Download de presentatie
1
search engines welk instrument voor welke taak eric sieverts Universiteitsbibliotheek Utrecht Instituut voor Media en Informatiemanagement / HvA Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
2
information retrieval retrieval is een commodity geworden als dat al in elk systeem zit, is het dan nog wel interessant ? JA ! want iedereen heeft ermee te maken want de vraag is niet meer OF, maar HOE en die hoe-vraag blijft interessant Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001).")
3
information retrieval kwaliteit en extra functionaliteit wordt steeds belangrijker –op het web –in intranets maar dat zijn wel heel verschillende omgevingen Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
4
wat is waar belangrijk ? web 1.relevantie/precisie (probleem van de grote hoeveelheid) 2.wat is er nieuw ? 3.volledigheid (die éne) intranet 1.volledigheid (alle relevante informatie) 2.wat is er nieuw ? 3.relevantie/precisie (het is al beperkt domein) Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 2.wat is er nieuw . 3.volledigheid (die éne) intranet 1.volledigheid (alle relevante informatie) 2.wat is er nieuw . 3.relevantie/precisie (het is al beperkt domein) Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001).")
5
wat is waar belangrijk ? Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) web search tools richten zich vooral DAAR op web 1.relevantie/precisie (probleem van de grote hoeveelheid) 2.wat is er nieuw ? 3.volledigheid (die éne)
 Retrieval Day (1/11/2001) web search tools richten zich vooral DAAR op web 1.relevantie/precisie (probleem van de grote hoeveelheid) 2.wat is er nieuw . 3.volledigheid (die éne).")
6
wat is waar belangrijk ? Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) maar wat DAAR goed werkt, hoeft DAAR nog niet goed te werken intranet 1.volledigheid (alle relevante informatie) 2.wat is er nieuw ? 3.relevantie/precisie (het is al beperkt domein) web 1.relevantie/precisie (probleem van de grote hoeveelheid) 2.wat is er nieuw ? 3.volledigheid (die éne)
 Retrieval Day (1/11/2001) maar wat DAAR goed werkt, hoeft DAAR nog niet goed te werken intranet 1.volledigheid (alle relevante informatie) 2.wat is er nieuw . 3.relevantie/precisie (het is al beperkt domein) web 1.relevantie/precisie (probleem van de grote hoeveelheid) 2.wat is er nieuw . 3.volledigheid (die éne).")
7
zoekmachines op het web web is uitstekende proeftuin, want daar is gratis onuitputtelijke hoeveelheid informatie beschikbaar maar: niet alles wat daar is ontwikkeld blijft daar ook beschikbaar het veelsoortige materiaal op het web is niet representatief voor elke collectie informatie Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
8
de algemene zoek-problemen te lage recall: je mist te veel te lage precisie / te lage relevantie: te veel niet relevante gevonden ondanks relevance ranking zijn de eerste niet relevant genoeg Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
9
recall-killers fouten in zoektermen (spelling) verkeerde zoektermen andere mogelijke vormen van zelfde woord veel mogelijke synoniemen te veel zoekelementen gecombineerd Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 verkeerde zoektermen andere mogelijke vormen van zelfde woord veel mogelijke synoniemen te veel zoekelementen gecombineerd Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)")
10
precisie-/relevantie-killers te weinig zoekelementen gecombineerd ongewenst syntactisch verband tussen de elementen zoektermen met meer betekenissen gebruikte zoekterm niet specifiek genoeg full-text bevat veel betekenisloze woorden Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
11
taaltechnologie ter verbetering betere relevance ranking technieken semantische kennis toevoegen zoekresultaat in "domeinen” laten indelen terugkoppeling van zoekersoordeel Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
12
relevance ranking kan een computer beoordelen of de ene hit relevanter is dan de andere ? nee, maar je kan wel proberen factoren te bedenken die daar “waarschijnlijk” mee samenhangen (en waarmee de computer kan rekenen) Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001).")
