Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Help! Statistiek! Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Derde woensdag in de maand, uur 18 april: “Welke toets wanneer?” 16 mei: “Lineaire regressie” (Lokaal 16 OC) 20 juni: “Logistische regressie” (Lokaal 16 OC) 19 september: ”Survival analyse” Sprekers: Vaclav Fidler, Hans Burgerhof, Wendy Post DG Epidemiologie
 20 juni: Logistische regressie (Lokaal 16 OC) 19 september: Survival analyse Sprekers: Vaclav Fidler, Hans Burgerhof, Wendy Post. DG Epidemiologie.")
2
Lineaire regressie Wat is het? Wanneer gebruiken we het (niet)?
Wat komt er allemaal bij kijken? Waar komt de naam eigenlijk vandaan?

3
Enkelvoudige lineaire regressie
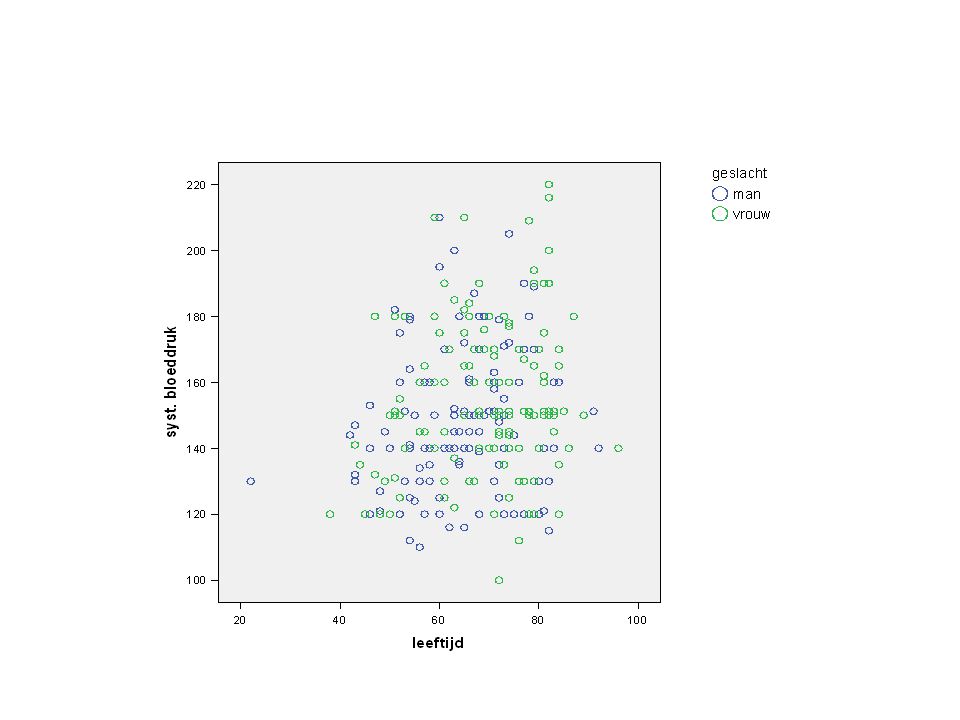
Er is een continue responsievariabele Y Er is een verklarende variabele X We zijn geïnteresseerd in de relatie tussen Y en X We beschikken over onafhankelijke waarnemingen Een lineair verband lijkt redelijk Bijvoorbeeld: systolische bloeddruk Bijvoorbeeld: leeftijd Relatie is niet symmetrisch!

