Download de presentatie
1
1 Optuigen van datastructuren Zoeken op meerdere sleutels Dynamische order statistics (1)
")
2
2 Vandaag –Optuigen van datastructuren: door het bijhouden van extra gegevens en/of het hebben van extra pointers kan je Extra functionaliteit bieden Sommige operaties sneller doen –Meerdere sleutels –Dynamische order statistics

3
3 Eerste voorbeeld: zoeken op twee keys Stel, we hebben stel objecten met twee soorten keys (bijvoorbeeld: naam en registratienummer). We willen snel kunnen zoeken op elk van de twee soorten keys, gevonden objecten kunnen weglaten, etc. –Delete1(“Introduction to Algorithms 2nd edition”) –Delete2(“0-262-03293-7”) Je kan 2 zoekbomen (of hash-tabellen of …) gebruiken; elk object in beide datastructuren opslaan, maar hoe zorg je dat deletions goed gaan?
 –Delete2( ) Je kan 2 zoekbomen (of hash-tabellen of …) gebruiken; elk object in beide datastructuren opslaan, maar hoe zorg je dat deletions goed gaan .")
4
4 Datastructuur Twee hash-tabellen met chaining, maar –Dubbel-gelinkte lijsten (om snel iets uit de lijst weg te kunnen laten) –Elk object heeft kopie in andere tabel en pointer naar kopie Variaties mogelijk –Bespaar geheugen: sateliet-data maar op 1 plek –Geen pointers, maar “gewoon” zoeken en deleten in de andere tabel Operaties gaan in O(1) verwachtte tijd onder aannames: –Simple uniform hashing aanname –Loadfactor n/m=O(1) 5,4 Allerlei pointers zijn niet getekend in dit voorbeeld Allerlei pointers zijn niet getekend in dit voorbeeld
 –Elk object heeft kopie in andere tabel en pointer naar kopie Variaties mogelijk –Bespaar geheugen: sateliet-data maar op 1 plek –Geen pointers, maar gewoon zoeken en deleten in de andere tabel Operaties gaan in O(1) verwachtte tijd onder aannames: –Simple uniform hashing aanname –Loadfactor n/m=O(1) 5,4 Allerlei pointers zijn niet getekend in dit voorbeeld Allerlei pointers zijn niet getekend in dit voorbeeld")
5
5 Zoekbomen met extra pointers! 42,5 23,8 12,4 31,6 23,8 42,5 12,4 31,6 Alle operaties in O(log n): Gebruik gebalanceerde bomen (bijv. rood-zwart-bomen (komt nog)) Bij deletion: ook weglaten in kopie; opletten dat alle pointers goed blijven staan Alle operaties in O(log n): Gebruik gebalanceerde bomen (bijv. rood-zwart-bomen (komt nog)) Bij deletion: ook weglaten in kopie; opletten dat alle pointers goed blijven staan Kan ook met hashtabellen…
: Gebruik gebalanceerde bomen (bijv. rood-zwart-bomen (komt nog)) Bij deletion: ook weglaten in kopie; opletten dat alle pointers goed blijven staan Alle operaties in O(log n): Gebruik gebalanceerde bomen (bijv. rood-zwart-bomen (komt nog)) Bij deletion: ook weglaten in kopie; opletten dat alle pointers goed blijven staan Kan ook met hashtabellen….")
6
6 Dynamische order statistics Extra operatie 1 op zoekboom (OS-Select): –Voor i, 1 i n: wat het i de qua grootte in de datastructuur? Als i = 1, dan is dit het minimum Als i = n, dan is dit het maximum Als i = n/2, dan heet dit de mediaan We zoeken het element met rang i. –Vb: als we keys 3, 6, 8, 10, 20 hebben, dan OS-Select(…, 4) = 10 Extra operatie 2 op zoekboom (OS-Rank): –Gegeven een key x die in de zoekboom T staat, wat is de rang van x, d.w.z., het hoeveelste element qua grootte is het –Vb. Als we keys 3, 6, 8, 10, 20 hebben, dan OS-Rank(T,3) = 1, OS-Rank(T,10) = 4, etc. We gaan een zoekboom (evt. rood-zwart) aanpassen zodat deze operaties ook snel (O(h), O(log n)) kunnen
 = 10 Extra operatie 2 op zoekboom (OS-Rank): –Gegeven een key x die in de zoekboom T staat, wat is de rang van x, d.w.z., het hoeveelste element qua grootte is het –Vb. Als we keys 3, 6, 8, 10, 20 hebben, dan OS-Rank(T,3) = 1, OS-Rank(T,10) = 4, etc. We gaan een zoekboom (evt. rood-zwart) aanpassen zodat deze operaties ook snel (O(h), O(log n)) kunnen.")
