Download de presentatie
1
Databases I Normaliseren Martin Caminada / Wiebren de Jonge Vrije Universiteit, Amsterdam definitieve versie 2002

2
Overzicht Reeds behandeld: –welke vormen van redundantie zijn er en hoe herken je ze? Te behandelen: –hoe moet je redundantie vermijden? –wat zijn de valkuilen?

3
Voorbeeld Normaliseren (1/2) F = {sofinr naam, sofinr adres, sofinr gdatum } Key: {sofinr, vmiddel} FD’s in F zijn allen r_partiëel, dus 1NF (en geen 2NF)
 F = {sofinr naam, sofinr adres, sofinr gdatum } Key: {sofinr, vmiddel} FD’s in F zijn allen r_partiëel, dus 1NF (en geen 2NF)")
4
Introductie Normaliseren (5/5) F = {sofinr naam, sofinr adres, sofinr gdatum} Key R 1 : {sofinr}Key R 2 : {sofinr, vmiddel} F 1 = FF 2 = R 1 is in BCNFR 2 is in BCNF (dus het hele schema is in BCNF)
 F = {sofinr naam, sofinr adres, sofinr gdatum} Key R 1 : {sofinr}Key R 2 : {sofinr, vmiddel} F 1 = FF 2 = R 1 is in BCNFR 2 is in BCNF (dus het hele schema is in BCNF)")
13
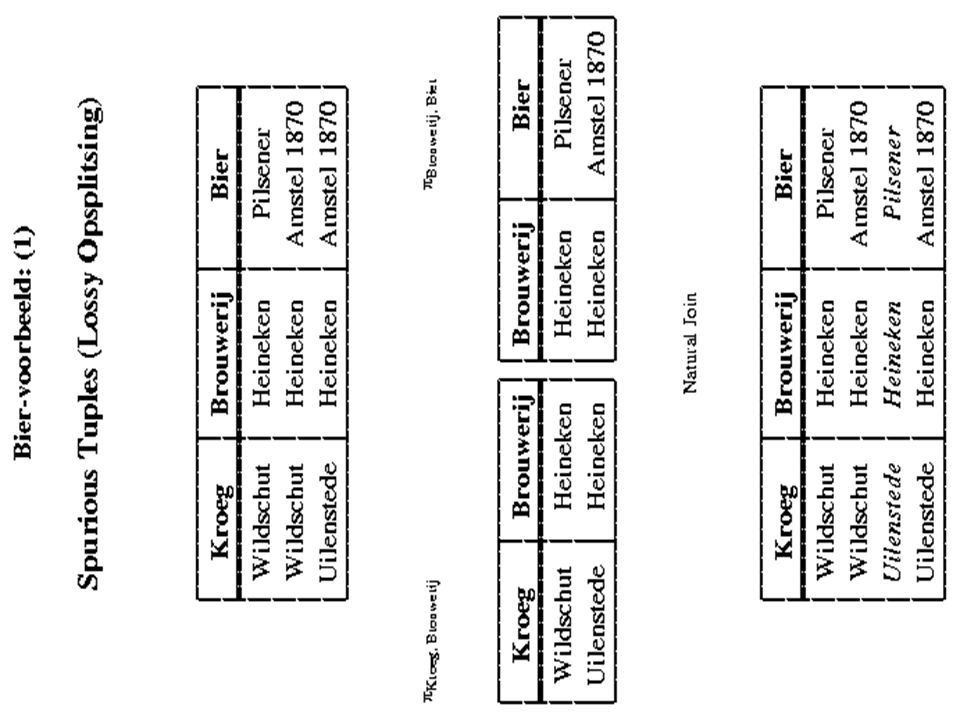
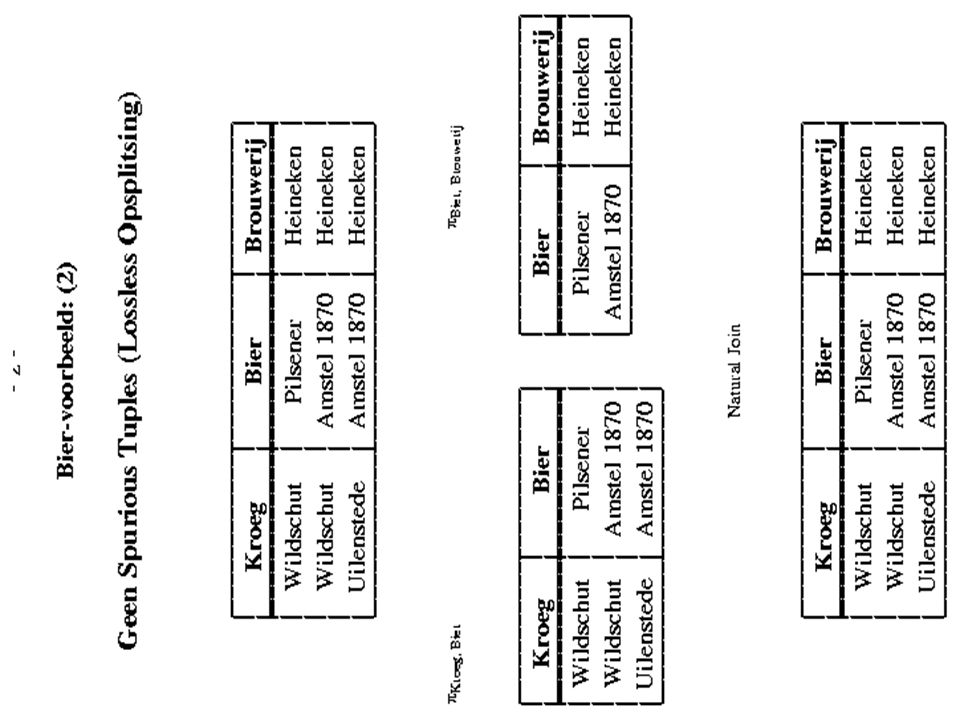
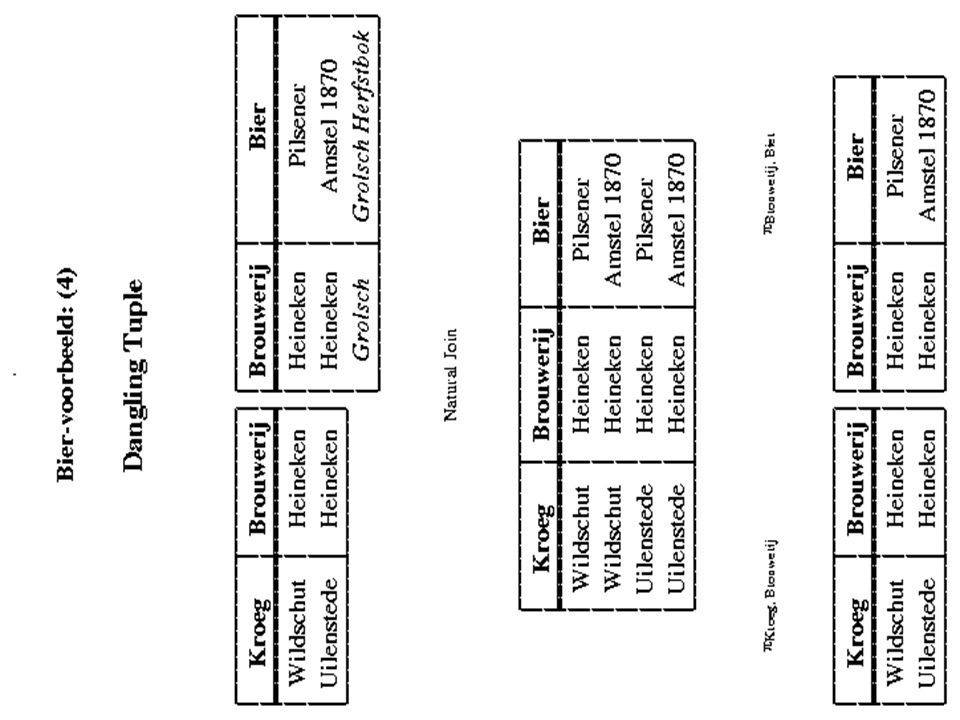
Spurious tupels en dangling tupels Spurious tupels zijn een serieus probleem: Het is niet meer mogelijk om vanuit de decompositie de oorspronkelijke relatie te reconstrueren Dangling tupels zijn geen probleem: Het betekent simpelweg dat in de decompositie informatie kan worden opgeslagen die bij het joinen verloren kan gaan. M.a.w.: de decompositie biedt je extra mogelijkheden om informatie op te slaan.

14
Lossless join eigenschap {R 1, R 2, …, R n } is een decompositie van een relationeel schema R indien: n i=1 R i = R (Dus indien alle R i ’s samen de attributen van R bevatten) Definitie van “lossless”: Zij R een relationeel schema, zij C een verzameling constraints en zij {R 1, R 2, …, R n } een decompositie van R. {R 1, R 2, …, R n } heeft de lossless join eigenschap m.b.t. C d.e.s.d.a. voor iedere extensie r van R die aan C voldoet geldt: r = R1 (r) join R2 (r) join … join Rn (r)
