Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Inleiding Besliskunde Maastricht University Department Mathematics
Lineair Programeren Prof. Dr. Ronald L. Westra Maastricht University Department Mathematics

2
Inleiding Besliskunde
Inhoud Geometrische interpretatie en de Simplexmethode De valkuilen van de Simplexmethode en Infeasible Dictionaries Dualiteitstheorie en de Simplexmethode in matrixformulatie Toepassing: robuuste regressie en Sparse Estimation mbv de Simplexmethode

3
1.1 Geometrische interpretatie
Besliskunde is de kunde van het beslissen. Exacter: het systematisch beschrijven van een beslissingsprobleem, en het methodisch vinden van een correcte oplossing daarvan. De drie belangrijkste elementen in de besliskunde zijn: het zeer nauwkeurig beschrijven van het beslissingsprobleem = maken van een mathematisch model het vinden van een correcte oplossing (= een beslissing) van het probleem de analyse en de gevoeligheid van de gevonden oplossing(en) In de besliskunde streven we naar: het vinden van juiste oplossingen (de beslissingen) het analyseren van verscheidene strategieën Voorbeelden van grote projecten waar besliskunde succesvol werd/wordt toegepast zijn: de apollo-saturnus maanlandingen grote bouwprojecten de beste keuze voor de nieuwe vestiging van een fabriek of supermarkt
 van het probleem. de analyse en de gevoeligheid van de gevonden oplossing(en) In de besliskunde streven we naar: het vinden van juiste oplossingen (de beslissingen) het analyseren van verscheidene strategieën. Voorbeelden van grote projecten waar besliskunde succesvol werd/wordt toegepast zijn: de apollo-saturnus maanlandingen grote bouwprojecten. de beste keuze voor de nieuwe vestiging van een fabriek of supermarkt.")
4
1. Geometrische interpretatie
Meestal is de beschrijving van het probleem gebaseerd op het beschrijven van de voorwaarden waaraan de oplossing moet voldoen. Zo’n voorwaarde heet een constraint. Veelal nemen we niet genoegen met ’n oplossing maar willen we de ‘beste’ oplossing. Dat wordt dan uitgedrukt in een criterium of object-functie. De beste oplossing wordt nu gedefinieerd als diegene die het criterium maximaliseert. Bij het mathematisch modelleren van een beslissingsprobleem zijn verscheidene modellen mogelijk. We onderscheiden: kwantitatieve modellen: hierin worden de beslissingsproblemen uitgedrukt aan de hand van kwantitatieve grootheden die we beslissingsparameters (decision variables) noemen. Dit zijn parameters die gehele of reële waarden kunnen aannemen. Bijvoorbeeld: x = 3.14. kwalitatieve modellen: hierin worden de kwalitatieve beslissingsparameters gebruikt. Bijvoorbeeld: kleur = ‘rood’.
 noemen. Dit zijn parameters die gehele of reële waarden kunnen aannemen. Bijvoorbeeld: x = kwalitatieve modellen: hierin worden de kwalitatieve beslissingsparameters gebruikt. Bijvoorbeeld: kleur = ‘rood’.")
5
1. Geometrische interpretatie
Lineair Programmeren Een groot probleem bij dergelijke beslissingmodellen is het vinden van de constraints, en het schatten van de parameters en constanten die daarin voorkomen. Vaak zijn experimenten of metingen nodig om deze te schatten. Op een zelfde manier is de validatie van het model problematisch. Voorbeeld: de ‘prijselasticiteit’ = hoeveel meer producten worden verkocht als we de prijs b.v. 1 euro goedkoper maken? Bij de meest eenvoudige kwantitatieve modellen zijn zowel de constraints alsook het criterium lineair in de beslissingsparameters. Dit zijn de lineaire programmeer problemen.

6
1. Geometrische interpretatie
Lineair Programmeren Historisch ligt hier ook de oorsprong van de besliskunde. Bij de landing van de geallieerden in Normandië in 1944, moesten in korte tijd een miljoen soldaten aan vijandig land gebracht worden. Deze operatie werd zeer nauwkeurig voorbereid. Bij die voorbereiding werden de eerste mathematische beslissingsmodellen gemaakt en toegepast. Dit waren lineaire modellen. Men kon zulke problemen toen nog niet exact oplossen, maar nam er genoegen mee door zo lang te gokken tot een oplossing werd gevonden die aan alle constraints voldeed. Dit is de zg. Monte Carlo simulatie. Pas in 1947 werd door G.B. von Dantzig een exacte mathematische oplossingsmethode bedacht: de zogenaamde Simplex-methode

7
1. Geometrische interpretatie
Lineair Programmeren Historisch ligt hier ook de oorsprong van de besliskunde. Bij de landing van de geallieerden in Normandië in 1944, moesten in korte tijd een miljoen soldaten aan vijandig land gebracht worden. Deze operatie werd zeer nauwkeurig voorbereid. Bij die voorbereiding werden de eerste mathematische beslissingsmodellen gemaakt en toegepast. Dit waren lineaire modellen. Men kon zulke problemen toen nog niet exact oplossen, maar nam er genoegen mee door zo lang te gokken tot een oplossing werd gevonden die aan alle constraints voldeed. Dit is de zg. Monte Carlo simulatie. Pas in 1947 werd door G.B. von Dantzig een exacte mathematische oplossingsmethode bedacht: de zogenaamde Simplex-methode

8
1. Geometrische interpretatie
Wij beschouwen nu de algemene vorm van lineaire programmeer (=LP) problemen: Beschouw een beslissingsprobleem waarin we zoeken naar de waarden van n reële (beslissings)variabelen x1, x2, ..., xn, onder de voorwaarde dat: Dit noemen we de standaardvorm van een LP probleem.
 problemen: Beschouw een beslissingsprobleem waarin we zoeken naar de waarden van n reële (beslissings)variabelen x1, x2, ..., xn, onder de voorwaarde dat: Dit noemen we de standaardvorm van een LP probleem.")
9
De geometrische interpretatie
We kunnen een nuttige geometrische interpretatie geven aan standaard LP-problemen. Beschouw een n-dimensionale Euclidische ruimte IRn met elementen (x1, x2, ..., xn). De vergelijking van een vlak V in deze ruimte is gegeven door: u1x1 + u2x unxn = c Hierbij zijn ui en c gegeven constanten. De vector u = (u1,u2,...,un)T staat loodrecht op vlak V en heet een normaalvector van V. Vervangen we het is-teken door een ongelijkheidsteken, dan definieert de relatie het halfvlak boven – of onder het vlak V. Het stelsel van ongelijkheden definieert de doorsnede van een aantal van zulke vlakken.
. De vergelijking van een vlak V in deze ruimte is gegeven door: u1x1 + u2x unxn = c. Hierbij zijn ui en c gegeven constanten. De vector u = (u1,u2,...,un)T staat loodrecht op vlak V en heet een normaalvector van V. Vervangen we het is-teken door een ongelijkheidsteken, dan definieert de relatie het halfvlak boven – of onder het vlak V. Het stelsel van ongelijkheden definieert de doorsnede van een aantal van zulke vlakken.")
10
1. Geometrische interpretatie

11
1. Geometrische interpretatie

12
1. Geometrische interpretatie

13
1. Geometrische interpretatie

14
1. Geometrische interpretatie

15
1. Geometrische interpretatie

16
1. Geometrische interpretatie

17
1. Geometrische interpretatie

18
1. Geometrische interpretatie

19
Voorbeeld: het vergelijken van appels en peren
Verbale beschrijving van het probleem: Hoeveel appels en peren kan ik kopen als ik 3.60 euro heb, en: appels 20 ct/stuk peren 30 ct/stuk Oplossing : Stel: #appels = a, #peren = p, beperkende voorwaarde [constraint]:

20
Voorbeeld: het vergelijken van appels en peren

21
Voorbeeld: het vergelijken van appels en peren
Stel dat er een bijkomend probleem is, te weten dat de groenteboer slechts 12 appels en 10 peren in voorraad heeft, dus:

22
Voorbeeld: het vergelijken van appels en peren
Hier valt weinig – of veel – te beslissen; elk paar (p,a) in het vlak is een toegestane oplossing. Stel dat we nu echter de voedingswaarde van onze keuze zo hoog mogelijk willen maken – bijvoorbeeld het vitaminegehalte. Stel: appel: 4 gram vitamine C/stuk peer: 7 gram vitamine C/stuk Het totaal aantal gram vitamine C is dan: V = 4 a + 7 p
 in het vlak is een toegestane oplossing. Stel dat we nu echter de voedingswaarde van onze keuze zo hoog mogelijk willen maken – bijvoorbeeld het vitaminegehalte. Stel: appel: 4 gram vitamine C/stuk. peer: 7 gram vitamine C/stuk. Het totaal aantal gram vitamine C is dan: V = 4 a + 7 p.")
23
Voorbeeld: het vergelijken van appels en peren
Het totaal aantal gram vitamine C is : V = 4 a + 7 p ; Dit definieert een verzameling van parallelle lijnen in het (a,p)-vlak:
-vlak:")
24
Voorbeeld: het vergelijken van appels en peren
Door schuiven van de lijn V = 4 a + 7 p over de convexe simplex vinden we de oplossing: a = 3 p = 10 V = 82

25
1. Geometrische interpretatie

26
Het oplossen van LP-problemen
1. Geometrische interpretatie Het oplossen van LP-problemen Voor het oplossen van een LP-probleem bestaan zeer effectieve en deterministische methoden. (Vergelijk dit met de vierkantswortel van tweedegraads-functies: ) De oudste en meest bekende is de genoemde simplex-methode. Deze is enerzijds duidelijk gedefinieerd. Anderzijds bewerkelijk en bol van de technische begrippen. Het werkt verhelderend om steeds de geometrische interpretatie steeds voor ogen te houden.
 De oudste en meest bekende is de genoemde simplex-methode. Deze is enerzijds duidelijk gedefinieerd. Anderzijds bewerkelijk en bol van de technische begrippen. Het werkt verhelderend om steeds de geometrische interpretatie steeds voor ogen te houden.")
27
Doelstelling van deze cursus
1. Geometrische interpretatie Doelstelling van deze cursus Nu we de basisbegrippen hebben leren kennen, kunnen de drie voornaamste doelstellingen van deze cursus noemen: het kunnen mathematisch modelleren van een beslissingsprobleem. het kunnen oplossen van een LP-probleem middels de Simplex-methode. het begrijpen van de theoretische achtergronden en de termen betreffende LP-problemen.

