Download de presentatie
De presentatie wordt gedownload. Even geduld aub

2
Query processing Van SQL-query naar resultaat Een kijkje onder de motorkap

3
Algebraïsche operatoren Klassieke dichotomie voor RA: sets or bags? Theorie van relationele databases: tabel is een set Praktijk (SQL): tabel is een bag B 1 1 2 2 AB 11 21 32 42 B 1 2 R π B (R) π B (R)
: tabel is een bag B AB B 1 2 R π B (R) π B (R).")
4
Bags (multisets) versus sets Union {a,b,c} U {a,a,c,d} = {a,a,a,b,c,c,d} Intersection {a,a,a,b,c,c,d} ∩ {a,a,b,e} = {a,a,b} Difference (minus) {a,a,a,b,c,c,d} - {a,a,b,e} = {a,c,c,d}
 versus sets Union {a,b,c} U {a,a,c,d} = {a,a,a,b,c,c,d} Intersection {a,a,a,b,c,c,d} ∩ {a,a,b,e} = {a,a,b} Difference (minus) {a,a,a,b,c,c,d} - {a,a,b,e} = {a,c,c,d}")
5
Nieuwe operatoren: projectie Extended projectie AB 11 21 32 A+BA1A2 211 311 522 R π A+B,A,A (R)
")
6
Nieuwe operatoren: sorteren τ L (R) = lijst van tupels in R gesorteerd op attributen in L R τ C,B↑ (R) BC 26 43 13 CB 31 34 62