 join R2 (r) join … join Rn (r).")
15
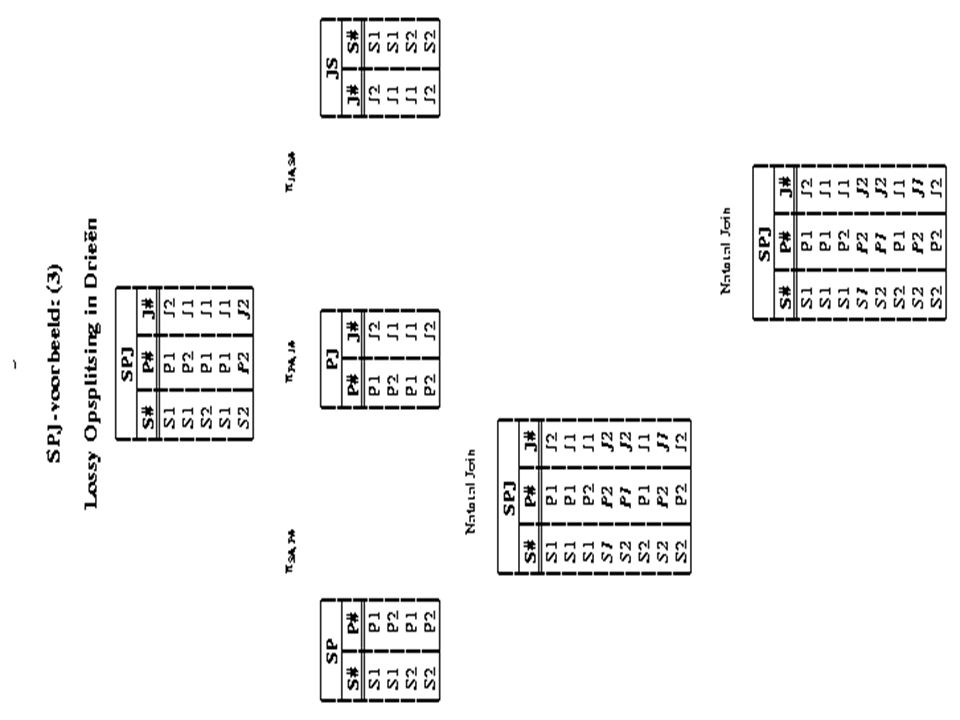
Eigenschappen “join van projecties” “join van projecties” kan soms meer tupels teruggeven, maar nooit minder als je de “join van projecties” opnieuw projecteert, krijg je hetzelfde resultaat als direct na het projecteren van de oorspronkelijke relatie meerdere keren uitvoeren van “join van projecties” levert precies hetzelfde resultaat op als één keer “join van projecties” (S 1, P 1, J 1 ) (S 2, P 1, J 2 ) (S 1, P 1 )(P 1, J 1 ) (S 2, P 1 )(P 1, J 2 ) (S 1, P 1, J 1 ) (S 2, P 1, J 2 ) (S 1, P 1, J 2 ) (S 2, P 1, J 1 )
 (S 2, P 1, J 2 ) (S 1, P 1 )(P 1, J 1 ) (S 2, P 1 )(P 1, J 2 ) (S 1, P 1, J 1 ) (S 2, P 1, J 2 ) (S 1, P 1, J 2 ) (S 2, P 1, J 1 )")
16
Controleren lossless-join (als 2 proj.) Zij D = {R 1, R 2 } een decompositie van R en zij F een verzameling FD’s. D is een lossless join decompositie m.b.t. F d.e.s.d.a. 1)(R 1 R 2 ) (R 1 - R 2 ) F +, of 2)(R 1 R 2 ) (R 2 - R 1 ) F + merk op dat: (R 1 R 2 ) (R 1 - R 2 ) F + (R 1 R 2 ) R 1 F + “ ”: augmentatie met R 1 R 2 (voeg links en rechts R 1 R 2 toe) “ ”: decompositie-regel (je laat attributen weg rechts van de “ ”) dus, D is een lossless join decompositie m.b.t. F d.e.s.d.a. 1) (R 1 R 2 ) R 1 F +, of 2) (R 1 R 2 ) R 2 F +
(R 1 R 2 ) (R 1 - R 2 ) F +, of 2)(R 1 R 2 ) (R 2 - R 1 ) F + merk op dat: (R 1 R 2 ) (R 1 - R 2 ) F + (R 1 R 2 ) R 1 F + : augmentatie met R 1 R 2 (voeg links en rechts R 1 R 2 toe) : decompositie-regel (je laat attributen weg rechts van de ) dus, D is een lossless join decompositie m.b.t. F d.e.s.d.a. 1) (R 1 R 2 ) R 1 F +, of 2) (R 1 R 2 ) R 2 F +.")
