Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Datastructuren Sorteren: bubble, merge, quick
College 3

2
Bubblesort Verwissel: hulp = a[i]; a[i] = a[i+1]; a[i+1] = hulp;
Eenvoudig sorteeralgoritme repeat change = false; for i=1 to n-1 do if (a[i] > a[i+1]) then verwissel a[i] en a[i+1] van plaats change = true until (change == false) Verwissel: hulp = a[i]; a[i] = a[i+1]; a[i+1] = hulp; Hoe snel? Correct?
![Bubblesort Verwissel: hulp = a[i]; a[i] = a[i+1]; a[i+1] = hulp;](http://slideplayer.nl/slide/2205668/8/images/2/Bubblesort+Verwissel%3A+hulp+%3D+a%5Bi%5D%3B+a%5Bi%5D+%3D+a%5Bi%2B1%5D%3B+a%5Bi%2B1%5D+%3D+hulp%3B.jpg "Eenvoudig sorteeralgoritme. repeat. change = false; for i=1 to n-1 do. if (a[i] > a[i+1]) then. verwissel a[i] en a[i+1] van plaats. change = true. until (change == false) Verwissel: hulp = a[i]; a[i] = a[i+1]; a[i+1] = hulp; Hoe snel Correct")
3
Correctheid en tijd bubble sort
Als we klaar zijn is de array gesorteerd; we hebben steeds een permutatie van de input Terminatie? Ja, want Na i keer de hoofdloop gedaan te hebben staan op posities n - i +1, n – i +2, … , n de i grootste getallen in de array Bewijzen we zometeen Dus: na hooguit n keer de hoofdloop te doen, is het array gesorteerd en zijn we klaar

4
Inductiebewijs Bubble sort
Inductie hypothese: Voor alle i: 0 £ i £ n: Na i keer de hoofdloop gedaan te hebben staan op posities n - i +1, n – i +2, … , n de i grootste getallen in de array Klopt als i = 0 Stel waar voor i – 1, dan …

5
Tijd Verwissel: O(1) repeat Binnenste deel: O(1)
For: n keer O(1): O(n) Totaal: n keer O(n): O(n2) Er zijn ook inputs waar zo’n n2 stappen gedaan worden, bijv.: het omgekeerde van een gesorteerde array (10, 9, 8, 7, 6, 5, 4, 3, 2, 1) repeat change = false; for i=1 to n-1 do if (a[i] > a[i+1]) then verwissel a[i] en a[i+1] van plaats change = true until (change == false)
: O(n) Totaal: n keer O(n): O(n2) Er zijn ook inputs waar zo’n n2 stappen gedaan worden, bijv.: het omgekeerde van een gesorteerde array (10, 9, 8, 7, 6, 5, 4, 3, 2, 1) repeat. change = false; for i=1 to n-1 do. if (a[i] > a[i+1]) then. verwissel a[i] en a[i+1] van plaats. change = true. until (change == false)")
6
Mergesort

7
Politiek / militaire strategie Algorithmische techniek
Divide and conquer Divide et impera Verdeel en heers Politiek / militaire strategie Algorithmische techniek Datastructuren

