Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Optuigen van datastructuren
Zoeken op meerdere sleutels Dynamische order statistics (1)
")
2
Vandaag Optuigen van datastructuren: door het bijhouden van extra gegevens en/of het hebben van extra pointers kan je Extra functionaliteit bieden Sommige operaties sneller doen Meerdere sleutels Dynamische order statistics

3
Eerste voorbeeld: zoeken op twee keys
Stel, we hebben stel objecten met twee soorten keys (bijvoorbeeld: naam en registratienummer). We willen snel kunnen zoeken op elk van de twee soorten keys, gevonden objecten kunnen weglaten, etc. Delete1(“Introduction to Algorithms 2nd edition”) Delete2(“ ”) Je kan 2 zoekbomen (of hash-tabellen of …) gebruiken; elk object in beide datastructuren opslaan, maar hoe zorg je dat deletions goed gaan? Eerste voorbeeld: verschillende datastructuren aan elkaar koppelen door middel van allerlei pointers
. We willen snel kunnen zoeken op elk van de twee soorten keys, gevonden objecten kunnen weglaten, etc. Delete1( Introduction to Algorithms 2nd edition ) Delete2( ) Je kan 2 zoekbomen (of hash-tabellen of …) gebruiken; elk object in beide datastructuren opslaan, maar hoe zorg je dat deletions goed gaan Eerste voorbeeld: verschillende datastructuren aan elkaar koppelen door middel van allerlei pointers.")
4
Allerlei verwijzingen/pijlen zijn niet getekend in dit voorbeeld
Datastructuur Twee hash-tabellen met chaining, maar Dubbel-gelinkte lijsten (om snel iets uit de lijst weg te kunnen laten) Elk object heeft kopie in andere tabel en verwijzing naar kopie Variaties mogelijk Bespaar geheugen: sateliet-data maar op 1 plek Geen verwijzingen, maar “gewoon” zoeken en deleten in de andere tabel Operaties gaan in O(1) verwachtte tijd onder aannames: Simple uniform hashing aanname Loadfactor n/m=O(1) 5,4 5,4 Allerlei verwijzingen/pijlen zijn niet getekend in dit voorbeeld
 Elk object heeft kopie in andere tabel en verwijzing naar kopie. Variaties mogelijk. Bespaar geheugen: sateliet-data maar op 1 plek. Geen verwijzingen, maar gewoon zoeken en deleten in de andere tabel. Operaties gaan in O(1) verwachtte tijd onder aannames: Simple uniform hashing aanname. Loadfactor n/m=O(1) 5,4. 5,4. Allerlei verwijzingen/pijlen zijn niet getekend in dit voorbeeld.")
5
Zoekbomen met extra verwijzingen!
Alle operaties in O(log n): Gebruik gebalanceerde bomen (bijv. rood-zwart-bomen) Bij deletion: ook weglaten in kopie; opletten dat alle verwijzingen goed blijven staan 42,5 42,5 23,8 12,4 31,6 23,8 12,4 31,6 Kan ook met hashtabellen…
: Gebruik gebalanceerde bomen (bijv. rood-zwart-bomen) Bij deletion: ook weglaten in kopie; opletten dat alle verwijzingen goed blijven staan. 42,5. 42,5. 23,8. 12,4. 31,6. 23,8. 12,4. 31,6. Kan ook met hashtabellen…")
6
Dynamische order statistics
Extra operatie 1 op zoekboom (OS-Select): Voor i, 1 £ i £ n: wat het ide qua grootte in de datastructuur? Als i = 1, dan is dit het minimum Als i = n, dan is dit het maximum Als i = n/2, dan heet dit de mediaan We zoeken het element met rang i. Vb: als we keys 3, 6, 8, 10, 20 hebben, dan OS-Select(…, 4) = 10 Extra operatie 2 op zoekboom (OS-Rank): Gegeven een key x die in de zoekboom T staat, wat is de rang van x, d.w.z., het hoeveelste element qua grootte is het Vb. Als we keys 3, 6, 8, 10, 20 hebben, dan OS-Rank(T,3) = 1, OS-Rank(T,10) = 4, etc. We gaan een zoekboom (evt. rood-zwart) aanpassen zodat deze operaties ook snel (O(h), O(log n)) kunnen Nieuw onderwerp: dynamische order statistics
: Voor i, 1 £ i £ n: wat het ide qua grootte in de datastructuur Als i = 1, dan is dit het minimum. Als i = n, dan is dit het maximum. Als i = n/2, dan heet dit de mediaan. We zoeken het element met rang i. Vb: als we keys 3, 6, 8, 10, 20 hebben, dan OS-Select(…, 4) = 10. Extra operatie 2 op zoekboom (OS-Rank): Gegeven een key x die in de zoekboom T staat, wat is de rang van x, d.w.z., het hoeveelste element qua grootte is het. Vb. Als we keys 3, 6, 8, 10, 20 hebben, dan OS-Rank(T,3) = 1, OS-Rank(T,10) = 4, etc. We gaan een zoekboom (evt. rood-zwart) aanpassen zodat deze operaties ook snel (O(h), O(log n)) kunnen. Nieuw onderwerp: dynamische order statistics.")