17
Voorbeeld Database DPD_EMP E#DPD_NREL EMP_NBDATED# E2Barbarawife Joe1968-04-04D1 E3Marydaughter Jack1969-09-03D1 E3Suewife Jack1969-09-03D1 E4Tomson Will1971-03-21D2 E4Marywife Will1971-03-21D2 DEPENDENT EMPLOYEE E#DPD_N REL E#EMP_N BDATE D# E2Barbara wife E2Joe 1968-04-04 D1 E3Mary daughter E3Jack 1969-09-03 D1 E3Sue wife E4Will 1971-03-21 D2 E4Tom son E4Mary wife

18
Vb. lossless-join (splitsing in 2 projecties) dus, D is een lossless join decompositie m.b.t. F d.e.s.d.a. 1) (R 1 R 2 ) R 1 F +, of 2) (R 1 R 2 ) R 2 F + DPD_EMP(E#, DPD_N, REL, EMP_N, BDATE, D#) met F = {E#, DPD_N REL, E# EMP_N, E# BDATE, E# D# } DEPENDENT(E#, DPD_N, REL) EMPLOYEE(E#, EMP_N, BDATE, D#) EMPLOYEE DEPENDENT = {E#} en E# E#, EMP_N, BDATE, D#(dus lossless)
 (R 1 R 2 ) R 1 F +, of 2) (R 1 R 2 ) R 2 F + DPD_EMP(E#, DPD_N, REL, EMP_N, BDATE, D#) met F = {E#, DPD_N REL, E# EMP_N, E# BDATE, E# D# } DEPENDENT(E#, DPD_N, REL) EMPLOYEE(E#, EMP_N, BDATE, D#) EMPLOYEE DEPENDENT = {E#} en E# E#, EMP_N, BDATE, D#(dus lossless).")
19
Vb. lossless-join (met n projecties) (1/3) DPD_EMP_DPM(E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET) met F = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D#, DPM_N BUDGET } DEPENDENT(E#, DPD_N, REL) EMPLOYEE(E#, EMP_N, BDATE, D#) DEPARTMENT(D#, DPM_N, BUDGET)
 (1/3) DPD_EMP_DPM(E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET) met F = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D#, DPM_N BUDGET } DEPENDENT(E#, DPD_N, REL) EMPLOYEE(E#, EMP_N, BDATE, D#) DEPARTMENT(D#, DPM_N, BUDGET).")
20
Vb. lossless-join (met n projecties) (2/3) DPD_EMP_DPM(E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET) met F = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D#, DPM_N BUDGET } E#DPD_NRELEMP_NBDATED#DPM_NBUDGET DEPENDENT a 1 a 2 a 3 b 14 b 15 b 16 b 17 b 18 EMPLOYEE a 1 b 22 b 23 a 4 a 5 a 6 b 27 b 28 DEPARTMENT b 31 b 32 b 33 b 34 b 35 a 6 a 7 a 8
 (2/3) DPD_EMP_DPM(E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET) met F = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D#, DPM_N BUDGET } E#DPD_NRELEMP_NBDATED#DPM_NBUDGET DEPENDENT a 1 a 2 a 3 b 14 b 15 b 16 b 17 b 18 EMPLOYEE a 1 b 22 b 23 a 4 a 5 a 6 b 27 b 28 DEPARTMENT b 31 b 32 b 33 b 34 b 35 a 6 a 7 a 8.")
21
Vb. lossless-join (met n projecties) (3/3) DPD_EMP_DPM(E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET) met F = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D#, DPM_N BUDGET } E#DPD_NRELEMP_NBDATED#DPM_NBUDGET DEPENDENT a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 EMPLOYEE a 1 b 22 b 23 a 4 a 5 a 6 a 7 a 8 DEPARTMENT b 31 b 32 b 33 b 34 b 35 a 6 a 7 a 8
 (3/3) DPD_EMP_DPM(E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET) met F = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D#, DPM_N BUDGET } E#DPD_NRELEMP_NBDATED#DPM_NBUDGET DEPENDENT a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 EMPLOYEE a 1 b 22 b 23 a 4 a 5 a 6 a 7 a 8 DEPARTMENT b 31 b 32 b 33 b 34 b 35 a 6 a 7 a 8.")
