Download de presentatie
1
Beschrijvende en inferentiële statistiek
College 11 – Anouk den Hamer – Vervolg regressie

2
Responsiecollege Volgende week dinsdag 19 maart
Vragen indienen op forum BB vóór vrijdag 15 maart uur

3
NB formuleblad Formule conditionele standaarddeviatie:
Wordt op formuleblad “residu standaard deviatie y” genoemd

7
Vandaag Uitwerking huiswerkopdracht Vervolg regressie

8
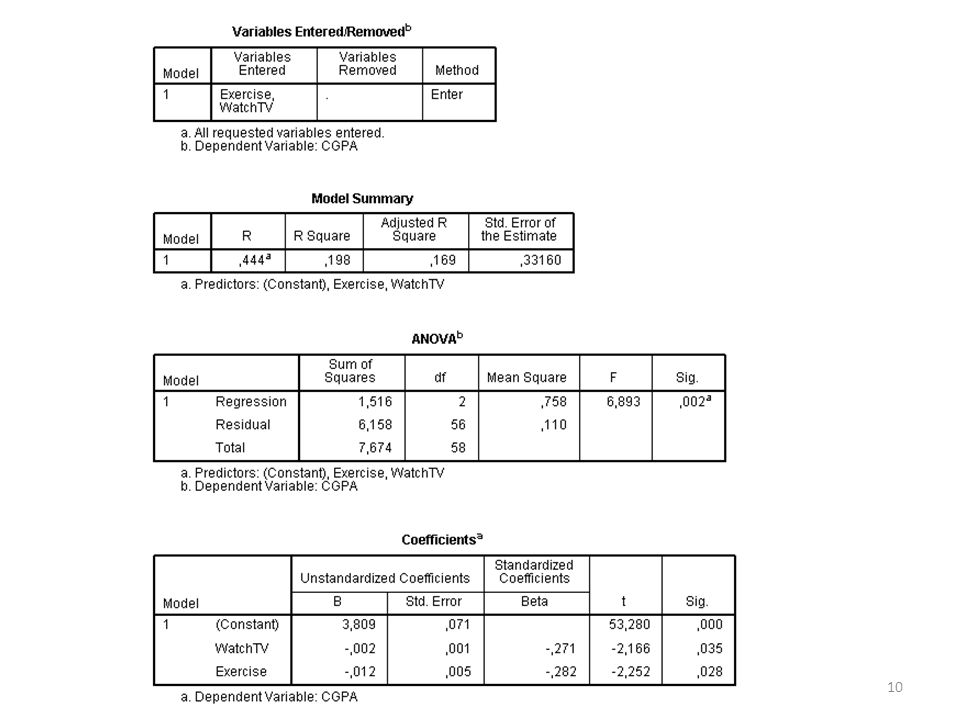
Oefening multipele regressie
In de huiswerkopdracht van college 9 hebben jullie onderzocht of tv kijken invloed heeft op tentamencijfer. Onderzoek of naast tv kijken sporten (in dataset exercising) en aantal uren studeren (studytime) ook invloed heeft (je hebt dus 3 onafhankelijke variabelen en 1 afhankelijke). Voer de regressie uit en trek je conclusie.
 en aantal uren studeren (studytime) ook invloed heeft (je hebt dus 3 onafhankelijke variabelen en 1 afhankelijke). Voer de regressie uit en trek je conclusie.")
9
Eerst correlatie

11
We weten nu dat hoe meer een student tv kijkt en hoe meer hij/zij sport, hoe lager zijn/haar tentamencijfer (p < .05). Het aantal uren studeren bleek geen significante invloed op tentamencijfer te hebben. Tv kijken en sporten verklaart 19.8% van het tentamencijfer.