 = lijst van tupels in R gesorteerd op attributen in L R τ C,B↑ (R) BC CB")
7
Grouping en aggregate functions WieWaarPrijs EasyjetBarcelona65 RyanairBarcelona59 KLMBarcelona80 EasyjetLondon45 LufthansaLondon58 KLMParijs69 WaarMinPrijs Barcelona59 London45 Parijs69 Trip Γ waar, min(prijs) (Trip)
 (Trip)")
11
Describe how a Selection distributes over a Minus Describe how a GroupBy distributes over a Union Rewrite the following expression for schema R(ABCD), S(AEFG), T(EHK)
, S(AEFG), T(EHK)")
12
We gaan kijken naar datastructuren en algoritmen ten behoeve van het uitvoeren van algebraïsche operatoren (Blok 4 INFODS) Algoritmische analyse in main memory: tel het aantal stappen van het programma ( :=, < ) Veralgemeniseer dit naar N, de lengte van de input Onze benadering: tel het aantal keren dat disk access (IO) wordt gedaan en negeer de data processing in CPU en main memory
 Algoritmische analyse in main memory: tel het aantal stappen van het programma ( :=, < ) Veralgemeniseer dit naar N, de lengte van de input Onze benadering: tel het aantal keren dat disk access (IO) wordt gedaan en negeer de data processing in CPU en main memory")