28
1.2 De Simplexmethode In dit onderdeel beschouwen we LP-problemen in de standaardvorm: In deel 1 hebben we een grafische oplossingsmethode voor LP-problemen besproken. We zullen nu een effectieve een oplossingsmethode voor dit soort stelsels bespreken. Deze zogenaamde Simplex-methode in 1947 bedacht door G. von Dantzig.

29
Voorbeeld 1. De Simplexmethode
Laten we eens een voorbeeld handmatig doorrekenen: Dit is een LP-probleem in standaardvorm.

30
1. De Simplexmethode Als eerste willen we de lineaire ongelijkheden ombouwen naar lineaire gelijkheden. Dit doen we met de volgende truck. We merken op dat: Voor de eerste restrictie: geldt dus dat het rechterlid altijd iets positief is, of minimaal nul als alle variabelen nul zijn. Het verschil: is dus ook altijd niet-negatief. Als we nu definiëren: dan geldt dus blikbaar dat: Deze observatie gaat op voor elk van de 3 restricties.

31
1. De Simplexmethode

32
1. De Simplexmethode

33
1. De Simplexmethode

34
1. De Simplexmethode

35
1. De Simplexmethode

36
1. De Simplexmethode

37
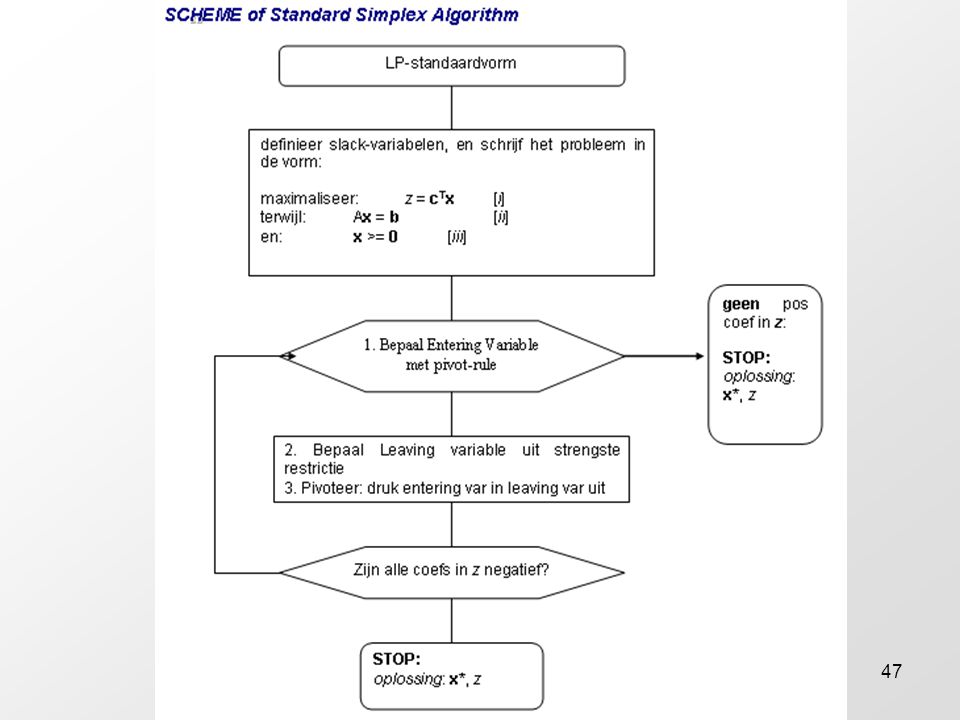
Generalisatie: De Simplex methode in zes stappen
We proberen de aanpak van het bovenstaande voorbeeld nu generaliseren. Dit is een beschrijving van het Simplex-algorithme. We zullen dit Simplex-algorithme nu in zes stappen beschrijven: stap 1: definieer restvariabelen Voor elke van de m constraints Ci voeren we een nieuwe variabele in. We nummeren door vanaf n dus dit zijn de variabelen xn+1, xn+2, ..., xn+m .Deze zg restvariabelen (eng: slack variables) zijn gedefinieerd als: voor i=1.. m. De eerdere variabelen heten de beslissings-variabelen (decision variables). Vanwege de i-e constraint Ci geldt dan :
 zijn gedefinieerd als: voor i=1.. m. De eerdere variabelen heten de beslissings-variabelen (decision variables). Vanwege de i-e constraint Ci geldt dan :")
38
Generalisatie: De Simplex methode in zes stappen
stap 2: herschrijf LP-standaardvorm naar dictionairies Ons stelsel heeft nu de vorm: maximaliseer: z = c1x1 + c2x cnxn onder restricties: C’i : , voor: i = 1 .. m. en: Verder leggen wij onszelf een beperking op: we zullen voorlopig slechts problemen beschouwen waarvoor: x1 = 0; x2 = 0; ... xn = 0; een toegestane oplossing is. Dit maakt het navolgende verhaal eenvoudiger, en doet niets af aan de algemene gedachte achter de Simplex-methode.

39
Generalisatie: De Simplex methode in zes stappen

40
Generalisatie: De Simplex methode in zes stappen
stap 3: initialisatie: kies een toegestane oplossing Kies initiële waarden voor de variabelen x1 = 0, x2 = 0, ..., xn = 0. Met bovenstaande restrictie voldoet deze keuze aan alle constraints. De waarden voor de slack-variabelen volgen uit de restricties en zullen i.h.a. niet-nul zijn. Daardoor is de startwaarde van:

41
Generalisatie: De Simplex methode in zes stappen
stap 4: bepaal de sterkste invloed op z Welke van de variabelen x1, x2, ..., xn+m doet de doelfunctie z het meest toenemen vanuit de huidige waarde? Het is duidelijk dat de variabele met de grootste coëfficiënt ci de waarde van z het meeste doet toenemen. Dus we zoeken de variabele met de index: k* = arg max k ck. Dit kunnen er in principe meerdere zijn. In dat geval bepalen we een tie break rule. Bijvoorbeeld min, max of rand. Dus, b.v.: j = min arg max k ck. Stel nu dat: Daar: , kan z alleen maar afnemen t.o.v. de waarde . M.a.w is de maximale – en dus de gezochte – oplossing.

42
Generalisatie: De Simplex methode in zes stappen

43
Generalisatie: De Simplex methode in zes stappen

44
Generalisatie: De Simplex methode in zes stappen

45
Generalisatie: De Simplex methode in zes stappen
De Simplex iteratie We kunnen nu de stappen 4 t/m 6 weer herhalen op de nieuwe basis, dictionaires, en uitdrukking voor z. Zoals al aangegeven in stap 4 stopt het proces – dus de iteratie als: De waarden van geven dan de optimale oplossing.

46
Generalisatie: De Simplex methode in zes stappen
Samenvatting Het feitelijke Simplex algoritme bestaat uit de volgende onderdelen: Initialisatie (stap 3) Iteratie (stap 4, 5, 6) Terminatie (in stap 4: ) Meteen rijzen er een aantal vragen: leidt het Simplex-algorithme altijd naar de juiste oplossing? vinden we de oplossing altijd in een eindig aantal iteraties?
 Iteratie (stap 4, 5, 6) Terminatie (in stap 4: ) Meteen rijzen er een aantal vragen: leidt het Simplex-algorithme altijd naar de juiste oplossing vinden we de oplossing altijd in een eindig aantal iteraties")
48
Inleiding Besliskunde EINDE LEZING 1

49
2. Convergentie en optimaliteit van de Simplexmethode
Werkt de Simplexmethode altijd? * Wordt altijd de optimale oplossing gevonden? * In hoeveel stappen wordt de oplossing gevonden als functie van de grootte van het probleem? * Maakt het wat uit welke ‘entering variable’ we kiezen? * Wat als de beginwaarde (0,0,0,...,0) niet werkt?
 niet werkt")
50
2. Valkuilen van de Simplexmethode
In dit onderdeel beschouwen we de efficiëntie van de Simplex-methode. Onder welke voorwaarden bestaat er een oplossing, en vinden we deze altijd in een eindig aantal iteraties? Of kan het voorkomen dat het Simplex-algorithme blijft ‘hangen’, en zo ja, onder welke voorwaarden. We beginnen met enkele definities om daarmee de hoofdstelling van lineair programmeren te kunnen formuleren..

51
2. Valkuilen van de Simplexmethode
Definities Beschouw de verzameling van lineaire restricties in matrix vorm: A x = b. Hierin is: x = (x1, x2, .., xn+m), b = (b1, b2, .., bm), en A een mx(n+m)-matrix. We kunnen matrix A schrijven als een matrix van kolom-vectoren: A = (a1, a2, .., an+m). De verzameling van indices van de basis-variabelen noemden we B en van de rest N. Dus bevat B: m elementen, en N: n elementen.
, b = (b1, b2, .., bm), en A een mx(n+m)-matrix. We kunnen matrix A schrijven als een matrix van kolom-vectoren: A = (a1, a2, .., an+m). De verzameling van indices van de basis-variabelen noemden we B en van de rest N. Dus bevat B: m elementen, en N: n elementen.")
52
2. Valkuilen van de Simplexmethode
Definities We kunnen met deze notatie een oplossing als volgt schrijven: We kunnen nu een partitie (verdeling) maken voor bovenstaande vectoren en matrices. We verdelen x in een basis-deel xB en een niet-basis-deel als volgt: , deze bevat dus m componenten. , deze bevat dus n componenten. Merk op dat:
 maken voor bovenstaande vectoren en matrices. We verdelen x in een basis-deel xB en een niet-basis-deel als volgt: , deze bevat dus m componenten. , deze bevat dus n componenten. Merk op dat:")
53
2. Valkuilen van de Simplexmethode
Definities We definiëren nu een basis-oplossing als volgt: Definitie 3.1: Een basis-oplossing van een stelsel Ax = b is een vector x met: xN = 0 (d.i. een n-dimensionale nul-vector). Dat betekent dat x een vorm heeft als (a b ... c )T, met a, b, etc – in principe – niet-nul in het basis-gedeelte, en de nullen in het niet-basis-gedeelte xN. Wegens geldt voor een basis-oplossing:
. Dat betekent dat x een vorm heeft als (a b ... c )T, met a, b, etc – in principe – niet-nul in het basis-gedeelte, en de nullen in het niet-basis-gedeelte xN. Wegens geldt voor een basis-oplossing:")
54
2. Valkuilen van de Simplexmethode
Definities Een basis-oplossing heet ontaard als geldt: Definitie: Een basis-oplossing x van een stelsel Ax = b heet ontaard als xB componenten bevat die nul zijn. Dat betekent dat nu het basis-gedeelte ook nullen bevat, b.v. als: x = (a b ... c )T, dan zijn onder de variabelen a, b, etc één of meerdere nullen.
T, dan zijn onder de variabelen a, b, etc één of meerdere nullen.")
55
2. Valkuilen van de Simplexmethode
Definities Beschouw nu het volgende stelsel: We definiëren nu het begrip toegelaten als volgt: Definitie: Als x aan i én ii voldoet heet het een toegelaten oplossing. Definitie: Als x aan i maar niet aan ii voldoet heet het een niet-toegelaten oplossing. Definitie: Een basis-oplossing xB die aan i én ii voldoet heet een toegelaten basis-oplossing, dan is dus: Definitie: Een basis-oplossing xB die niet voldoet aan: heet een niet-toegelaten basis-oplossing.