12
Tot nu toe Enkelvoudige regressie: 1 X en 1 Y
Meervoudige regressie: > 1 X-en en 1 Y Y voorspellen dmv X (regressieformule) Residuals Correlatie sterkte verband R-square verklaarde variantie Y door X Wijken slopes significant af van 0?
 Residuals. Correlatie sterkte verband. R-square verklaarde variantie Y door X. Wijken slopes significant af van 0")
13
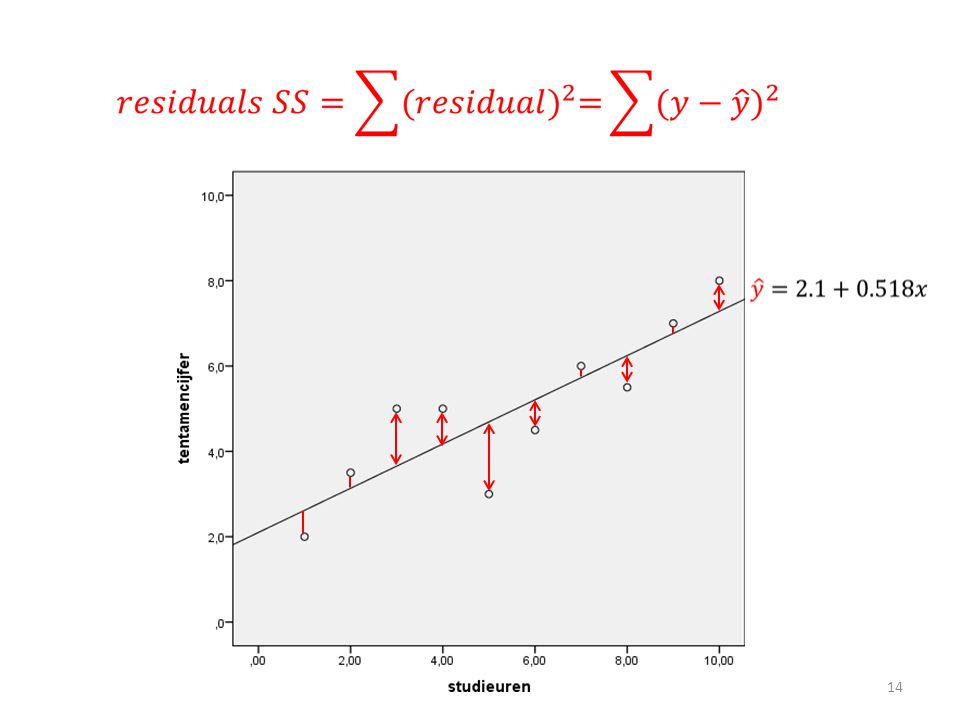
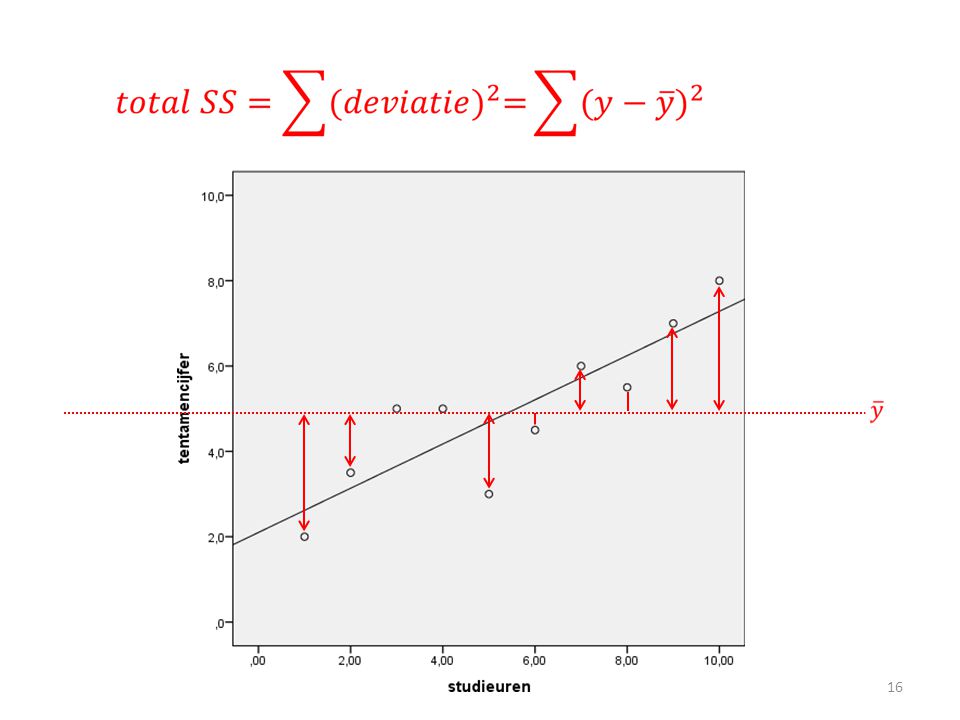
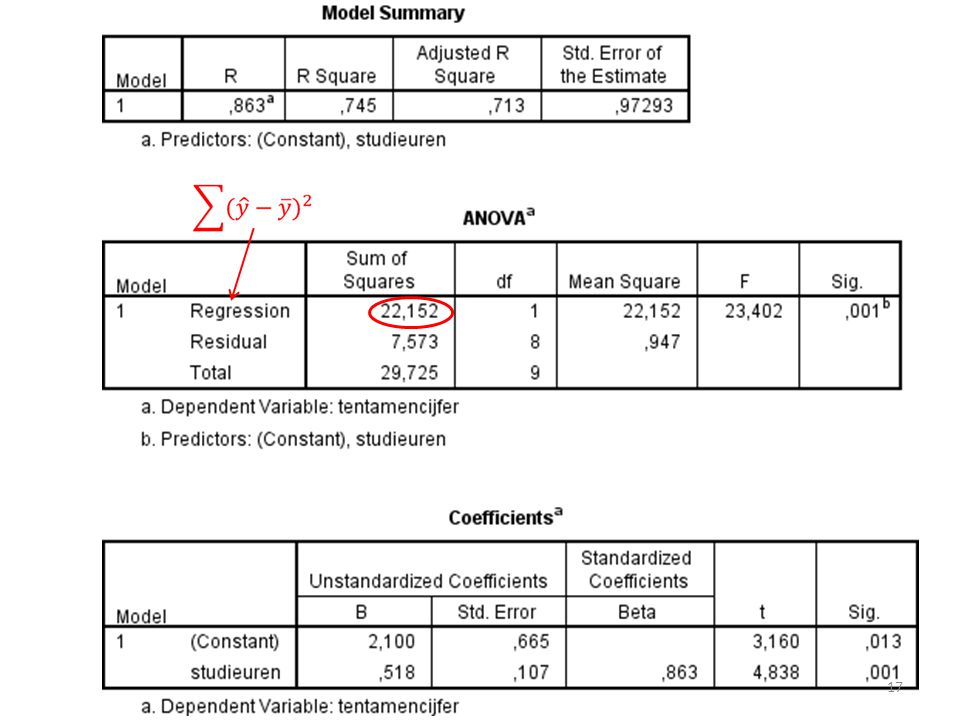
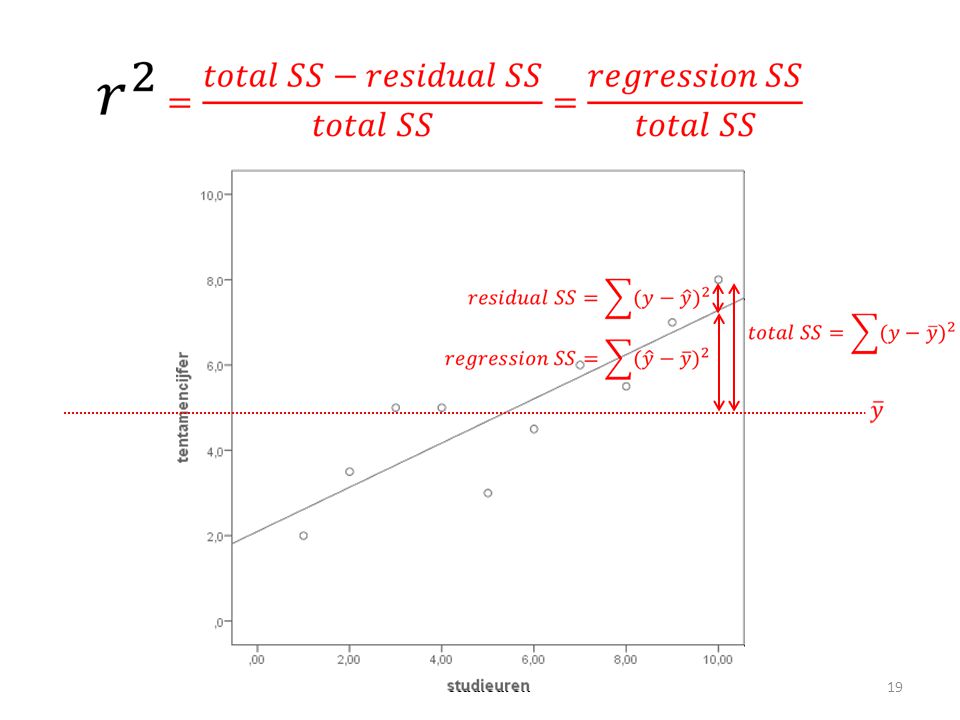
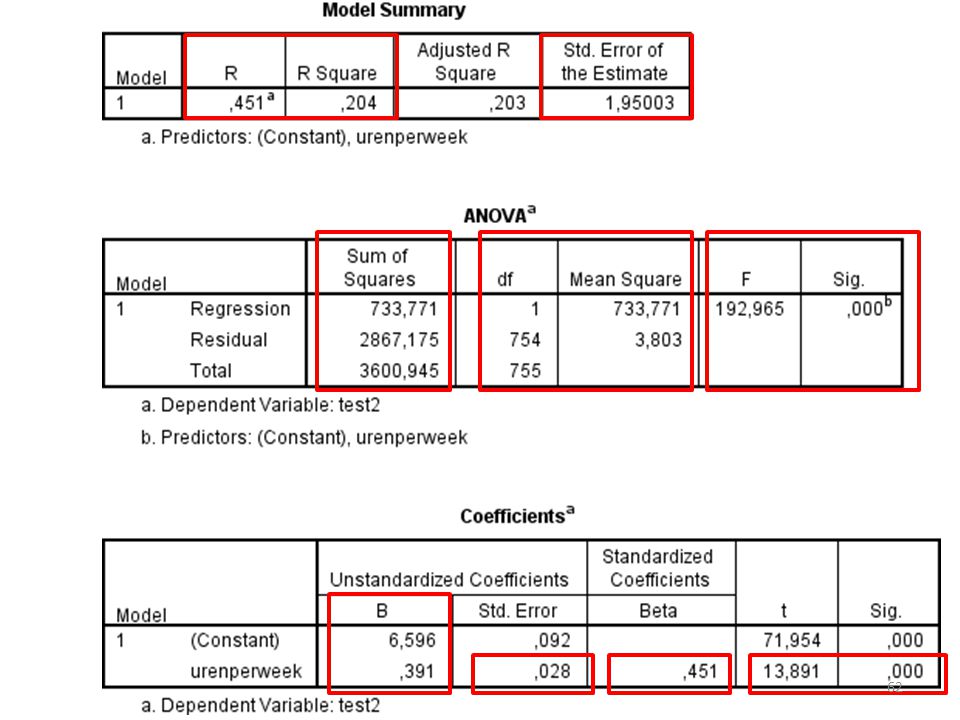
RSS, TSS, MSS MSS RSS TSS

