HMM gebaseerd op observation sequences Y en bijhorende state sequences S. Herkennen van spraak op basis van models Θ en actuele observatie.
Initializatie Initialization Training HMM phoneme parameters Speech data Phoneme labels Speech data Phoneme labels Initialization module computes the HMM parameters first guess using preprocessed speech data, and their associated phoneme labels.
Voor iedere phoneme moet een HMM model gemaakt worden. Dat betekent dat aan elke toestand wordt een probability density function P(y| s = i ) toegekend. P(y| s = i ) wordt beschreven als mengsel van multidimensional Gaussian pdf’s. De parameters μ i - mean, c i - gewicht, U i - covariance matrix moeten bepaald worden aan de hand van acoustic labeled data (y,λ), waar λ de label van de phoneme is. Initialization of M=M’+1 Gaussian model Initialization of one Gaussian HMM Initialization Training M’=final number of Gaussians M’=M no yes μ1U1μ1U1 μ 1... μ M’ U 1 …U M’ M’ =1 (y,λ)
Berekenen van one Gaussian HMM model Functie Sectionate bepaalt de toestaand voor elke (y,λ). In functie Calculate_One_Mixture_Codebook worden de pdf parameters bepaald. Sectionate Calculate_One Mixture_Codebook HMM models (y,λ) (y,λ,s) Training (y,λ) HMM models (μ,U) Initialization module
Training Training is implementatie van Baum-Welch algorithme. Gedurende initializatie hebben we een HMM phoneme model Θ van N toestanden en M Gaussians per toestand. Met Baum-Welch kunnen we een new model Θ’ vinden die beter hoort bij observation data y.