Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Neurale Netwerken Kunstmatige Intelligentie Rijksuniversiteit Groningen Mei 2005

2
overzicht samenvatting en discussie hc1 t/m hc4 samenvatting en discussie hc1 t/m hc4 inleiding tot de rest van het vak inleiding tot de rest van het vak toepassingen toepassingen

3
hc 1 neurale netwerken – een overzicht neurale netwerken – een overzicht biologische en kunstmatige neuronen biologische en kunstmatige neuronen boek: H1 en H2, 2.5 komt later boek: H1 en H2, 2.5 komt later

4
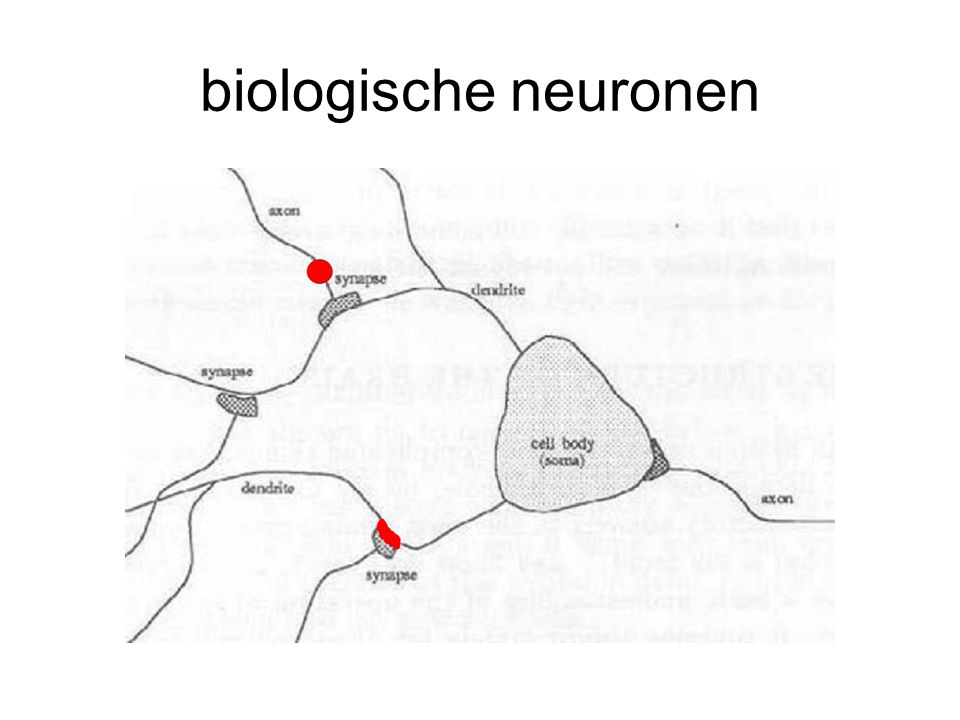
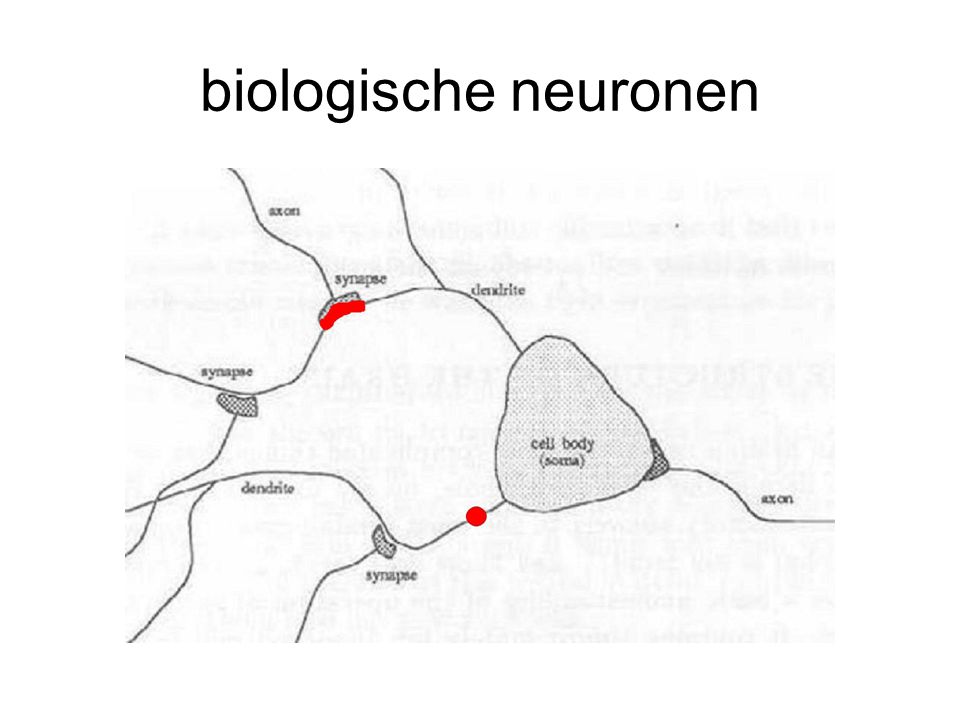
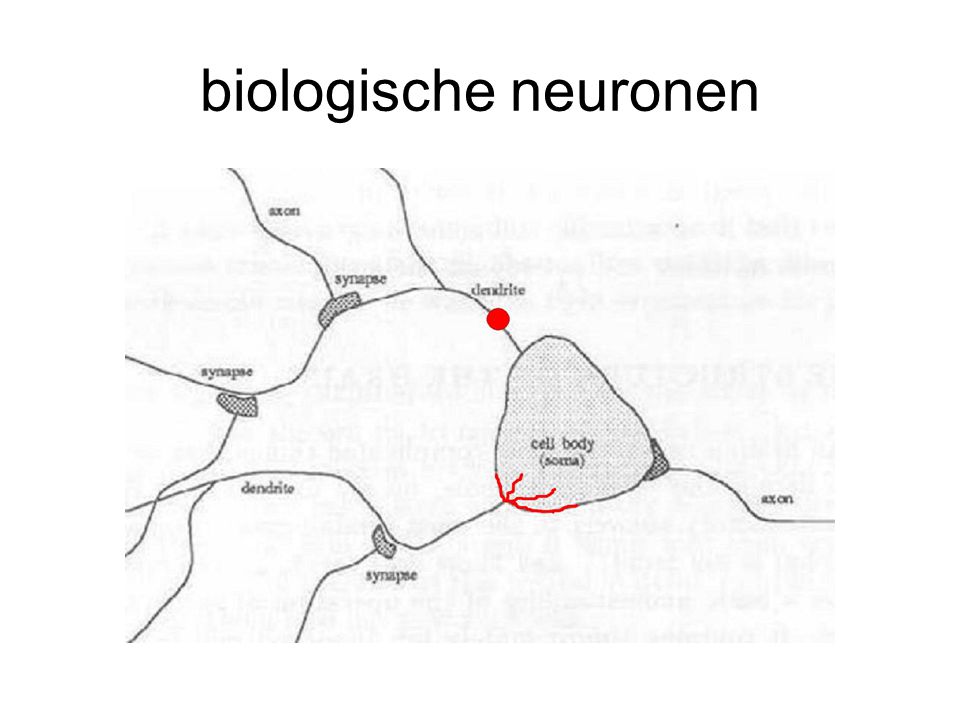
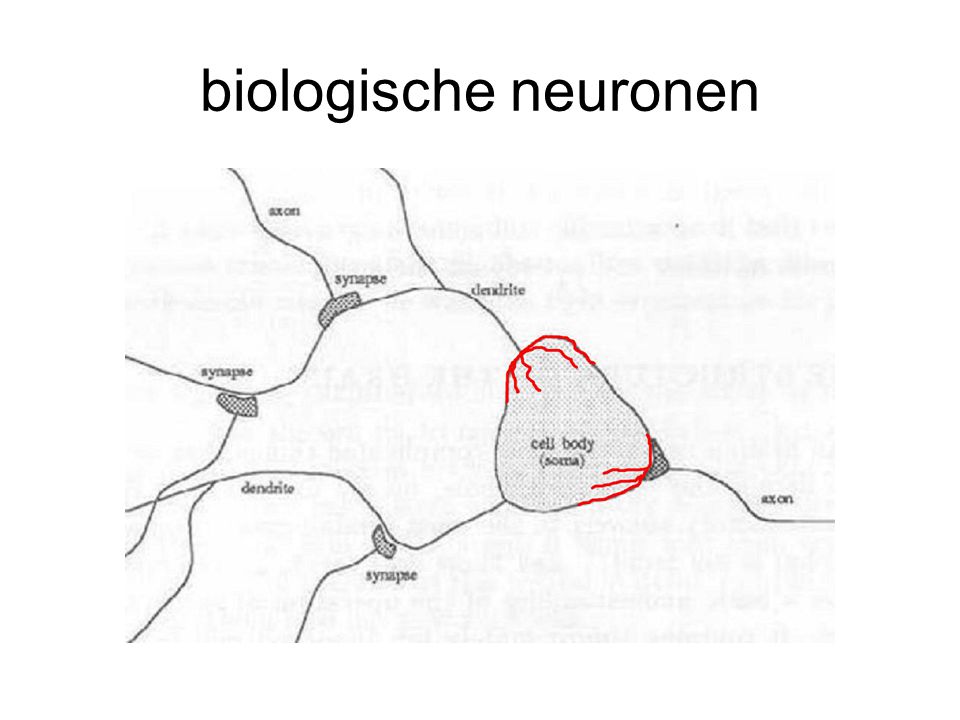
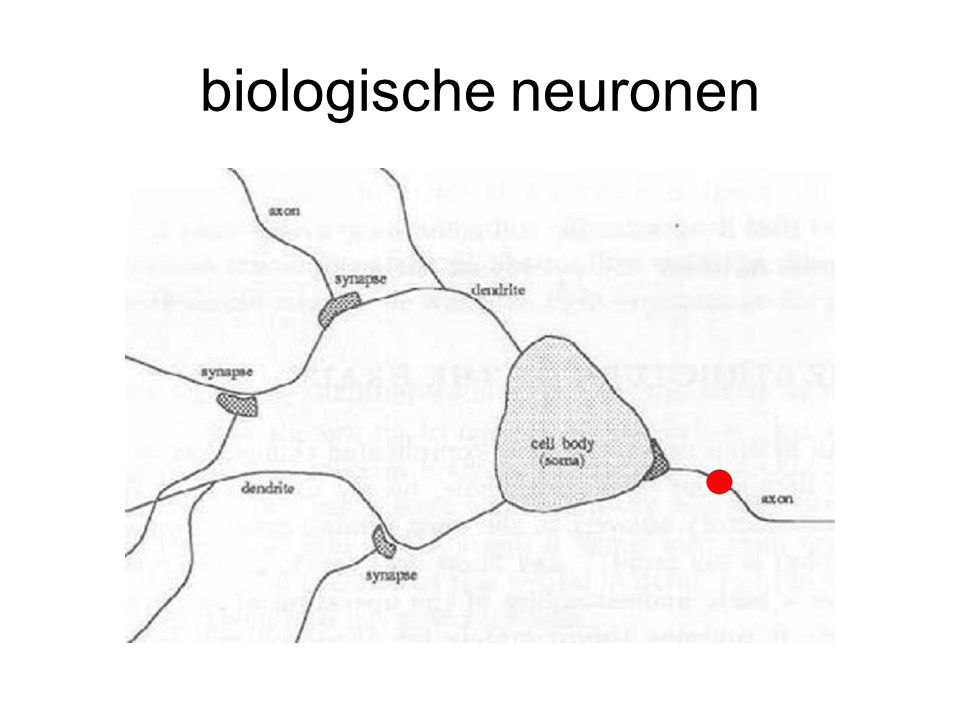
biologische neuronen uitleg termen op p. 12, 13 boek