56
2. Valkuilen van de Simplexmethode
Hoofdstelling van de lineaire programmering Om iets te zeggen over de eindigheid van het Simplex-algorithme definieren we nu de hoofdstelling van de lineaire programmering. Beschouw een herschreven standaardvorm van een LP-probleem. We nemen nu aan de rang van A gelijk n is. Indien x hieraan voldoet en de objectfunctie z maximaliseert wordt het de optimale toegelaten oplossing genoemd. In het geval van een basisoplossing spreken we van een optimale toegelaten basis-oplossing.

57
2. Valkuilen van de Simplexmethode
Hoofdstelling van de lineaire programmering De hoofdstelling van LP luidt nu:indien er een toegelaten oplossing van 4.1 bestaat, dan bestaat er ook een toegelaten basis-oplossing. indien er een optimale toegelaten oplossing van 4.1 bestaat, dan bestaat er ook een optimale toegelaten basis-oplossing. Met behulp van deze stelling is het mogelijk om het zoekproces naar de optimale oplossing aanzienlijk te verkorten. Immers kunnen we ons beperken tot toegelaten basis-oplossingen, d.w.z. oplossingen met allemaal nullen in het niet-basis-gedeelte. indien er een toegelaten oplossing van het probleem bestaat, dan bestaat er ook een toegelaten basis-oplossing. indien er een optimale toegelaten oplossing van het probleem bestaat, dan bestaat er ook een optimale toegelaten basis- oplossing.

58
2. Valkuilen van de Simplexmethode
Hoofdstelling van de lineaire programmering Met behulp van de hoofdstelling van LP is het mogelijk om het zoekproces naar de optimale oplossing aanzienlijk te verkorten. Immers kunnen we ons beperken tot toegelaten basis-oplossingen, d.w.z. oplossingen met allemaal nullen in het niet-basis-gedeelte. Dit klinkt erg aantrekkelijk, want er zijn maar eindig veel basis-oplossingen. Immers, volgens bovenstaande kan iedere basis-oplossing uniek geschreven worden uit slechts m van de n kolommen van matrix A. Dit kan op slechts: manieren. Hoewel, ‘slechts’ is hier niet op zijn plaats. Voor een – in praktische gevallen – klein probleem als n = 20 en m = 10 geeft dit mogelijke basis-oplossingen. Al deze mogelijkheden zouden nagelopen moeten worden. Het is duidelijk dat zo’n aanpak geen enkele praktische waarde heeft. De Simplex-methode maakt echter zeer efficiënt gebruik van de hoofdstelling, doordat niet alle toegelaten basis-oplossingen doch slechts een klein deel hiervan op een systematische wijze worden onderzocht.

59
2. Valkuilen van de Simplexmethode
Eindigheid en Cycling Tot nu toe hebben we bewust ‘eenvoudige’ gevallen bekeken, waarin het Simplex-algorithme in een eindig aantal iteratiestappen naar een optimale oplossing convergeert. Laten we nu de drie onderdelen van het Simplex-algorithme beschouwen waarin problemen zouden kunnen ontstaan t.o.v. convergentie of eindigheid. We beschouwen drie stadia van het algoritme. Initialisatie: lukt het altijd om een toegelaten oplossing te vinden? Iteratie: Kunnen we altijd een entering en een leaving variabele vinden, en te ‘pivoteren’. Terminatie: Kan het gebeuren dat het algoritme oneindig doorgaat zonder ooit een oplossing te bereiken? We zullen nu deze stadia een voor een bespreken.

60
2. Valkuilen van de Simplexmethode
Initialisatie Door onze zelf-opgelegde restrictie beginnen we met een vorm als: x0 = (a b ... c )T. Het zou natuurlijk kunnen dat deze begin waarden niet aan de constraints voldoet, m.a.w. dat Ax niet b is. Later zullen we daarom de 2-fasen Simplexmethode bespreken waarin ook een andere start-oplossing mogelijk wordt – tenminste als die bestaat. Er blijft dus de mogelijkheid dat een LP-probleem geen oplossing heeft, namelijk omdat er geen enkele x bestaat met Ax = b!
T. Het zou natuurlijk kunnen dat deze begin waarden niet aan de constraints voldoet, m.a.w. dat Ax niet b is. Later zullen we daarom de 2-fasen Simplexmethode bespreken waarin ook een andere start-oplossing mogelijk wordt – tenminste als die bestaat. Er blijft dus de mogelijkheid dat een LP-probleem geen oplossing heeft, namelijk omdat er geen enkele x bestaat met Ax = b!")
61
2. Valkuilen van de Simplexmethode
Iteratie Bij de mogelijkheid binnen een iteratiestap zijn drie aspecten van belang: het vinden van een entering variabele: deze stap is eenduidig geregeld als: k* = arg max k ck het vinden van een leaving variabele: hier kunnen we een restrictie vinden aan de bovengrens van de entering variabele. Als dat echter niet lukt, dan is er geen boven-grens, en is het probleem onbegrensd (unbounded). In dit geval moeten we het algoritme beëindigen; er is geen oplossing. We zouden in deze stap ook kunnen vinden dat de entering variabele x voldoet aan bijvoorbeeld: x < -3. Ook in dat geval is er geen oplossing, omdat we weten dat x moet voldoen aan: x > 0. Ook dan sluiten we af.
. In dit geval moeten we het algoritme beëindigen; er is geen oplossing. We zouden in deze stap ook kunnen vinden dat de entering variabele x voldoet aan bijvoorbeeld: x < -3. Ook in dat geval is er geen oplossing, omdat we weten dat x moet voldoen aan: x > 0. Ook dan sluiten we af.")
62
2. Valkuilen van de Simplexmethode
Iteratie degeneratie: als de entering variabele t.g.v. de restricties de waarde nul verkrijgt, dan is het probleem dus volgens de definitie ontaard of gedegenereerd. Het directe gevolg is dat z niet toeneemt in deze iteratiestap. Immers, de toename van z is meteen gekoppeld aan de toename van de entering variabele. Het kan voorkomen dat het algoritme een serie van zulke ontaarde stappen achterelkaar doormaakt, en dat het daarna weer ‘goed’ verder gaat.

63
2. Valkuilen van de Simplexmethode
Terminatie Het kan inderdaad voorkomen dat het terminatiecriterium nooit actief wordt, en de iteratie dus oneindig lang duurt. Maar er kan (eenvoudig) bewezen worden dat: Dit verschijnsel is echter zeer zeldzaam en zal in de praktijk niet voorkomen. Stelling : Als het Simplex-algoritm niet eindigt dan bevindt het zich in een oneindig herhalende cyclus.
 bewezen worden dat: Dit verschijnsel is echter zeer zeldzaam en zal in de praktijk niet voorkomen. Stelling : Als het Simplex-algoritm niet eindigt dan bevindt het zich in een oneindig herhalende cyclus.")
64
2. Valkuilen van de Simplexmethode
Efficiëntie en Snelheid Voor een Simplex-probleem met n variabelen en m restricties vindt men empirisch voor het aantal iteraties grofweg: aantal iteraties ~ 1.5 m log n [Dantzig, 1963]. Merk op dat het aantal iteraties nauwelijks toeneemt met n. Bijvoorbeeld bij een probleem met n = 10 en m = 10, leidt een toename van het aantal variabelen naar 100 ‘slechts’ tot een verdubbeling van het aantal iteraties, terwijl eenzelfde toename van het aantal restricties het aantal iteraties vertienvoudigt. Als men dus de keuze heeft, kan men beter veel variabelen definiëren en weinig restricties.

65
2. Valkuilen van de Simplexmethode
Efficiëntie en Snelheid We hebben boven gezien dat er problemen bestaan die cyclisch zijn – d.w.z. na enige tijd wederom in de begintoestand terugkeren – en dus oneindig lang duren. Zijn er nu ook ‘gewone’ LP-problemen die zeer lang duren, zonder dat er sprake is van een cyclus? Deze bestaan inderdaad, een voorbeeld zijn de zogenaamde Klee-Minty-problemen [V. Klee, G. Minty, 1972].