21
Correlatie Correlatie: geeft sterkte van het verband tussen X en Y aan
Twee manieren om te berekenen: Met de R-square Met de slope en de standaarddeviaties

22
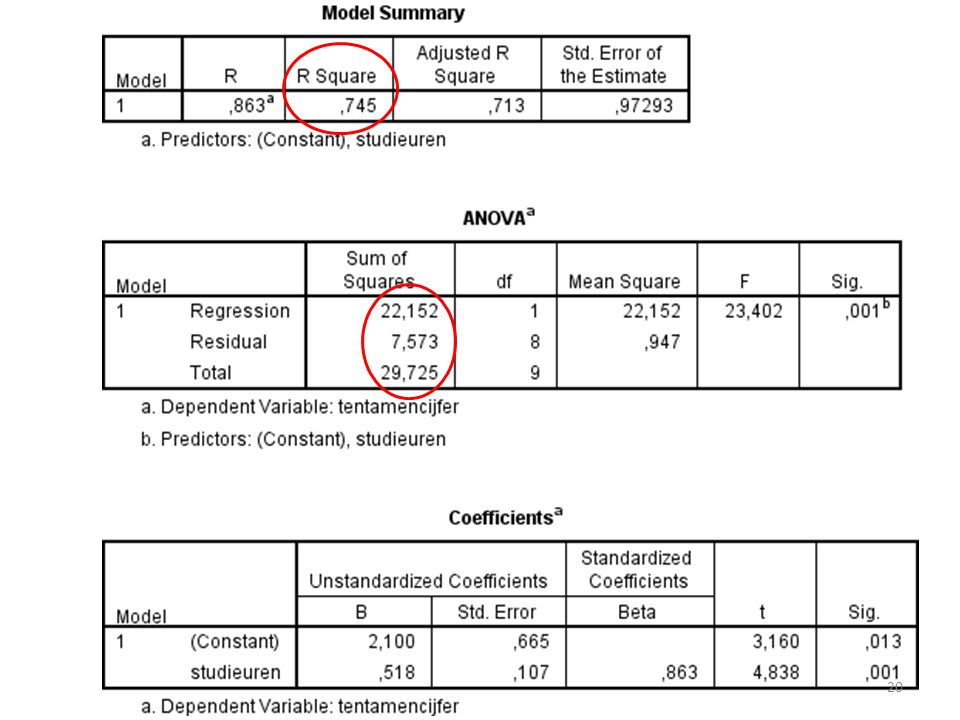
Correlatie Correlatie berekenen met de R-square:
De correlatie wordt uitgedrukt in r. Dus de wortel van R-square is de correlatie:

23
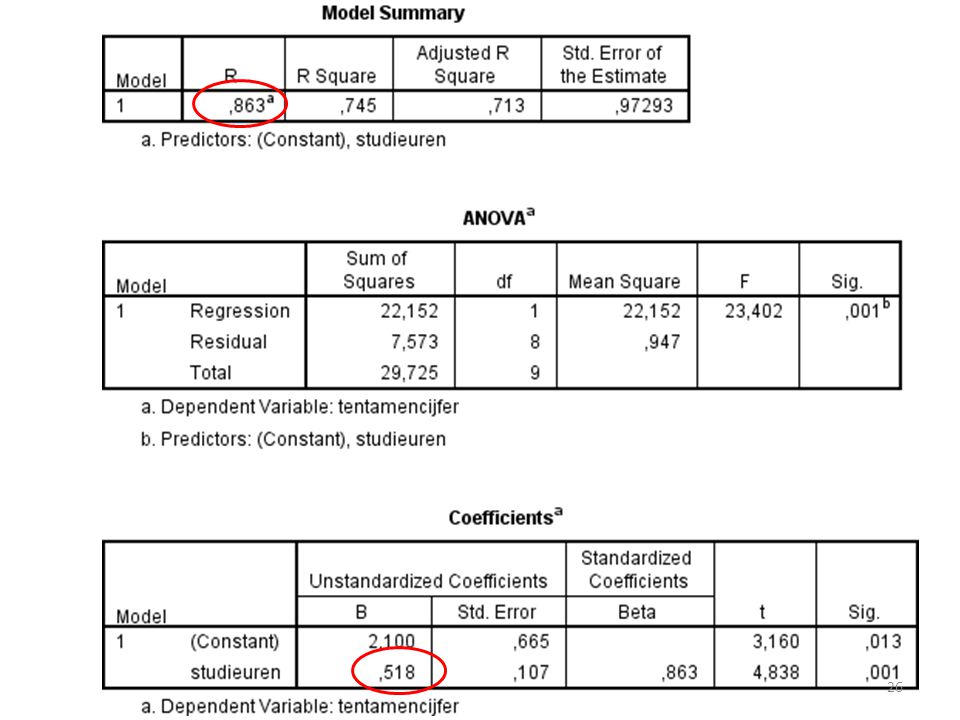
Correlatie Correlatie berekenen met de slope en de standaarddeviaties van X en Y:

25
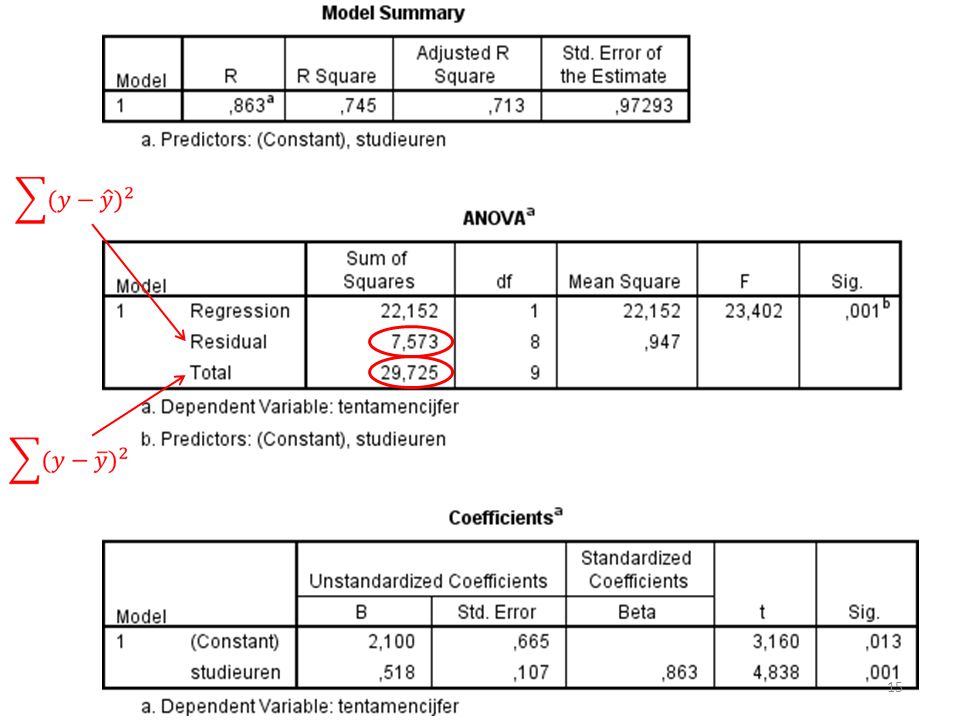
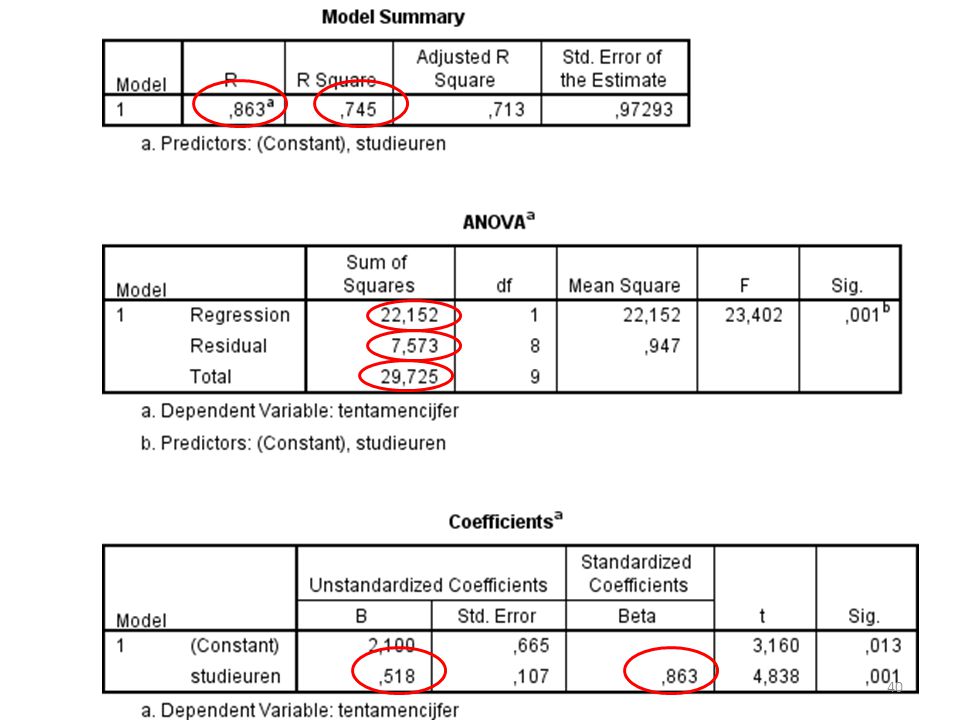
In een andere tabel (door een descriptives te draaien) zie ik een standaarddeviatie van X en van Y .650. De slope was .518.

27
Let op: De correlatie berekenen dmv de standaarddeviaties en de slope kan alleen maar als je 1 X hebt Als je meerdere X-en hebt dan geeft de correlatie het verband tussen al die X-en en Y aan

28
Theorie achter correlatie

29
Variantie en covariantie
Variantie: gemiddelde gekwadrateerde afstand tot het gemiddelde Covariantie: vergelijkbaar met variantie, maar dan voor 2 variabelen: Covariantie: meet hoeveel afstand tussen de gemiddeldes van 2 variabelen met elkaar te maken heeft.

30
Covariantie Nadeel: is afhankelijk van meeteenheden.
Voor inkomen in euros ipv dollars:

31
Covariantie and correlatie
In plaats van de variantie, gebruiken we de standaard deviatie. In plaats van de covariantie, gebruiken we de correlatie. In ons inkomen (in dollars) en opleiding voorbeeld:
 en opleiding voorbeeld:")
32
Correlatie Voordeel: is niet afhankelijk van meeteenheden.
Eigenschappen: -1 ≤ r ≤ 1. r=1: perfecte positieve correlatie. r=-1: perfecte negatieve correlatie. Grootte van r: sterkte van de associatie. Gebruiken we vooral met interval/continue variabelen.