4
Lineair verband?

5
Lineair verband? leeftijd

6
Lineaire regressie (formule)
We schatten de populatierelatie We nemen aan dat Controleren! Residuen normaal verdeeld rond leeftijds- gemiddelde, met dezelfde spreiding Rechtlijnig verband van de gemiddelden

7
De geschatte regressielijn
Waarom is dit de “best passende lijn”?

8
De geschatte lijn De populatie regressielijn wordt geschat met behulp van de kleinste kwadratenmethode: neem die lijn waarvoor de som van de gekwadrateerde residuen zo klein mogelijk is Rond 1800 Gauss en Legendre Astronomie

9
Minimaliseer Residu e = verschil tussen waargenomen
en voorspelde waarde Minimaliseer

10
Lineaire regressie in SPSS

11
Toelichting SPSS uitdraai
SBP = 128,8 + 0,33*leeftijd, bv, de geschatte bloeddruk van een 70-jarige: SBP = 128,8 + 0,33*70 = 151,9

12
De geschatte regressielijn
H0: β1 = 0 (geen lineair verband) b0
 b0.")
13
ANalysis Of VAriance De totale spreiding van SBP wordt gesplitst in een verklaard deel en een onverklaard deel (de residuen) Er wordt getoetst of het verklaarde deel net zo groot is als het onverklaarde deel De F-test is gelijkwaardig met de t-test voor β1 in een enkelvoudige lineaire regressie

14
,003 F = t² ,003

15
R is de multiple correlatiecoëfficiënt (gelijk aan de absolute waarde van r)
R square = R in het kwadraat = SSregression /SStotal = de proportie verklaarde variantie Adjusted R square: reëlere schatting van R² in de populatie Standaard error of the estimate = gemiddelde grootte van een residu

16
Controle van de aannames
Alle paren waarnemingen (X,Y) zijn onafhankelijk van elkaar (externe informatie) Het verband tussen E(Y) en X is lineair (strooiingsdiagram) De residuen zijn normaal verdeeld (pplot) De spreiding van de residuen is gelijk, ongeacht de grootte van X (scatter)
 zijn onafhankelijk van elkaar (externe informatie) Het verband tussen E(Y) en X is lineair (strooiingsdiagram) De residuen zijn normaal verdeeld (pplot) De spreiding van de residuen is gelijk, ongeacht de grootte van X (scatter)")
17
Normaliteit van de residuen

18
Normaliteit van de residuen

19
Homogene spreiding van de residuen

20
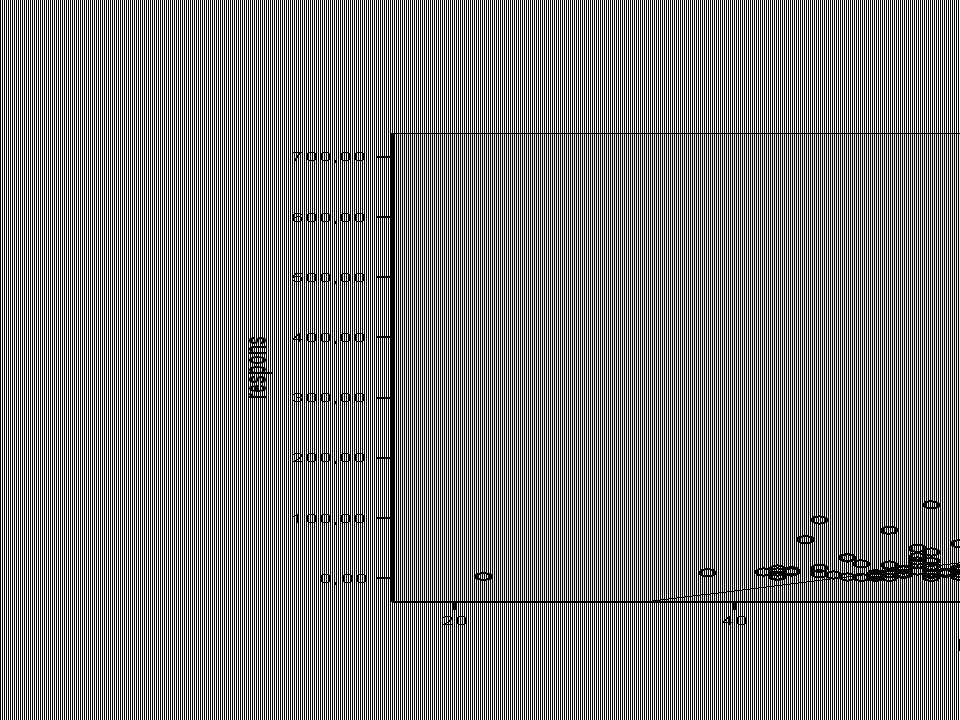
Lineaire regressie op deze data
leeftijd