22
Algoritme lossless-join Heeft een decompositie R 1, …, R k van R de lossless-join eigenschap m.b.t. een verzameling FD’s F? maak een tabel met k rijen (voor iedere R 1, …, R k een rij) en n kolommen (voor ieder attribuut A 1, …, A n een kolom) zet in rij i en kolom j het symbool a j (als A j R i ) of het symbool b ij (als A j R i ). doe dit voor iedere i en j. “verwerk” nu telkens opnieuw alle FD’s X Y F totdat –ofwel één van de rijen gelijk is geworden aan a 1, …, a n –ofwel de tabel niet meer gewijzigd kan worden “verwerken” van een FD X Y: telkens als een aantal rijen ‘dezelfde waarden voor X’ hebben, geef ze dan ook ‘dezelfde waarden voor Y’ (en kies hiervoor indien mogelijk een a j ) let op: telkens als je een symbool wijzigt, moet je alle instanties van dat symbool wijzigen (ook in alle andere rijen). decompositie is lossless er is uiteindelijk een rij gelijk aan a 1 …a n
 en n kolommen (voor ieder attribuut A 1, …, A n een kolom) zet in rij i en kolom j het symbool a j (als A j R i ) of het symbool b ij (als A j R i ). doe dit voor iedere i en j. verwerk nu telkens opnieuw alle FD’s X Y F totdat –ofwel één van de rijen gelijk is geworden aan a 1, …, a n –ofwel de tabel niet meer gewijzigd kan worden verwerken van een FD X Y: telkens als een aantal rijen ‘dezelfde waarden voor X’ hebben, geef ze dan ook ‘dezelfde waarden voor Y’ (en kies hiervoor indien mogelijk een a j ) let op: telkens als je een symbool wijzigt, moet je alle instanties van dat symbool wijzigen (ook in alle andere rijen). decompositie is lossless er is uiteindelijk een rij gelijk aan a 1 …a n.")
23
Voorbeeld lossless join algoritme(1/4) R = {A,B,C,D,E} = ABCDE R 1 =AD R 2 =AB R 3 =BE R 4 =CDE R 5 =AE F = {A C, B C, C D, DE C, CE A} ABCDE R 1 a 1 b 12 b 13 a 4 b 15 R 2 a 1 a 2 b 23 b 24 b 25 R 3 b 31 a 2 b 33 b 34 a 5 R 4 b 41 b 42 a 3 a 4 a 5 R 5 a 1 b 52 b 53 b 54 a 5
 R = {A,B,C,D,E} = ABCDE R 1 =AD R 2 =AB R 3 =BE R 4 =CDE R 5 =AE F = {A C, B C, C D, DE C, CE A} ABCDE R 1 a 1 b 12 b 13 a 4 b 15 R 2 a 1 a 2 b 23 b 24 b 25 R 3 b 31 a 2 b 33 b 34 a 5 R 4 b 41 b 42 a 3 a 4 a 5 R 5 a 1 b 52 b 53 b 54 a 5")
24
Voorbeeld lossless join algoritme(2/4) R 1 =AD R 2 =AB R 3 =BE R 4 =CDE R 5 =AE F = {A C, B C, C D, DE C, CE A} tussenresultaat na het verwerken van de eerste drie FD’s: ABCDE R 1 a 1 b 12 b 13 a 4 b 15 R 2 a 1 a 2 b 13 a 4 b 25 R 3 b 31 a 2 b 13 a 4 a 5 R 4 b 41 b 42 a 3 a 4 a 5 R 5 a 1 b 52 b 13 a 4 a 5
 R 1 =AD R 2 =AB R 3 =BE R 4 =CDE R 5 =AE F = {A C, B C, C D, DE C, CE A} tussenresultaat na het verwerken van de eerste drie FD’s: ABCDE R 1 a 1 b 12 b 13 a 4 b 15 R 2 a 1 a 2 b 13 a 4 b 25 R 3 b 31 a 2 b 13 a 4 a 5 R 4 b 41 b 42 a 3 a 4 a 5 R 5 a 1 b 52 b 13 a 4 a 5")
25
Voorbeeld lossless join algoritme(3/4) R 1 =AD R 2 =AB R 3 =BE R 4 =CDE R 5 =AE F = {A C, B C, C D, DE C, CE A} eindresultaat : ABCDE R 1 a 1 b 12 a 3 a 4 b 15 R 2 a 1 a 2 a 3 a 4 b 25 R 3 a 1 a 2 a 3 a 4 a 5 R 4 a 1 b 42 a 3 a 4 a 5 R 5 a 1 b 52 a 3 a 4 a 5
 R 1 =AD R 2 =AB R 3 =BE R 4 =CDE R 5 =AE F = {A C, B C, C D, DE C, CE A} eindresultaat : ABCDE R 1 a 1 b 12 a 3 a 4 b 15 R 2 a 1 a 2 a 3 a 4 b 25 R 3 a 1 a 2 a 3 a 4 a 5 R 4 a 1 b 42 a 3 a 4 a 5 R 5 a 1 b 52 a 3 a 4 a 5")
26
Voorbeeld lossless join algoritme(4/4) opmerking We hebben de FD’s “toevallig” in een gunstige volgorde verwerkt zodat we na één ronde al klaar zijn. In het algemeen moet de gehele verzameling van FD’s meerdere malen doorlopen worden. (net zolang totdat er een rij a’s uitkomt, of er niets meer in de tabel veranderd kan worden)
.")
