Download de presentatie
1
Gegevensverwerving en verwerking
Bibliotheek Staalname - aantal stalen/replicaten - grootte staal - apparatuur Statistiek - beschrijvend - variantie-analyse - correlatie - regressie - ordinatie - classificatie Experimentele setup Websites : => electronic statistic textbook allserv.rug.ac/ ~katdhond/ => reservatie PC zalen / ~gdsmet/MarBiolwebsite/ => lesnota’s

2
= beschrijving van verband
Licht temperatuur nutrienten …….. Groei voedselaanbod verstoring …….. densiteiten Onafhankelijke Afhankelijke variabelen Correlatie = graad van associatie tussen 2 variabelen Regressie = beschrijving van verband Impliceert geen causaal verband Impliceert geen afhankelijkheid

3
Parametrisch of niet-parametrische testen
Product-moment Spearman rank Kendall’s rank Als een gekende distributie (normale of Poisson) als model voor data frequentie distributie kan gebruikt worden Niet-parametrische testen die niet uitgaan van deze voorwaarden, zijn minder krachtig doordat ze niet alle aanwezige informatie gebruiken => RANKING In het geval van kleine stalen en geen normale distributie van de data zijn ze echter krachtiger dan parametrische testen.
 als model voor data frequentie distributie kan gebruikt. worden. Niet-parametrische testen die niet uitgaan van deze. voorwaarden, zijn minder krachtig doordat ze niet alle. aanwezige informatie gebruiken => RANKING. In het geval van kleine stalen en geen normale distributie. van de data zijn ze echter krachtiger dan parametrische testen.")
4
Parametrisch of niet-parametrische testen
Product-moment voor N koppels van waarnemingen(x1,y1)…(xi,yi)... (xN,yN) R is maat voor sterkte van lineair verband (zegt niets over vorm) R varieert tussen -1 en +1 De significantietest is afgeleid van een student-t distributie met N-2 df HO Nulhypothese “ R=0 => geen associatie”
…(xi,yi)... (xN,yN) R is maat voor sterkte van lineair verband (zegt niets over vorm) R varieert tussen -1 en +1. De significantietest is afgeleid van een student-t distributie met N-2 df. HO. Nulhypothese R=0 => geen associatie")
5
Parametrisch of niet-parametrische testen
Product-moment Partiële correlatie-berekening aan de hand van R : = berekening van graad van associatie waarbij het mogelijke effect van een derde factor wordt geneutraliseerd. X Y Z Voorbeeld : berekening van correlatie tussen factor X en factor Y waarbij het effect van factor Z (die ook gecorreleerd is met X) constant wordt gehouden
 constant. wordt gehouden.")
6
Partiële correlatie-berekening aan de hand van R :
= berekening van graad van associatie waarbij het mogelijke effect van een derde factor wordt geneutraliseerd. RXY = 1 X Y X Z Y RXY = 1 RXY.ZW => 1 X Z V Y W

7
Parametrisch of niet-parametrische testen
Spearman rank Kendall’s rank Voorbeeld:

8
Gegevensverwerving en verwerking
Bibliotheek Staalname - aantal stalen/replicaten - grootte staal - apparatuur Statistiek - beschrijvend - variantie-analyse - correlatie - regressie - ordinatie - classificatie Experimentele setup Websites : => electronic statistic textbook allserv.rug.ac/ ~katdhond/ => reservatie PC zalen / ~gdsmet/MarBiolwebsite/ => lesnota’s

9
= beschrijving van verband
Licht temperatuur nutrienten …….. Groei voedselaanbod verstoring …….. densiteiten Onafhankelijke Afhankelijke variabelen Correlatie = graad van verband Regressie = beschrijving van verband