13
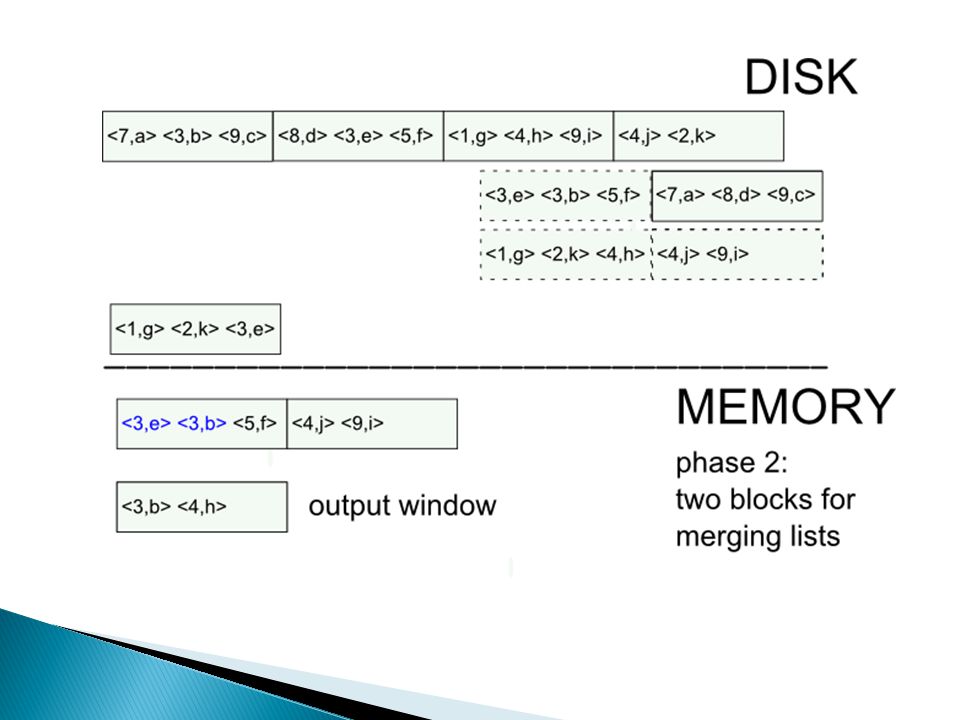
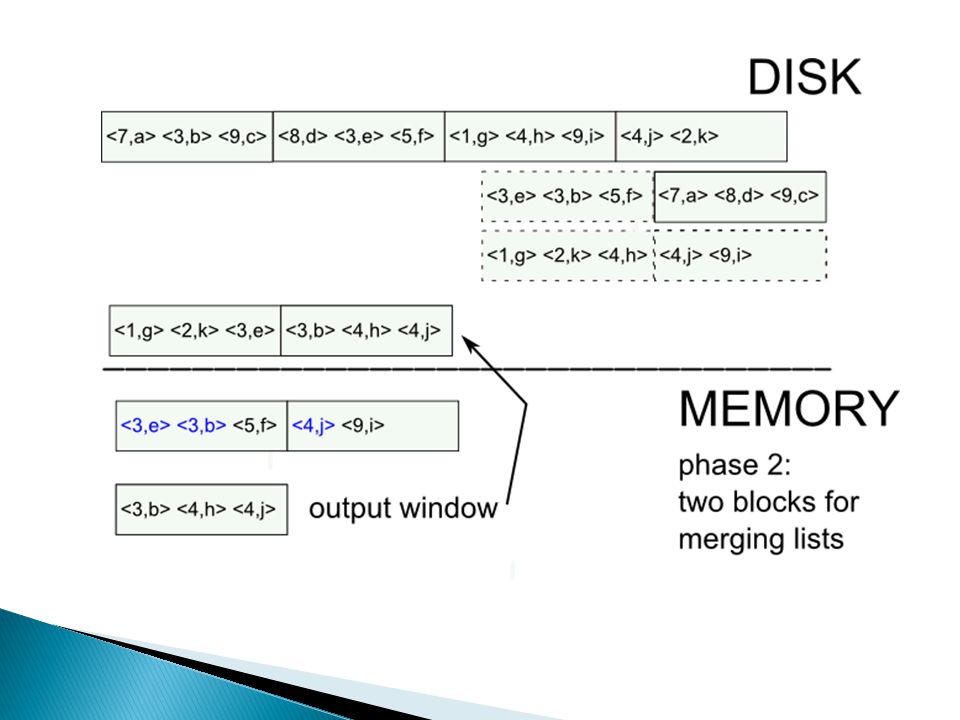
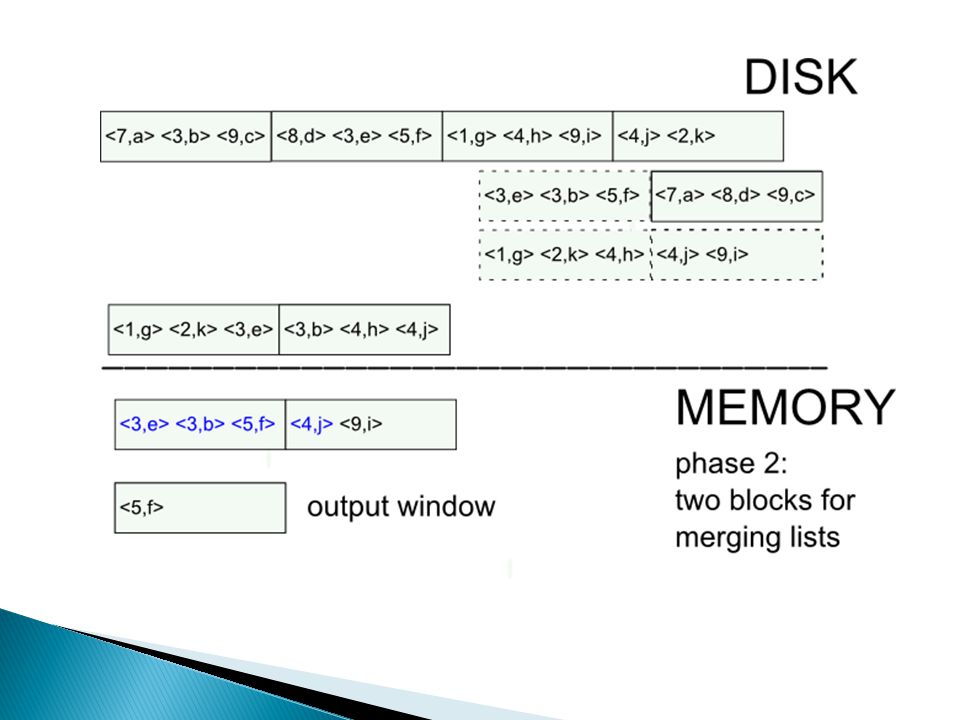
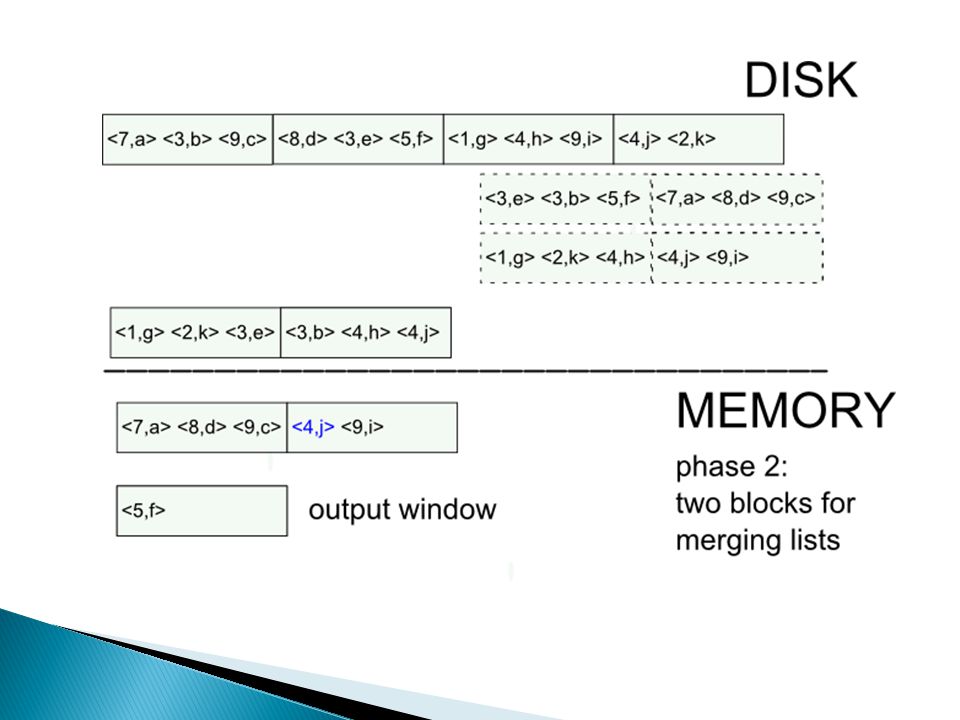
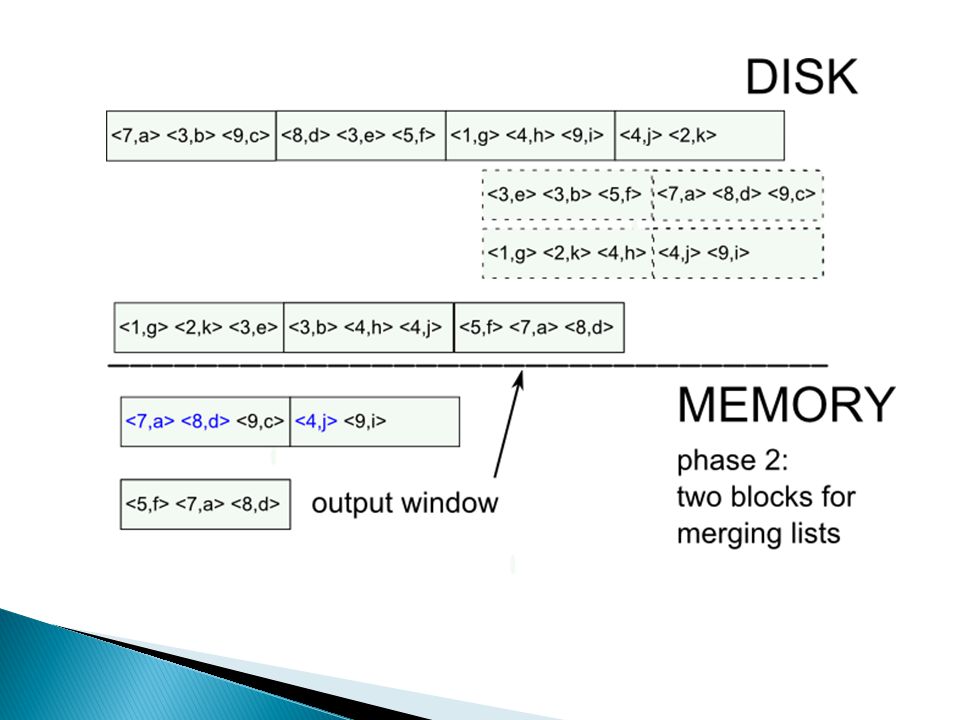
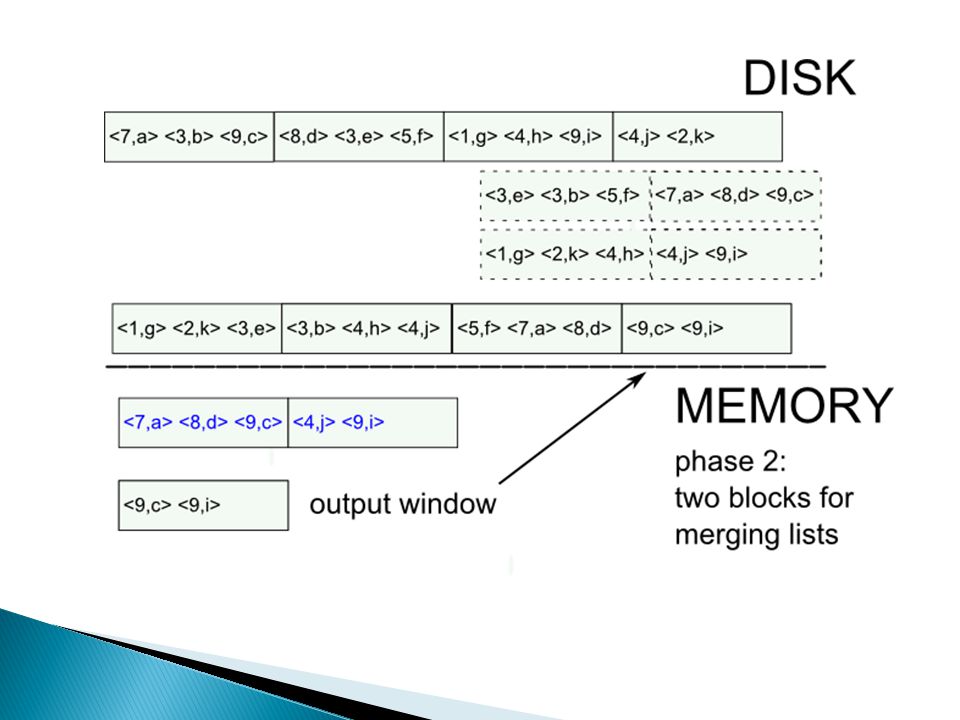
Hoe doe je … duplicate elimination? methode 1: sorteren external sorting van R kan gedaan worden via merge sort methode 2: hashing 1.hash tupels naar table van M buckets (daarvoor heb je M buffer pages nodig) 2.haal buckets één voor één naar main-memory en verwijder duplicaten IO: 3 * B, met B = het aantal blocks nodig om R op te slaan
 2.haal buckets één voor één naar main-memory en verwijder duplicaten IO: 3 * B, met B = het aantal blocks nodig om R op te slaan.")
14
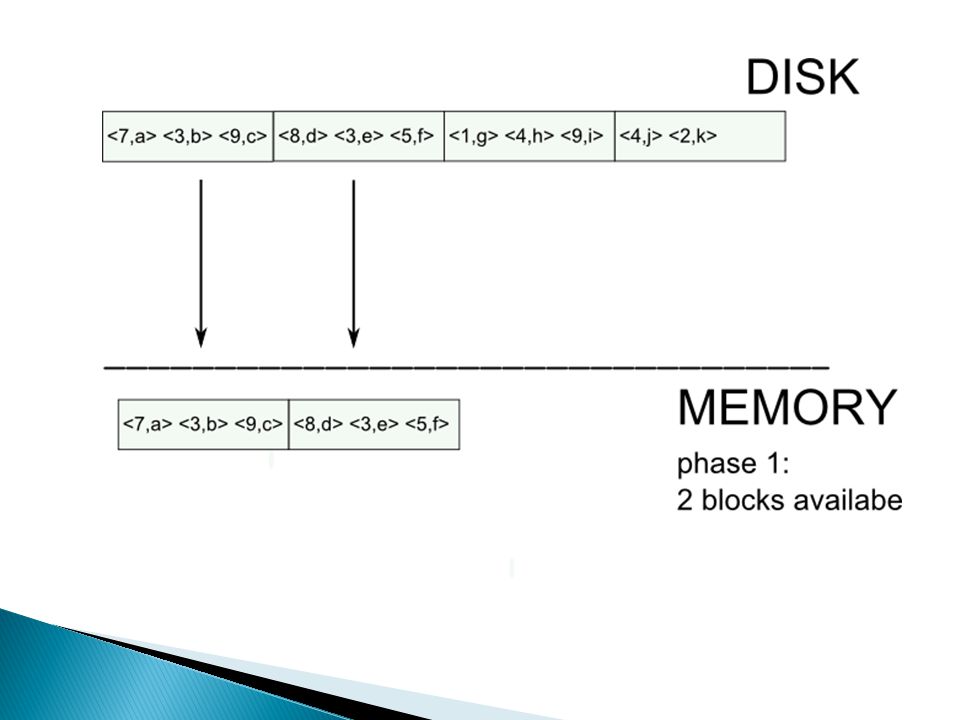
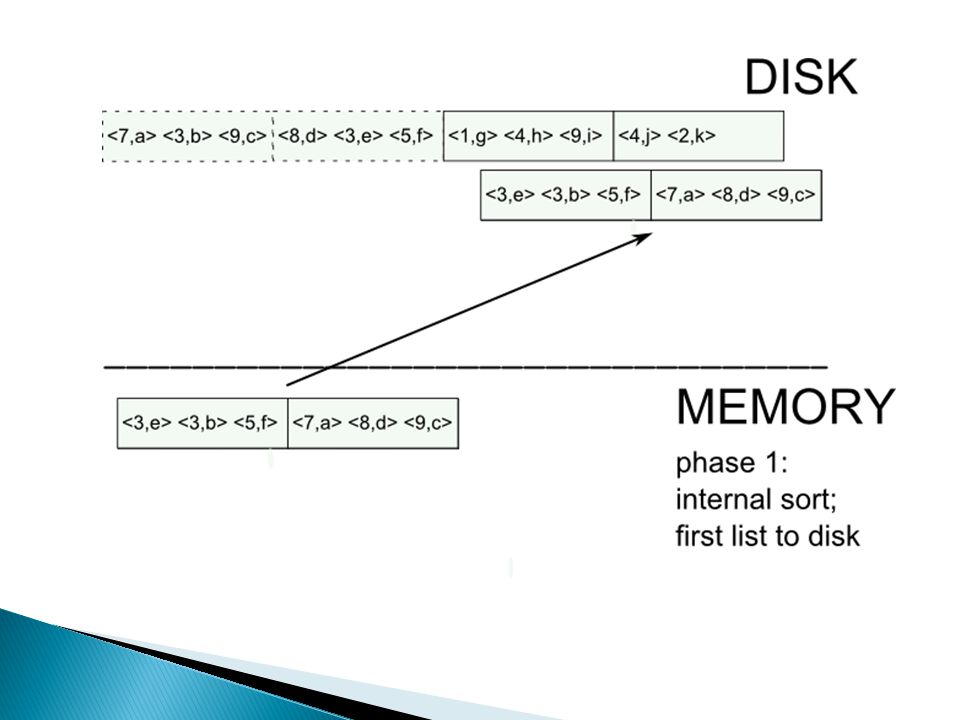
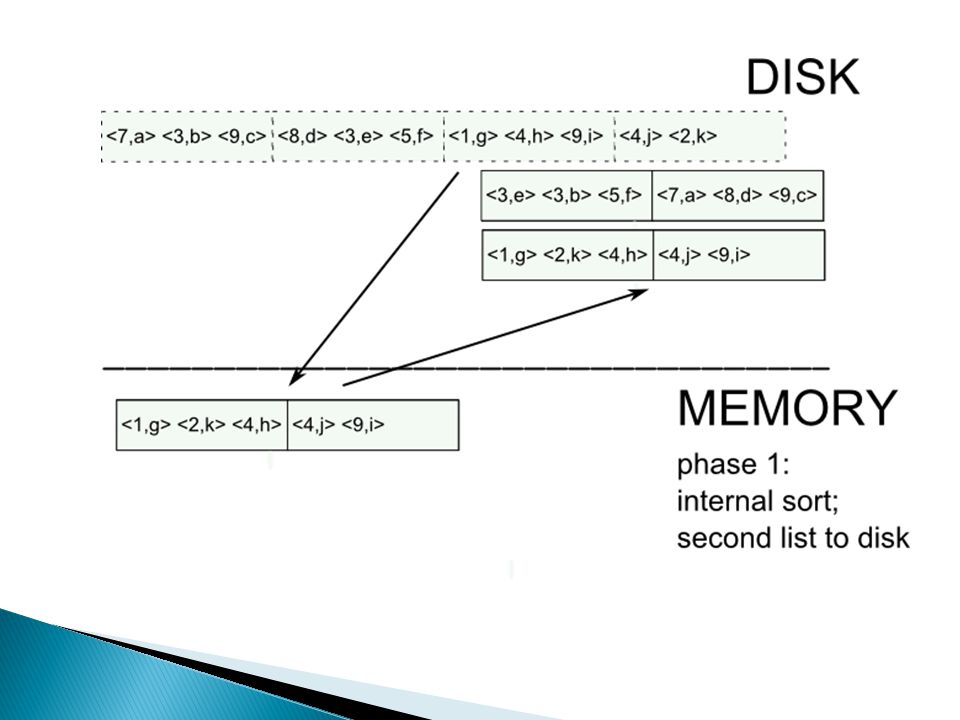
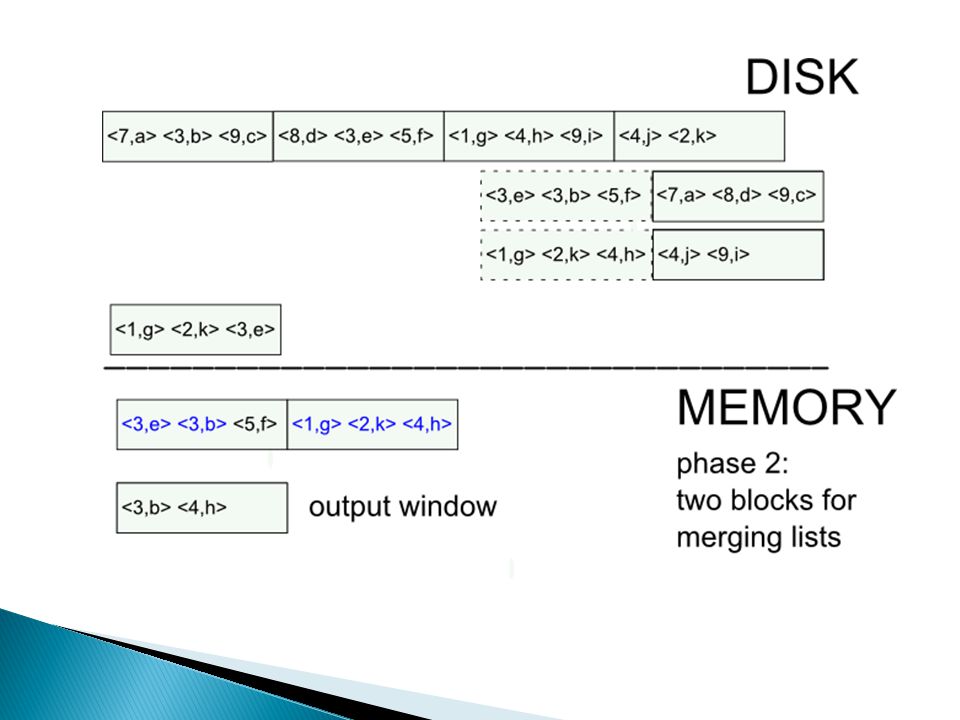
External merge sort: sort R[A,B] on A