27
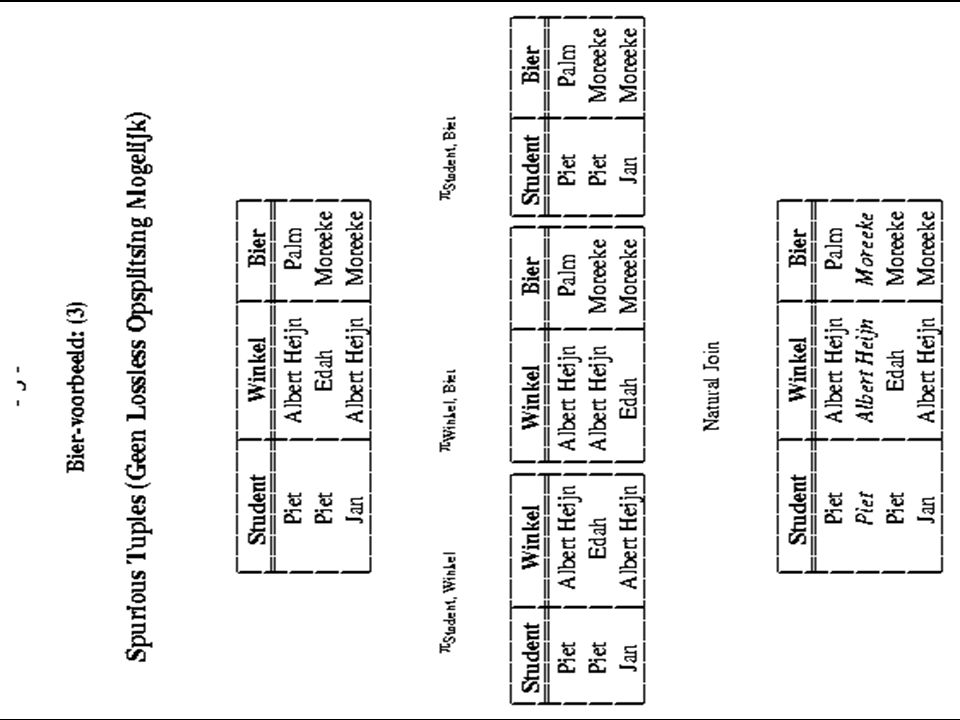
Vb. 1: Dependency Preserving ? (1/3) R = {Stad, Straat, Huisnr, Postcode, Vraagprijs} F = { {Stad, Straat, Huisnr} Postcode, {Stad, Straat, Huisnr} Vraagprijs, {Postcode, Huisnr} Vraagprijs, Postcode Stad, Postcode Straat} StadStraatHuisnrPostcodeVraagprijs AmsterdamWesterstr311015 MK500 000 Den HaagLaan2372512 DT400 000 Den HaagHoefkade302526 CA150 000 AppingedamBroerstr89901 EK200 000 AppingedamBroerstr129901 EK225 000 Keys: { {Stad, Straat, Huisnr}, {Postcode, Huisnr} }
 R = {Stad, Straat, Huisnr, Postcode, Vraagprijs} F = { {Stad, Straat, Huisnr} Postcode, {Stad, Straat, Huisnr} Vraagprijs, {Postcode, Huisnr} Vraagprijs, Postcode Stad, Postcode Straat} StadStraatHuisnrPostcodeVraagprijs AmsterdamWesterstr MK Den HaagLaan DT Den HaagHoefkade CA AppingedamBroerstr89901 EK AppingedamBroerstr EK Keys: { {Stad, Straat, Huisnr}, {Postcode, Huisnr} }.")
28
Vb. 1: Dependency Preserving ? (2/3) R = {Stad, Straat, Huisnr, Postcode, Vraagprijs} F = { {Stad, Straat, Huisnr} Postcode, {Stad, Straat, Huisnr} Vraagprijs, {Postcode, Huisnr} Vraagprijs, Postcode Stad, Postcode Straat} R 1 R 2 PostcodeHuisnrVraagprijsPostcodeStadStraat 1015 MK31500 0001015 MKAmsterdamWesterstr 1212 DT237400 0001212 DTDen HaagLaan 2526 CA30150 0002526 CADen HaagHoefkade 9901 EK8200 0009901 EKAppingedamBroerstaat 9901 EK12225 000
 R = {Stad, Straat, Huisnr, Postcode, Vraagprijs} F = { {Stad, Straat, Huisnr} Postcode, {Stad, Straat, Huisnr} Vraagprijs, {Postcode, Huisnr} Vraagprijs, Postcode Stad, Postcode Straat} R 1 R 2 PostcodeHuisnrVraagprijsPostcodeStadStraat 1015 MK MKAmsterdamWesterstr 1212 DT DTDen HaagLaan 2526 CA CADen HaagHoefkade 9901 EK EKAppingedamBroerstaat 9901 EK")
29
Vb. 1: Dependency Preserving ? (3/3) R = {Stad, Straat, Huisnr, Postcode, Vraagprijs} F = { {Stad, Straat, Huisnr} Postcode, {Stad, Straat, Huisnr} Vraagprijs, {Postcode, Huisnr} Vraagprijs, Postcode Stad, Postcode Straat} R 1 = {Postcode, Huisnr, Vraagprijs} R 2 = {Postcode, Stad, Straat} er geldt: R 1 R 2 = Postcode en Postcode {Stad, Straat} F + dus de decompositie heeft de lossless-join eigenschap echter, de volgende FD’s zijn beide “tussen wal en schip gevallen”: {Stad, Straat, Huisnr} Postcode {Stad, Straat, Huisnr} Vraagprijs (dus join nodig om ze te checken, want niet afleidbaar uit rest; zie vb.2)
 R = {Stad, Straat, Huisnr, Postcode, Vraagprijs} F = { {Stad, Straat, Huisnr} Postcode, {Stad, Straat, Huisnr} Vraagprijs, {Postcode, Huisnr} Vraagprijs, Postcode Stad, Postcode Straat} R 1 = {Postcode, Huisnr, Vraagprijs} R 2 = {Postcode, Stad, Straat} er geldt: R 1 R 2 = Postcode en Postcode {Stad, Straat} F + dus de decompositie heeft de lossless-join eigenschap echter, de volgende FD’s zijn beide tussen wal en schip gevallen : {Stad, Straat, Huisnr} Postcode {Stad, Straat, Huisnr} Vraagprijs (dus join nodig om ze te checken, want niet afleidbaar uit rest; zie vb.2).")
30
Vb. 2: Dependency Preserving ? R = {A, B, C} = ABC (keys: {A} = A) F = {A B, (r_sleutel) A C, (r_sleutel) B C} (r_transitief) R 1 = AB (= {A, B}) R 2 = BC (= {B, C}) er geldt: R 1 R 2 = B en B BC F + (dus lossless-join eigenschap) de FD A C lijkt “tussen wal en schip te vallen”, doch: A C volgt uit A B en B C A B kan efficiënt in R 1 gecontroleerd worden B C kan efficiënt in R 2 gecontroleerd worden Dus: als eenmaal A B en B C gecontroleerd zijn (en OK bevonden) dan is automatisch ook A C gecontroleerd/OK.
 F = {A B, (r_sleutel) A C, (r_sleutel) B C} (r_transitief) R 1 = AB (= {A, B}) R 2 = BC (= {B, C}) er geldt: R 1 R 2 = B en B BC F + (dus lossless-join eigenschap) de FD A C lijkt tussen wal en schip te vallen , doch: A C volgt uit A B en B C A B kan efficiënt in R 1 gecontroleerd worden B C kan efficiënt in R 2 gecontroleerd worden Dus: als eenmaal A B en B C gecontroleerd zijn (en OK bevonden) dan is automatisch ook A C gecontroleerd/OK..")