66
2. Valkuilen van de Simplexmethode
Klee-Minty-problemen Beschouw het volgende probleem met n variabelen en n restricties: Klee en Minty toonden voor deze problemen aan dat zij 2n – 1 iteratiestappen vergen. Bijvoorbeeld het Klee-Minty-probleem met n = 50 (een relatief klein LP-probleem) zou met 100 iteraties/seconde meer dan jaar nodig hebben voor het vinden van de oplossing. In het boek: Introduction to LP, Chvátal, pag. 47 e.v. is het voorbeeld met n=3 beschreven. Deze heeft 23-1 = 7 stappen nodig voor de oplossing.
 zou met 100 iteraties/seconde meer dan jaar nodig hebben voor het vinden van de oplossing. In het boek: Introduction to LP, Chvátal, pag. 47 e.v. is het voorbeeld met n=3 beschreven. Deze heeft 23-1 = 7 stappen nodig voor de oplossing.")
67
2. Valkuilen van de Simplexmethode
Alternatieve Pivoting-Rules Tot nu toe hanteerden we bij de keuze voor de entering variabele de vuistregel: regel 1: “Kies de variabele met de grootste coëfficiënt in de regel voor z”. Dit leidde bij Klee-Minty-problemen van orde n tot 2n-1 iteraties. Beschouw nu de volgende vuistregel: regel 2: “Kies de variabele die de grootste toename in z veroorzaakt”. Merk op dat we daartoe voor elke (positieve) coëfficiënt in z de resulterende toename in z moeten berekenen. Toepassing van deze regel op het Klee-Minty-problemen van orde 3 in het voorbeeld van Chvátal – pag. 47 e.v. leidt tot: 1 iteratiestap! Maar ook deze regel heeft een Achilleshiel: Jeroslav [Jeroslav,1973] gaf een voorbeeld waarin deze regel een exponentieel aantal iteraties gaf – net als in het Klee-Minty-voorbeeld voor regel 1.
 coëfficiënt in z de resulterende toename in z moeten berekenen. Toepassing van deze regel op het Klee-Minty-problemen van orde 3 in het voorbeeld van Chvátal – pag. 47 e.v. leidt tot: 1 iteratiestap! Maar ook deze regel heeft een Achilleshiel: Jeroslav [Jeroslav,1973] gaf een voorbeeld waarin deze regel een exponentieel aantal iteraties gaf – net als in het Klee-Minty-voorbeeld voor regel 1.")
68
2. Valkuilen van de Simplexmethode
Alternatieve Pivoting-Rules Vuistregels als hierboven heten pivotting-rules. Hoewel i.h.a. regel 2 minder iteraties veroorzaakt dan regel 2, is de extra check zo tijdrovend dat regel 1 bij implementatie toch weer sneller is. Daarom kiest men bij implementatie vaak de volgende vuistregel: regel 3: “Kies een willekeurige variabele met positieve coëfficiënt in de uitdrukking voor z”. Meestal kiest men dan degene met de kleinste index.

69
2. Valkuilen van de Simplexmethode
Infeasible Dictionaries Tot nu toe legden we ons zelf een restrictie op: in de eerste iteratie stap moest xN = 0 een mogelijke oplossing zijn. Dat wil zeggen, dat als we in de standaardvorm van het originele probleem alle beslissingsvariabelen gelijk aan nul mogen stellen. Dit hoeft niet altijd het geval te zijn, bijvoorbeeld x1 + x2 < -5 kan niet, want invulling van met x1, x2 = 0 geeft: 0 < -5, hetgeen onwaar is. Nu zullen we met behulp van de twee-fasen Simplex-methode leren dergelijk problemen op te lossen.

70
2. Valkuilen van de Simplexmethode
Mogelijke oplossingen en mogelijke dictionaires Als we in een dictionaire van een LP-probleem alle niet-basisvariabelen aan de rechterkant gelijk aan nul stellen, verkrijgen we voor de basis-variabelen aan de linkerkant een mogelijke oplossing (eng: feasible solution). Als echter een dictionaire op deze wijze negatieve waarden zou geven voor de basisvariabelen, dan noemen we het een onmogelijke dictionaire (eng: infeasible dictionary).
. Als echter een dictionaire op deze wijze negatieve waarden zou geven voor de basisvariabelen, dan noemen we het een onmogelijke dictionaire (eng: infeasible dictionary).")
71
2. Valkuilen van de Simplexmethode
Feasible Dictionaries, Voorbeeld: Merk op dat zo’n stelsel wel een oplossing zou kunnen hebben. We kunnen het alleen met onze standaard-Simplexmethode niet vinden.

72
2. Valkuilen van de Simplexmethode
Hulp-variabelen en het hulp-probleem Stel dat we een LP-probleem met een infeasible dictionary hebben in de standaardvorm: Dat betekent dat onder de componenten van b negatieve elementen zijn. Stel dat we nu de rechterkant van de restricties zoveel zouden verhogen dat er wel een feasible dictionary zou ontstaan. Met andere woorden, wat is de kleinste x0 waarvoor x = 0 wel een oplossing is van:

73
2. Valkuilen van de Simplexmethode
Hulp-variabelen en het hulp-probleem Anders gezegd: Dit heet het hulp-probleem (eng: auxiliary problem) van het originele infeasible probleem. De variabele x0 heet de hulp-variabele (eng: auxiliary variable).
 van het originele infeasible probleem. De variabele x0 heet de hulp-variabele (eng: auxiliary variable).")
74
2. Valkuilen van de Simplexmethode
Hulp-variabelen en het hulp-probleem We kunnen dit ook in de LP-standaardvorm schrijven:

75
2. Valkuilen van de Simplexmethode
Hulp-variabelen en het hulp-probleem Of na invoering van de slack-variabelen in dictionaire-vorm: Ga na dat deze dictionaire nog steeds infeasible is.

76
2. Valkuilen van de Simplexmethode
Hulp-variabelen en het hulp-probleem Toch kunnen we dit stelsel met een enkele stap omzetten in een feasible dictionary. Kies namelijk: entering variabele: x0 leaving variabele: x[n+i*], met: i* = arg mini b[i] We hebben dus de meest negatieve constante uit vector b gekozen om de leaving variabele te bepalen.

77
2. Valkuilen van de Simplexmethode
Hulp-variabelen en het hulp-probleem Het gevolg is dat bij de spil-operaties er een nieuwe dictionaire ontstaat met alleen positieve constanten. Immers, we nemen de dictionaire die x0 en x[i*] bevat, en brengen x0 naar links: we substitueren dit in de andere dictionaires: , voor i = 1,...,m Merk op dat: bi – b[i*] altijd niet-negatief is omdat we expres met b[i*] de ‘negatiefste’ component uit b hebben gekozen.

78
2. Valkuilen van de Simplexmethode
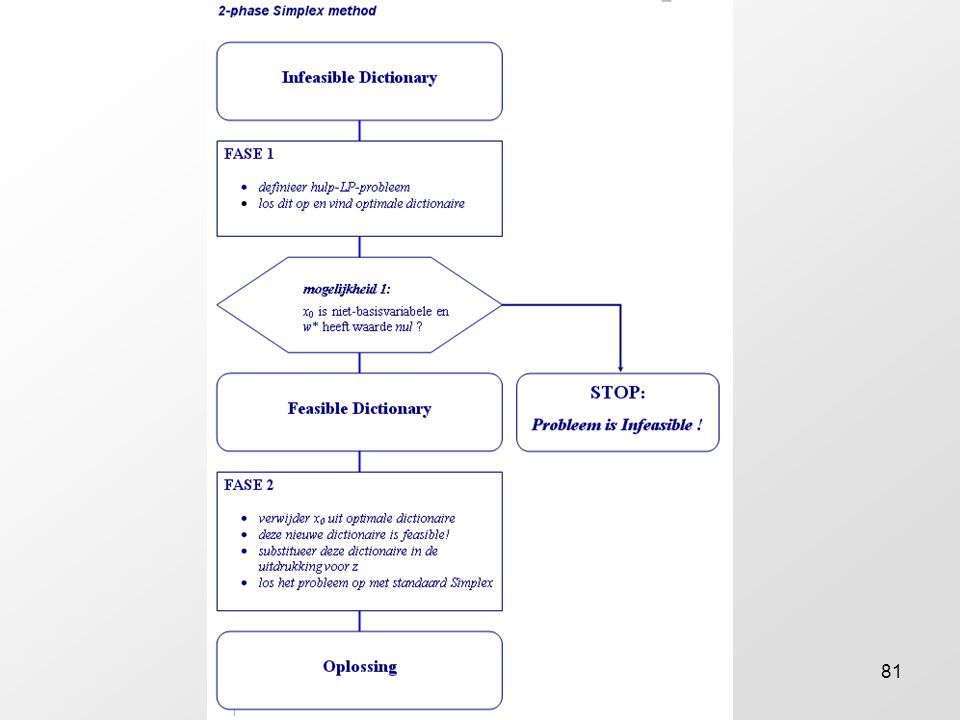
Hulp-variabelen en het hulp-probleem Nu hebben we dus een mogelijke dictionaire (feasible dictionary) verkregen. We kunnen nu dus verder met de standaard-Simplexmethode, en kunnen we trachten het probleem op te lossen. We noemen de uitkomst dan een optimale dictionaire. Er kunnen zich echter dan slechts één van de volgende twee mogelijkheden voordoen: mogelijkheid 1: x0 is niet-basisvariabele en w* heeft waarde nul. mogelijkheid 2: x0 is basisvariabele en w* heeft een waarde niet gelijk aan nul. In het eerste geval weten we dus dat w = -x0 de optimale oplossing is. Dat betekent dat de restricties van het hulpprobleem geheel identiek zijn aan de restricties van het originele probleem.
 verkregen. We kunnen nu dus verder met de standaard-Simplexmethode, en kunnen we trachten het probleem op te lossen. We noemen de uitkomst dan een optimale dictionaire. Er kunnen zich echter dan slechts één van de volgende twee mogelijkheden voordoen: mogelijkheid 1: x0 is niet-basisvariabele en w* heeft waarde nul. mogelijkheid 2: x0 is basisvariabele en w* heeft een waarde niet gelijk aan nul. In het eerste geval weten we dus dat w = -x0 de optimale oplossing is. Dat betekent dat de restricties van het hulpprobleem geheel identiek zijn aan de restricties van het originele probleem.")
79
2. Valkuilen van de Simplexmethode
Hulp-variabelen en het hulp-probleem We kunnen dus de optimale dictionaire van het hulpprobleem in zijn uiteindelijke vorm nemen, daaruit x0 geheel verwijderen (deze is toch 0), en dan de uitdrukkingen in die dictionaire invullen in de oorspronkelijke uitdrukking voor z. Dit nieuwe stelsel is dan feasible (dus het basis-deel der variabelen mag nul gesteld worden) en dus kunnen we dat met standaard-Simplex verder oplossen! In het tweede geval concluderen we dat het stelsel in het geheel infeasible is, en dus niet oplosbaar.
, en dan de uitdrukkingen in die dictionaire invullen in de oorspronkelijke uitdrukking voor z. Dit nieuwe stelsel is dan feasible (dus het basis-deel der variabelen mag nul gesteld worden) en dus kunnen we dat met standaard-Simplex verder oplossen! In het tweede geval concluderen we dat het stelsel in het geheel infeasible is, en dus niet oplosbaar.")
80
2. Valkuilen van de Simplexmethode
Het twee-fasen Simplex-algoritme Deze aanpak heet de twee-fasen-Simplexmethode. In de eerste fase stellen we het hulp-probleem op, en lossen we dat op. Als de resulterende optimale dictionaire voldoet aan mogelijkheid 1 dan gaan we naar de tweede fase: verwijderen x0 en lossen het stelsel op met standaard-Simplex. In geval van mogelijkheid 2 concluderen we dat het originele probleem in het geheel infeasible is. Hieronder is een schematisch voorstelling van het twee-fasen-Simplexalgoritme gegeven in de vorm van een stroomdiagram.