![External merge sort: sort R[A,B] on A](http://images.slideplayer.nl/8/2164916/slides/slide_14.jpg "External merge sort: sort R[A,B] on A")
27
Hoe doe je … een selectie? S := σ A1 = C1, …, An = Cn (R) Verschillende access-paden Scan de gehele tabel en check de condities tupelgewijs Gebruik een index waarvan het attribuut bevat is in A 1,…, A n
 Verschillende access-paden Scan de gehele tabel en check de condities tupelgewijs Gebruik een index waarvan het attribuut bevat is in A 1,…, A n.")
28
Hoe doe je … een selectie? S := σ A1 = C1, …, An = Cn (R) Stel je hebt meerdere goede accesspaden (bijv. twee indexen) Optie 1: gebruik het meest selectieve access-pad Optie 2: gebruik twee (of meer) access- paden en bereken de intersectie
 Stel je hebt meerdere goede accesspaden (bijv. twee indexen) Optie 1: gebruik het meest selectieve access-pad Optie 2: gebruik twee (of meer) access- paden en bereken de intersectie.")
29
Statistics voor kostenschattingen T(R): het aantal tuples van R B(R): het aantal blocks van R V(R,A): het aantal verschillende waarden van attribuut A in R Uitdaging: doorrekenen effecten van algebraïsche operatoren voor statistics van tussenresultaten
: het aantal tuples van R B(R): het aantal blocks van R V(R,A): het aantal verschillende waarden van attribuut A in R Uitdaging: doorrekenen effecten van algebraïsche operatoren voor statistics van tussenresultaten")
30
Statistics voor kostenschattingen R’ := σ A=c (R) T(R’) = … T(R’) = T(R)/V(R,A) Veronderstelling: homogene verdeling waarden domein(A) Nauwkeuriger: histogrammen Prijskaartje: onderhoud Alternatief: sampling
 T(R’) = … T(R’) = T(R)/V(R,A) Veronderstelling: homogene verdeling waarden domein(A) Nauwkeuriger: histogrammen Prijskaartje: onderhoud Alternatief: sampling")
31
Statistics voor kostenschattingen U := R S θ: R.A = S.A T(U) = … T(U) = T(R)*T(S)/V(S,A) T(U) = T(S)*T(R)/V(R,A) Kies minimum van beide ?!
 = … T(U) = T(R)*T(S)/V(S,A) T(U) = T(S)*T(R)/V(R,A) Kies minimum van beide !")
32
Hoe doe je … een join? T := R S θ: R.A = S.A