7
Extra gegevens in zoekboom
Elke knoop x heeft nog 1 extra getal opgeslagen: het aantal keys in het deel van de boom met x als wortel 26 20 41 7 17 12 47 1 14 7 21 4 30 5 10 4 16 2 19 2 23 1 28 1 38 3 35 1 39 1 7 2 12 1 15 1 20 1 3 1

8
Bijhouden van deze gegevens
size(x): hoeveel afstammelingen (x inclusief) heeft x (aantal (niet-NIL) knopen in deelboom met x als wortel) (altijd integer) Invariant: size(x) = size(left(x))+ size(right(x)) +1 waarbij deze waarden 0 zijn voor NIL’s Bij veranderingen aan de boom: Herbereken de waarden voor de knopen waar we iets veranderden, en alle knopen naar het pad naar de wortel toe x
: hoeveel afstammelingen (x inclusief) heeft x (aantal (niet-NIL) knopen in deelboom met x als wortel) (altijd integer) Invariant: size(x) = size(left(x))+ size(right(x)) +1. waarbij deze waarden 0 zijn voor NIL’s. Bij veranderingen aan de boom: Herbereken de waarden voor de knopen waar we iets veranderden, en alle knopen naar het pad naar de wortel toe. x.")
9
Operaties in rood-zwart-boom
Als we een knoop x weglaten: Herbereken de size-waarden voor x en alle knopen op het pad van x naar de wortel Steeds worden die waarden 1 kleiner Als we een knoop x toevoegen: Zet size x op 1, en herbereken de size-waarden voor alle knopen op het pad van x naar de wortel Steeds worden die waarden 1 groter Als we een rotatie doen: Herbereken de size-waarden voor de twee geroteerde knopen en alle knopen op het pad van deze twee knopen naar de wortel Bij een rood-zwart-boom zijn er O(log n) knopen die: Geroteerd, weggelaten, toevoegd zijn, Of op het pad zitten van zo’n knoop naar de wortel Herbereken (van beneden naar boven) voor deze O(log n) knopen Bijhouden kan in O(log n) tijd per operatie
 knopen die: Geroteerd, weggelaten, toevoegd zijn, Of op het pad zitten van zo’n knoop naar de wortel. Herbereken (van beneden naar boven) voor deze O(log n) knopen. Bijhouden kan in O(log n) tijd per operatie.")
10
Van bijhouden naar gebruiken
Conclusie tot nu toe: we kunnen ervoor zorgen dat de waarden van size correct blijven, en Invoegen en weglaten gaan in O(h) tijd op een `gewone’ zoekboom in O(log n) tijd op een rood-zwartboom Nu: hoe gebruiken we die waarden voor snelle order statistic queries. Eerst: selectie (zoek het k-de element kwa grootte) Recursieve oplossing...
 tijd op een `gewone’ zoekboom. in O(log n) tijd op een rood-zwartboom. Nu: hoe gebruiken we die waarden voor snelle order statistic queries. Eerst: selectie (zoek het k-de element kwa grootte) Recursieve oplossing...")