82
2. Valkuilen van de Simplexmethode
Relatie tot de geometrische interpretatie We kunnen nu de relatie leggen tot de geometrische interpretatie van de eerste lezing:

83
2. Valkuilen van de Simplexmethode
Relatie tot de geometrische interpretatie De normale feasible dictionary is de reguliere geometrische situatie waar het criterium het convexe gebied op één punt uitschuift.

84
2. Valkuilen van de Simplexmethode
Relatie tot de geometrische interpretatie De infeasible dictionary is de situatie waar het convexe gebied geen oplossing toestaat door bv niet in het eerste kwadrant te liggen.

85
2. Valkuilen van de Simplexmethode
Relatie tot de geometrische interpretatie De onbegrensde situatie geeft oplossingen ‘oneindig’, bv: max x s.t. x ≥ 0.

86
2. Valkuilen van de Simplexmethode
Relatie tot de geometrische interpretatie De ontaarde (gedegenereerde) geometrische situatie komt overeen met de ontaarde oplossing in de Simplexmethode waar minimaal één basisvariabele nul is.
 geometrische situatie komt overeen met de ontaarde oplossing in de Simplexmethode waar minimaal één basisvariabele nul is.")
87
Inleiding Besliskunde EINDE LEZING 2

88
3. Dualiteit en Matrixformulatie
Computationeel complexe problemen toch kunnen oplossen * Elk LP-probleem heeft een “spiegelprobleem”: de duale LP * Computationeel “zware” primale LPs hebben (cq kunnen hebben) eenvoudige duale LPs * Zwakke en sterke dualiteit * De “algemene” Simplex-methode in matrixformulatie
 eenvoudige duale LPs. * Zwakke en sterke dualiteit. * De algemene Simplex-methode in matrixformulatie.")
89
3. Dualiteit en matrixvorm
Primale en Duale LP problemen In dit onderdeel beginnen we met het schatten van de oplossing van een LP-probleem (ipv het exact berekenen) . Het zal blijken dat we de oplossing (van het criterium z) kunnen inperken tussen een laagst-mogelijke en hoogst-mogelijke waarde Door die schatting te “optimaliseren” kunnen we een algemene aanpak formuleren die bij elk LP-probleem (noem het “het eerste” of in Latijn: “het primale”) een ander LP-probleem definieert (het “tweede” oftewel in Lingua Latina: “duale”).
 . Het zal blijken dat we de oplossing (van het criterium z) kunnen inperken tussen een laagst-mogelijke en hoogst-mogelijke waarde. Door die schatting te optimaliseren kunnen we een algemene aanpak formuleren die bij elk LP-probleem (noem het het eerste of in Latijn: het primale ) een ander LP-probleem definieert (het tweede oftewel in Lingua Latina: duale ).")
90
3. Dualiteit en matrixvorm
Schatting voor bovengrens van criterium z Stel we willen een bovengrens afschatten voor de oplossing van het criterium z van een LP-probleem. Voorbeeld:

91
3. Dualiteit en matrixvorm
Schatting voor bovengrens van criterium z Het schatten van een ondergrens voor de oplossing van het criterium z van een LP-probleem is niet moeilijk (waarom niet?). Elke toegestane oplossing xtrial geeft een bijbehorende waarde van ztrial. Daar de optimale oplossing z* de grootst mogelijke oplossing is, is z* ≥ ztrial , dus ztrial is een ondergrens de oplossing.
. Elke toegestane oplossing xtrial geeft een bijbehorende waarde van ztrial. Daar de optimale oplossing z* de grootst mogelijke oplossing is, is z* ≥ ztrial , dus ztrial is een ondergrens de oplossing.")
92
3. Dualiteit en matrixvorm
Schatting voor bovengrens van criterium z Maar hoe kunnen we een bovengrens voor z schatten? Merk op dat als we de tweede restrictie vermenigvuldigen met 5/3 we verkrijgen: Merk ook op dat dit term-voor-term groter-of-gelijk is dan de overeenkomstige term in z: 4 ≤ 25/3, 1 ≤ 5/3, 5 ≤ 5, 3 ≤ 40/3.

93
3. Dualiteit en matrixvorm
term-voor-term is z kleiner-of-gelijk aan de overeenkomstige term in 5/3 x restrictie #2: z: 4 ≤ 25/3, 1 ≤ 5/3, 5 ≤ 5, 3 ≤ 40/3. Verder is nog steeds voldaan aan: Dus: Dus 275/3 is een bovengrens van z !

94
3. Dualiteit en matrixvorm
Op analoge manier kunnen we de tweede en derde restrictie optellen, en verkrijgen we: Daarvoor geldt analoog aan bovenstaande overweging: Dus zestimate = 58 is een betere schatting voor de bovengrens van z.

95
3. Dualiteit en matrixvorm
We kunnen deze aanpak generaliseren. Laten we kijken naar lineaire combinaties van de drie restricties R1, R2, en R3. Hiervoor hebben we drie multiplicatoren y1, y2, en y3 nodig. Deze moeten positief zijn, want anders ‘klapt’ het ongelijkheidsteken om: We verkrijgen nu: R1 R2 R3

96
3. Dualiteit en matrixvorm
Analoog aan onze bovenstaande overweging kan dit alleen een bovengrens geven voor : als geldt:

97
3. Dualiteit en matrixvorm
→ Als dat het geval is, dan vinden we voor de bovengrens van z de multiplicatoren y keer de constanten aan de rechterkant van de ongelijkheden R: Dit geldt in het bijzonder voor de optimale oplossing z*, oftewel:

98
3. Dualiteit en matrixvorm
primale We willen een zo klein mogelijke bovengrens te weten komen terwijl. Dit leidt tot het volgende LP-probleem: Dit noemen we het duale probleem van het oorspronkelijke probleem. Het oorspronkelijke probleem wordt dan wel het primale probleem genoemd. duale

99
3. Dualiteit en matrixvorm
primale duale Merk op dat we van 4 variabelen en 3 restricties zijn gegaan naar 3 variabelen met 4 restricties. Voordelen: elke oplossing van de duale geeft een schatting voor de bovengrens van z van de primale. wellicht is het duale probleem makkelijker oplosbaar: rekentijd ≈ 1.5 m log n wordt dan: ≈ 1.5 n log m.

100
3. Dualiteit en matrixvorm
Het Duale Probleem We kunnen deze aanpak generaliseren naar willekeurige LP-problemen. Eerst definiëren we de LP- standaardvorm met matrix a = (aij) en vectoren b en c als: Het duale probleem van LP(a,b,c) is nu gedefinieerd:
 en vectoren b en c als: Het duale probleem van LP(a,b,c) is nu gedefinieerd:")
101
3. Dualiteit en matrixvorm
LP- standaardvorm met matrix a = (aij) en vectoren b en c als: En zo is dus het duale probleem van LP(a,b,c) nu gedefinieerd. Nu geldt dat voor elke mogelijke oplossing x van het primale probleem LP(a,b,c) en elke mogelijke oplossing y van het duale systeem de volgende relatie geldt: Voor de optimale oplossingen x* en y* van de systemen geldt zelfs: .
 en vectoren b en c als: En zo is dus het duale probleem van LP(a,b,c) nu gedefinieerd. Nu geldt dat voor elke mogelijke oplossing x van het primale probleem LP(a,b,c) en elke mogelijke oplossing y van het duale systeem de volgende relatie geldt: . Voor de optimale oplossingen x* en y* van de systemen geldt zelfs: .")
102
3. Dualiteit en matrixvorm
Nog krachtiger is de dualiteits-stelling:

103
3. Dualiteit en matrixvorm
Relatie tussen het Primale en Duale SysteemDuale Probleem Merk op dat we dit duale probleem ook kunnen schrijven als een maximaliseringsprobleem: Dus het duale probleem van LP(a,b,c) is: LP(-aT,-c,-b). Merk op dat de duale van de duale wederom het oorspronkelijke primale probleem is, want: de duale van de duale is: LP(-(-aT) T,-(-b),-(-c)) = LP(a,b,c) .
 is: LP(-aT,-c,-b). Merk op dat de duale van de duale wederom het oorspronkelijke primale probleem is, want: de duale van de duale is: LP(-(-aT) T,-(-b),-(-c)) = LP(a,b,c) .")
104
3. Dualiteit en matrixvorm
Relatie tussen het Primale en Duale SysteemDuale Probleem Verder is eenvoudig in te zien dat de volgende equivalenties gelden:

105
3. Dualiteit en matrixvorm
Interpretatie van Duale Probleem In de econometrie bestaat een duidelijke interpretatie aan de duale oplossing. Namelijk; yi stelt de kosten per eenheid van ‘soort’ i voor. Stel we hebben een LP-probleem LP(a,b,c) met oplossing z* en laat y* de optimale oplossing zijn van het duale probleem LP(-aT,-c,-b). Stel dat we b met een kleine vector e laten toenemen (klein vergeleken met b). Dan is de oplossing van: LP(a,b,c) gelijk aan: z + y*Te. Voorbeeld: voorbeeld van de calculerende houthakker [Chvátal pag. 67,68].
 met oplossing z* en laat y* de optimale oplossing zijn van het duale probleem LP(-aT,-c,-b). Stel dat we b met een kleine vector e laten toenemen (klein vergeleken met b). Dan is de oplossing van: LP(a,b,c) gelijk aan: z + y*Te. Voorbeeld: voorbeeld van de calculerende houthakker [Chvátal pag. 67,68].")
106
3. Dualiteit en matrixvorm
Simplex-methode in Matrixvorm Symbolische matrixrepresentatie van het uitgebreide stelsel restricties We hebben in het eerste deel van de cursus geleerd hoe we stelsels van lineaire vergelijkingen kunnen oplossen met behulp van de Gauss-eliminatiemethode, oftewel het ‘vegen’ van matrices. Deze methode is ook bruikbaar binnen onze context van de Simplexmethode. Althans, als we eerst de vergelijkingen in een geschikte vorm brengen.