7
7 Extra gegevens in zoekboom Elke knoop x heeft nog 1 extra getal opgeslagen: het aantal keys in het deel van de boom met x als wortel 26 20 17 12 41 7 47 1 30 5 28 1 38 3 10 4 14 7 21 4 16 2 35 1 19 2 23 1 39 1 15 1 7272 12 1 20 1 3131

8
8 Bijhouden van deze gegevens size(x): hoeveel afstammelingen (x inclusief) heeft x (aantal (niet-NIL) knopen in deelboom met x als wortel) (altijd integer) Invariant: –size(x) = size(left(x))+ size(right(x)) +1 –waarbij deze waarden 0 zijn voor NIL’s Bij veranderingen aan de boom: –Herbereken de waarden voor de knopen waar we iets veranderden, en alle knopen naar het pad naar de wortel toe x
: hoeveel afstammelingen (x inclusief) heeft x (aantal (niet-NIL) knopen in deelboom met x als wortel) (altijd integer) Invariant: –size(x) = size(left(x))+ size(right(x)) +1 –waarbij deze waarden 0 zijn voor NIL’s Bij veranderingen aan de boom: –Herbereken de waarden voor de knopen waar we iets veranderden, en alle knopen naar het pad naar de wortel toe x")
9
9 Operaties in rood-zwart-boom Als we een knoop x weglaten: –Herbereken de size-waarden voor x en alle knopen op het pad van x naar de wortel –Steeds -1 Als we een knoop x toevoegen: –Zet size x op 1, en herbereken de size-waarden voor alle knopen op het pad van x naar de wortel –Steeds +1 Als we een rotatie doen: –Herbereken de size-waarden voor de twee geroteerde knopen en alle knopen op het pad van deze twee knopen naar de wortel Bij een rood-zwart-boom zijn er O(log n) knopen die: –Geroteerd, weggelaten, toevoegd zijn, –Of op het pad zitten van zo’n knoop naar de wortel Herbereken (van beneden naar boven) voor deze O(log n) knopen Bijhouden kan in O(log n) tijd per operatie Sheet wordt overgeslagen in 2011 Materiaal komt terug bij Rood-zwart-bomen
 knopen die: –Geroteerd, weggelaten, toevoegd zijn, –Of op het pad zitten van zo’n knoop naar de wortel Herbereken (van beneden naar boven) voor deze O(log n) knopen Bijhouden kan in O(log n) tijd per operatie Sheet wordt overgeslagen in 2011 Materiaal komt terug bij Rood-zwart-bomen")
10
10 Selectie OS-Select(x, i): zoek het element met rang i in de deelboom met x als wortel Roep dit aan met OS- Select(root(T),i) Kijk naar het formaat van de linkerboom, zitlinks Dat vertelt of: –Het gezochte element in de linkerboom zit OF –De root het gezochte element is –Het gezochte element in de rechterboom zit Er zijn al zitlinks + 1 kleinere elementen niet in de rechterboom OS-Select(x,i) {Werkt correct als 1 i size(x)} if left(x)==NIL then –zitlinks =0 else –zitlinks = size(left(x)) if (i zitlinks) then –Return OS-Select(left(x),i) if (i = = zitlinks+1) then –Return x (if (i > zitlinks + 1) then) –Return OS-Select( right(x), i – zitlinks – 1 )