33
Hoe doe je … een join? T := R S θ: R.A = S.A Tuple nested-loop Block-nested loop Index-nested loop Sort-Merge Hash-Join Buffer: M pages/blocks

34
Hoe doe je … een join? Block-nested loop S = smallest relation (nr of blocks) foreach chunk van M-1 blocks van S do lees deze blocks in main memory; foreach block B2 van R do { lees B2 in overgebleven bufferblok; check alle mogelijke combinaties van tupels t1 in chunk en t2 in B2; als t1.A = t2.A, schrijf dan de join van deze tuples naar output } IO: B(S) + B(R) * ┌ B(S)/(M-1) ┐
 foreach chunk van M-1 blocks van S do lees deze blocks in main memory; foreach block B2 van R do { lees B2 in overgebleven bufferblok; check alle mogelijke combinaties van tupels t1 in chunk en t2 in B2; als t1.A = t2.A, schrijf dan de join van deze tuples naar output } IO: B(S) + B(R) * ┌ B(S)/(M-1) ┐.")
35
Hoe doe je … een join? Index-nested loop aanname: index op S.A foreach block B van R do foreach tupel t in B do { stel t.A = a; gebruik de index om alle t2 in S te zoeken met t2.A = a; schrijf de join van t met elke t2 weg; }