11
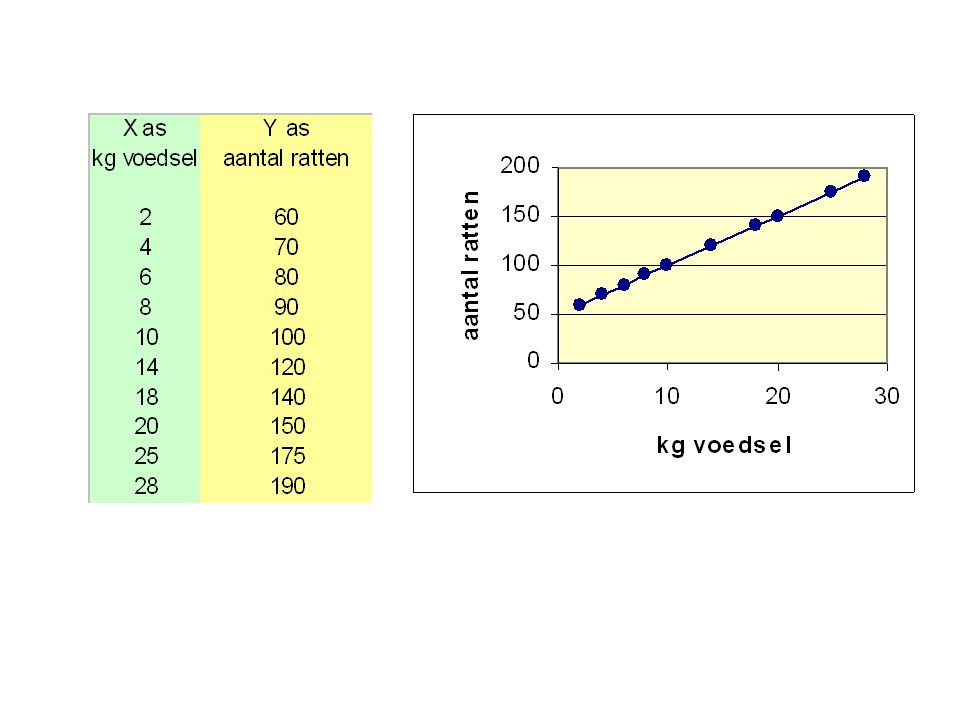
Y = a + bX Lineaire regressie-analyse
- nagaan van effecten van sommige variabelen op andere variabelen - relatie tussen variabelen beschrijven met een (lineaire) functie 2 soorten variabelen : Predictor of onafhankelijke variabelen (X) Respons of afhankelijke variabelen (Y) Hoe bepalen veranderingen in de onafhankelijke variabelen de waarden van de afhankelijke variabelen??? Type 1 : relatie tussen 2 variabelen kan beschreven worden door een rechte lijn = LINEAIRE REGRESSIE Y = a + bX Vergelijking van een rechte :
 functie. 2 soorten variabelen : Predictor of onafhankelijke variabelen (X) Respons of afhankelijke variabelen (Y) Hoe bepalen veranderingen in de onafhankelijke variabelen. de waarden van de afhankelijke variabelen Type 1 : relatie tussen 2 variabelen kan beschreven worden door een. rechte lijn = LINEAIRE REGRESSIE. Y = a + bX. Vergelijking van een rechte :")
12
Y = a + bX Y = a2 +b2X Y = a1 +b1X Lineaire regressie-analyse
Vergelijking van een rechte : Y = a + bX X = onafhankelijke variabelen Y = afhankelijke variabelen a en b zijn parameters of constanten Y = a2 +b2X b2 Y = a1 +b1X b1 a1 a2 1 1 a = waarde van Y als X = 0 ; = snijpunt Y as b = aantal eenheden dat Y verandert als X met één eenheid verandert; = helling