11
Selectie OS-Select(x,i) {Werkt correct als 1 £ i £ size(x)}
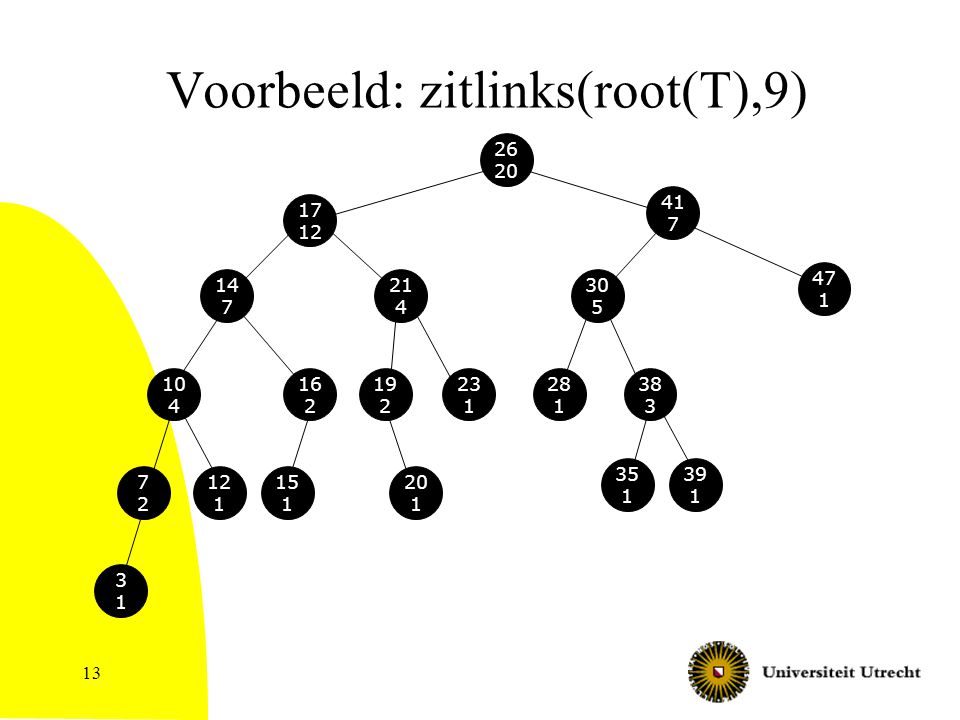
if left(x)==NIL then zitlinks =0 else zitlinks = size(left(x)) if (i £ zitlinks) then Return OS-Select(left(x),i) if (i = = zitlinks+1) then Return x (if (i > zitlinks + 1) then) Return OS-Select( right(x), i – zitlinks – 1 ) OS-Select(x, i): zoek het element met rang i in de deelboom met x als wortel Roep dit aan met OS-Select(root(T),i) Kijk naar het formaat van de linkerboom, zitlinks Dat vertelt of: Het gezochte element in de linkerboom zit OF De root het gezochte element is Het gezochte element in de rechterboom zit Er zijn al zitlinks + 1 kleinere elementen niet in de rechterboom
==NIL then. zitlinks =0. else. zitlinks = size(left(x)) if (i £ zitlinks) then. Return OS-Select(left(x),i) if (i = = zitlinks+1) then. Return x. (if (i > zitlinks + 1) then) Return OS-Select( right(x), i – zitlinks – 1 ) OS-Select(x, i): zoek het element met rang i in de deelboom met x als wortel. Roep dit aan met OS-Select(root(T),i) Kijk naar het formaat van de linkerboom, zitlinks. Dat vertelt of: Het gezochte element in de linkerboom zit OF. De root het gezochte element is. Het gezochte element in de rechterboom zit. Er zijn al zitlinks + 1 kleinere elementen niet in de rechterboom.")
12
Randgevallen Test of i in het goede interval zit:
if (1 £ i £ size(x)) then … (code als net) else return NIL
) then. … (code als net) else return NIL.")
13
Voorbeeld: zitlinks(root(T),9)
26 20 41 7 17 12 47 1 14 7 21 4 30 5 10 4 16 2 19 2 23 1 28 1 38 3 35 1 39 1 7 2 12 1 15 1 20 1 3 1
14
Tijd Selectie kan, als we size’s bijhouden, in O(h) tijd op een boom met hoogte h En omdat een rood-zwart-boom hoogte O(log n) heeft dus in O(log n) tijd op een rood-zwart-boom
 heeft dus in O(log n) tijd op een rood-zwart-boom.")