31
Dependency Preserving Z (F) = { X Y F + | XY Z} (projectie van F op een verzameling attributen Z) let op: Z (F) = Z (F + ) een decompositie {R 1, R 2, … R k } is dependency preserving d.e.s.d.a. F ( k i=1 Ri (F) ) + ( Eigenlijk:d.e.s.d.a. F + = ( k i=1 Ri (F) ) + Echter:F + = G + F G + èn G F + en de tweede eis G F +, oftewel: ( k i=1 Ri (F)) F +, volgt in dit geval uit de definitie van projectie. )
 ) + ( Eigenlijk:d.e.s.d.a. F + = ( k i=1 Ri (F) ) + Echter:F + = G + F G + èn G F + en de tweede eis G F +, oftewel: ( k i=1 Ri (F)) F +, volgt in dit geval uit de definitie van projectie. ).")
32
Vb. bij definitie Dependency Preserving (1/3) F = {A B, A C, B C} R 1 = {A,B} = AB R 2 = {B,C} = BC als deze decompositie is dependency preserving is, dan zou moeten gelden: F ( R1 (F) R2 (F) ) + dus er zou moeten gelden: F ( R1 (F + ) R2 (F + ) ) + eerst maar eens F + uitrekenen...
 F = {A B, A C, B C} R 1 = {A,B} = AB R 2 = {B,C} = BC als deze decompositie is dependency preserving is, dan zou moeten gelden: F ( R1 (F) R2 (F) ) + dus er zou moeten gelden: F ( R1 (F + ) R2 (F + ) ) + eerst maar eens F + uitrekenen....")
33
Vb. bij definitie Dependency Preserving (2/3) F + = {A A, AB A,AC A,ABC A A B,B B, AB B,BC B,AC B,ABC B A C,B C,C C, AB C,BC C,AC C,ABC C A AB, AB AB,AC AB,ABC AB A BC,B BC, AB BC,BC BC,AC BC,ABC BC A AC, AB AC,AC AC,ABC AC A ABC, AB ABC, AC ABC,ABC ABC}
 F + = {A A, AB A,AC A,ABC A A B,B B, AB B,BC B,AC B,ABC B A C,B C,C C, AB C,BC C,AC C,ABC C A AB, AB AB,AC AB,ABC AB A BC,B BC, AB BC,BC BC,AC BC,ABC BC A AC, AB AC,AC AC,ABC AC A ABC, AB ABC, AC ABC,ABC ABC}.")
34
Vb. bij definitie Dependency Preserving (3/3) F = {A B, A C, B C} R 1 = {A,B} = AB R 2 = {B,C} = BC als deze decompositie is dependency preserving is, dan zou moeten gelden: F ( R1 (F) R2 (F) ) + R1 (F) = {A A, A B, A AB, B B, AB A, AB B, AB AB} R2 (F) = {B B, B C, B BC, C C, BC B, BC C, BC BC} dus er zou moeten gelden –A B ( R1 (F) R2 (F) ) + (klopt, want A B R1 (F) ) –B C ( R1 (F) R2 (F) ) + (klopt, want B C R2 (F) ) –A C ( R1 (F) R2 (F) ) + (klopt, want uit A B R1 (F) en B C R2 (F) volgt A C ( R1 (F) R2 (F) ) + ) dus: deze decompositie is dependency preserving
 F = {A B, A C, B C} R 1 = {A,B} = AB R 2 = {B,C} = BC als deze decompositie is dependency preserving is, dan zou moeten gelden: F ( R1 (F) R2 (F) ) + R1 (F) = {A A, A B, A AB, B B, AB A, AB B, AB AB} R2 (F) = {B B, B C, B BC, C C, BC B, BC C, BC BC} dus er zou moeten gelden –A B ( R1 (F) R2 (F) ) + (klopt, want A B R1 (F) ) –B C ( R1 (F) R2 (F) ) + (klopt, want B C R2 (F) ) –A C ( R1 (F) R2 (F) ) + (klopt, want uit A B R1 (F) en B C R2 (F) volgt A C ( R1 (F) R2 (F) ) + ) dus: deze decompositie is dependency preserving.")
35
Nog een vb. bij def Dependency Preserving F = {{Stad, Straat, Huisnr} Postcode, {Stad, Straat, Huisnr} Vraagprijs, {Postcode, Huisnr} Vraagprijs, Postcode Stad, Postcode Straat} R 1 = {Postcode, Huisnr, Vraagprijs} R 2 = {Postcode, Stad, Straat} als deze decompositie is dependency preserving is, dan zou moeten gelden: F ( R1 (F) R2 (F) ) + echter, er geldt o.a.: {Stad, Straat, Huisnr} Vraagprijs ( R1 (F) R2 (F) ) + dus: deze decompositie is niet dependency preserving
 R2 (F) ) + echter, er geldt o.a.: {Stad, Straat, Huisnr} Vraagprijs ( R1 (F) R2 (F) ) + dus: deze decompositie is niet dependency preserving.")
36
Normaalvormen een database-ontwerp (db-schema) R 1, R 2, …, R n is in ?NF t.o.v. een verzameling FD’s F d.e.s.d.a. iedere relatie R i in ?NF is t.o.v. Ri (F)
.")
37
Gewenste eigenschappen database-ontwerp hoge normaalvorm, want anders potentiële redundantie; lossless-join eigenschap, want anders verlies van info; dependency preserving, want anders heeft DBMS veel werk, i.e. joins nodig, om de opgelegde constraints (zoals FD’s) af te dwingen. helaas… BCNF + dependency preserving + lossless: soms onmogelijk BCNF + dependency preserving: soms onmogelijk BCNF + lossless: altijd mogelijk 3NF + dependency preserving + lossless: altijd mogelijk
 af te dwingen. helaas… BCNF + dependency preserving + lossless: soms onmogelijk BCNF + dependency preserving: soms onmogelijk BCNF + lossless: altijd mogelijk 3NF + dependency preserving + lossless: altijd mogelijk.")
