Download de presentatie
1
Beschrijvende en inferentiële statistiek
College 9 – Anouk den Hamer – Hoofdstuk 12 (12.5 geen tentamenstof)
")
2
Vandaag Uitwerking oude tentamenopgaven Overzicht toetsen Regressie R²

5
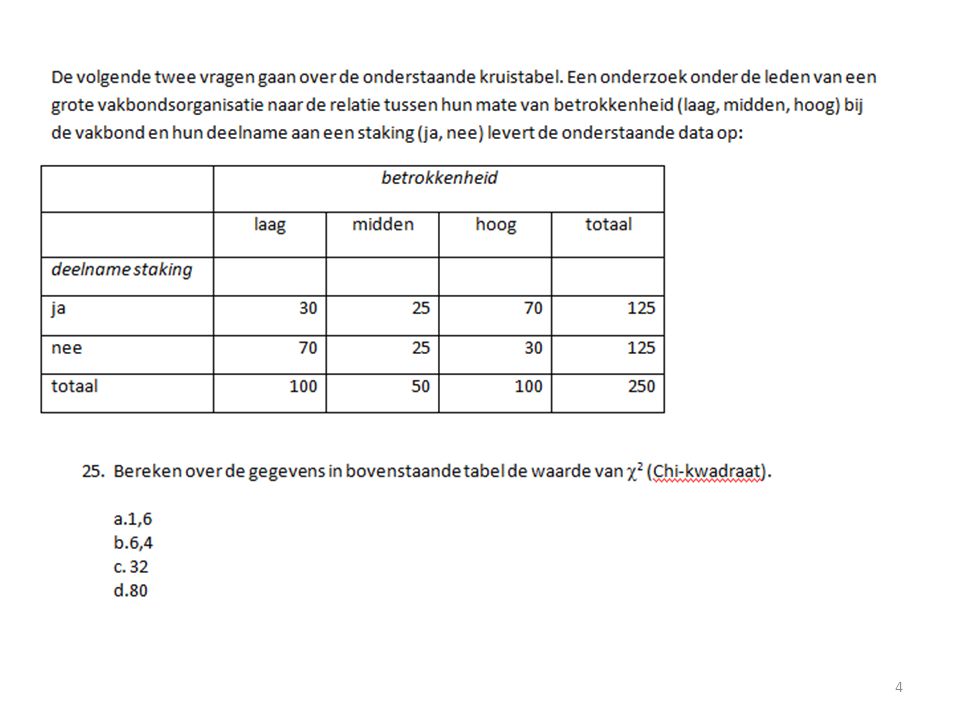
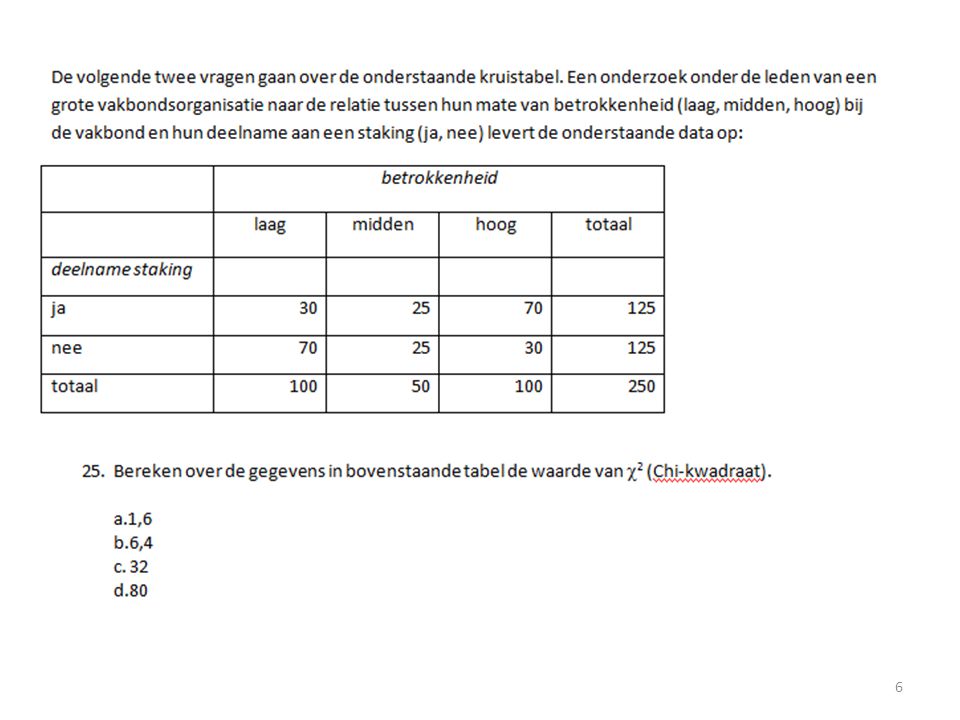
Totaal Observed 30 25 70 125 Expected 50 (obs-exp)^2 / exp 8 100 250
^2 / exp")
10
Wanneer gebruik je welke toets?