107
3. Dualiteit en matrixvorm
Simplex-methode in Matrixvorm Ons startpunt zijn de lineaire restricties inclusief de ‘slack’-variabelen gedurende de iteratie. Deze luiden volledig: Verder hebben we de doelfunctie z, deze luidt: z = c0 + c1x1 + c2x cn+mxn+m Hierbij stelt c0 de actuele waarde van z* voor – in de eerste stap is c0 = 0.

108
3. Dualiteit en matrixvorm
Simplex-methode in Matrixvorm We kunnen initieel deze stelsels op uniforme wijze weergeven als: Dit stelsel kunnen we symbolisch weergeven in de vorm van een matrix als:

109
3. Dualiteit en matrixvorm
Hierin zijn de volgende componenten te onderkennen: met: a de mxn matrix elementen afkomstig van de restricties, Em de mxm eenheidsmatrix – dwz de mxm matrix met overal nullen behalve op de diagonaal, de vector b afkomstig van de restricties, en de (m+n)-vector c uit de doelfunctie [waarvan aanvankelijk de laatste m componenten nul zullen zijn]. Tenslotte hebben we de negatieve waarde van het maximum van z: – z* = – c0 , dewelke aanvankelijk nul zal zijn.
-vector c uit de doelfunctie [waarvan aanvankelijk de laatste m componenten nul zullen zijn]. Tenslotte hebben we de negatieve waarde van het maximum van z: – z* = – c0 , dewelke aanvankelijk nul zal zijn.")
110
3. Dualiteit en matrixvorm
Gauss-eliminatie en Simplexmethode voor matrixrepresentatie We kunnen de Simplexmethode nu definiëren in termen van de Gauss-eliminatie op deze representatie. Dit gaat als volgt:

111
3. Dualiteit en matrixvorm
Gauss-eliminatie en Simplexmethode voor matrixrepresentatie

112
3. Dualiteit en matrixvorm
Voorbeeld Laten we deze methode eens toepassen op een voorbeeld:

113
3. Dualiteit en matrixvorm
Voorbeeld

114
3. Dualiteit en matrixvorm
Voorbeeld

115
3. Dualiteit en matrixvorm
Duale in Gaus-Jordan vorm Merk op dat we eenvoudig de matrix van de duale van een probleem vinden als:

116
3. Dualiteit en matrixvorm
Het ‘revised Simplex-algorithm’ als algoritmische matrixmanipulaties Tenslotte behandelen we een matrix-representatie van de Simplex methode. Beschouw een LP-probleem met n beslissingsvariabelen, m ‘slack’-variabelen, en lineaire doelstellingsfunctie. Laten er bovendien m lineaire restricties als constraints gelden; met gegeven parameters aij, bi, cj (i = 1..m, j = 1..n) .
 .")
117
3. Dualiteit en matrixvorm
Dit probleem kunnen we kort en bondig weergeven in matrixnotatie:

118
3. Dualiteit en matrixvorm
De Simplex-iteratie bestaat uit successieve verbeteringen van de doelfunctie z door: (bv) selectie van de variabele die z het meest doet toenemen, en de dictionaire die de kleinste bovengrens aan die bewuste variabele stelt. De variabelen waarvoor een dictionaire bestaat noemen we de basis in die iteratiestap. De verzameling van indices van de basisvariabelen noemen we B, die van de niet-basisvariabelen noemen we N. Deze separatie voeren we nu uit in alle componenten van de bovengedefinieerde matrix en vectoren.
 selectie van de variabele die z het meest doet toenemen, en. de dictionaire die de kleinste bovengrens aan die bewuste variabele stelt. De variabelen waarvoor een dictionaire bestaat noemen we de basis in die iteratiestap. De verzameling van indices van de basisvariabelen noemen we B, die van de niet-basisvariabelen noemen we N. Deze separatie voeren we nu uit in alle componenten van de bovengedefinieerde matrix en vectoren.")
119
3. Dualiteit en matrixvorm
Merk op dat het aantal elementen van B gelijk is aan m, en van N gelijk aan n. Daarom is AN een mxn-matrix. Invulling in box 1 en verdere uitwerking van de vergelijkingen geeft:

120
3. Dualiteit en matrixvorm
bij het optimaliseringprobleem met in de nieuwe iteratiestap: Vanwege de hoofdstelling van LP volgt de bijbehorende oplossing x* in deze iteratiestap uit het nul stellen van x*N in box 4:

121
3. Dualiteit en matrixvorm
Met deze notatie is het mogelijk de stappen in het Simplex-algorithme te herschrijven. Bij elke iteratiestap gaan we uit van de volgende twee aannamen: Er is een partitie van de n+m indices in een verzameling B van m basis-variabelen en een verzameling N van n niet-basis-variabelen, zodanig dat matrix AB inverteerbaar is. Elke iteratiestap is er een oplossing: x = (xB , xN)T met: , en: xN = 0.
T met: , en: xN = 0.")
122
3. Dualiteit en matrixvorm
Het ‘revised Simplex-algorithm’ Het Simplex-algorithme in matrixvorm, genaamd het revised Simplex-algorithme, beslaat nu de volgende vijf stappen:

124
Inleiding Besliskunde EINDE LEZING 3

125
4. Practische voorbeelden
In dit laatste college zullen we een aantal toepassingen van Lineair Programmeren en de Simplexmethode beschouwen: een enkel voorbeeld en lineaire regressie

126
4.1 Praktische Voorbeelden van LP
Voorbeeld 1. Dieetproblematiek Op levensmiddelen staat vaak de samenstelling van het product in termen van mineralen en vitaminen vermeld. Vaak is dit weergegeven als ADH = Aanbevolen Dagelijkse Hoeveelheid. Onderstaande tabel geeft een voorbeeld.

127
Voorbeeld 1. Dieetproblematiek

128
Voorbeeld 1. Dieetproblematiek

129
Voorbeeld 1. Dieetproblematiek
Optimaal gezond menu samenstellen voor een geven persoon Stap 1: bepaal beslissingsparameters We kunnen de hoeveelheid in gram van voedingsproduct i dat de persoon tot zich neemt kunnen weergeven met een beslissingsparameter xi. Stap 2: bepaal optimaliseringscriterium= doelfunctie We willen minimaliseren de surplus hoeveelheid energieopname (de kcal). Stap 3: bepaal randvoorwaarden We willen dat de persoon minimaal zijn ADH’s aan mineralen, vitaminen en zijn dagelijks benodigde hoeveelheid verbrandingsenergie bekomt.
. Stap 3: bepaal randvoorwaarden. We willen dat de persoon minimaal zijn ADH’s aan mineralen, vitaminen en zijn dagelijks benodigde hoeveelheid verbrandingsenergie bekomt.")
130
Voorbeeld 1. Dieetproblematiek
Stel: qi is de energie per gram van voeding i Q is minimaal benodigde energie voor persoonsprofiel vij de hoeveelheid mineraal/vitamine j in voeding i aj is de ADH in gram van mineraal/vitamine i Zo vinden we: minimaliseer : terwijl voor i = 1..M: NB: merk op dat dit niet in LP-standaardvorm staat!

131
Voorbeeld 2. Optimale Mengverhouding
Beschouw het volgende probleem; Een fabriek maakt grondstoffen voor autoruiten. Het assortiment bestaat uit 30 mogelijke producten – ieder dus een grondstof voor autoruiten. Voor elk product bestaat een recept : het wordt samengesteld uit een aantal mineralen en andere (an)organische componenten, in een bepaalde gegeven verhouding. Als basismateriaal gebruikt de fabriek ruwe grondstoffen (raw materials) d.i. mengsels uit groeves over de gehele wereld. Elk van die mengsels heeft een bekende samenstelling aan mineralen en andere (an)organische componenten, en een prijs per kilogram. Elk recept heeft bovendien een maximum aan ongewenste componenten.
organische componenten, in een bepaalde gegeven verhouding. Als basismateriaal gebruikt de fabriek ruwe grondstoffen (raw materials) d.i. mengsels uit groeves over de gehele wereld. Elk van die mengsels heeft een bekende samenstelling aan mineralen en andere (an)organische componenten, en een prijs per kilogram. Elk recept heeft bovendien een maximum aan ongewenste componenten.")
132
Voorbeeld 2. Optimale Mengverhouding
Aanpak: Stap 1: bepaal beslissingsparameters We noemen beslissingsparameter xi de hoeveelheid in kilogram van mengsel i dat we gebruiken in het gevraagde recept. Stap 2: bepaal doelfunctie We willen minimaliseren de prijs van de receptuur. Stap 3: bepaal randvoorwaarden We willen dat de receptuur gehaald wordt, dat wil zeggen dat de benodigde kilo’s component in de receptuur aanwezig is.

133
Voorbeeld 2. Optimale Mengverhouding

134
Voorbeeld 2. Optimale Mengverhouding

135
Voorbeeld 2. Optimale Mengverhouding
Dit leidt tot de volgende LP-formulering :

136
4.2 Robust regression en Sparse Estimation
Toepassing van Simplexmethode op lineaire regressie lost eeuwenoud probleem op * Vind de “beste” lijn door een gegeven verzameling punten * Het least deviation problem * Gauss en Laplace vinden lineaire kleinste kwadratenmethode (LKK) * De Simplex-methode lost het oorspronkelijke probleem op * Deze vindt ook sparse solutions die LKK niet kan vinden
 * De Simplex-methode lost het oorspronkelijke probleem op. * Deze vindt ook sparse solutions die LKK niet kan vinden.")
137
Lineaire Regressie 4. Robuuste regressie
Het vinden van verbanden tussen meetgrootheden Bij de bestudering van praktische problemen, proberen we grootheden te vinden waarmee we het probleem adequaat kunnen beschrijven. Daartoe zullen we eerst data moeten verzamelen betreffende ons probleem. Dat kan door gericht in te grijpen op het systeem middels een experiment, of indirect via doen van waarnemingen.