38
Tussenstand We weten nu hoe we in een relatie-schema en/of db-schema potentiële redundantie kunnen herkennen (normaalvorm bepalen) Van een decompositie kunnen we nu beoordelen: –hoe goed in de decompositie redundantie wordt voorkomen (via normaalvorm bepalen) –of de decompositie dezelfde informatie kan bevatten als de oorspronkelijke tabel (via “lossless join” algoritme) –of de FD’s ( { “gewenste constraints”} ) in de decompositie op een efficiënte manier kunnen worden gecontroleerd (via “dependency preserving” algoritme; wordt niet behandeld) Hoe vind je een decompositie die hieraan voldoet? (zonder alle mogelijke decomposities te testen)
.")
39
Twee decompositie-algoritmes 3NF decompositie algoritme (lossless + dependency preserving) BCNF decompositie algoritme (lossless, doch niet noodzakelijk dependency preserving) In dit college gaan we uitsluitend het 3NF algoritme behandelen! (BCNF algoritme valt dit jaar buiten de tentamenstof, o.a. i.v.m. complexiteit van projecteren van F + en van testen “dependency preserving” eigenschap)
.")
40
3NF decompositie algoritme (lossless + d.p.) Gegeven een relatie-schema R en een verzameling FD’s F: 1)Bepaal een minimal cover van F en noem die m.c. G. 2)Als er een FD in G is die alle attributen bevat (dus: een X A met X {A} = R) dan is R al in 3NF. Zo niet, splits dan R op in alle relatie-schema’s X i A i die corresponderen met een afhankelijkheid X i A i in G 3)Telkens als X i = X j mogen we de twee bijbehorende schema’s (X i A i en X j A j ) samenvoegen tot X i A i A j. 4)Om de lossless-join eigenschap te verzekeren voegen we één relatie-schema X toe, waarbij X een sleutel moet zijn van R. 5)Verwijder eventueel een aantal overbodige schema’s (± schema’s die bevat zijn in een ander schema).
Als er een FD in G is die alle attributen bevat (dus: een X A met X {A} = R) dan is R al in 3NF. Zo niet, splits dan R op in alle relatie-schema’s X i A i die corresponderen met een afhankelijkheid X i A i in G 3)Telkens als X i = X j mogen we de twee bijbehorende schema’s (X i A i en X j A j ) samenvoegen tot X i A i A j. 4)Om de lossless-join eigenschap te verzekeren voegen we één relatie-schema X toe, waarbij X een sleutel moet zijn van R. 5)Verwijder eventueel een aantal overbodige schema’s (± schema’s die bevat zijn in een ander schema)..")
41
Voorbeeld 3NF decompositie algoritme (1/5) DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} met F = {{E#, DPD_N} REL, E# {EMP_N, BDATE, D#}, D# {BUDGET, DPM_N}, DPM_N {D#, BUDGET} } Stap 1: Bepaal een minimal cover G = {{E#, DPD_N} REL, D# DPM_N, E# EMP_N, D# BUDGET, E# BDATE, DPM_N D#, E# D# }
 DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} met F = {{E#, DPD_N} REL, E# {EMP_N, BDATE, D#}, D# {BUDGET, DPM_N}, DPM_N {D#, BUDGET} } Stap 1: Bepaal een minimal cover G = {{E#, DPD_N} REL, D# DPM_N, E# EMP_N, D# BUDGET, E# BDATE, DPM_N D#, E# D# }")
42
Voorbeeld 3NF decompositie algoritme (2/5) DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} G = { {E#, DPD_N} REL, D# DPM_N, E# EMP_N, D# BUDGET, E# BDATE, DPM_N D#, E# D#, } Stap 2: Splitsen in losse relatieschema’s (voor iedere FD in G een relatieschema) {E#, DPD_N, REL},{D#, DPM_N}, {E#, EMP_N},{D#, BUDGET}, {E#, BDATE},{DPM_N, D#}, {E#, D#}
 DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} G = { {E#, DPD_N} REL, D# DPM_N, E# EMP_N, D# BUDGET, E# BDATE, DPM_N D#, E# D#, } Stap 2: Splitsen in losse relatieschema’s (voor iedere FD in G een relatieschema) {E#, DPD_N, REL},{D#, DPM_N}, {E#, EMP_N},{D#, BUDGET}, {E#, BDATE},{DPM_N, D#}, {E#, D#}")
43
Voorbeeld 3NF decompositie algoritme (3/5) DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} {E#, DPD_N, REL},{D#, DPM_N}, {E#, EMP_N},{D#, BUDGET}, {E#, BDATE},{DPM_N, D#}, {E#, D#} Stap 3: Samenvoegen van schema’s {E#, DPD_N, REL}, {E#, EMP_N, BDATE, D#}, {D#, DPM_N, BUDGET}, {DPM_N, D#}
 DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} {E#, DPD_N, REL},{D#, DPM_N}, {E#, EMP_N},{D#, BUDGET}, {E#, BDATE},{DPM_N, D#}, {E#, D#} Stap 3: Samenvoegen van schema’s {E#, DPD_N, REL}, {E#, EMP_N, BDATE, D#}, {D#, DPM_N, BUDGET}, {DPM_N, D#}")
44
Voorbeeld 3NF decompositie algoritme (4/5) DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} G = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D# } Stap 4: Relatie-schema voor een sleutel toevoegen {E#, DPD_N, REL} {E#, EMP_N, BDATE, D#} {D#, DPM_N, BUDGET} {DPM_N, D#} {E#, DPD_N}
 DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} G = {E#, DPD_N REL,D# DPM_N, E# EMP_N,D# BUDGET, E# BDATE,DPM_N D#, E# D# } Stap 4: Relatie-schema voor een sleutel toevoegen {E#, DPD_N, REL} {E#, EMP_N, BDATE, D#} {D#, DPM_N, BUDGET} {DPM_N, D#} {E#, DPD_N}")
45
Voorbeeld 3NF decompositie algoritme (5/5) DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} {E#, DPD_N, REL}, {E#, EMP_N, BDATE, D#}, {D#, DPM_N, BUDGET}, {DPM_N, D#}, {E#, DPD_N} Stap 5: Verwijderen overbodige relatie-schema’s (± schema’s die in een ander relatie-schema bevat zijn) {E#, DPD_N, REL}(=dependent) {E#, EMP_N, BDATE, D#}(=employee) {D#, DPM_N, BUDGET}(=department)