36
Hoe doe je … een join? Index-nested loop c = kosten access via index (~2 voor B-tree) μ = gem. aantal gevonden tupels (schatten uit statistics) IO: B(R) + (c + μ) T(R) μ ~= T(S)/V(S,A) Als A key is in S: μ = 1
 IO: B(R) + (c + μ) T(R) μ ~= T(S)/V(S,A) Als A key is in S: μ = 1.")
37
Hoe doe je … een join? Sort-merge 1.(Indien nodig) sorteer R op A 2.(Indien nodig) sorteer S op A 3. repeat vul de buffer met de blocks van R en S die de kleinste gemeenschappelijke waarde voor R.A en S.A bevatten; join de tupels in deze blocks; until restant R of restant S leeg
 sorteer R op A 2.(Indien nodig) sorteer S op A 3. repeat vul de buffer met de blocks van R en S die de kleinste gemeenschappelijke waarde voor R.A en S.A bevatten; join de tupels in deze blocks; until restant R of restant S leeg.")
38
Hoe doe je … een join? Sort-merge AB a11 b12 a13 c14 c15 a16 AC b21 a22 c23 b24 c25 a26

39
1. Sort AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25

40
2. Merge buffer (mem) AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB a11 a13 a16 AC a22 a26 b21
 AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB a11 a13 a16 AC a22 a26 b21.")
41
2. Merge buffer (mem) AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 ABC a1122 a1126 a1322 a1326 a1622 a1626 AB a11 a13 a16 AC a22 a26 b21
 AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 ABC a1122 a1126 a1322 a1326 a1622 a1626 AB a11 a13 a16 AC a22 a26 b21.")
42
2. Merge buffer (mem) AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB b12 c14 c15 AC b21 b24 c23 ABC a1122 a1126 a1322 a1326 a1622 a1626
 AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB b12 c14 c15 AC b21 b24 c23 ABC a1122 a1126 a1322 a1326 a1622 a1626.")
43
2. Merge buffer (mem) AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB b12 c14 c15 AC b21 b24 c23 ABC ……… a1626 b1221 b1224
 AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB b12 c14 c15 AC b21 b24 c23 ABC ……… a1626 b1221 b1224.")
44
2. Merge buffer (mem) AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB c14 c15 AC c23 c25 ABC ……… b1224
 AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB c14 c15 AC c23 c25 ABC ……… b1224.")
45
2. Merge buffer (mem) AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB c14 c15 AC c23 c25 ABC ……… b1224 c1423 c1425 c1523 c1525
 AB a11 a13 a16 b12 c14 c15 AC a22 a26 b21 b24 c23 c25 AB c14 c15 AC c23 c25 ABC ……… b1224 c1423 c1425 c1523 c1525.")
46
Hoe doe je … een join? Hash Join 1.Kies een hash-functie voor het domein van A 2.Kies de grootte M van de hash-table 3.Hash elk tupel van R naar het corresponderende bucket 4.Hash elk tupel van S naar het corresponderende bucket 5.Haal elk bucket naar main-memory en construeer de resultaat-tupels