: zoek het element met rang i in de deelboom met x als wortel Roep dit aan met OS- Select(root(T),i) Kijk naar het formaat van de linkerboom, zitlinks Dat vertelt of: –Het gezochte element in de linkerboom zit OF –De root het gezochte element is –Het gezochte element in de rechterboom zit Er zijn al zitlinks + 1 kleinere elementen niet in de rechterboom OS-Select(x,i) {Werkt correct als 1 i size(x)} if left(x)==NIL then –zitlinks =0 else –zitlinks = size(left(x)) if (i zitlinks) then –Return OS-Select(left(x),i) if (i = = zitlinks+1) then –Return x (if (i > zitlinks + 1) then) –Return OS-Select( right(x), i – zitlinks – 1 )")
11
11 Randgevallen Test of i in het goede interval zit: if (1 i size(x) then –… (code als net) else return NIL
 then –… (code als net) else return NIL")
12
12 Voorbeeld: zitlinks(root(T),9) 26 20 17 12 41 7 47 1 30 5 28 1 38 3 10 4 14 7 21 4 16 2 35 1 19 2 23 1 39 1 15 1 7272 12 1 20 1 3131
,9)")
13
13 Tijd Selectie kan, als we size’s bijhouden, in O(h) tijd op een boom met diepte h Straks zien we bomen met diepte O(log n) dus in O(log n) tijd
 tijd op een boom met diepte h Straks zien we bomen met diepte O(log n) dus in O(log n) tijd")
14
14 Bepalen van de rang OS-Rank(T,x) geeft 1+ het aantal elementen in T dat kleiner is dan x. –Iets preciezer: als we gelijke keys kunnen hebben moeten die elementen voor x komen in een inorder-traversal Welke knopen moeten we tellen? –1 voor x zelf –Alle knopen in de linkerdeelboom van x –Sommige knopen die voorouder zijn van x: welke??? … –Voor sommige voorouders z van x alle knopen in de linkerdeelboom van z: welke?? …

15
15 Bepalen van de rang OS-Rank(T,x) geeft 1+ het aantal elementen in T dat kleiner is dan x. –Iets preciezer: als we gelijke keys kunnen hebben moeten die elementen voor x komen in een inorder-traversal Welke knopen moeten we tellen? –1 voor x zelf –Alle knopen in de linkerdeelboom van x –Sommige knopen die voorouder zijn van x Alle voorouders z waarvoor x in de rechterdeelboom van z zit Want dan is x groter dan z –Voor deze voorouders z van x: alle knopen in de linkerdeelboom van z (die zijn allemaal kleiner dan z en dus kleiner dan x) –Verder niet…
 –Verder niet….")
16
16 Welke knopen tellen 1 voor x zelf Alle knopen in de linkerdeelboom van x Sommige voorouders z van x en voor die voorouders z van x: alle knopen in de linkerdeelboom van z De test: –y = = right(p(y)) –Waarbij y het kind van z is in de deelboom waar x in zit Tel dit omhooglopend in de boom! z y x z y x

17
17 Pseudocode OS-Rank(T,x) if left(x)==NIL then –totaal = 1 {alleen x} else –totaal = size(left(x))+1 {x en alles in linkerboom van x} while (y != root(T)) do –if y == right(p(y)) {y is een rechterkind} then if left(p(y)) == NIL then totaal++ {tel p(y)} else totaal = totaal + size(left(p(y))) + 1 –{p(y) en alles in de linkerdeelboom van p(y)} –y = p(y) {een stapje omhoog de boom in} Return totaal