33
Correlatie en regressie
Correlatie: geen causaal onderscheid tussen X en Y. Regressie: wel een causaal onderscheid tussen X en Y. Relatie tussen correlatie en regressiecoëfficiënt:

34
Correlatie en regressie
In ons voorbeeld: r is ook de gestandaardiseerde coëfficiënt (alleen met 1 X)
")
35
Correlatie en regressie
1 b sx sxb=rsy Eén s.d. omhoog in x resulteert in r s.d.’s omhoog in y. Onafhankelijk van meeteenheid! r (in dit geval de gestandardiseerde coefficient): goede maat voor sterkte!
: goede maat voor sterkte!")
36
Ter illustratie Inkomen in dollars: Inkomen in euros:

37
Gestandaardiseerde coëfficiënten (beta’s)
Om de sterkte van de associatie te meten. Mogelijk om verschillende coëfficiënten te vergelijken: …van dezelfde variabelen tussen verschillende regressies. Ook als de meeteenheid niet hetzelfde is. …van verschillende variabelen in dezelfde (multivariate) regressie.
 regressie.")
38
Verschil correlatie en regressielijn
Onafhankelijk van meeteenheden Geeft sterkte van associatie tussen X en Y aan in één getal Niet mogelijk om Y te voorspellen Geen causale richting tussen X en Y, simpelweg associatie Regressielijn: Afhankelijk van meeteenheden Mogelijk om Y te voorspellen o.b.v. X Geeft richting: je kijkt of X Y voorspelt

39
Weten nu meer over RSS, TSS, MSS R-square Correlatie

41
Hebben het nu steeds over beschrijvende statistiek Nu inferentiële statistiek

42
Betrouwbaarheidsintervallen
Betrouwbaarheidsintervallen Hypothesetests Ha: β > 0 of Ha: β < 0

43
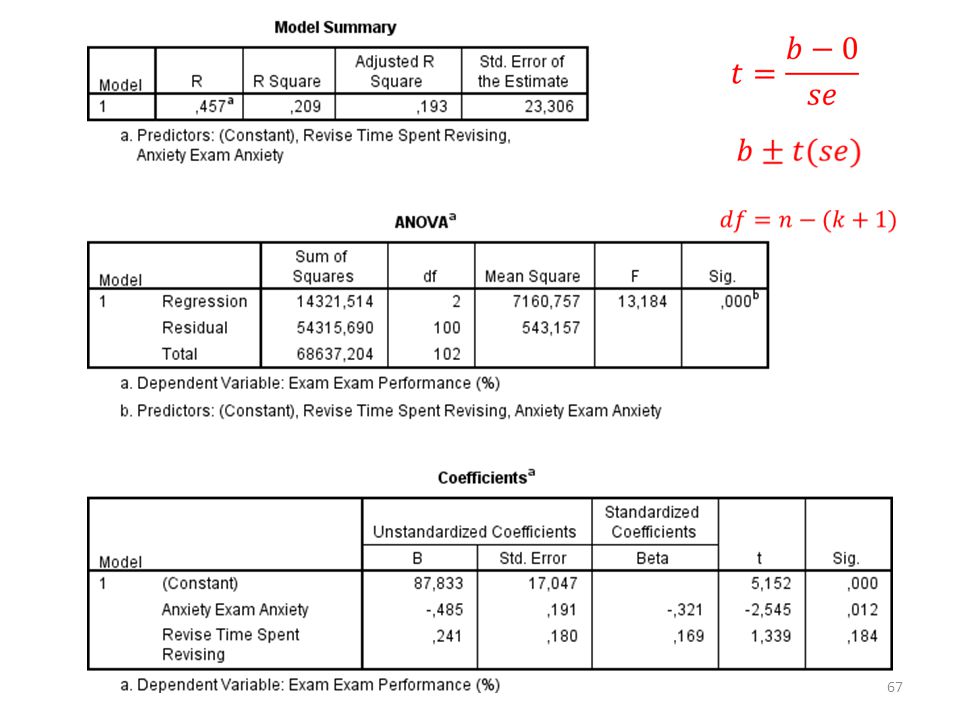
We willen weten of de slope significant afwijkt van 0 (0 is waarde nulhypothese) Moeten eerst de test statistic (t-waarde) weten.
 Moeten eerst de test statistic (t-waarde) weten.")
44
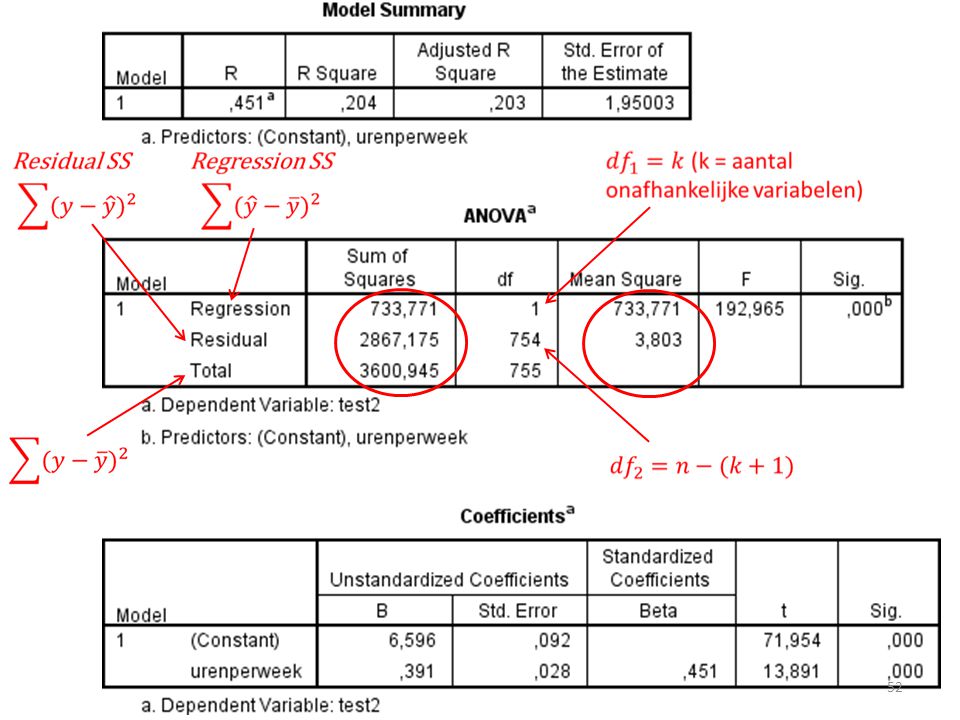
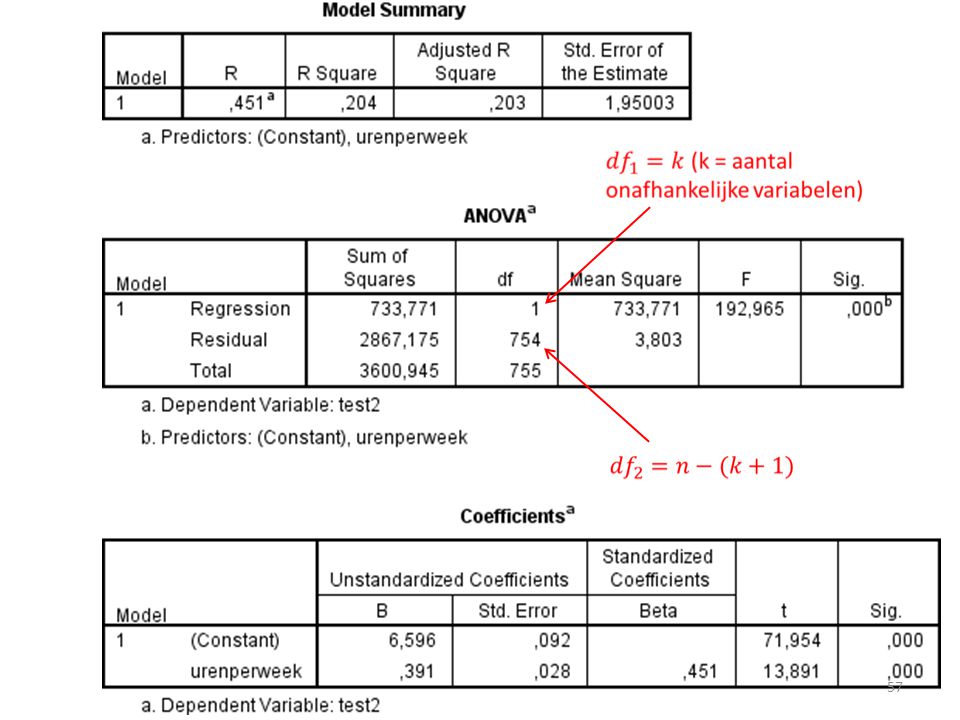
Want n – (1 + k)
")
45
Kritieke t-waarde bij df=8 met 95% (tweezijdig)?
")
46
Kritieke t = 2.306