11
Wanneer je een specifieke waarde verwacht voor de nulhypothese:
Bij een proportie: Binomial Test. Hoe in SPSS? Analyze – Nonparametric Tests – Legacy Dialogs – Binomial. Variabele naar test variabele list slepen – test proportion invullen – bij options descriptives aanvinken. Bij een gemiddelde: One Sample T test. Hoe in SPSS? Analyze – Compare Means – One Sample T test. Variabele naar test variabele slepen – test value invullen – bij options hoef je niks te veranderen.

12
Wanneer je twee groepen wilt vergelijken:
Onafhankelijke groepen: Independent T-test. Hoe in SPSS? Analyze – Compare Means – Independent T-test. De variabele die uit de 2 groepen bestaat is je grouping variable. Vul bij define groups de waarden van deze groepen in (vaak 1 en 2). De afhankelijke variabele komt in test variabele. Afhankelijke groepen: Dependent T-test. Hoe in SPSS? Analyze – Compare Means – Paired Samples T-test. Dubbelklik op de variabele van de voormeting en dubbelklik daarbij op de variabele van de nameting.
. De afhankelijke variabele komt in test variabele. Afhankelijke groepen: Dependent T-test. Hoe in SPSS Analyze – Compare Means – Paired Samples T-test. Dubbelklik op de variabele van de voormeting en dubbelklik daarbij op de variabele van de nameting.")
13
Wanneer je categorische variabelen wilt vergelijken:
Chi-square: Analyze – Descriptive Statistics – Crosstabs. Variabele in row en variabele in colom (maakt niet uit welke waar). Bij statistics chi-square aanvinken. Bij cells observed, expected en adjusted standardized aanvinken.
. Bij statistics chi-square aanvinken. Bij cells observed, expected en adjusted standardized aanvinken.")
14
Wanneer je wilt weten wat de invloed van een of meer continue onafhankelijke variabelen op een continue afhankelijke variabele is: Enkelvoudige regressie: Analyze > Regression > Lineair. Dependent is Y en Independent X. Meervoudige regressie: Analyze > Regression > Lineair. Dependent is Y en bij Independent kun je alle X-en invullen.

15
Wanneer je wilt weten of een schaal in je vragenlijst betrouwbaar is:
Betrouwbaarheidsanalyse: Analyze > Scale > Reliability analysis. Alle items in itemsbox zetten. Bij statistics aanvinken: onder “descriptives for” item, scale en scale if item deleted, en onder “summaries” correlations. Ok.

16
Bestand te vinden op BB (Course Documents).
.")
17
Tabellen Tabel A: z-verdeling met z-scores en p-waardes
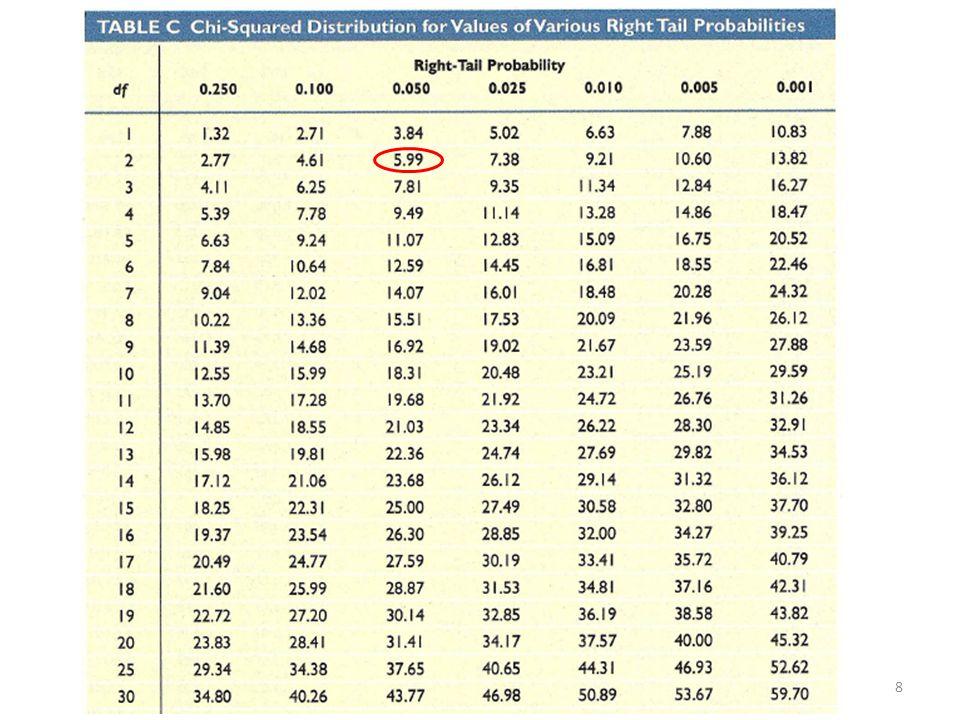
Tabel B: t-verdeling met df’s en kritieke t-waardes Tabel C: chi-square verdeling met df’s en kritieke chi-square waardes Tabel B: Ervan uitgaande dat je toetst bij een significantieniveau van .05: Bij een eenzijdige toets ga je op zoek naar de kritieke t-waarde bij t.05 (want 5% verdeeld over één staart) Bij een tweezijdige toets ga je op zoek naar de kritieke t-waarde bij t.025 (want 5% verdeeld over twee staarten)
 Bij een tweezijdige toets ga je op zoek naar de kritieke t-waarde bij t.025 (want 5% verdeeld over twee staarten)")
18
X is categorisch: z-toets, t-toetsen, chi-sqaure toets Vandaag:
Tot nu toe: X is categorisch: z-toets, t-toetsen, chi-sqaure toets Vandaag: X is continu (of kwantitatief) en Y is continu: regressie X Y
 en Y is continu: regressie. X. Y.")
19
Regressie Met regressie ga je proberen een waarde van Y te voorspellen aan de hand van X Bij regressie zijn X en Y beide kwantitatief! Enkelvoudige regressie: 1 X en 1 Y Meervoudige regressie: meerdere X-en en 1 Y Voorbeeld enkelvoudige regressie: je wilt weten of percentage single parents in een stad (X) verband houdt met de violent crime rate (Y)
 verband houdt met de violent crime rate (Y)")
20
Scatterplot