13
relevance ranking factoren 1.meer van de gevraagde termen in een document 2.gevraagde termen in titel of begin van document 3.gevraagde termen komen in document herhaald voor 4.gevraagde termen staan in document dicht bij elkaar 5.termen in document staan in zelfde volgorde als in de vraag 6.zeldzame termen krijgen zwaarder gewicht dan algemene 7.hoeveelheid hyperlinks die naar document verwijst 8.hoe vaak een document wordt "bezocht" google bewijst dat dat goed werkt Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
14
1.meer van de gevraagde termen in een document 2.gevraagde termen in titel of begin van document 3.gevraagde termen komen in document herhaald voor 4.gevraagde termen staan in document dicht bij elkaar 5.termen staan in document in zelfde volgorde als in de vraag 6.zeldzame termen krijgen zwaarder gewicht dan algemene 7.hoeveelheid hyperlinks die naar document verwijst 8.hoe vaak een document wordt "bezocht" relevance ranking factoren Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) allemaal gericht op hogere relevantie voor "de eerste tien", dus op precisie
 Retrieval Day (1/11/2001) allemaal gericht op hogere relevantie voor de eerste tien , dus op precisie")
15
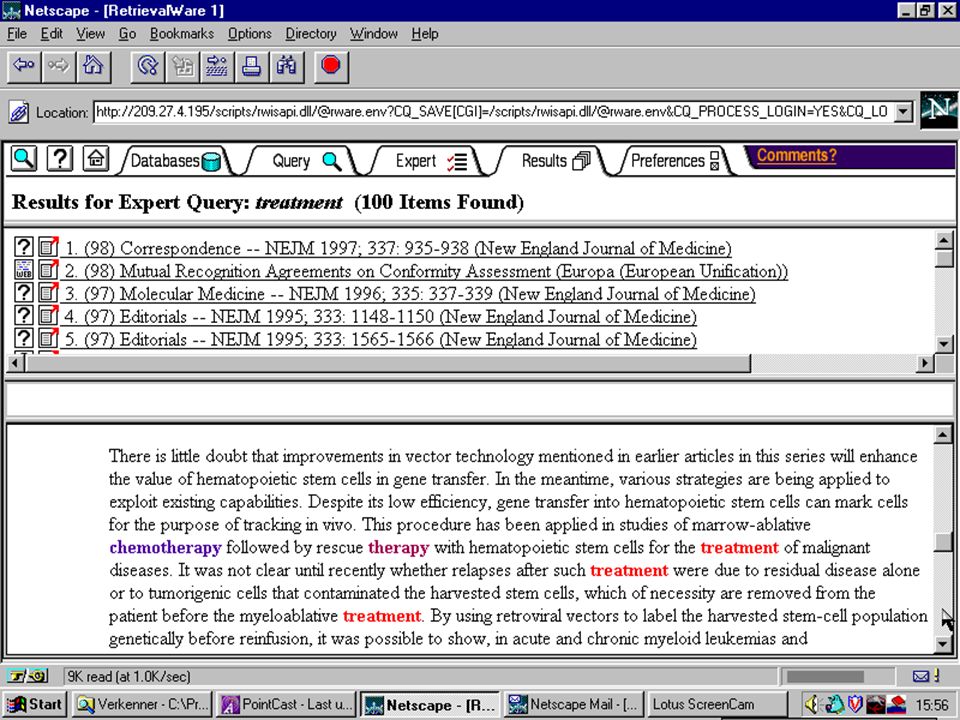
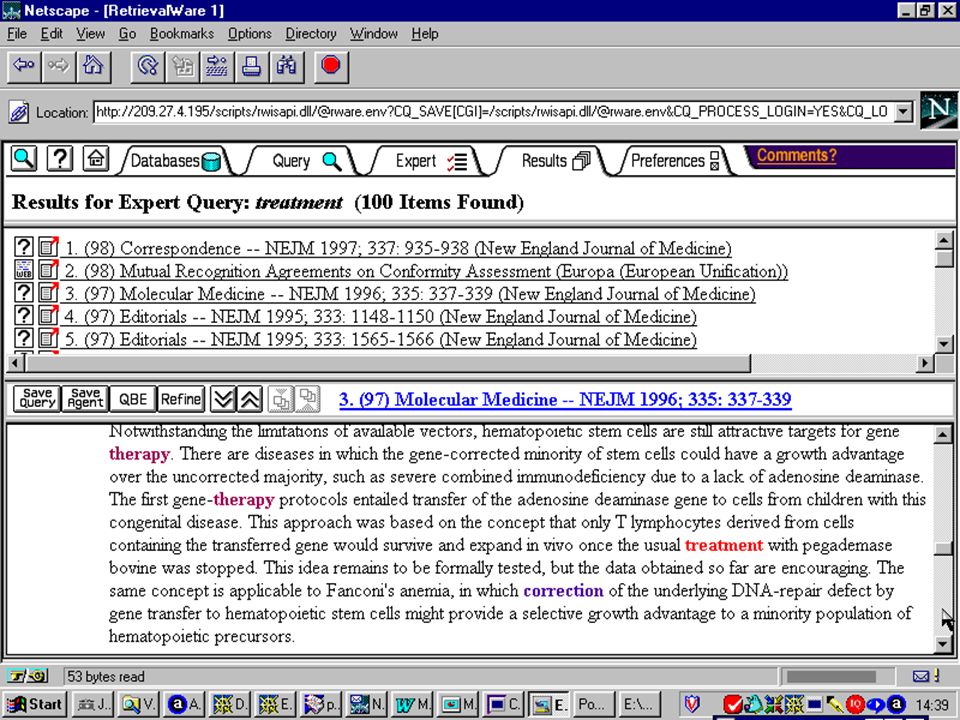
semantische kennis in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) omgeving van woord in het netwerk kan betekenissen onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) voorbeeld: retrievalware van excalibur
 omgeving van woord in het netwerk kan betekenissen onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) voorbeeld: retrievalware van excalibur")
16
visualisatie van wordnet

17
bepaalde gewenste betekenissen van zoekterm geselecteerd

20
semantische kennis in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) omgeving van woord in het netwerk kan betekenissen onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) verbeteren van precisie verbeteren van recall
 omgeving van woord in het netwerk kan betekenissen onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) verbeteren van precisie verbeteren van recall")
21
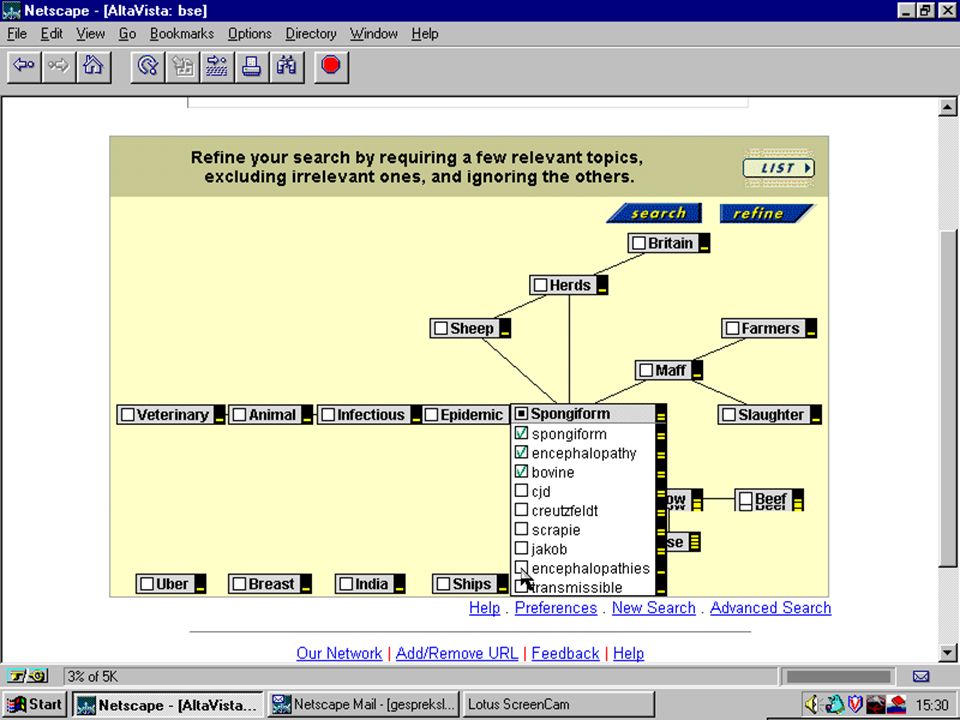
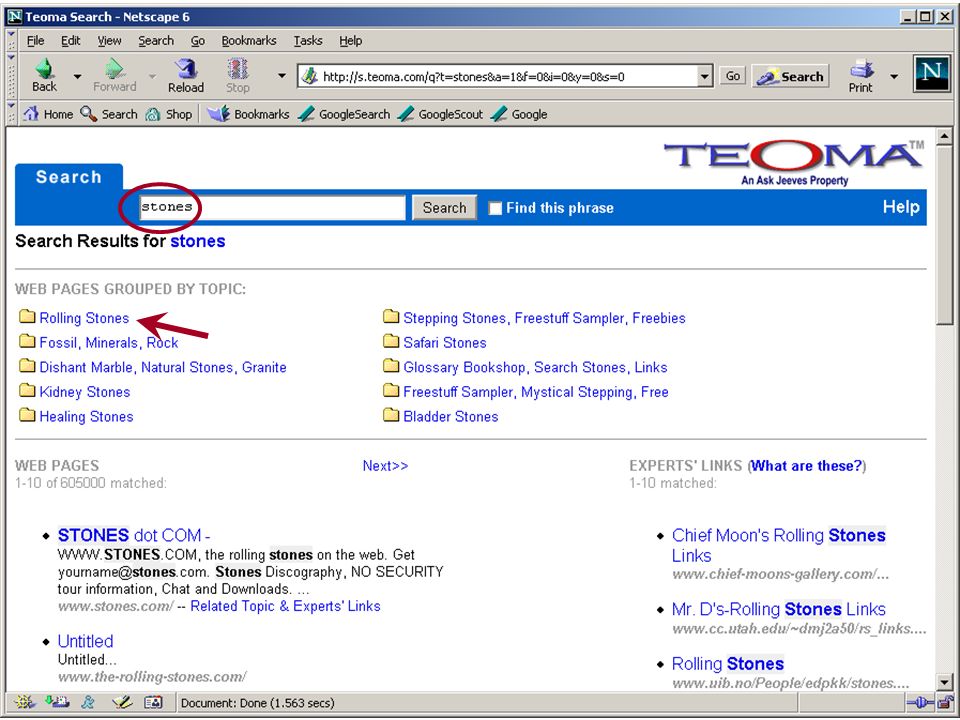
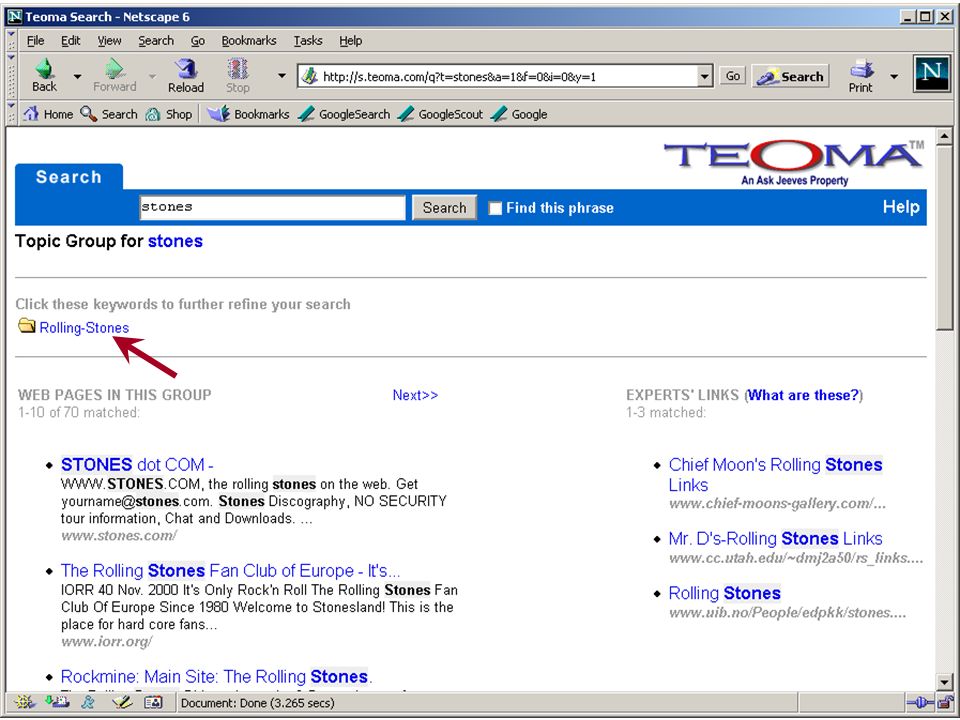
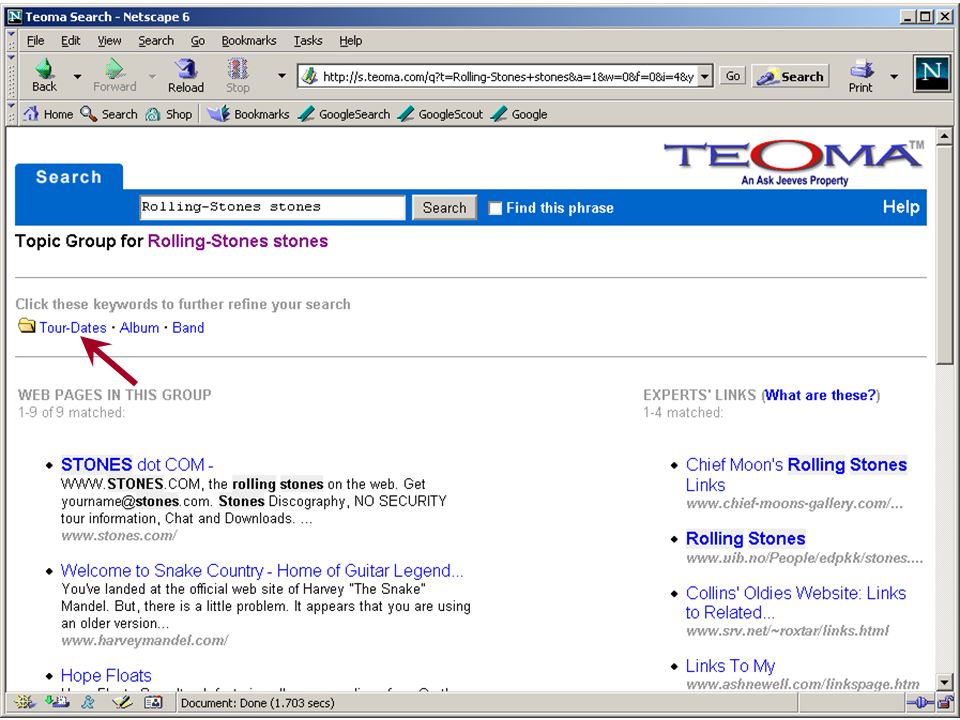