48
Betrouwbaarheidsinterval van de slope (95%)
b ± t(se) b = .518 Kritieke t-waarde = 2.306 Se = 0.107 Dus: .518 ± 2.306(0.107) We weten met 95% zekerheid dat de slope in de populatie tussen de 0.27 en 0.76 ligt.
 b = Kritieke t-waarde = Se = Dus: .518 ± 2.306(0.107) We weten met 95% zekerheid dat de slope in de populatie tussen de 0.27 en 0.76 ligt.")
49
Als de 0 in het betrouwbaarheidsinterval van de slope ligt, dan kunnen we de nulhypothese niet verwerpen. Ligt de 0 niet in het betrouwbaarheidsinterval, dan kunnen we de nulhypothese wel verwerpen: de slope wijkt significant af van 0.

50
(0.028) = van tot 0.446
 = van tot")
51
Nu F-toets in ANOVA tabel
De F-toets ziet of een van de X-en een significante invloed op Y heeft

53
Mean squares Hoe kleiner de gemiddelde residual sum of squares (ofwel prediction errors) - de afwijkingen die we NIET verklaren met het regressiemodel - ten opzichte van de variatie die het regressiemodel WEL verklaart (de gemiddelde regression sum of squares), hoe beter het regressiemodel variantie y verklaart
 - de afwijkingen die we NIET verklaren met het regressiemodel - ten opzichte van de variatie die het regressiemodel WEL verklaart (de gemiddelde regression sum of squares), hoe beter het regressiemodel variantie y verklaart.")
54
De F-toets geeft de verhouding weer tussen het regressiemodel en de residuals.

55
Hoe hoger de F-waarde, hoe groter de kans dat één van de X-en een significante invloed heeft op Y
Zoeken kritieke F-waardes: Tabel D