21
Regressie 1) Je wilt Y dmv X kunnen voorspellen met een formule. 2) Je probeert Y zo goed mogelijk te voorspellen, maar je kunt niet vermijden dat je Y niet helemaal precies voorspelt. 3) We hebben het wederom over de associatie tussen variabelen. 4) De sterkte van de associatie tussen X en Y wordt uitgedrukt door de correlatie. 5) Naast de sterkte van de associatie wil je weten hoe goed X Y voorspelt (met de R-square). 6) We willen weten of onze X een significante invloed heeft op Y.
 Je wilt Y dmv X kunnen voorspellen met een formule. 2) Je probeert Y zo goed mogelijk te voorspellen, maar je kunt niet vermijden dat je Y niet helemaal precies voorspelt. 3) We hebben het wederom over de associatie tussen variabelen. 4) De sterkte van de associatie tussen X en Y wordt uitgedrukt door de correlatie. 5) Naast de sterkte van de associatie wil je weten hoe goed X Y voorspelt (met de R-square). 6) We willen weten of onze X een significante invloed heeft op Y.")
22
Regressie 1) Je wilt Y dmv X kunnen voorspellen met een formule.
 Je wilt Y dmv X kunnen voorspellen met een formule.")
23
Regressieformule Formule: a is het intercept en b de slope
Intercept (a of α): de waarde van Y als X 0 is Slope (b of β): de helling van de lijn. Dus de hoeveelheid Y die erbij komt als X één waarde omhoog gaat Bij een positieve b is er een positief verband en bij een negatieve b is er een negatief verband
: de waarde van Y als X 0 is. Slope (b of β): de helling van de lijn. Dus de hoeveelheid Y die erbij komt als X één waarde omhoog gaat. Bij een positieve b is er een positief verband en bij een negatieve b is er een negatief verband.")
24
Wat is het intercept? En wat is de slope?
Intercept: bij X = 0, Y = 0. Het intercept is dus 0 Slope: bij X = 8 stijgt Y met 1000 (van 0 naar 1000). 1000/8 is 125. De slope is dus 125
. 1000/8 is 125. De slope is dus 125.")
25
Invullen in formule De formule: Dus:
Y-hat = x, oftewel gewoon 125x Stel dat een stad een single parent percentage van 10 heeft, hoe hoog is de crime rate dan? *10 = 1250

26
Intercept verandert α: intercept
Als α verandert terwijl b constant blijft resulteert dat in parallelle lijnen.

27
Slope verandert b: slope.
Als b verandert terwijl α constant blijft resulteert dat in geroteerde lijnen.

28
Regressie 2) Je probeert Y zo goed mogelijk te voorspellen, maar je kunt niet vermijden dat je Y niet helemaal precies voorspelt.
 Je probeert Y zo goed mogelijk te voorspellen, maar je kunt niet vermijden dat je Y niet helemaal precies voorspelt.")
29
Residuals Probeert zo goed mogelijk te schatting hoe de lijn loopt
Je hebt echter altijd predictions errors ,ofwel residuals: de verticale afstand tussen een observatie en de lijn, het verschil tussen de y die je voorspelt met je formule en de geobserveerde y

30
Regressielijn en residuals
Regressielijn met zo klein mogelijke residuals: least squares line Least squares line: lijn met de kleinste sum of squared residuals: sum of squared residuals = …dus de som van de gekwadrateerde residuals Waarom geen least residuals line, maar least squares line? Als je de residuals niet kwadrateert, dan vallen de positieve residuals weg tegen de negatieve residuals. ( = 0, terwijl = 18)
")
31
Model De regressielijn of de formule wordt ook wel een model genoemd
Het model kan Y niet exact voorspellen, maar is een benadering van de relatie tussen X en Y