5
biologische neuronen

12
kunstmatige neuronen: de Threshold Logic Unit y = 1 if a >= Θ y = 0 if a < Θ x1x1 w1w1 x3x3 w3w3 x2x2 y w2w2 boek: figuur 2.4 (iets andere weergave). McCullogh & Pitts (1943)
.")
13
informatieoverdracht tussen biologische en kunstmatige neuronen biologische neuronen gebruiken spike patronen kunstmatige neuronen gebruiken activatie tussen 0 en 1 axon activatie: biologischkunstmatig 00 f max 1

14
hc 2 TLUs, lineaire scheidbaarheid en vectoren TLUs, lineaire scheidbaarheid en vectoren TLUs trainen; de perceptron regel TLUs trainen; de perceptron regel boek: H3 en H4 boek: H3 en H4

15
y = 1 if a >= Θ y = 0 if a < Θ x1x1 w1w1 x2x2 y w2w2 1 TLU trainen (2 inputs, 1 output) “ordening” patterns en opsplitsen in trainingset {p 1,..., p n } en testset {p n + 1,..., p m } training set van patterns {p 1,..., p n }, p i = (x i1, x i2, t i ) voor elk pattern p i gewichten aanpassen dmv. error estimate (t i – y i ) y i is de output die de TLU geeft t i is wat de output zou moeten zijn test set van patterns {p n + 1,..., p m } error op de test set is de prestatie maat testen gebeurt na elk epoch
 y i is de output die de TLU geeft t i is wat de output zou moeten zijn test set van patterns {p n + 1,..., p m } error op de test set is de prestatie maat testen gebeurt na elk epoch.")
16
w’ = w + αvw’ = w – αv t y w’ = w + α(t – y)v 1 1 1 0 0 1 0 Δw = α(t – y)v vector components i = 1 t/m (n + 1): Δw i = α(t – y)v i w = (w 1, w 2,..., w n, θ) v = (v 1, v 2,..., v n, -1) Perceptron Training Rule
v Δw = α(t – y)v vector components i = 1 t/m (n + 1): Δw i = α(t – y)v i w = (w 1, w 2,..., w n, θ) v = (v 1, v 2,..., v n, -1) Perceptron Training Rule")
17
the perceptron training algorithm boek p. 34 repeat for each training vector pair (v, t) evaluate the output y when v is input to the TLU if y ≠ t then form new weight vector w’ according to (4.4) else do nothing end if end for loop until y = t for all input vectors (4.4) w’ = w + α(t – y)v Perceptron Convergence Theorem: Als twee klasses lineair scheidbaar zijn zal het toepassen van bovenstaand algoritme leiden tot een decision hyperplane dat de twee klasses van elkaar scheidt. bewezen door Rosenblatt (1962)
 evaluate the output y when v is input to the TLU if y ≠ t then form new weight vector w’ according to (4.4) else do nothing end if end for loop until y = t for all input vectors (4.4) w’ = w + α(t – y)v Perceptron Convergence Theorem: Als twee klasses lineair scheidbaar zijn zal het toepassen van bovenstaand algoritme leiden tot een decision hyperplane dat de twee klasses van elkaar scheidt. bewezen door Rosenblatt (1962).")
18
hc 3 herhaling hc 2 herhaling hc 2 de delta regel de delta regel begin hc4 begin hc4 boek: H3, H4, H5 en 6.1 boek: H3, H4, H5 en 6.1

19
gradient descent E “n + 1 weights” locale minima globaal minimum E w

20
pattern training (sequential ipv. batch) error estimate e p : sequential learning snel, schatting delta regel w convergeert naar w 0, E(w 0 ) is een minimum bij niet lineair scheidbare problemen geeft w 0 het beste decision hyperplane perceptron regel w blijft oscilleren perceptron rule is afgeleid van hyperplane manipulation delta regel van gradient descent op de kwadratische fout
 error estimate e p : sequential learning snel, schatting delta regel w convergeert naar w 0, E(w 0 ) is een minimum bij niet lineair scheidbare problemen geeft w 0 het beste decision hyperplane perceptron regel w blijft oscilleren perceptron rule is afgeleid van hyperplane manipulation delta regel van gradient descent op de kwadratische fout.")
21
the delta rule training algorithm boek p. 59 repeat for each training vector pair (v, t) evaluate activation a when v is input to the TLU adjust each of the weights according to (5.13) end for loop until the rate of change of the error is sufficiently small.
 evaluate activation a when v is input to the TLU adjust each of the weights according to (5.13) end for loop until the rate of change of the error is sufficiently small..")
22
σ(a) σ’(a) -1 0 1 a uitbreiding van één TLU naar een single layer netwerk: σ’(a) Is het grootst rond a = 0, dan zijn de aanpassingen aan de gewichtsvector ook het grootst. input pattern index p neuron index j gewichts/input index i