 if left(x)==NIL then –totaal = 1 {alleen x} else –totaal = size(left(x))+1 {x en alles in linkerboom van x} while (y != root(T)) do –if y == right(p(y)) {y is een rechterkind} then if left(p(y)) == NIL then totaal++ {tel p(y)} else totaal = totaal + size(left(p(y))) + 1 –{p(y) en alles in de linkerdeelboom van p(y)} –y = p(y) {een stapje omhoog de boom in} Return totaal")
18
18 26 20 17 12 41 7 47 1 30 5 28 1 38 3 10 4 14 7 21 4 16 2 35 1 19 2 23 1 39 1 15 1 7272 12 1 20 1 3131
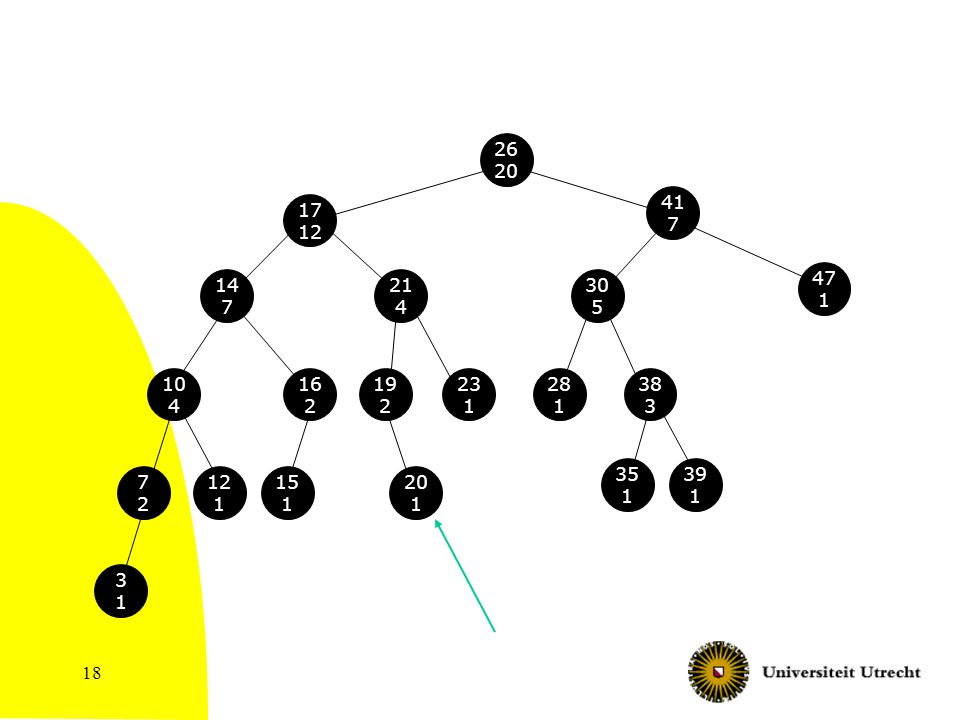
19
19 Zoeken van aantal Aantal(T,k): hoeveel knopen in T hebben key precies k? Wat je kan doen is: –Pas zoeken aan, en vindt de “meest linkse” node x met waarde k –Bereken de rang i van k –Pas zoeken aan, en vindt de “meest rechtse” node y met waarde k –Bereken de rang j van k –Output: j – i + 1 42 4 42 1 42 2 42 1 47 2 47 1 49 1

20
20 Andere evaluaties / Conclusies Er zijn ook andere functies die je op een soortgelijke manier kan bijhouden Een aantal hiervan behandelen we later, na het onderwerp van de gebalanceerde bomen Dus eerst: hoe zorg je ervoor dat de diepte van de boom O(log n) blijft?? Door toevoegen van extra informatie of pointers kan je soms –Operaties op een datastructuur versnellen –Extra functionaliteit toevoegen Analyse gaat: wiskundig EN experimenteel

21
21 Stelling Stelling Stel f is een waarde van elke knoop van een rood-zwart-boom T met n knopen. Stel dat we f(x) kunnen uitrekenen aan de hand van de informatie in knopen x, left(x), right(x) en dus ook f(left(x)) en f(right(x)). Dan kan je f bijhouden gedurende insertions en deletions op T zodat elke operatie nog steeds O(log n) tijd kost. Bewijs Bij elke insertion en deletion worden O(log n) knopen beinvloed door weglaten, toevoegen, kopieren van gegevens of roteren, of op het pad van zo’n knoop naar de wortel liggen. Voor deze knopen, herberekenen we f. Dit doen we in volgorde van beneden in de boom naar boven. Alle andere knopen blijven dezelfde waarde voor f houden. Sheet komt in deel materiaal na Rood-zwart-bomen
 kunnen uitrekenen aan de hand van de informatie in knopen x, left(x), right(x) en dus ook f(left(x)) en f(right(x)). Dan kan je f bijhouden gedurende insertions en deletions op T zodat elke operatie nog steeds O(log n) tijd kost. Bewijs Bij elke insertion en deletion worden O(log n) knopen beinvloed door weglaten, toevoegen, kopieren van gegevens of roteren, of op het pad van zo’n knoop naar de wortel liggen. Voor deze knopen, herberekenen we f. Dit doen we in volgorde van beneden in de boom naar boven. Alle andere knopen blijven dezelfde waarde voor f houden. Sheet komt in deel materiaal na Rood-zwart-bomen.")