32
Regressie 3) We hebben het wederom over de associatie tussen variabelen.
 We hebben het wederom over de associatie tussen variabelen.")
33
Associatie De slope (de b) geeft aan of de associatie positief of negatief is De correlatie geeft de sterkte van de associatie

34
Regressie 4) De sterkte van de associatie tussen X en Y wordt dus uitgedrukt door de correlatie.
 De sterkte van de associatie tussen X en Y wordt dus uitgedrukt door de correlatie.")
35
Regressie 5) Naast de sterkte van de associatie wil je weten hoe goed X Y voorspelt (met de R-square).
 Naast de sterkte van de associatie wil je weten hoe goed X Y voorspelt (met de R-square).")
36
R-square De correlatie geeft aan hoe sterk het verband is en de R-square geeft aan in hoeverre X in staat is Y te voorspellen. Waarom wil je dat weten? Stel dat de R-square heel laag is, dan weet je dat je ook met andere variabelen rekening moet houden wil je Y goed kunnen voorspellen.

37
Zo meteen de formule voor de R-square

38
We zagen net… least squares line

39
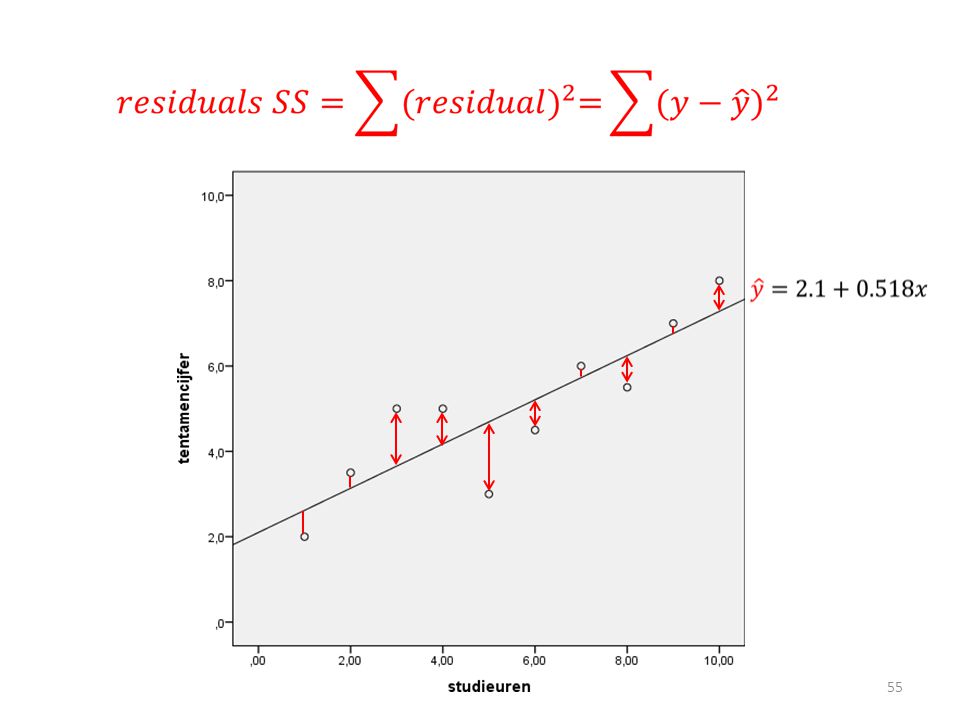
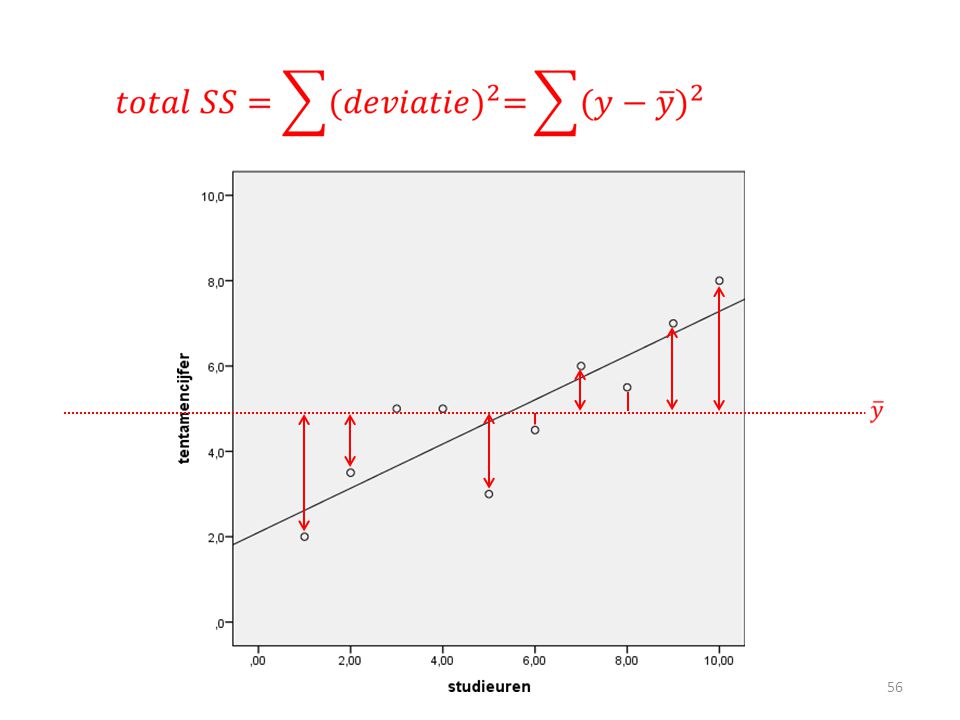
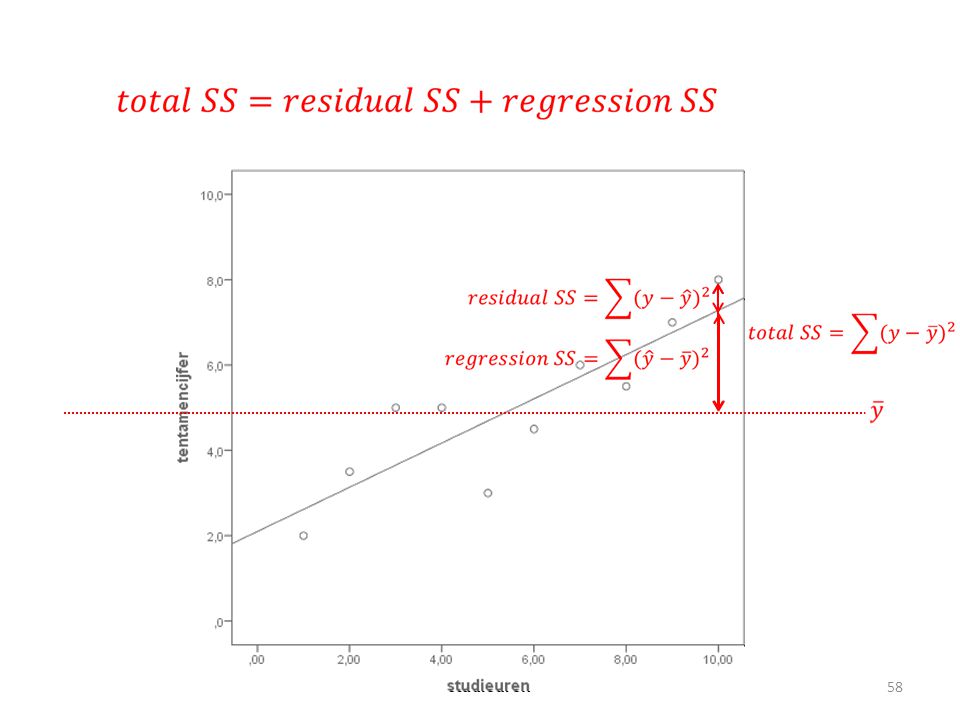
RSS = residual sum of squares
RSS = alle groene streepjes kwadrateren en bij elkaar optellen Regressielijn met de voorspelde y