138
Een voorbeeld 4. Robuuste regressie
Bij de bestudering van de prestatie van personenwagens kunnen we kijken naar de het vermogen, het verbruik per strekkende kilometer, de oliedruk en de kleur van de ogen van de chauffeur. Sommige van die grootheden zullen relevant zijn voor ons onderzoek, andere minder. Zo kun je op voorhand verwachten dat de kleur van de chauffeur’s ogen van weinig belang zal zijn. Een andere vraag is of er verbanden bestaan tussen de gemeten grootheden. Als er zo’n verband bestaat, dan kunnen we de ene grootheid voorspellen op grond van onze kennis van de andere, en een van deze grootheden weglaten – bijvoorbeeld de moeilijkst meetbare. In veel praktische gevallen zijn we dan ook geïnteresseerd in het vinden van verbanden tussen de gemeten grootheden. Uitgangspunt zal voor ons zijn een hoeveelheid data, waarin een groot aantal instanties van zulke grootheden staan. In tabel 1 staat een voorbeeld van zo’n verzameling data (engels: data set) betreffende enkele waarnemingen aan personenwagens (NB: fictief).
 betreffende enkele waarnemingen aan personenwagens (NB: fictief).")
139
4. Robuuste regressie Elke rij stelt een instantie voor, dat wil zeggen een volledige verzameling van grootheden voor een waargenomen object. Zo geeft wagen #4 een groene fiat uit 2004 weer. Elke kolom stelt een volledige verzameling van metingen voor van een grootheid. Zo is de zesde kolom ‘verbruik bij 100 km/hr’ de gemeten waarden voor alle objecten – dus auto’s – uit onze dataverzameling.

140
4. Robuuste regressie In de praktijk zal het probleem veelal moeilijker zijn omdat niet alle waarden ingevuld zullen zijn in de tabel. Zo’n niet-ingevulde plek noemen we een missing value. Ook zal het vaak voorkomen dat we een belangrijke grootheid over het hoofd hebben gezien – in ons voorbeeld bijvoorbeeld of het een diesel- of benzinemotor betreft. Zo’n omissie heet een hidden parameter.

141
4. Robuuste regressie We kunnen nu eens kijken of we een verband vinden tussen enkele grootheden. Als voorbeeld nemen we het verbruik van de wagen bij respectievelijk 50 km/h en 100 km/h. In figuur 1 staan beide grootheden tegen elkaar uitgezet.

142
4. Robuuste regressie In een oogopslag is duidelijk dat er inderdaad een verband is tussen deze twee grootheden. Maar hoe zouden we dit verband kunnen kwantificeren? Stel we geven het verbruik bij 50 km/h door de variabele x en het verbruik bij 100 km/h door de variabele y. Elke concrete waarneming in onze data kunnen we nu weergeven door een punt (x,y). De hele verzameling is dan: { (x1,y1), (x2,y2), (x3,y3), ... , (x18,y18), (x19,y19) }, waarbij de index slaat op het rijnummer – dus op de wagen in onze verzameling data. Op het eerste gezicht lijkt het verband tussen de parameters x en y nagenoeg lineair. Laten we daarom zoeken naar een lineair verband tussen x en y. We zoeken dus parameters a en b zodanig dat: y = a.x + b Voor elk tweetal punten kunnen we in principe zo’n lijn tekenen en de bijbehorende coëfficiënten a en b bereken. Het zal duidelijk zijn dat elk tweetal in het algemeen andere lijn en dus andere waarden voor a en b zullen geven.
. De hele verzameling is dan: { (x1,y1), (x2,y2), (x3,y3), ... , (x18,y18), (x19,y19) }, waarbij de index slaat op het rijnummer – dus op de wagen in onze verzameling data. Op het eerste gezicht lijkt het verband tussen de parameters x en y nagenoeg lineair. Laten we daarom zoeken naar een lineair verband tussen x en y. We zoeken dus parameters a en b zodanig dat: y = a.x + b. Voor elk tweetal punten kunnen we in principe zo’n lijn tekenen en de bijbehorende coëfficiënten a en b bereken. Het zal duidelijk zijn dat elk tweetal in het algemeen andere lijn en dus andere waarden voor a en b zullen geven.")
143
4. Robuuste regressie Laten we nu een andere invalshoek nemen, en laat ons aannemen dat er een goedpassende lijn bestaat met parameters a en b. Voor elke meting (xi,yi) kunnen we nu kijken naar de afstand naar die ‘ideale’ lijn. Dit is weergegeven in onderstaand figuur.
 kunnen we nu kijken naar de afstand naar die ‘ideale’ lijn. Dit is weergegeven in onderstaand figuur.")
144
4. Robuuste regressie Die afstand meten we in verticale zin, en de lengte ervan is een mate voor de ‘fout’ van waarneming nummer i ten opzichte van de lijn. We geven de lengte weer door ei (e van engels ‘error’). Dit verschil wordt ook het residu genoemd. De uitdrukking voor het residu is nu: ei = yi – (a .xi + b) Merk op dat voor punten boven de lijn ei positief is, en voor punten onder de lijn negatief.
. Dit verschil wordt ook het residu genoemd. De uitdrukking voor het residu is nu: ei = yi – (a .xi + b) Merk op dat voor punten boven de lijn ei positief is, en voor punten onder de lijn negatief.")
145
4. Robuuste regressie We kunnen nu kijken naar de totale som van alle fouten voor onze verzameling waarnemingen. Deze is:

146
4. Robuuste regressie Nu gaan we kijken naar de verzameling van alle mogelijke lijnen met coëfficiënten a en b. Over deze verzameling van lijnen kan bovenstaande som S kan in principe alle waarden aannemen: het is een functie van a en b: S(a,b). De ‘beste’ lijn zou waarde S(a,b) = 0 hebben, maar dat zal alleen het geval zijn als alle waarnemingen precies op die lijn liggen. In principe zoeken we de lijn (dus de waarden a en b) die de som S(a,b) van alle afstanden minimaliseert. Echter, de uitdrukking die we voor de fout hebben is: Dit is lineair in a en b (want X, Y, en N zijn constanten), dus heeft geen minimum. Dus S is niet op deze wijze te minimaliseren.
. De ‘beste’ lijn zou waarde S(a,b) = 0 hebben, maar dat zal alleen het geval zijn als alle waarnemingen precies op die lijn liggen. In principe zoeken we de lijn (dus de waarden a en b) die de som S(a,b) van alle afstanden minimaliseert. Echter, de uitdrukking die we voor de fout hebben is: Dit is lineair in a en b (want X, Y, en N zijn constanten), dus heeft geen minimum. Dus S is niet op deze wijze te minimaliseren.")
147
S(a,b) ≥ 0 4. Robuuste regressie
We moeten dus een definitie kiezen voor de lengte die allen positief of nul is – dan is: S(a,b) ≥ 0 en dan is S te minimaliseren over a en b. Wat te kiezen voor de lengte? Het meest voor de hand liggend is de echte afstand, de absolute waarde van het residu, dus: ei = |yi – (a .xi + b)| dus:
 ≥ 0. en dan is S te minimaliseren over a en b. Wat te kiezen voor de lengte Het meest voor de hand liggend is de echte afstand, de absolute waarde van het residu, dus: ei = |yi – (a .xi + b)| dus:")
148
4. Robuuste regressie Nadeel: hoe het minimum van S(a,b) te bepalen?
Hier een deelgrafiek van S als functie van a voor constante b =

149
4. Robuuste regressie Het probleem is dus: minimaliseer: over alle terwijl: X = {x1, x2, .., xN} en : Y = {y1, y2, .., yN} gegeven zijn. Hoe minimaliseer je een functie S(a,b) over a en b? Dit was een zeer groot en wijd bestudeerd probleem in de late achtiende eeuw, bv bij het voorspellen van planeet- en komeet-banen, het voorspellen van zons- en maansverduisteringen etc. Men kende maar één manier om het minimum te bepalen (welke?).
 over a en b Dit was een zeer groot en wijd bestudeerd probleem in de late achtiende eeuw, bv bij het voorspellen van planeet- en komeet-banen, het voorspellen van zons- en maansverduisteringen etc. Men kende maar één manier om het minimum te bepalen (welke ).")
150
4. Robuuste regressie De enige methode die men toen kende is de afgeleiden op nul stellen: dS(a,b) /da = 0 èn dS(a,b) /db = 0 Nadeel hier is dat S niet coninu differentieerbaar is omdat abs(x) een scherpe hoek heeft:
 een scherpe hoek heeft:")
151
4. Robuuste regressie Daarom dat de graph van S ook “hoekig” was: het is de som van veel “abs-en”:

152
4. Robuuste regressie Daarom dat Gauss eind achtiende eeuw voorstelde niet de abs te gebruiken, maar het kwadraat: ei = (yi – (a .xi + b))2 Deze is wèl differentieerbaar:

153
The Method of Least Absolute Deviations
Wie vond robuuste regressie uit? In 1801 Gauss scored a triumph which made him instantly famous. On the basis of a small number of available observations he correctly predicted the location of the minor planet Ceres after it had been lost out of sight by astronomers. Whereas Laplace, in dealing with astronomical or geodetic data, minimized the sum of the absolute deviations between observed and theoretical values, Gauss minimized the sum of squares. There is little doubt that Gauss used the method of least squares years before Legendre published and named the method in 1805. Gauss had not published the method, regarding it as obvious, but unfortunately could not restrain himself from bringing up his prior use, calling it "our method". The older Legendre was greatly upset, writing that Gauss had already acquired such great fame that he did not need to claim the method of least squares as well. Gauss remained slow to publish. Legendre had provided a computational method that caught on immediately. We owe to Gauss the theoretical underpinning (Gauss, 1809, 1823). Of course, the Gauss linear model was not presented in matrix form (matrices did not enter the mathematical literature until the 1930s). Karl Friedrich Gauss ( ) Adrien-Marie Legendre (1752–1833)
. Of course, the Gauss linear model was not presented in matrix form (matrices did not enter the mathematical literature until the 1930s). Karl Friedrich Gauss ( ) Adrien-Marie Legendre (1752–1833)")
154
4. Robuuste regressie We definiëren de cumulatieve kwadratenfout Q als: Merk op dat Q een functie is over a en b. De ‘beste’ lijn vinden we nu door naar het minimum van deze functie Q te zoeken over de hele verzameling a en b. Dit minimum vinden we door tegelijkertijd te differentiëren naar a èn naar b over de nu gladde curve:

155
4. Robuuste regressie Dit is een stelsel van twee vergelijkingen. De tweede differentiatie – naar b – geeft: Dat wil niets anders zeggen dan dat de gemiddelden: van de waarnemingen op de optimale lijn liggen: (We hadden dus meteen dat gemiddelde van onze metingen kunnen aftrekken, de data is dan mean-centered geworden.)
")
156
4. Robuuste regressie De uitdrukking voor a is als volgt: Als we deze uitdrukkingen in ons voorbeeld gebruiken dan vinden we: a = 1.99 en b = We kunnen deze lijn in de figuur van de metingen tekenen.