23
hc 4 multilayer netwerken en backpropagation multilayer netwerken en backpropagation boek H6 boek H6

24
multilayer nets en backpropagation gradient descent op error E(w) sequential learning (pattern mode of training) outputs worden vergeleken met targets probleem: geen targets voor hidden neurons credit assignment problem
 sequential learning (pattern mode of training) outputs worden vergeleken met targets probleem: geen targets voor hidden neurons credit assignment problem")
25
de gegeneraliseerde delta regel input pattern index p neuron index k, j gewichts/input index i I k : de verzameling van neuronen die de output van neuron k als input hebben

26
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern train on that pattern end for loop until the error is acceptably low. epoch

27
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input... end for loop until the error is acceptably low.

28
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input hiddens calculate their output... end for loop until the error is acceptably low.

29
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input hidden neurons calculate their output this output is input to next step output neurons calculate output... end for loop until the error is acceptably low.

30
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input hidden neurons calculate their output this output is input to next step output neurons calculate output compare output to target... end for loop until the error is acceptably low.

31
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input hidden neurons calculate their output this output is input to next step output neurons calculate output compare output to target calculate δ’s for output neurons (eq. 6.5)... end for loop until the error is acceptably low.
... end for loop until the error is acceptably low..")
32
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input hidden neurons calculate their output this output is input to next step output neurons calculate output compare output to target calculate δ’s for output neurons (eq. 6.5) train output neurons with δ’s (eq. 6.4)... end for loop until the error is acceptably low.
 train output neurons with δ’s (eq. 6.4)... end for loop until the error is acceptably low..")
33
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input hidden neurons calculate their output this output is input to next step output neurons calculate output compare output to target calculate δ’s for output neurons (eq. 6.5) train output neurons with δ’s (eq. 6.4) calculate δ’s for hidden neurons (eq. 6.6)... end for loop until the error is acceptably low.
 train output neurons with δ’s (eq. 6.4) calculate δ’s for hidden neurons (eq. 6.6)... end for loop until the error is acceptably low..")
34
6.2 The backpropagation algorithm boek: p. 68 initialize weights repeat for each training pattern present input hidden neurons calculate their output this output is input to next step output neurons calculate output compare output to target calculate δ’s for output neurons (eq. 6.5) train output neurons with δ’s (eq. 6.4) calculate δ’s for hidden neurons (eq. 6.6) train hidden neurons with δ’s (eq. 6.4)... NOG EEN LAAG? end for loop until the error is acceptably low.
 train output neurons with δ’s (eq. 6.4) calculate δ’s for hidden neurons (eq. 6.6) train hidden neurons with δ’s (eq. 6.4)... NOG EEN LAAG. end for loop until the error is acceptably low..")
35
eq. 6.4, 6.5 en 6.6 (van boven naar beneden)
")
36
1 45 32 y1y1 y2y2 input 1 input 2 output 1 output 2

37
ontsnappen uit locale minima mogelijkheden: sequential ipv. batch (zie fig. 5.7) randomize training set na elk epoch momentum term learning rate: trade-off stabiliteit en snelheid afnemende learning rate locale minima globaal minimum E w
 randomize training set na elk epoch momentum term learning rate: trade-off stabiliteit en snelheid afnemende learning rate locale minima globaal minimum E w.")
38
E(w) #epochs test set training set overfitting is in de praktijk geen probleem, mits netwerk niet te groot goed gevulde pattern space, gelijkmatig verdeeld, 5 samples per degree of freedom (gewicht) #epochs vaak niet groter dan 100 Wanneer stop je met trainen?
 #epochs test set training set overfitting is in de praktijk geen probleem, mits netwerk niet te groot goed gevulde pattern space, gelijkmatig verdeeld, 5 samples per degree of freedom (gewicht) #epochs vaak niet groter dan 100 Wanneer stop je met trainen")
Verwante presentaties










 prof. dr. L. Schomaker (2004) KI RuG.>")




 (j = kandidaat in eerste i-blok)>")