40
Je wilt weten hoeveel de voorspelde y’s afwijken van de geobserveerde y’s (RSS)
En je wilt kunnen verklaren waarom er observaties zijn die afwijken van het gemiddelde van y

41
Gemiddelde y TSS = total sum of squares TSS = alle groene streepjes kwadrateren en bij elkaar optellen

42
Nodig voor de formule van de R-square

43
Formule R² R² = (TSS - RSS)/TSS
TSS (total sum of sqaures): hoeveel de geobserveerde y’s afwijken van het gemiddelde van y ( ) RSS (residual sum of squares): hoeveel de geobserveerde y’s afwijken van de voorspelde y ( ) MSS (model sum of squares): TSS-RSS, dus de variantie verklaard door het model
: hoeveel de geobserveerde y’s afwijken van het gemiddelde van y ( ) RSS (residual sum of squares): hoeveel de geobserveerde y’s afwijken van de voorspelde y ( ) MSS (model sum of squares): TSS-RSS, dus de variantie verklaard door het model.")
44
Met de R² wil je weten hoeveel beter de regressielijn (waarbij je rekening houdt met X) Y voorspelt dan wanneer je alleen de gemiddeldelijn van Y had gebruikt. M.a.w.: je wilt weten hoeveel variantie van Y verklaard wordt door X. Stel dat een R² 0.40 is, dan is de error als je de voorspelde Y gebruikt (met X in de formule) 40% kleiner dan de error als je de gemiddelde y gebruikt (dus zonder X). Dus 40% van de variantie in Y wordt voorspeld door X
 40% kleiner dan de error als je de gemiddelde y gebruikt (dus zonder X). Dus 40% van de variantie in Y wordt voorspeld door X.")
45
Theoretisch geeft de R² de reductie in error als je de regressielijn gebruikt ipv de gemiddeldelijn. Praktisch geeft de R² aan hoeveel variantie van Y verklaard wordt door X.