automatisch clusteren/classificeren op grond van kennisregels (en bestaande taxonomie) –NorthernLight “custom search folders” –SmartLogik's MuscatStructure software –Verity filters/topics op grond van statistiek of patronen –AltaVista (3 jaar geleden) –Teoma –Autonomy Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 –NorthernLight custom search folders –SmartLogik s MuscatStructure software –Verity filters/topics op grond van statistiek of patronen –AltaVista (3 jaar geleden) –Teoma –Autonomy Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)")
22
custom search folders

23
toekenning document aan taxonomy-term gebaseerd op rules base, zoals bij producten van Verity of Smartlogik

24
op grond van kennisregels (en bestaande taxonomie) –NorthernLight “custom search folders” –SmartLogik's MuscatStructure software –Verity filters/topics op grond van statistiek of patronen –AltaVista (3 jaar geleden) –Teoma –Autonomy Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) automatisch clusteren/classificeren
 –NorthernLight custom search folders –SmartLogik s MuscatStructure software –Verity filters/topics op grond van statistiek of patronen –AltaVista (3 jaar geleden) –Teoma –Autonomy Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) automatisch clusteren/classificeren")
36
op grond van kennisregels (en bestaande taxonomie) –NorthernLight “custom search folders” –SmartLogik's MuscatStructure software –Verity filters/topics op grond van statistiek of patronen –AltaVista (3 jaar geleden) –Teoma –Autonomy verbeteren van precisie automatisch clusteren/classificeren Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 –NorthernLight custom search folders –SmartLogik s MuscatStructure software –Verity filters/topics op grond van statistiek of patronen –AltaVista (3 jaar geleden) –Teoma –Autonomy verbeteren van precisie automatisch clusteren/classificeren Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)")
37
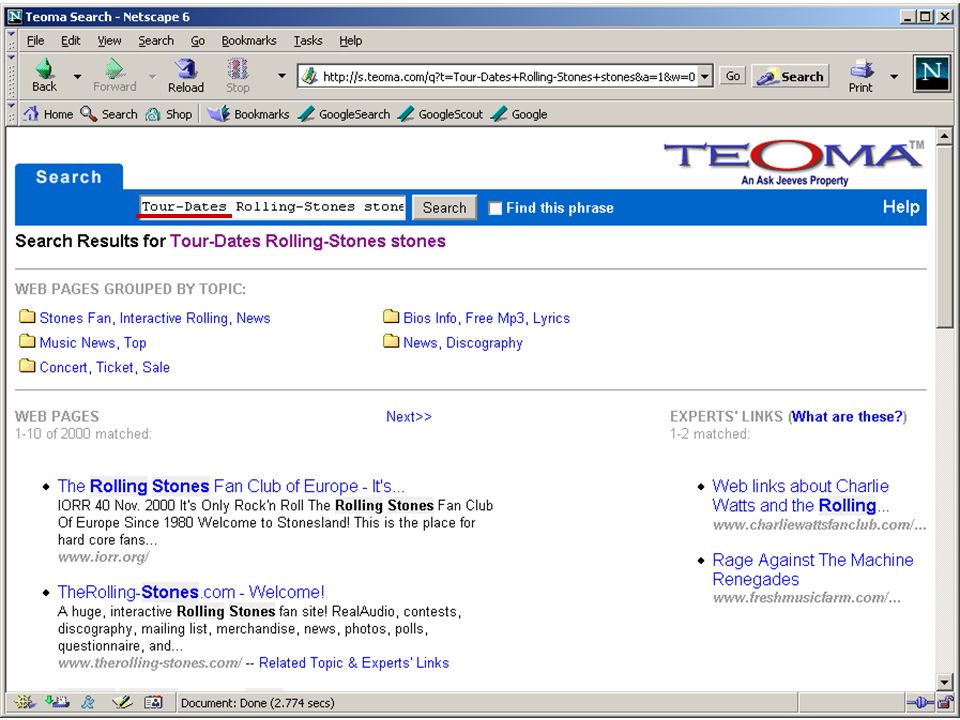
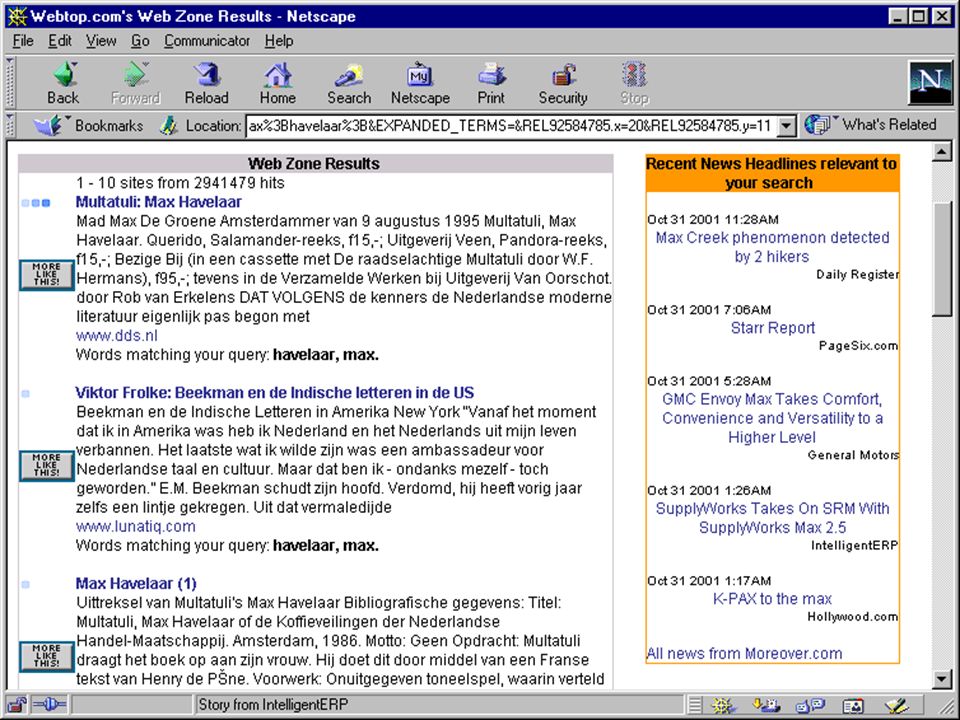
terugkoppeling gebruiker klikt bij relevante hit op “more like this” computer zoekt op grond van daarin aanwezige termen of patronen naar daarop lijkende documenten bijv.:Webtop zoekmachine Autonomy Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
38
max havelaar keurmerk producten max havelaar - het boek more like this

40
terugkoppeling gebruiker klikt bij relevante hit op “more like this” computer zoekt op grond van daarin aanwezige termen of patronen naar daarop lijkende documenten bijv.:Webtop zoekmachine Autonomy Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) verbeteren van precisie