22
22 Verbeteren met extra pointers: opvolgers Stel, we willen de opvolger van een knoop snel weten. (Allerlei toepassingen, bijv. we zoeken op naam, en willen mensen met dezelfde naam ook) We weten: O(h) en dus als we een gebalanceerde boom gebruiken O(log n) Maar, je kan deze bomen “verbeteren” zodat het in O(1) kan: –Houd voor elke knoop een pointer naar z’n opvolger bij 17 10 1421 161923 1571220 3 Sheet komt in deel materiaal na Rood-zwart-bomen
 We weten: O(h) en dus als we een gebalanceerde boom gebruiken O(log n) Maar, je kan deze bomen verbeteren zodat het in O(1) kan: –Houd voor elke knoop een pointer naar z’n opvolger bij Sheet komt in deel materiaal na Rood-zwart-bomen.")
23
23 Bijhouden successor-pointers Voor elk van de elementaire operaties: –Toevoegen –Weglaten –Roteren –Kopieren van gegevens Zorgen we dat de pointers na afloop van zo’n operatie weer goed staan En dat e.e.a. in O(log n) tijd per elementaire operatie kan 1.Weglaten van knoop x –Bereken predecessor x, zeg y –Successorpointer van x wijst naar z –Laat de successorpointer van y naar z wijzen 10 14 712 3 10 14 7 3 Sheet komt in deel materiaal na Rood-zwart-bomen
 tijd per elementaire operatie kan 1.Weglaten van knoop x –Bereken predecessor x, zeg y –Successorpointer van x wijst naar z –Laat de successorpointer van y naar z wijzen Sheet komt in deel materiaal na Rood-zwart-bomen.")
24
24 Elementaire operatie 2: toevoegen van knoop Toevoegen in O(log n): –Voeg de knoop x eerst toe –Bereken predecessor x, zeg y –Stel successor-pointer van y wijst naar z –Laat successorpointer van y naar x wijzen –Laat successorpointer van x naar z wijzen Merk op: balanceer-acties nog niet gedaan, maar de diepte van de boom is hooguit 1 te groot daardoor (dus nog steeds O(log n) Andere 2 stappen: kopieren van gegevens en rotaties zijn net zo makkelijk Stelling: rood-zwart-bomen hebben een variant, waarbij insertions, deletions, search in O(log n), maar successor, predecessor, minimum, maximum in O(1) tijd gaan Sheet komt in deel materiaal na Rood-zwart-bomen
: –Voeg de knoop x eerst toe –Bereken predecessor x, zeg y –Stel successor-pointer van y wijst naar z –Laat successorpointer van y naar x wijzen –Laat successorpointer van x naar z wijzen Merk op: balanceer-acties nog niet gedaan, maar de diepte van de boom is hooguit 1 te groot daardoor (dus nog steeds O(log n) Andere 2 stappen: kopieren van gegevens en rotaties zijn net zo makkelijk Stelling: rood-zwart-bomen hebben een variant, waarbij insertions, deletions, search in O(log n), maar successor, predecessor, minimum, maximum in O(1) tijd gaan Sheet komt in deel materiaal na Rood-zwart-bomen")
25
25 Intervalbomen Een rood-zwart-boom waarbij alle keys intervallen zijn. Hier: gesloten intervallen (eindpunten horen erbij): [a,b] Open en half-open intervallen gaan op soortgelijke manier Interval [a,b]: object, met –low(x) = a (lage, of linker-eindpunt) –high(x) = b (hoge, of rechter-eindpunt) Operaties op intervalboom: –Invoegen, Weglaten –Interval-Overlap-Search(T, y) Lever een pointer naar interval-object x, zodat interval x interval y overlapt, of NIL als zo’n x niet bestaat Toepassingen… y x y x y x Sheet komt in deel materiaal na Rood-zwart-bomen
: [a,b] Open en half-open intervallen gaan op soortgelijke manier Interval [a,b]: object, met –low(x) = a (lage, of linker-eindpunt) –high(x) = b (hoge, of rechter-eindpunt) Operaties op intervalboom: –Invoegen, Weglaten –Interval-Overlap-Search(T, y) Lever een pointer naar interval-object x, zodat interval x interval y overlapt, of NIL als zo’n x niet bestaat Toepassingen… y x y x y x Sheet komt in deel materiaal na Rood-zwart-bomen.")