22
Controle aannames De gebruikte testen zijn niet valide!
Overweeg een transformatie (bv logaritmisch) of zoek naar een verbetering van je model (toevoegen van variabelen)
 of. zoek naar een verbetering van je model. (toevoegen van variabelen)")
23
Betrouwbaarheidsintervallen (gemiddelden)
Breedte BI verschilt per leeftijd

24
Predictie-intervallen (individueel)
")
25
Kan men een lineaire regressie uitvoeren als de verklarende variabele dichotoom is?
Bijvoorbeeld wil men weten of bloeddruk afhangt van het geslacht

26
Kan men een lineaire regressie uitvoeren als de verklarende variabele dichotoom is?
Bijvoorbeeld wil men weten of bloeddruk afhangt van het geslacht man vrouw

27
Test van de richtingscoëfficiënt = gepoolde t-test
Gemiddelde vrouwen 154,97 Gemiddelde mannen: 147,74 H0: β1=0 Maakt de gebruikte codering iets uit? vrouw man

28
Verklarende variabelen:
Continu: ok Dichotoom: ok Nominaal met meer dan twee categorieën: maak dummy’s (hulpvariabelen) Ordinaal: als er sprake lijkt van een lineaire trend: ok, anders dummy’s
 Ordinaal: als er sprake lijkt van een lineaire trend: ok, anders dummy’s.")
29
Meervoudige lineaire regressie
Hoe berekenen we het effect van een variabele (X1) op Y terwijl we rekening willen houden met het effect van een tweede variabele (X2) op Y? Maar eerst: waarom is het eigenlijk nodig om rekening te houden met X2?
 op Y terwijl we rekening willen houden met het effect van een tweede variabele (X2) op Y Maar eerst: waarom is het eigenlijk nodig om rekening te houden met X2")
30
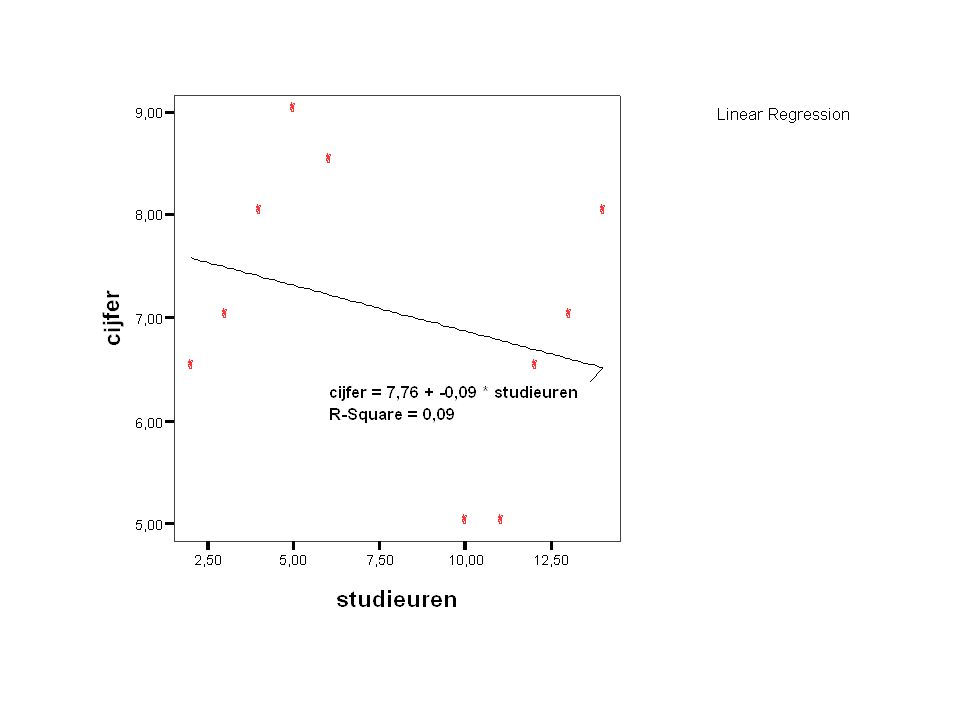
Relatie studie-uren en cijfer