15
Bepalen van de rang OS-Rank(T,x) geeft 1+ het aantal elementen in T dat kleiner is dan x. Iets preciezer: als we gelijke keys kunnen hebben moeten die elementen voor x komen in een inorder-traversal Welke knopen moeten we tellen? 1 voor x zelf Alle knopen in de linkerdeelboom van x Sommige knopen die voorouder zijn van x: welke??? … Voor sommige voorouders z van x alle knopen in de linkerdeelboom van z: welke??

16
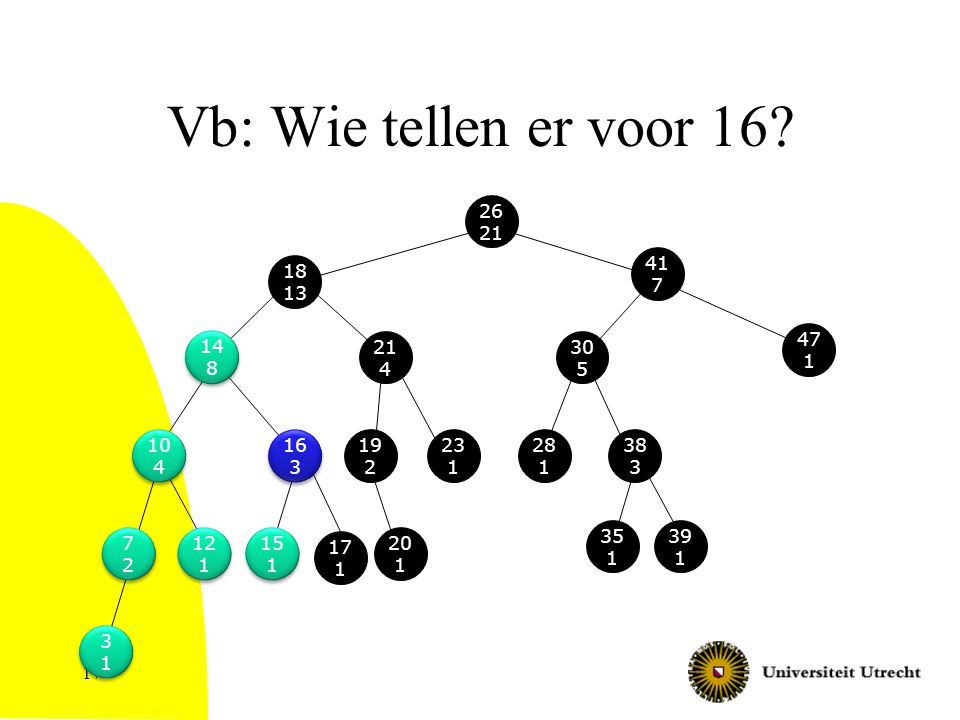
Bepalen van de rang OS-Rank(T,x) geeft 1+ het aantal elementen in T dat kleiner is dan x. Iets preciezer: als we gelijke keys kunnen hebben moeten die elementen voor x komen in een inorder-traversal Welke knopen moeten we tellen? 1 voor x zelf Alle knopen in de linkerdeelboom van x Sommige knopen die voorouder zijn van x Alle voorouders z waarvoor x in de rechterdeelboom van z zit Want dan is x groter dan z Voor deze voorouders z van x: alle knopen in de linkerdeelboom van z (die zijn allemaal kleiner dan z en dus kleiner dan x) Verder niet…
 Verder niet…")
17
Vb: Wie tellen er voor 16? 26 21 41 7 18 13 47 1 14 8 21 4 30 5 10 4 16 3 19 2 23 1 28 1 38 3 35 1 39 1 7 2 12 1 15 1 17 1 20 1 3 1
18
Welke knopen tellen? y is rechterkind kleiner y is linkerkind groter
z y is rechterkind kleiner 1 voor x zelf Alle knopen in de linkerdeelboom van x Sommige voorouders z van x en voor die voorouders z van x: alle knopen in de linkerdeelboom van z De test: y = = right(p(y)) Waarbij y het kind van z is in de deelboom waar x in zit Tel dit omhooglopend in de boom! y x y is linkerkind z y groter x
) Waarbij y het kind van z is in de deelboom waar x in zit. Tel dit omhooglopend in de boom! y. x. y is linkerkind. z. y. groter. x.")