26
26 Datastructuur Gebruik rood-zwart-boom met een knoop voor elk opgeslagen interval, waarbij het linkereindpunt de key is Verbeter de boom als volgt: –Elke knoop x heeft een waarde max(x): –max(x) = de maximum waarde van een rechtereindpunt van een interval opgeslagen in de boom met x als wortel [6,8] 16 [7,16] 16 [4,8] 15 [3,15] 15 [4,9] 10 [4,5] 5 [6,10] 10 Sheet komt in deel materiaal na Rood-zwart-bomen
![26 Datastructuur Gebruik rood-zwart-boom met een knoop voor elk opgeslagen interval, waarbij het linkereindpunt de key is Verbeter de boom als volgt: –Elke knoop x heeft een waarde max(x): –max(x) = de maximum waarde van een rechtereindpunt van een interval opgeslagen in de boom met x als wortel [6,8] 16 [7,16] 16 [4,8] 15 [3,15] 15 [4,9] 10 [4,5] 5 [6,10] 10 Sheet komt in deel materiaal na Rood-zwart-bomen](http://images.slideplayer.nl/17/5368695/slides/slide_26.jpg "26 Datastructuur Gebruik rood-zwart-boom met een knoop voor elk opgeslagen interval, waarbij het linkereindpunt de key is Verbeter de boom als volgt: –Elke knoop x heeft een waarde max(x): –max(x) = de maximum waarde van een rechtereindpunt van een interval opgeslagen in de boom met x als wortel [6,8] 16 [7,16] 16 [4,8] 15 [3,15] 15 [4,9] 10 [4,5] 5 [6,10] 10 Sheet komt in deel materiaal na Rood-zwart-bomen")
27
27 Bijhouden van max(x) max(x) = maximum van –high(x), –max(left(x)), en –max(right(x)) Dus stelling geldt: O(log n) per insertion en deletion Sheet komt in deel materiaal na Rood-zwart-bomen
 max(x) = maximum van –high(x), –max(left(x)), en –max(right(x)) Dus stelling geldt: O(log n) per insertion en deletion Sheet komt in deel materiaal na Rood-zwart-bomen")
28
28 Uitrekenen van Interval-Search Als we de max-waarden hebben, kan de Interval-Search in O(log n) tijd gedaan worden Stel we zoeken interval y. Kijk naar wortel x: –Als y overlapt met [low(x),high(x)]: klaar, we leveren de wortel op –Als x == NIL: klaar, niets gevonden –Anders: –Als max(left(x)) low(y), dan x = left(x) Als er een oplossing is, dan zit er zo’n oplossing in de linkerboom: het stuk met wortel left(x). Dit bewijzen we zometeen –Anders: doe x = right(x) Als er een oplossing is, dan zit er zo’n oplossing in de rechterboom Sheet komt in deel materiaal na Rood-zwart-bomen
,high(x)]: klaar, we leveren de wortel op –Als x == NIL: klaar, niets gevonden –Anders: –Als max(left(x)) low(y), dan x = left(x) Als er een oplossing is, dan zit er zo’n oplossing in de linkerboom: het stuk met wortel left(x). Dit bewijzen we zometeen –Anders: doe x = right(x) Als er een oplossing is, dan zit er zo’n oplossing in de rechterboom Sheet komt in deel materiaal na Rood-zwart-bomen.")