56
Df1 Df2

58
Df1 = 1 Df2 = 754 Kritieke F-waarde = 3.84

59
Kritieke F-waarde = 3.84

60
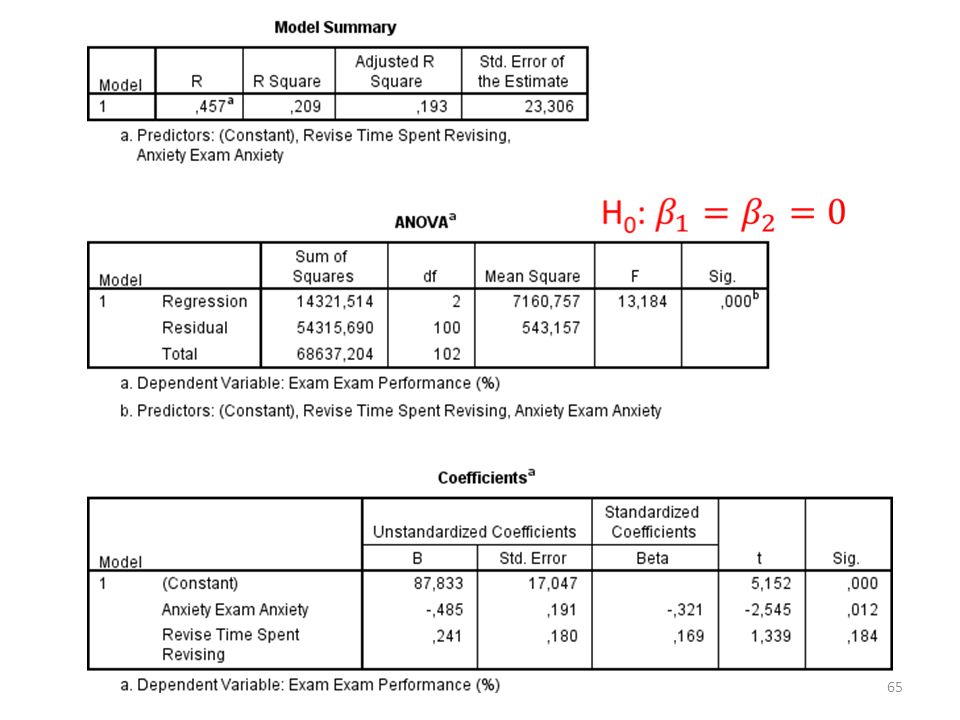
F-test en t-test t-test Test of één regressiecoëfficiënt 0 is.
H0: β1=0 (of β2=0 of β3=0). F-test Test of ALLE regressiecoëfficiënten 0 zijn. H0: β1=β2=β3=0. Ha: in ieder geval één van β1,β2,β3 is niet nul. F-test toetst of in ieder geval één onafhankelijke variabele enige variantie in de afhankelijke variabele verklaart. t-toets(en) vindt welk coëfficiënt dat doet.
. F-test. Test of ALLE regressiecoëfficiënten 0 zijn. H0: β1=β2=β3=0. Ha: in ieder geval één van β1,β2,β3 is niet nul. F-test toetst of in ieder geval één onafhankelijke variabele enige variantie in de afhankelijke variabele verklaart. t-toets(en) vindt welk coëfficiënt dat doet.")
61
Manieren om significantie X op Y te bepalen
T-toets: toets per slope Betrouwbaarheidsinterval van de slopes F-toets: toets alle slopes tegelijk

63
Meervoudige regressie

64
Multipele regressie in SPSS

66
Df1 = 2 Df2 = 100

68
Waarom zoveel output? Zodat je alles snapt als je zelf onderzoek doet

69
Oefenen

70
Vraag 1 We voeren een enkelvoudige regressie uit en vinden een model sum of squares (MSS) van 2163 en een total sum of squares (TSS) van 8560. Welke waarde heeft de residual sum of squares (RSS)? MSS + TSS MSS – TSS TSS – MSS Dat weten we niet obv bovenstaande
 MSS + TSS. MSS – TSS. TSS – MSS. Dat weten we niet obv bovenstaande.")
71
Output MSS + RSS = TSS, dus = 3172 MSS RSS TSS

72
Vraag 2 We vinden een slope van X1 van .523 en een standaard error van deze slope van .023. Wat is de t-waarde? Slope * se Slope / se Se / slope Se + slope

74
Vraag 3 Bij een meervoudige regressie vind je een R-square van .745.
Wat is de waarde van de correlatie? Onbekend obv bovenstaande R-square * 2 R-square / 2 Wortel R-square

76
Vraag 4 Een onderzoeker wil weten welke factoren van belang zijn in het bepalen van de huurprijs. Hij onderzoekt de effecten van grootte van de woning, wijk waarin de woning gesitueerd is en hoeveel kamers de woning heeft. Hij vindt een R-square van .31. Dit betekent dat 31% van de variantie in huurprijs bepaald wordt door grootte, wijk en aantal kamers. Waar Niet waar

77
Vraag 5 Dezelfde onderzoeker vindt voor grootte van de woning een slope van .589, voor wijk een slope van .123 en voor aantal kamers een slope van .988. Welke X heeft de grootste invloed op huurprijs? Grootte van de woning Wijk waarin de woning gesitueerd is Aantal kamers in de woning Dat weet je niet obv bovenstaande

78
Inferentiële statistiek: overzicht
Aantal variabelen Soort variabele(n) SPSS toets 1 Categorisch Binomial Kwantitatief One-sample T test 2 (of meer) Kwantitatief en 2 onafhankelijke groepen Independent-samples T test Kwantitatief en 2 afhankelijke groepen Dependent-samples T test Chi-kwadraat T test en F test (regressie) Betrouwbaarheid schaal Reliability analysis
 SPSS toets. 1. Categorisch. Binomial. Kwantitatief. One-sample T test. 2 (of meer) Kwantitatief en 2 onafhankelijke groepen. Independent-samples T test. Kwantitatief en 2 afhankelijke groepen. Dependent-samples T test. Chi-kwadraat. T test en F test (regressie) Betrouwbaarheid schaal. Reliability analysis.")
79
Morgen betrouwbaarheidsanalyse Toegevoegd hoofdstuk Van de Bunt: reliability analysis
















 23 januari 2013 Bodegraven.>")








 Quiz Night !>")