46
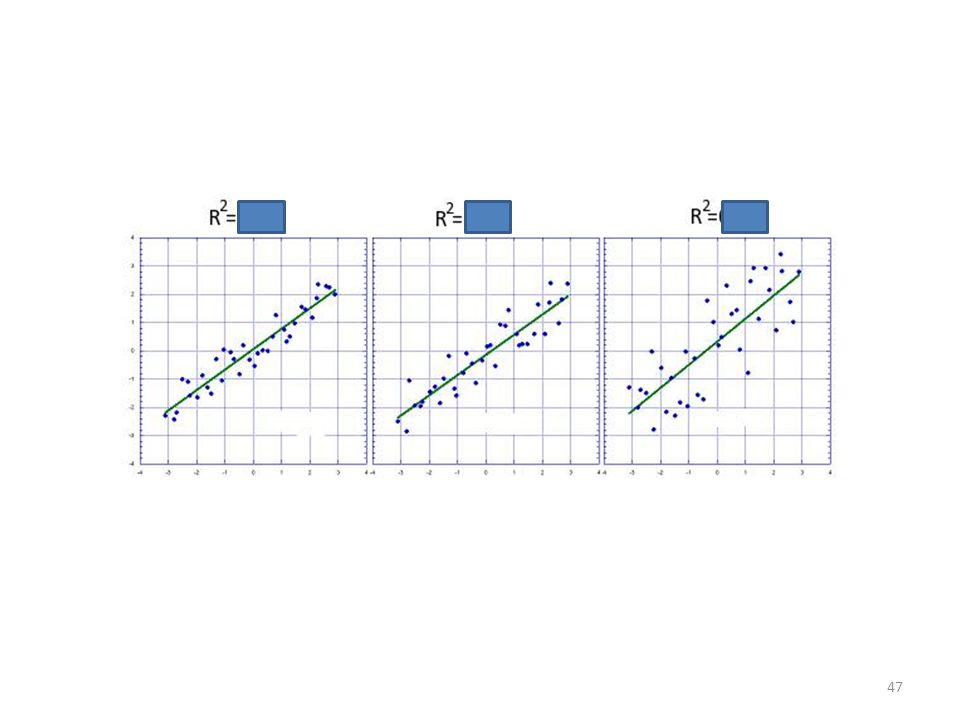
Eigenschappen R² R² ligt tussen 0 en 1
Hoe dichter bij 1, hoe sterker de associatie