 Retrieval Day (1/11/2001) verbeteren van precisie")
41
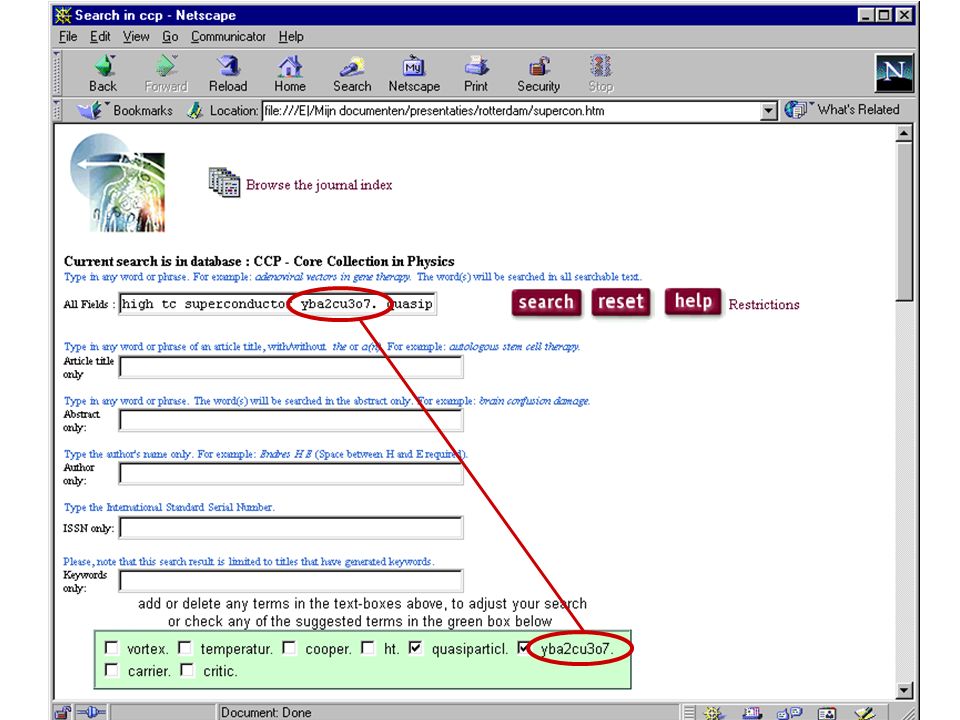
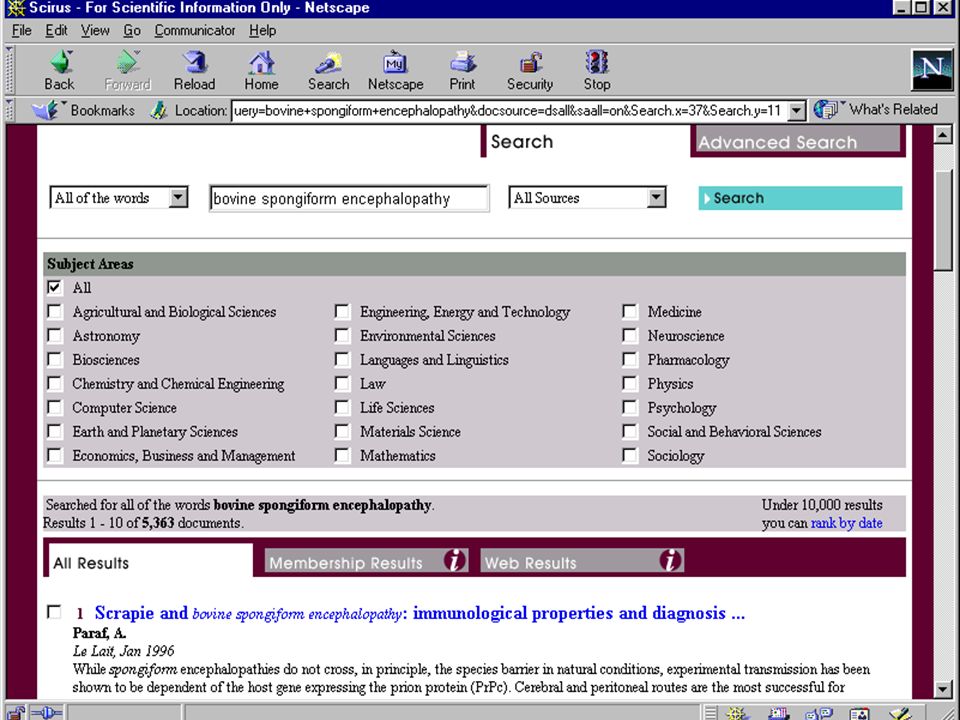
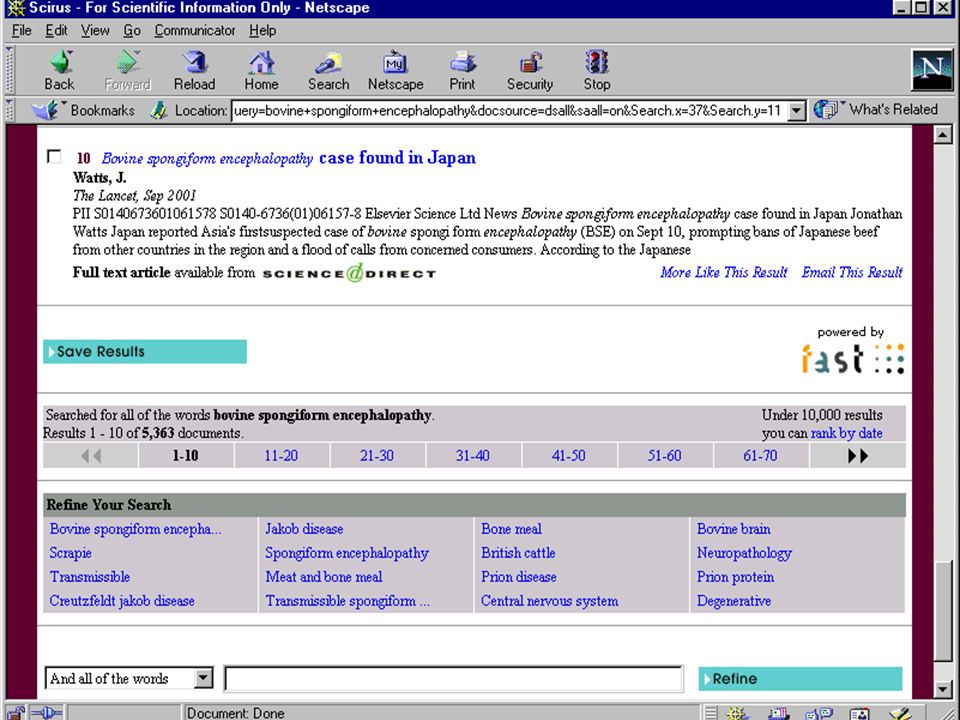
terugkoppeling gebruiker markeert relevante hits computer haalt karakteristieke (andere) termen uit die documenten (statistiek) gebruiker kiest daaruit termen om de zoekactie uit te breiden / in te perken bijv.: SmartLogik MuscatDiscovery software Scirus database van Elsevier Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 termen uit die documenten (statistiek) gebruiker kiest daaruit termen om de zoekactie uit te breiden / in te perken bijv.: SmartLogik MuscatDiscovery software Scirus database van Elsevier Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)")
46
terugkoppeling gebruiker markeert relevante hits computer haalt karakteristieke (andere) termen uit die documenten (statistiek) gebruiker kiest daaruit termen om de zoekactie uit te breiden / in te perken Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) verbeteren van precisie en soms recall