32
Conclusie van deze enkelvoudige regressie-analyse:
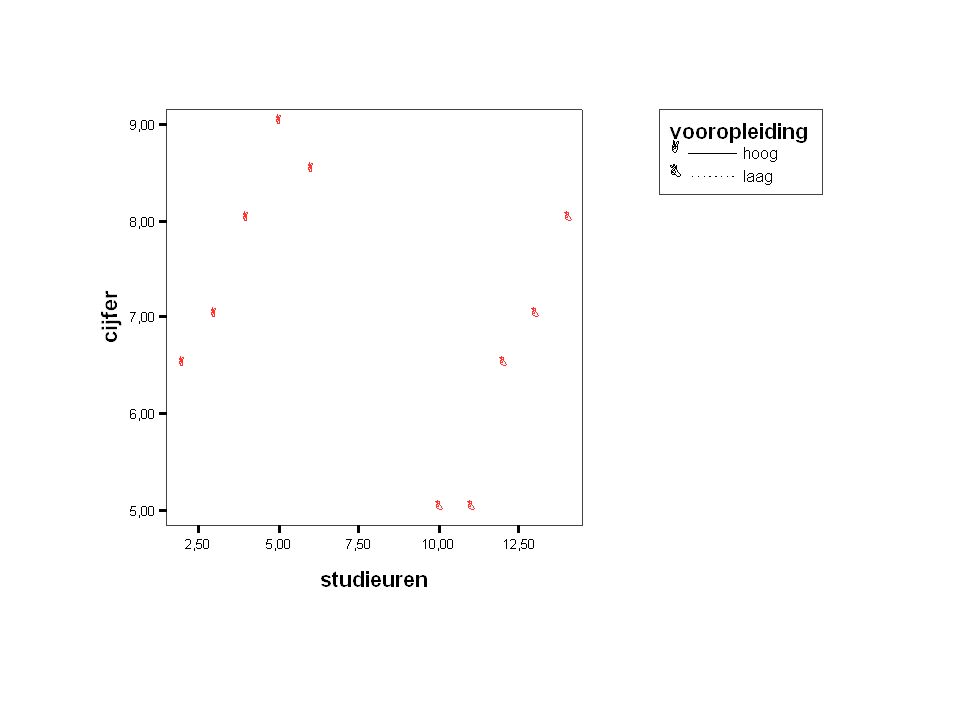
Hoe langer je studeert hoe lager je cijfer ????? Wat gebeurt er als we rekening houden met de vooropleiding van de respondenten?

35
Conclusie van deze meervoudige regressie-analyse
In beide groepen, gevormd op grond van de vooropleiding, is een positief effect van studie-uren op het cijfer Dit effect is in beide groepen ongeveer gelijk Als we geen rekening houden met de vooropleiding, schatten we het effect van studie-uren op het cijfer totaal verkeerd Vooropleiding wordt een confounder genoemd

36
Leeftijd verklaart ongeveer 3% van de spreiding van bloeddruk
Equivalentie van F-test en t-test Wat gebeurt er als we geslacht toevoegen?