49
Regressie 6) We willen weten of onze X een significante invloed heeft op Y.
 We willen weten of onze X een significante invloed heeft op Y.")
50
Toetsen van regressiecoëfficiënten (de slopes)
Als de regressielijn horizontaal loopt, betekent dit dat bij welke waarde van X dan ook, je steeds dezelfde Y vindt. Y hangt dus niet van X af. De regressiecoëfficiënt (of slope of b of ß) is 0. Dus: als de onafhankelijke variabele X effect heeft op de afhankelijke variabele Y, dan verwachten we een regressiecoëfficiënt b die significant afwijkt van nul: positief of negatief. Bij toetsen van slopes toets je of de slope significant van 0 afwijkt
 is 0. Dus: als de onafhankelijke variabele X effect heeft op de afhankelijke variabele Y, dan verwachten we een regressiecoëfficiënt b die significant afwijkt van nul: positief of negatief. Bij toetsen van slopes toets je of de slope significant van 0 afwijkt.")
52
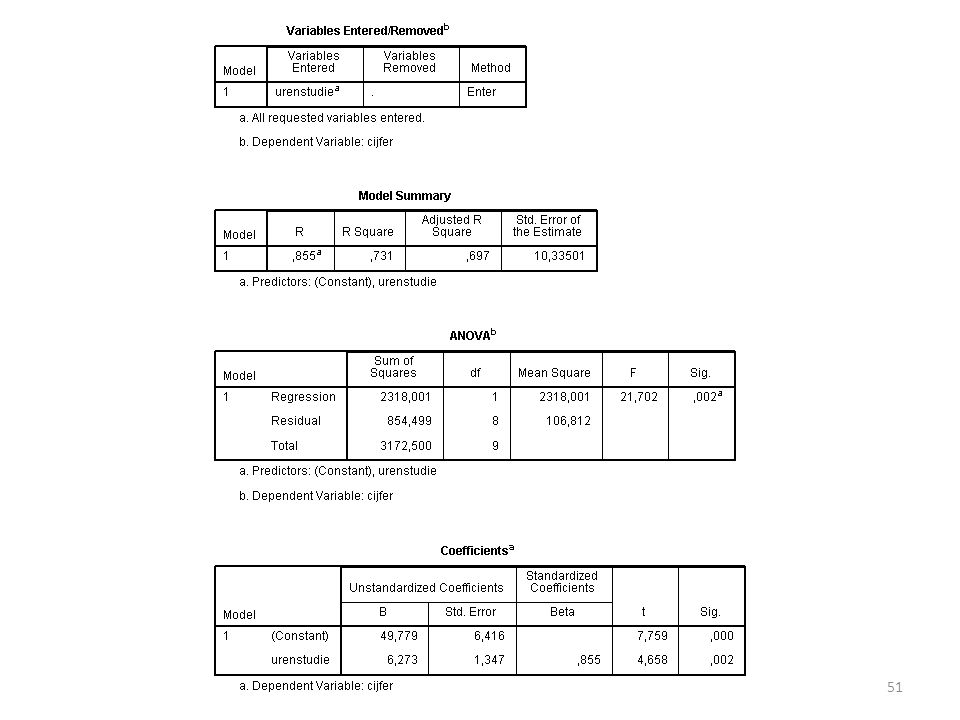
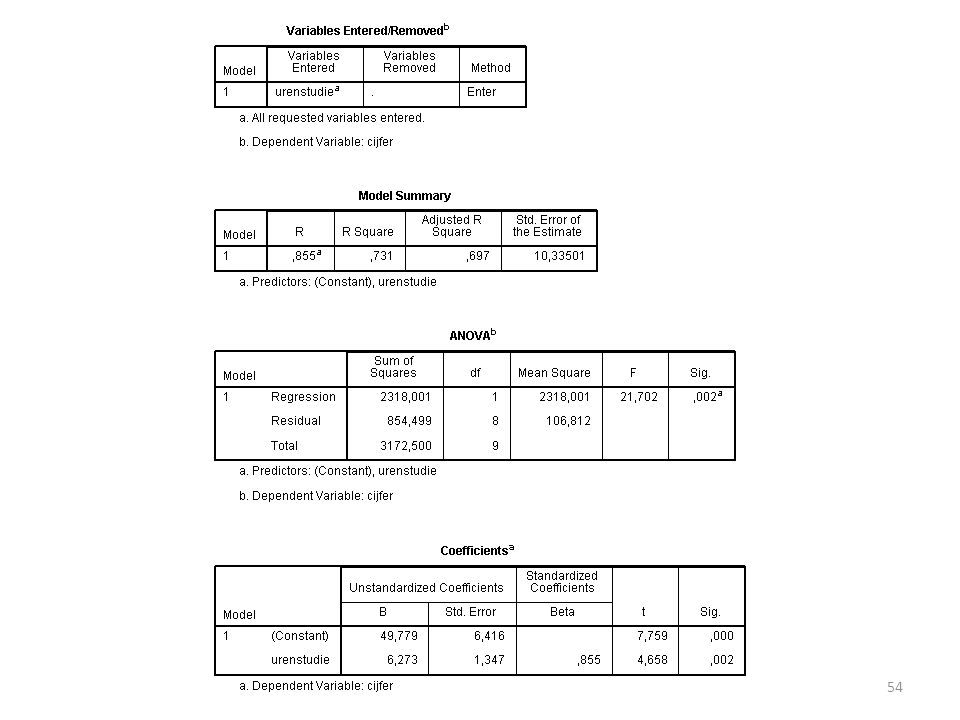
Output (onderste tabel)
Intercept (a) = (de constante is altijd het intercept) Slope (b) = 6.273 Beta = slope / standaarddeviatie, dus de gestandaardiseerde slope. Als je het standaardiseert, heb je geen last meer van verschillende meeteenheden (belangrijk bij meervoudige regressie).
 = (de constante is altijd het intercept) Slope (b) = Beta = slope / standaarddeviatie, dus de gestandaardiseerde slope. Als je het standaardiseert, heb je geen last meer van verschillende meeteenheden (belangrijk bij meervoudige regressie).")
53
Output We zien dat de correlatie tussen X en Y .86 is (correlatie wordt met R aangegeven) en de R² = .73, dus 73% van de variantie van Y wordt veklaard door X. Hier is X aantal uren studie en Y tentamencijfer.
 en de R² = .73, dus 73% van de variantie van Y wordt veklaard door X. Hier is X aantal uren studie en Y tentamencijfer.")
57
MSS