 termen uit die documenten (statistiek) gebruiker kiest daaruit termen om de zoekactie uit te breiden / in te perken Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) verbeteren van precisie en soms recall")
47
terugkoppeling gebruiker markeert relevante hits zoektermen of patronen die in die documenten voorkomen krijgen hoger gewicht bij toekomstige zoekacties krijgen documenten met die termen of patronen een hogere berekende relevantie bijv.: - SmartLogik MuscatDiscovery software - Autonomy Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
48
terugkoppeling Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001) gebruiker markeert relevante hits zoektermen of patronen die in die documenten voorkomen krijgen hoger gewicht bij toekomstige zoekacties krijgen documenten met die termen of patronen een hogere berekende relevantie bijv.: - SmartLogik MuscatDiscovery software - Autonomy verbeteren van precisie
 Retrieval Day (1/11/2001) gebruiker markeert relevante hits zoektermen of patronen die in die documenten voorkomen krijgen hoger gewicht bij toekomstige zoekacties krijgen documenten met die termen of patronen een hogere berekende relevantie bijv.: - SmartLogik MuscatDiscovery software - Autonomy verbeteren van precisie")
49
agents hulpprogramma’s om zonder begeleiding informatie voor je te zoeken (bijvoorbeeld voor automatische attendering) maar pas op voor de hype: het “filtert” maar dat is meestal gewoon retrieval je moet zelf opgeven waarin de agent moet zoeken of waar hij heen moet gaan wel prima voor attendering uit vaste bronnen gebruiken vaak al goede terugkoppeltechnieken Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 maar pas op voor de hype: het filtert maar dat is meestal gewoon retrieval je moet zelf opgeven waarin de agent moet zoeken of waar hij heen moet gaan wel prima voor attendering uit vaste bronnen gebruiken vaak al goede terugkoppeltechnieken Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)")
50
retrieval of taxonomie al gaat retrieval steeds beter, toch zijn er veel situaties waar bladeren door onderwerps- indelingen - taxonomieën - toch nog handiger is op web: Yahoo, Open Directory ook vaak te groot, te veel takken, moeilijk consistent te houden, te veel links per rubriek in intranet: beperkt domein, afgestemd op eigen organisatie eerder genoemde clustertechnieken te gebruiken Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")
51
conclusie ? / vragen ? Eric Sieverts (MIM-HvA/UBU) Retrieval Day (1/11/2001)
 Retrieval Day (1/11/2001)")