13
Residuelen (e) Y = a + bX + e
 Y = a + bX + e")
14
Y = a + bX e= residuele = afwijking van de geobserveerde y-waarden
van de voorspelde y waarden Residuelen (e) Y = a + bX + e M.a.w. Y kan maar gedeeltelijk voorspeld worden op basis van X omdat Y een ariatie vertoont tengevolge van ongekende willekeurige factoren Zelden een rechte lijn door alle data ==> compromis van best passende rechte => residuelen zo klein mogelijk houden bij bepalen van a en b
 Y = a + bX. + e. M.a.w. Y kan maar gedeeltelijk voorspeld worden op basis van X omdat. Y een ariatie vertoont tengevolge van ongekende willekeurige factoren. Zelden een rechte lijn door alle data ==> compromis van best passende rechte. => residuelen zo klein mogelijk houden bij bepalen van a en b.")
15
=> residuelen zo klein mogelijk houden bij bepalen van a en b
door de METHODE van de KLEINSTE KWADRATEN = minimalisatie van de som van de gekwadrateerde residuelen Voor n koppels van observaties (x1 , y1 ) ...(xi , yi )...(xn , yn) met y1 = a + b x1 + e1 en i = 1, …n De som van de kwadraten van de residuelen is dan : (y1 - a - b x1 )² Dus a en b worden nu zo berekend dat een zo klein mogelijke waarde voor S wordt bekomen
 ...(xi , yi )...(xn , yn) met y1 = a + b x1 + e1 en i = 1, …n. De som van de kwadraten van de residuelen is dan : (y1 - a - b x1 )². Dus a en b worden nu zo berekend dat een zo klein mogelijke waarde voor S wordt bekomen.")
16
=> residuelen zo klein mogelijk houden bij bepalen van a en b
door de METHODE van de KLEINSTE KWADRATEN = minimalisatie van de som van de gekwadrateerde residuelen (yi - a - b xi )² Dus a en b worden nu zo berekend dat een zo klein mogelijke waarde voor S wordt bekomen Totale populatie Y = a + b X ==> Schatting S minimaal door differentiaties van S naar a en b gelijk te stellen aan 0 waaruit a en b kunnen berekend worden met als resultaat : wordt dan of Met b’ de enige onbekende die moet berekend worden om een schatting van Y te bekomen
². Dus a en b worden nu zo berekend dat een zo klein mogelijke waarde voor S wordt bekomen. Totale populatie Y = a + b X ==> Schatting. S minimaal door differentiaties van S naar a en b gelijk te stellen aan 0. waaruit a en b kunnen berekend worden met als resultaat : wordt dan. of. Met b’ de enige onbekende die moet berekend worden om een schatting van Y te bekomen.")
17
Betrouwbare schatting
Onbetrouwbare schatting ????????????

18
Maat voor betrouwbaarheid van schatting
Significantie-test : Maat voor betrouwbaarheid van schatting Gebaseerd op de splitsing van de som der kwadraten (SS) cfr ANOVA Y as Variatie tussen groepen (effect) Tot. var. Variatie binnen groepen (error) = geobserveerde Y waarde = voorspelde of geschatte Y waarde = gemiddelde Y waarde X as SSregr. SSY SSres SSY SSregr. SSres = +
 cfr ANOVA. Y as. Variatie tussen groepen (effect) Tot. var. Variatie binnen groepen (error) = geobserveerde Y waarde. = voorspelde of geschatte Y waarde. = gemiddelde Y waarde. X as. SSregr. SSY. SSres. SSY. SSregr. SSres. = +")
19
SSY SSregr. SSres Totaal n-1 Tussen 1 tgv Regressie MSregr Binnen n-2
= SSregr. + SSres Bron van variatie Vrijheidsgraden (df) Som kwadraten SS Gemiddelde kwadraten MS = SS/df Variantie s² = MS = SS / df Totaal n-1 Tussen tgv Regressie MSregr Binnen n-2 Residuele S ² = SS / n-2 Vrijheidsgraden is aantal onafhankelijke eenheden om SS te bekomen Volgt bij benadering een F-distributie met 1 en n-2 vrijheidsgraden indien b=0 Dus indien F > F tabel => Regressie is significant
 Som kwadraten. SS. Gemiddelde kwadraten. MS = SS/df. Variantie s² = MS = SS / df. Totaal n-1. Tussen 1. tgv Regressie. MSregr. Binnen n-2. Residuele. S ² = SS / n-2. Vrijheidsgraden is aantal onafhankelijke eenheden om SS te bekomen. Volgt bij benadering een F-distributie met 1 en n-2 vrijheidsgraden. indien b=0. Dus indien F > F tabel => Regressie is significant.")
20
Maat voor % variatie verklaard door regressieid van schatting
R² ratio: Maat voor % variatie verklaard door regressieid van schatting Y as = geobserveerde Y waarde = voorspelde of geschatte Y waarde = gemiddelde Y waarde X as SSY SSregr. SSres = + SSregr. SSres R² = Indien =0 => R² = 1 >>0 => R²=>0 SSY R² geeft weer hoeveel % variatie in Y kan worden toegeschreven aan een lineaire relatie met X De overige variatie is willekeurig.

21
Standard error van de schatting
= standard deviatie van de geobserveerde Y waarden van de voorspelde Y waarden = gemiddelde fout in de voorspelling van Y op basis van de regressie Standard error van b’ = schatting van de variantie van b’ Indien de schattingen van b’ van verschillende staalnamen normaal verdeeld zijn kunnen betrouwbaarheidsintervallen berekend worden voor b’. De nulhypothese dat b=0 kan dan getoetst worden aan de hand van een t-test. Standard error van a’ = schatting van de variantie van a’









>")