47
Join R[A,B] with S[A,C] h(a) = a DIV 10 AB 12a 3b 29c 7d 13e 12f 27g AC 29h 7i 8j 28k 12l
![Join R[A,B] with S[A,C] h(a) = a DIV 10 AB 12a 3b 29c 7d 13e 12f 27g AC 29h 7i 8j 28k 12l](http://images.slideplayer.nl/8/2164916/slides/slide_47.jpg "Join R[A,B] with S[A,C] h(a) = a DIV 10 AB 12a 3b 29c 7d 13e 12f 27g AC 29h 7i 8j 28k 12l")
48
Hash Join on A AB 12a 3b 29c 7d 13e 12f 27g AC 29h 7i 8j 28k 12l Bucket: h(a) = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k
 = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k")
49
Hash Join on A Bucket: h(a) = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k Join each bucket in main memory: AB 3b 7d AC 7i 8j ABC 7di adds:
 = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k Join each bucket in main memory: AB 3b 7d AC 7i 8j ABC 7di adds:")
50
Bucket: h(a) = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k Join each bucket in main memory: ABC 7di 12al fl adds: AB 12a 13e 12f AC l
 = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k Join each bucket in main memory: ABC 7di 12al fl adds: AB 12a 13e 12f AC l")
51
Bucket: h(a) = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k Join each bucket in main memory: ABC 7di 12al fl 29ch adds: AB 29c 27g AC 29h 28k
 = 0 Bucket: h(a) = 1 Bucket: h(a) = 2 AB 3b 7d AC 7i 8j AB 12a 13e 12f AC l AB 29c 27g AC 29h 28k Join each bucket in main memory: ABC 7di 12al fl 29ch adds: AB 29c 27g AC 29h 28k")
52
Hash Join on A: analysis R and S fit in B(R) and B(S) blocks Scanning R and S to hash the tuples requires B(R) + B(S) disk accesses Writing tuples to hash table (using window block for each bucket) requires B(R) + B(S) disk accesses Fetching each bucket for joining requires (roughly) B(R) + B(S) disk accesses for reading Ignore writing resulting tuples in analysis (all methods have to do that) IO = 3 *(B(R) + B(S))
 and B(S) blocks Scanning R and S to hash the tuples requires B(R) + B(S) disk accesses Writing tuples to hash table (using window block for each bucket) requires B(R) + B(S) disk accesses Fetching each bucket for joining requires (roughly) B(R) + B(S) disk accesses for reading Ignore writing resulting tuples in analysis (all methods have to do that) IO = 3 *(B(R) + B(S))")
53
Physical tuning Presence of physical structures facilitates efficient query processing Possibilities: indexes keeping tables sorted on a specific attribute keeping tables clustered on a specific index maintaining materialized views Task for the DBA: monitor performance and reconsider physical database organization Challenge: automatic support for optimizing physical database organization

54
Dual architecture: OLTP vs OLAP OLTP = On Line Transaction Processing High volumes of small updating transactions, often in combination with simple queries to identify primary key values Typical domain: support of commercial activities Real time performance requirements High requirements with respect to transaction integrity: concurrency, recovery, constraint satisfaction Term: “production database” Relatively low number of indexes

55
Dual architecture: OLTP vs OLAP OLAP = On Line Analytical Processing Low volumes of massive read-only queries, often changing perspective (sales per week, month, year, article, region, …) Typical domain: management information systems No real time performance requirements, although … No updates, no transaction processing; periodical reloading of preprocessed snapshots from production database Physical organization tuned toward read queries: many indices, materialized views, precomputed aggregates, … Term: “data warehouse”
 Typical domain: management information systems No real time performance requirements, although … No updates, no transaction processing; periodical reloading of preprocessed snapshots from production database Physical organization tuned toward read queries: many indices, materialized views, precomputed aggregates, … Term: data warehouse")
56
Beyond OLAP: data mining Discovery of interesting patterns and models in data bases

57
Data mining example Market basket analysis: Find groups of products that are often bought together

58
Data mining example Market basket analysis folklore: diapers & beer

Verwante presentaties








 –Analyse –Oplossen.>")







 College 6.>")
 kost ongeveer 400 bytes ◦ Een disk block bevat 8.>")

 (j = kandidaat in eerste i-blok)>")




 Wiebren de Jonge Vrije Universiteit, Amsterdam Voorlopige versie 2003.>")