60
Output k = aantal x-en R-squared: MSS/TSS = 2318.001/3172.500 = 0.7307
MSS + RSS = TSS, dus =3172 df regression + df residual = df total, dus 1+8=9 MSS / df regression = mean square regression, dus 2318 / 1 = 2318 RSS / df residual = mean square residual (ook wel mean square error genoemd), dus 854 / 8 = 106 MSS RSS TSS N – 1 – k, hier was n = 10 n - 1
, dus 854 / 8 = 106. MSS. RSS. TSS. N – 1 – k, hier was. n = 10. n - 1.")
61
Mean square regression: gemiddelde per onafhankelijke variabele van
Mean square residual: gemiddelde gekwadrateerde residual, dus van F = (mean square regression) / (mean square residual), dus 2318 / 106 = 21.7 F is de gekwadrateerde t-waarde uit de coefficiententabel. Wortel 21.7 = 4.658 De F-test is een andere manier om te zien of X een significante invloed op Y heeft (wat je met de t-statistic ook kon doen) Waarom? Komt in volgend hoofdstuk aan bod.
 / (mean square residual), dus 2318 / 106 = F is de gekwadrateerde t-waarde uit de coefficiententabel. Wortel 21.7 = De F-test is een andere manier om te zien of X een significante invloed op Y heeft (wat je met de t-statistic ook kon doen) Waarom Komt in volgend hoofdstuk aan bod.")
62
Conditionele verdeling
Conditionele verdeling in regressie: verdeling van y bij specifieke waardes van x. Stel dat x opleiding is en y inkomen, dan kijkt regressie hoe het conditionele gemiddelde van y verandert door opleiding.

63
Omdat de voorspelde y een schatting is, heb je bij ieder punt van x bij y een conditionele verdeling.

64
Conditionele standaard deviatie σ
Meet hoe ‘ver’ de geobserveerde y van de voorspelde y af ligt. σ weten we niet. Dus gebruiken we: Maar er is nog een standaard deviatie: Dat is de marginale standaard deviatie en die negeert alle waardes van x.

65
Conditionele en marginale s.d.
Conditionele standaard deviatie: variantie van inkomen bij een specifiek aantal jaar van opleiding. Marginale standaard deviatie: variantie van inkomen, los van aantal jaren opleiding.

66
Conditionele standaard deviatie
Slechte titel! = conditionele sd

67
Conditionele en marginale s.d.
Conditionele standaard deviatie: variantie van inkomen bij een specifiek aantal jaar van opleiding. Marginale standaard deviatie: variantie van inkomen, los van aantal jaren opleiding.

68
Marginale standaard deviatie

69
Conditionele en marginale s.d.
Conditionele standaard deviatie: variantie van inkomen bij een specifiek aantal jaar van opleiding. Marginale standaard deviatie: variantie van inkomen, los van aantal jaren opleiding. s = 15.9 < sy = 20.7 Hoe groter de verhouding tussen s/ sy , hoe sterker de associatie tussen x en y. De conditionele sd is altijd kleiner dan de marginale sd

70
Inferentie in regressie
Assumpties: Random steekproef. Formule: Conditionele verdeling van y voor elke waarde van x is normaal (dus normaal verdeeld, klokvormig). Identieke conditionele standaard deviatie voor elke waarde van x (constante variantie of homoscedasticiteit).
. Identieke conditionele standaard deviatie voor elke waarde van x (constante variantie of homoscedasticiteit).")
71
Inferentie in regressie
Benoem de hypotheses: H0: β=0 Ηα: β≠0 (of β<0, β>0) Vind de test statistic: Sigma beta = standard error van de slope s = conditionele standaard deviatie
 Vind de test statistic: Sigma beta = standard error van de slope. s = conditionele standaard deviatie.")
73
Wat moeten jullie weten van de output?
Kijk altijd eerst naar de coefficiententabel. Je moet weten waar je het intercept, de slope, de t-waarde en de p-waarde vindt. Daarnaast moet je weten wat de beta betekent. Daarna de model summarytabel. Hierin moet je de correlatie kunnen vinden, evenals de R-square. Als laatste de ANOVA-tabel. De cijfers onder sum of squares en df moeten jullie begrijpen. De rest (vooralsnog) alleen weten hoe je ze berekent (dus stel dat je bv de TSS niet weet, hoe kan je daar toch achter komen? Idem voor als je bv de F-waarde niet weet).
 alleen weten hoe je ze berekent (dus stel dat je bv de TSS niet weet, hoe kan je daar toch achter komen Idem voor als je bv de F-waarde niet weet).")
74
Huiswerkopdracht Ik ben benieuwd of het aantal minuten dat een student per dag tv kijkt verband houdt met zijn/haar cijfer voor het tentamen van BIS Mijn hypothese: hoe meer minuten een student per dag tv kijkt, hoe lager zijn/haar tentamencijfer voor BIS Gebruik de data van de Georgia Student Survey (zie op BB onder Course Documents). Beschouw CGPA (college GPA) als tentamencijfer BIS. Voer dit in SPSS in, maak een scatterplot en voer een regressie-analyse uit Trek je conclusie omtrent de hypothese
. Beschouw CGPA (college GPA) als tentamencijfer BIS. Voer dit in SPSS in, maak een scatterplot en voer een regressie-analyse uit. Trek je conclusie omtrent de hypothese.")
75
Hoe in SPSS? Scatterplot: Graphs > Legacy Dialogs > Scatter/dot > Simple. Vul X en Y as in. Regressie: Analyze > Regression > Lineair. Dependent is Y en Independent X.

























 Quiz Night !>")