 DPD_EMP_DPM = {E#, DPD_N, REL, EMP_N, BDATE, D#, DPM_N, BUDGET} {E#, DPD_N, REL}, {E#, EMP_N, BDATE, D#}, {D#, DPM_N, BUDGET}, {DPM_N, D#}, {E#, DPD_N} Stap 5: Verwijderen overbodige relatie-schema’s (± schema’s die in een ander relatie-schema bevat zijn) {E#, DPD_N, REL}(=dependent) {E#, EMP_N, BDATE, D#}(=employee) {D#, DPM_N, BUDGET}(=department)")
47
Hogere normaalvormen: 4NF(1/3) voorbeeld: dating-bureau houdt van iedere zoekende de volgende informatie bij: naam, hobby’s, huisdieren –personen kunnen meerdere hobby's en huisdieren hebben –er is geen verband tussen hobby’s en huisdieren ZOEKENDE_HOBBY ZOEKENDE_HUISDIER NAAMHOBBY NAAMHUISDIER Truusbridgen Truuskat Truuspuzzelen Truusgoudvis Teunsjoelen TeunHond TeunKanarie
 voorbeeld: dating-bureau houdt van iedere zoekende de volgende informatie bij: naam, hobby’s, huisdieren –personen kunnen meerdere hobby s en huisdieren hebben –er is geen verband tussen hobby’s en huisdieren ZOEKENDE_HOBBY ZOEKENDE_HUISDIER NAAMHOBBY NAAMHUISDIER Truusbridgen Truuskat Truuspuzzelen Truusgoudvis Teunsjoelen TeunHond TeunKanarie")
48
Hogere normaalvormen: 4NF(2/3) Stel, je stopt al deze informatie in slechts één tabel. Kun je dan d.m.v. FD’s vooraf detecteren dat je hiermee redundantie kunt introduceren? (antwoord: nee, want F = ) ZOEKENDE NAAMHOBBYHUISDIER Truusbridgenkat Truusbridgengoudvis Truuspuzzelenkat Truuspuzzelengoudvis Teunsjoelenhond Teunsjoelenkanarie
 ZOEKENDE NAAMHOBBYHUISDIER Truusbridgenkat Truusbridgengoudvis Truuspuzzelenkat Truuspuzzelengoudvis Teunsjoelenhond Teunsjoelenkanarie.")
49
Hogere normaalvormen: 4NF(3/3) ZOEKENDE NAAMHOBBYHUISDIER Truusbridgenkat Truusbridgengoudvis Truuspuzzelenkat Truuspuzzelengoudvis Teunsjoelenhond Teunsjoelenkanarie Multi-valued dependencies (MVD’s): 1)naam --->> hobby 2)naam --->> huisdier 4NF: gebaseerd op MVD’s (ZOEKENDE wel in BCNF, doch niet in 4NF)
 ZOEKENDE NAAMHOBBYHUISDIER Truusbridgenkat Truusbridgengoudvis Truuspuzzelenkat Truuspuzzelengoudvis Teunsjoelenhond Teunsjoelenkanarie Multi-valued dependencies (MVD’s): 1)naam --->> hobby 2)naam --->> huisdier 4NF: gebaseerd op MVD’s (ZOEKENDE wel in BCNF, doch niet in 4NF)")
50
Hogere normaalvormen: 5NF (=PJNF) Join Dependency (JD): een constraint die inhoudt dat de relatie is gelijk aan de join van een aantal projecties (voor iedere extensie) N.B.: {FD’s} {MVD’s} {JD’s} 5NF (=PJNF): gebaseerd op èchte join dependencies voorbeeld join dependency (SPJ voorbeeld): “Als een supplier iets levert aan een bepaald project, dan levert hij aan dat project ook alles wat hij kan leveren en wat bij dat project gebruikt wordt.” Als deze join dependency geldt in het SPJ-voorbeeld dan is SPJ niet in 5NF. De decompositie {SP, PJ, JS} is dan wel in 5NF èn lossless.

51
Enkele nuttige stellingen Als een relatie-schema in 3NF is en als elke sleutel bestaat uit slechts één attribuut (geen samengestelde sleutels), dan is het relatie-schema ook in 5NF Als een relatie-schema in BCNF is en als er tenminste één sleutel is bestaande uit een enkel attribuut, dan is het relatie-schema ook in 4NF Elke relatie met twee attributen is in BCNF
, dan is het relatie-schema ook in 5NF Als een relatie-schema in BCNF is en als er tenminste één sleutel is bestaande uit een enkel attribuut, dan is het relatie-schema ook in 4NF Elke relatie met twee attributen is in BCNF")
52
Bewijs laatste stelling Stelling:Elke relatie R met twee attributen is in BCNF (BCNF: iedere relevante FD is een r_sleutelafh) Bewijs: Neem een minimal cover G van R Er zijn 4 mogelijkheden voor G: 1)G = dan is inderdaad iedere relevante FD een r_sleutelafh (triviaal) 2)G = {A B} dan is A een key, dus A B een r_sleutelafh 3)G = {B A} dan is B een key, dus B A een r_sleutelafh 4)G = {A B, B A} dan zijn A en B key’s en zijn A B en B A r_sleutelafh
 Bewijs: Neem een minimal cover G van R Er zijn 4 mogelijkheden voor G: 1)G = dan is inderdaad iedere relevante FD een r_sleutelafh (triviaal) 2)G = {A B} dan is A een key, dus A B een r_sleutelafh 3)G = {B A} dan is B een key, dus B A een r_sleutelafh 4)G = {A B, B A} dan zijn A en B key’s en zijn A B en B A r_sleutelafh")
53
Laatste opmerking normaliseren Met de in dit college behandelde theorie is men in staat om gegeven een schema potentiële redundantie te herkennen en te vermijden (tot op zekere hoogte). Het is echter aan de Database-ontwerper om te beslissen of normalisering ook echt wenselijk is. (denk hierbij b.v. aan zaken als performance van leesoperaties)
.")
54
Thuis nalezen: 15.1 + aanvullingen H15 + opmerkingen H15 voorbereiden: H16 + H17 (minus 17.3)
")











>")



 SQL – een begin.>")

 Quiz Night !>")
 Normaliseren Wiebren de Jonge Vrije Universiteit, Amsterdam voorlopige versie 2003 sheets 1-54 stabiel !?>")