38
Meervoudige lineaire regressie

39
Meervoudige lineaire regressie
Leeftijd en geslacht verklaren samen ongeveer 5 % van de spreiding van de bloeddruk ANOVA toetst de H0 dat leeftijd en geslacht samen niets verklaren Geen equivalentie meer tussen F-test en t-test(en) T-test van geslacht toetst de H0 dat geslacht niets verklaart, rekening houdend met leeftijd Was 0,33
 T-test van geslacht toetst de H0 dat geslacht. niets verklaart, rekening houdend met leeftijd. Was 0,33.")
40
SBP = 129 + 0,3*leeftijd + 6*geslacht
vrouwen (1) mannen (0) SBP = ,3*leeftijd + 6*geslacht
 mannen (0) SBP = ,3*leeftijd + 6*geslacht.")
41
NB Voor een meervoudige lineaire regressie gelden dezelfde voorwaarden als voor een enkelvoudige lineaire regressie: - onafhankelijke data - lineair verband - normaal verdeelde residuen - homogene spreiding van de residuen

42
Twee continue verklarende variabelen

43
Interactie Als het effect van een verklarende variabele beïnvloed wordt door een tweede verklarende variabele dan spreken we van interactie of effectmodificatie. Bijvoorbeeld als het effect van leeftijd op de bloeddruk bij rokers anders is dan bij niet rokers, is er sprake van interactie. In het lineair model wordt dan een interactieterm (bijvoorbeeld het product van leeftijd en roken) opgenomen.
 opgenomen.")
44
Model met interactie Bijvoorbeeld als X1 = leeftijd, X2 = roken (0 = niet, 1 = wel) dan wordt de vergelijking voor niet rokers: Y = β0 + β1*leeftijd + ε Maar voor rokers: Y = β0 + β1*leeftijd + β2*1 + β3*leeftijd*1 + ε = β0 + β2 + (β1 + β3)*leeftijd + ε Als de coëfficiënt van de interactieterm (β3) significant is, lopen de regressielijnen van rokers en niet-rokers niet parallel en spreken we van interactie (ook wel effectmodificatie genoemd). Als de interactieterm significant is, horen de bijbehorende hoofdeffecten ook in het model!
*leeftijd + ε. Als de coëfficiënt van de interactieterm (β3) significant is, lopen de. regressielijnen van rokers en niet-rokers niet parallel en spreken we van. interactie (ook wel effectmodificatie genoemd). Als de interactieterm significant is, horen de bijbehorende hoofdeffecten. ook in het model!")
45
Voorbeeld van interactie
leeftijd

46
Hoe wordt een model opgebouwd?
Kijk eerst naar univariate analyses (welke variabelen hangen samen met Y?) Selecteer variabelen die mogelijk een rol spelen in de multivariate analyse op grond van een ruime alfa (0,25) en theorie Bouw het model stap voor stap op, te beginnen met de meest significante verklarende variabele Kijk alleen naar interacties tussen variabelen die sterk significant zijn of waarvan je op grond van theorie of literatuur verwacht dat ze interacteren
 Selecteer variabelen die mogelijk een rol spelen in de multivariate analyse op grond van een ruime alfa (0,25) en theorie. Bouw het model stap voor stap op, te beginnen met de meest significante verklarende variabele. Kijk alleen naar interacties tussen variabelen die sterk significant zijn of waarvan je op grond van theorie of literatuur verwacht dat ze interacteren.")
47
De term “regressie” Regressie = terugval
Wat heeft dat met een lineair verband te maken? Onderzoek van Francis Galton naar de lengte van ouders en kinderen

48
Regression to the mean Francis Galton y = x Valkuil:
Regressie naar het gemiddelde! Francis Galton Regression towards mediocrity in hereditary stature. Journal of the Anthropological Institute 1886

49
Geen (normale) lineaire regressie
Y dichotoom Wel / geen verbetering na 1 uur Y categorisch (>2 categorieën) Y ordinaal Herhaalde waarnemingen Overlevingsduren Logistische regressie Polytome logistische regressie Ordinale logistische regressie Repeated measures MANOVA Mixed effects models Multilevel analyse Survival analyse
 Y ordinaal. Herhaalde waarnemingen. Overlevingsduren. Logistische regressie. Polytome logistische regressie. Ordinale logistische regressie. Repeated measures MANOVA. Mixed effects models. Multilevel analyse. Survival analyse.")
50
Volgende keer … Woensdag 20 juni: Logistische regressie
Zie Bedankt voor uw aandacht

Verwante presentaties