Latente semantische analyse (LSA) en erkenning van EVC’s: wat kunnen we ermee? Jan van Bruggen Ellen Rusman Bas Giesbers Oktober 2005
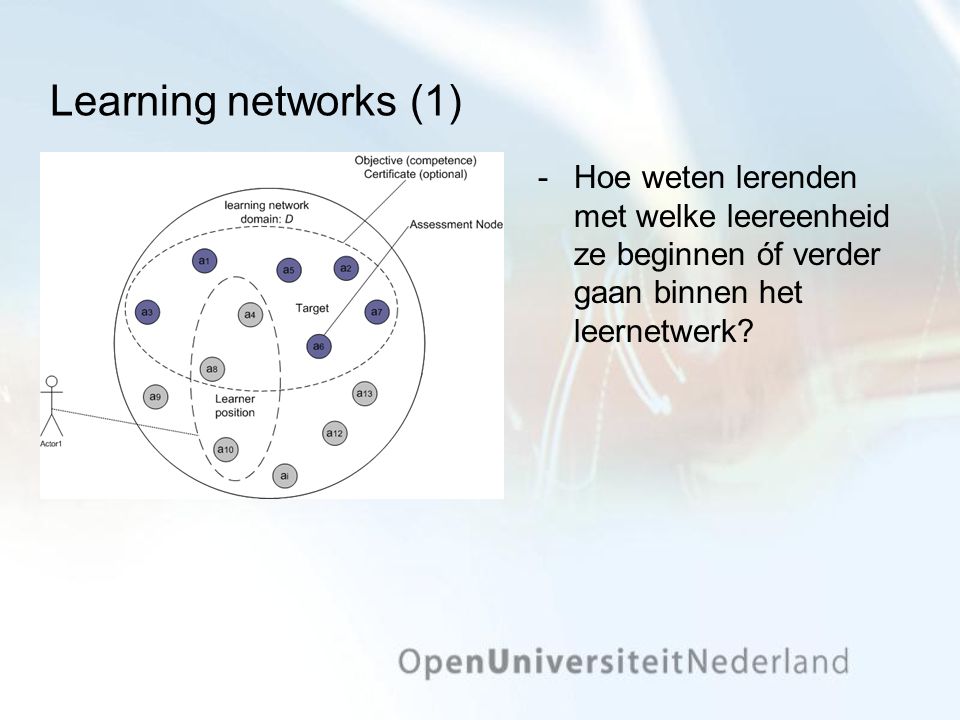
Learning networks (1) Hoe weten lerenden met welke leereenheid ze beginnen óf verder gaan binnen het leernetwerk?
Activiteiten binnen ‘positioning’ 1.Ontwikkelt richtlijnen rondom het gebruik van Latente semantische Analyse (LSA) voor positionering 2.Specificeert, ontwikkelt en test een prototype ‘positioner’ 3.Vergelijkt huidige praktijken van het erkennen van EVC’s met betrouwbaarheid en validiteit van computergebaseerde positionering
Gebruik van LSA: Nu vooral: Information retrieval grote, algemene corpora Ook gebruik binnen onderwijssettings: Beoordeling van essays en terugkoppeling Matchen van studenten met instructie-tekst Hulp bij maken van samenvattingen Binnen positioning: Relatief kleine, specifieke corpora Inhoudelijk ‘voorgeselecteerd’
Techniek: documentvectoren als basis C h i m p a n s ee A B GorillaGorilla C D
Latente Semantische Analyse Gebaseerd op singuliere waarde ontbinding Sterke gelijkenis met principale componenten analyse Symmetrische matrix M Eigenwaarden en eigenvectoren M = U Λ U’ Λ is diagonaalmatrix met geordende eigenwaarden Reproductie: verwijder kleinste eigenwaarden in Λ en kolomen en rijen in U en U’
Singuliere waardenontbinding (SVD) Asymmetrische matrix (data-matrix) D = L S R’ S is diagonaal met geordende singuliere waarden Aantal S > 0 is gelijk aantal dimensies van de matrix LSA: reproductie van matrix op basis van een model met minder dimensies Σ S 2 = Σ d 2
Een voorbeeld: 8 * 8 matrix
SVD in Excel
Onze context Datamatrix is Term*Document matrix met woordfrequenties in de cellen. Heel veel cellen bevatten nullen Voor een ijle matrijs (sparse matrix) geldt: Gemiddelde dicht bij nul Geringe variantie Cumulatieve waarden van S 2 zijn een goede benadering van de variantie ( Σ S 2 = Σ d 2)
Probleem Positioning vergt discrimineren tussen documenten Hoge correlaties in homogene verzameling Lage correlaties tussen homogene verzamelingen Stoppen en zo ja wat of hoeveel? Vind objectief criterium om aantal SW te bepalen: Meer is niet beter ! Literatuur: 300 of meer; hoogste correlatie Maximale discriminatie Proportie verklaarde variantie Betrouwbaarheid SW > 1
Experiment met aapcorpus Constructie corpus: Stoppen: 0, 30, 50 Stemmen Bepalen query-set: Gorilla Orang oetan Analyse
Analyses Correlatie: Binnen Q-set (gorilla, orang oetan): hoog Homogene set Q met N-set: laag Heterogene set Correlaties kennen een optimum verschil: Correlaties Q-set hoog EN Correlaties N-set laag Als aantal sv toeneemt, dalen correlaties door toename ruis
Resultaten (1)
Resultaten (2)
Resultaten (3)
Conclusies De correlaties voor de Q-set zijn hoog Zonder stoppen zijn ze dat ook voor de N-set Dus: discrimineren lukt alleen onder stopping condities Correlaties dalen met het toenemen van het aantal SW
Discussie Waar zitten de gaten? Vind objectief criterium om aantal SW te bepalen: Literatuur: 300 of meer Maximale discriminatie Proportie verklaarde variantie Betrouwbaarheid SW > 1