29
29 Pseudocode Interval-Search(T,y) x = wortel(T); while x != NIL do –if het interval van x overlapt het interval van y then Return x –if left(x) != NIL and max(left(x)) low(y) then x = left(x) –else x = right(x) Return NIL Sheet komt in deel materiaal na Rood-zwart-bomen
 x = wortel(T); while x != NIL do –if het interval van x overlapt het interval van y then Return x –if left(x) != NIL and max(left(x)) low(y) then x = left(x) –else x = right(x) Return NIL Sheet komt in deel materiaal na Rood-zwart-bomen")
30
30 Lemma en begin bewijs Stel x is een knoop in de rood-zwart-boom, zodat er een z is die y overlapt, en z is een afstammeling van x. Stel x en y overlappen niet. Als left(x)!=NIL en max(left(x)) low(y), dan is er een afstammeling van left(x) die y overlapt. Bewijs. Er zijn 2 gevallen die we bekijken. x en y overlappen niet, dus: x helemaal links van y of x helemaal rechts van y … x y y Geval 2: Geval 1: Sheet komt in deel materiaal na Rood-zwart-bomen
!=NIL en max(left(x)) low(y), dan is er een afstammeling van left(x) die y overlapt. Bewijs. Er zijn 2 gevallen die we bekijken. x en y overlappen niet, dus: x helemaal links van y of x helemaal rechts van y … x y y Geval 2: Geval 1: Sheet komt in deel materiaal na Rood-zwart-bomen.")
31
31 Geval 1 Kijk naar het interval w, afstammeling van left(x), met high(w) = max(left(x)). Die bestaat (definities.) low(w) low(x), want w in linkerdeelboom van x (zoekboomeigenschap) high(w) low(y) volgt uit max(left(x)) low(y) Dus: w begint voor x en eindigt na het begin van y, dus w overlapt y: klaar x y Sheet komt in deel materiaal na Rood-zwart-bomen
 low(w) low(x), want w in linkerdeelboom van x (zoekboomeigenschap) high(w) low(y) volgt uit max(left(x)) low(y) Dus: w begint voor x en eindigt na het begin van y, dus w overlapt y: klaar x y Sheet komt in deel materiaal na Rood-zwart-bomen.")
32
32 Geval 2 Kijk naar een oplossing z die met y overlapt. z moet beginnen voordat y eindigt, dus –low(z) high(y) < low(x) Dus moet z in de linkerdeelboom van x zitten, vanwege zoekboomeigenschap. QED x y Sheet komt in deel materiaal na Rood-zwart-bomen
 high(y) < low(x) Dus moet z in de linkerdeelboom van x zitten, vanwege zoekboomeigenschap. QED x y Sheet komt in deel materiaal na Rood-zwart-bomen.")
33
33 Samenvatten van correctheid algoritme Als er een oplossing is, dan is er een oplossing in de linkerdeelboom als left(x)!=NIL en max(left(x)) low(y). Een soortgelijk argument toont aan: als die test niet geldt, en er is een oplossing, dan is er een oplossing in de rechterdeelboom Invariant van het algoritme: als er een oplossing is, dan is er een oplossing in de deelboom met x als wortel. Dus: je vindt de oplossing als ie bestaat. Sheet komt in deel materiaal na Rood-zwart-bomen

34
34 Conclusies Door toevoegen van extra informatie of pointers kan je soms –Operaties op een datastructuur versnellen –Extra functionaliteit toevoegen We zagen met name een optuigingen van rood-zwart-bomen die een aantal operaties in O(log n) of minder doen. E.e.a. kan ook met andere soorten gebalanceerde bomen. Goed ontwerp is combinatie van: toepassen van technieken, inventiviteit, en doorzettingsvermogen Analyse doe je door: wiskundige analyse EN experimenten Sheet komt in deel materiaal na Rood-zwart-bomen





 –Analyse –Oplossen.>")





 Onderwerp 7.>")





 College 6.>")


 (j = kandidaat in eerste i-blok)>")