19
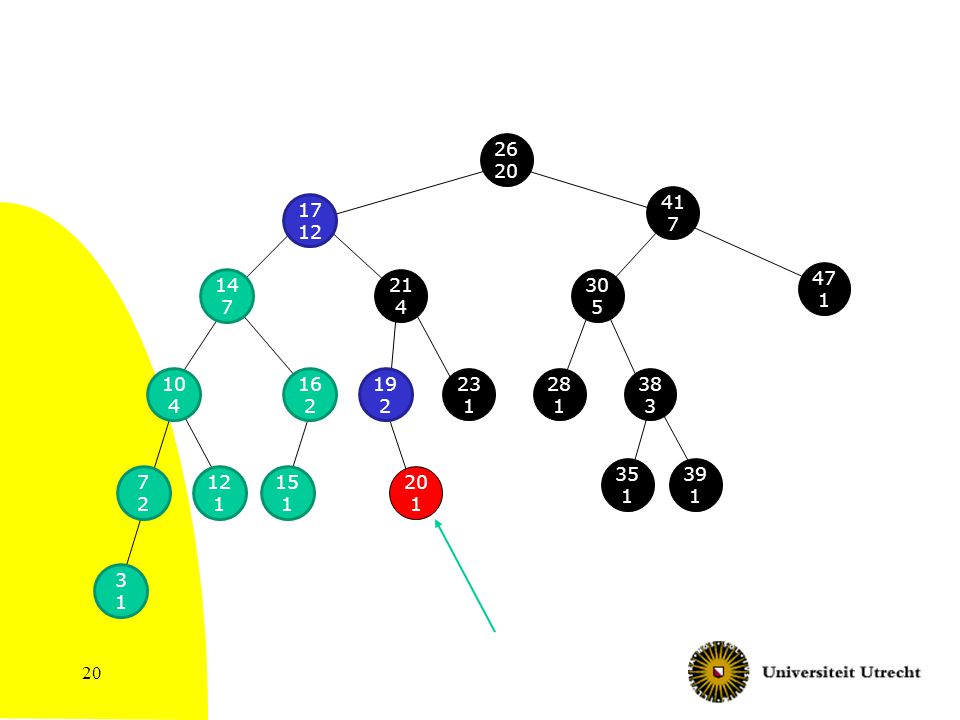
Pseudocode OS-Rank(T,x) if left(x)==NIL then else
totaal = 1 {alleen x} else totaal = size(left(x))+1 {x en alles in linkerboom van x} while (y != root(T)) do if y == right(p(y)) {y is een rechterkind} then if left(p(y)) == NIL then totaal++ {tel p(y)} else totaal = totaal + size(left(p(y))) + 1 {p(y) en alles in de linkerdeelboom van p(y)} y = p(y) {een stapje omhoog de boom in} Return totaal
)+1 {x en alles in linkerboom van x} while (y != root(T)) do. if y == right(p(y)) {y is een rechterkind} then. if left(p(y)) == NIL then totaal++ {tel p(y)} else totaal = totaal + size(left(p(y))) + 1. {p(y) en alles in de linkerdeelboom van p(y)} y = p(y) {een stapje omhoog de boom in} Return totaal.")
20
26 20 41 7 17 12 47 1 14 7 21 4 30 5 10 4 16 2 19 2 23 1 28 1 38 3 35 1 39 1 7 2 12 1 15 1 20 1 3 1
21
Zoeken van aantal 42 4 Aantal(T,k): hoeveel knopen in T hebben key precies k? Wat je kan doen is: Pas zoeken aan, en vindt de “meest linkse” node x met waarde k Bereken de rang i van k Pas zoeken aan, en vindt de “meest rechtse” node y met waarde k Bereken de rang j van k Output: j – i + 1 42 2 42 1 42 1 47 2 47 1 49 1

22
Andere evaluaties / Conclusies
Er zijn ook andere functies die je op een soortgelijke manier kan bijhouden Door toevoegen van extra informatie of pointers kan je soms Operaties op een datastructuur versnellen Extra functionaliteit toevoegen Analyse gaat: wiskundig EN experimenteel

Verwante presentaties










 Quiz Night !>")
 –Analyse –Oplossen.>")