157
4. Robuuste regressie Deze methode van Gauss heet de ‘kleinste kwadratenmethode’, omdat we de kwadratensom van de fouten minimaliseren. De methode is begin negentiende eeuw geïntroduceerd door Gauss om een praktisch probleem in de astronomie op te lossen. De lineaire kleinste kwadratenmethode[1] – kort LKK – is een methode om de beste parameters te schatten voor een geparameteriseerde benadering bij een gegeven verzameling waarnemingen. In ons geval is die geparameteriseerde benadering een rechte lijn met parameters a en b. [1] Engels: Least Squares Method – vaak afgekort LSQ.

158
4. Robuuste regressie Een groot nadeel van de kleinste kwadratenmethode is dat het heel gevoelig is voor ‘uitliggers’ (of ‘uitschieters’), punten die ver van de lijn afliggen, en ongevoelig voor kleine foutjes. Dit komt door het kwadraat. Stel bv een punt P ligt ver van de lijn en heeft een grote fout e = 10, dit levert een bijdrage aan de foutensom Q van e2 = 100. Stel een ander punt R ligt bijna op de lijn en geeft een kleine fout e = 0.1. Dit levert slecht een bijdrage een bijdrage van e2 = 0.01 aan de foutensom Q, totaal verwaarloosbaar. Het gevolg is dat de LKK de lijn trekt ver van de uitliggers maar niet echt door de punten die er dichtbij liggen: LKK verdeelt de ‘pijn’ over alle punten. Gevolg is dat geen enkel punt echt op de lijn ligt.
, punten die ver van de lijn afliggen, en ongevoelig voor kleine foutjes. Dit komt door het kwadraat. Stel bv een punt P ligt ver van de lijn en heeft een grote fout e = 10, dit levert een bijdrage aan de foutensom Q van e2 = 100. Stel een ander punt R ligt bijna op de lijn en geeft een kleine fout e = 0.1. Dit levert slecht een bijdrage een bijdrage van e2 = 0.01 aan de foutensom Q, totaal verwaarloosbaar. Het gevolg is dat de LKK de lijn trekt ver van de uitliggers maar niet echt door de punten die er dichtbij liggen: LKK verdeelt de ‘pijn’ over alle punten. Gevolg is dat geen enkel punt echt op de lijn ligt.")
159
4. Robuuste regressie Voor heel veel toepassingen kan dat ongewenst zijn. Stel je hebt data van een netwerk van interacties tussen bijvoorbeeld alle +/- 500 miljoen Europeanen: hoe vaak belt X naar Y? Stel we hebben data X die aangeeft hoe vaak persoon i belt op tijd: xi(t) op tijdstippen t = 0,1,2, …, en tevens hoe vaak deze gebeld wordt: yi(t). Laat aij de frekwentie zijn waarmee persoon j naar persoon i belt. Dan is: Als data X = {x1(t), x2(t), x3(t), ... , xN(t)} en Y = {y1(t), y2(t), y3(t), ... , yN(t)} geheel bekend zijn, kan mbv de LKK-methode de parameters aij geschat worden. Het gevolg zal zijn dat geen enkele aij nul zal zijn, maar integendeel bijna alle aij klein. Daardoor lijkt het alsof alle Europeanen soms met alle Europeanen bellen.
 op tijdstippen t = 0,1,2, …, en tevens hoe vaak deze gebeld wordt: yi(t). Laat aij de frekwentie zijn waarmee persoon j naar persoon i belt. Dan is: Als data X = {x1(t), x2(t), x3(t), ... , xN(t)} en Y = {y1(t), y2(t), y3(t), ... , yN(t)} geheel bekend zijn, kan mbv de LKK-methode de parameters aij geschat worden. Het gevolg zal zijn dat geen enkele aij nul zal zijn, maar integendeel bijna alle aij klein. Daardoor lijkt het alsof alle Europeanen soms met alle Europeanen bellen.")
160
Wat we zoeken is zoiets: (meeste a zijn nul)
4. Robuuste regressie Wat we zoeken is zoiets: (meeste a zijn nul) 9 20 30 39 35 23 50 14 52 Wat we vinden met LKK is : (alle a zijn niet exact nul) 9 20 30 23 39 35 50 14 52
 Wat we vinden met LKK is : (alle a zijn niet exact nul)")
161
4. Robuuste regressie We gaan terug naar het oorspronkelijke probleem. minimaliseer: over alle terwijl: X = {x1, x2, .., xN} en : Y = {y1, y2, .., yN} gegeven zijn. Dit ziet er al bijna lineair uit, kunnen we af van die absolute waarde? Herinner dat voor de absolute waarde geldt: |x| ≥ x èn |x| ≥ -x Voer nu een hulp-variabele r in (van residu) met: ri = |yi – axi – b| Dan geldt: ri ≥ yi – axi – b èn ri ≥ – yi + axi + b
 met: ri = |yi – axi – b| Dan geldt: ri ≥ yi – axi – b èn ri ≥ – yi + axi + b.")
162
4. Robuuste regressie Met de definitie: ri = |yi – axi – b| en twee randvoorwaarden: (1) ri ≥ yi – axi – b, en (2) ri ≥ – yi + axi + b, kunnen we: minimaliseer: over alle terwijl: X = {x1, x2, .., xN} en : Y = {y1, y2, .., yN} gegeven zijn. herschrijven als: minimaliseer: over alle terwijl: en X = {x1, x2, .., xN} en : Y = {y1, y2, .., yN} gegeven zijn. Let op!!! Dit lijkt wel een LP-probleem!!!

163
4. Robuuste regressie minimaliseer: over alle terwijl: en X = {x1, x2, .., xN} en : Y = {y1, y2, .., yN} gegeven zijn. Met N+2 nieuwe variabelen x1 = a, x2 = b, xi+2 = ri, pi = oude xi, en qi = oude yi kunnen we dit probleem herschrijven als: terwijl: en P = {p1, p2, .., pN} en : Q = {q1, q2, .., qN} gegeven zijn.

164
4. Robuuste regressie 4. Robuuste regressie terwijl: en P = {p1, p2, .., pN} en : Q = {q1, q2, .., qN} gegeven zijn. Dit kunnen we op quasi-standaard LP schrijven als: terwijl: met: Hier ontbreekt x ≥ 0 maar dat maakt voor moderne LP- pakketten niets uit!

165
4. Robuuste regressie Voorbeeld:

166
4. Robuuste regressie Voorbeeld:

167
4. Robuuste regressie Voorbeeld:

168
4. Robuuste regressie Voorbeeld:

169
4. Robuuste regressie Voorbeeld:

170
4. Robuuste regressie Voorbeeld:

171
VOORBEELD 2: We zoeken zoiets: (meeste a zijn nul)
4. Robuuste regressie VOORBEELD 2: We zoeken zoiets: (meeste a zijn nul) 9 20 30 39 35 23 50 14 52 Wat we vinden met L1-regressie is : 9 20 30 39 35 23 50 14 52
 Wat we vinden met L1-regressie is :")
172
4. Robuuste regressie Robuuste regressie is een statistische procedure die er op gericht is regressies uit te kunnen voeren wanneer de data-set vervuild is met enige punten die niet tot een (multivariate) normaal verdeling rond het model behoren. Deze methode heeft veel toepassingen in situaties waarin sommige parameters exact nul moeten zijn: interactie-netwerken coefficienten in benaderingen herkennen van uitbijters In regressies zijn uitbijters erg desastreus. Er is daarom behoefte aan een methode die de uitbijters identificeert. In hun boek Robust regression and outlier detection hebben twee Vlaamse onderzoekers Peter J. Rousseeuw en Annick M. Leroy daar wat op gevonden. Zij vervangen het gemiddelde (avg) door een mediaan (med), en passen daarmee de L1-norm toe.
 normaal verdeling rond het model behoren. Deze methode heeft veel toepassingen in situaties waarin sommige parameters exact nul moeten zijn: interactie-netwerken. coefficienten in benaderingen. herkennen van uitbijters. In regressies zijn uitbijters erg desastreus. Er is daarom behoefte aan een methode die de uitbijters identificeert. In hun boek Robust regression and outlier detection hebben twee Vlaamse onderzoekers Peter J. Rousseeuw en Annick M. Leroy daar wat op gevonden. Zij vervangen het gemiddelde (avg) door een mediaan (med), en passen daarmee de L1-norm toe.")
173
De Lp-norm 4. Robuuste regressie
Als we over de lengte van een vector x = (x1,x2,x3, ... ,xn) praten bedoelen we vaak de Euclidische norm: Er zijn tal van situaties waarin deze keuze niet de beste is. Soms – zoals we net zagen – is het handiger de absolute waarde te nemen: We kunnen deze definitie generaliseren tot de Lp-norm als volgt: We zien nu ook waarom we net van ||.||1 en ||.||2 spraken. Er is nog een interessante norm, de ∞-norm; L∞ : Ga na dat dit betekent dat:
 praten bedoelen we vaak de Euclidische norm: Er zijn tal van situaties waarin deze keuze niet de beste is. Soms – zoals we net zagen – is het handiger de absolute waarde te nemen: We kunnen deze definitie generaliseren tot de Lp-norm als volgt: We zien nu ook waarom we net van ||.||1 en ||.||2 spraken. Er is nog een interessante norm, de ∞-norm; L∞ : Ga na dat dit betekent dat:")
174
4. Robuuste regressie Met deze notatie kunnen we nu het LKK schrijven voor het fitten van data met het model y = ax + b als een L2-minimalisatie: terwijl : Op dezelfde manier kunnen we nu robust estimation schrijven als een L1-minimalisatie : terwijl :

175
1. Geometrische interpretatie Bedankt voor uw aandacht!!!
Resumé van deze cursus Wat hebben we in deze cursus geleerd? het kunnen mathematisch modelleren van een LP probleem. het kunnen oplossen van een LP-probleem middels de Simplex-methode. het begrijpen van de theoretische achtergronden en de termen betreffende LP-problemen. Het kunnen toepassen van LP-methode in andere gebieden, bv robuuste estimatie Slides op: Bedankt voor uw aandacht!!!

176
EINDE van dit COLLEGE

Verwante presentaties