8
Algoritmische methode: divide and conquer (verdeel en heers)
Mergesort Algoritmische methode: divide and conquer (verdeel en heers) Splits probleem in deelstukken Los elk deelstuk afzonderlijk op Combineer oplossing van deelstukken Mergesort gebruikt divide and conquer strategie Sorteer eerst, recursief de 1e helft van de array Sorteer daarna, recursief, de 2e helft van de array Voeg de twee gesorteerde helften samen door een soort van ‘ritsen’
 Splits probleem in deelstukken. Los elk deelstuk afzonderlijk op. Combineer oplossing van deelstukken. Mergesort gebruikt divide and conquer strategie. Sorteer eerst, recursief de 1e helft van de array. Sorteer daarna, recursief, de 2e helft van de array. Voeg de twee gesorteerde helften samen door een soort van ‘ritsen’")
9
Merge-sort I Mergesort(A, p, r)
{Input: array A, integers p, r, met 1£ p £ r £ lengte(A)} {Output: A[p..r] is gesorteerd en bevat dezelfde elementen als A[p..r] in input} If (p ³ r) then doe niets else midden = ë (p+r)/2 û ; Mergesort(A,p, midden); Mergesort(A,midden+1,r); Merge(A,p,midden,r); {“Rits” de twee stukken in elkaar”}
} {Output: A[p..r] is gesorteerd en bevat dezelfde elementen als A[p..r] in input} If (p ³ r) then doe niets. else. midden = ë (p+r)/2 û ; Mergesort(A,p, midden); Mergesort(A,midden+1,r); Merge(A,p,midden,r); { Rits de twee stukken in elkaar }")
10
Merge(A,p,q,r) (deel 1) {Input: A[p…q] is gesorteerd, en A[q+1…r] is gesorteerd} {Output: A[p…r] is gesorteerd} n1 = q – p +1; n2 = r – q; Maak een array L[1…n1+1]; Maak een array R[1..n2+1]; for i=1 to n1 do L[i] = A[p+i – 1]; for j=1 to n2 do R[j] = A[q+j]; (rest komt zometeen) Eentje extra voor stootblokken Eerst copieren in arrays L en R
![Merge(A,p,q,r) (deel 1) {Input: A[p…q] is gesorteerd, en A[q+1…r] is gesorteerd} {Output: A[p…r] is gesorteerd}](http://slideplayer.nl/slide/2205668/8/images/10/Merge%28A%2Cp%2Cq%2Cr%29+%28deel+1%29+%7BInput%3A+A%5Bp%E2%80%A6q%5D+is+gesorteerd%2C+en+A%5Bq%2B1%E2%80%A6r%5D+is+gesorteerd%7D+%7BOutput%3A+A%5Bp%E2%80%A6r%5D+is+gesorteerd%7D.jpg "n1 = q – p +1; n2 = r – q; Maak een array L[1…n1+1]; Maak een array R[1..n2+1]; for i=1 to n1 do L[i] = A[p+i – 1]; for j=1 to n2 do R[j] = A[q+j]; (rest komt zometeen) Eentje extra voor stootblokken. Eerst copieren in. arrays L en R.")
11
Merge deel 2 n1 = q – p +1; n2 = r – q; Maak een array L[1…n1+1]; Maak een array R[1..n2+1]; for i=1 to n1 do L[i] = A[p+i – 1]; for j=1 to n2 do R[j] = A[q+j]; L[n1+1] = MAXINT; {Stootblok (sentinel)} R[n2+1] = MAXINT; {Stootblok}
![Merge deel 2 n1 = q – p +1; n2 = r – q; Maak een array L[1…n1+1]; Maak een array R[1..n2+1]; for i=1 to n1 do L[i] = A[p+i – 1];](http://slideplayer.nl/slide/2205668/8/images/11/Merge+deel+2+n1+%3D+q+%E2%80%93+p+%2B1%3B+n2+%3D+r+%E2%80%93+q%3B+Maak+een+array+L%5B1%E2%80%A6n1%2B1%5D%3B+Maak+een+array+R%5B1..n2%2B1%5D%3B+for+i%3D1+to+n1+do+L%5Bi%5D+%3D+A%5Bp%2Bi+%E2%80%93+1%5D%3B.jpg "for j=1 to n2 do R[j] = A[q+j]; L[n1+1] = MAXINT; {Stootblok (sentinel)} R[n2+1] = MAXINT; {Stootblok}")
12
Merge deel 2 for k = p to r do pleklinks = 1; plekrechts = 1;
n1 = q – p +1; n2 = r – q; Maak arrays L[1…n1+1] en R[1..n2+1]; for i=1 to n1 do L[i] = A[p+i – 1]; for j=1 to n2 do R[j] = A[q+j]; L[n1+1] = MAXINT; {Stootblok} R[n2+1] = MAXINT; {Stootblok} pleklinks = 1; plekrechts = 1; for k = p to r do {Vind het element op positie k in A} if (L(pleklinks) £ R(plekrechts)) then A[k] = L(pleklinks); pleklinks ++; else A[k] = R[plekrechts); plekrechts ++;
 £ R(plekrechts)) then A[k] = L(pleklinks); pleklinks ++; else A[k] = R[plekrechts); plekrechts ++;")
13
Invariant geldt initieel, en blijft gelden
Correctheid merge Invariant Aan het begin van de for-loop gelden: A[p…k-1] bevat de k-p kleinste elementen uit L[1..n1+1] en R[1..n2+1] A[p…k-1] is gesorteerd L[pleklinks] is het kleinste element in L dat niet teruggezet is naar A r[plekrechts] is het kleinste element in R dat niet teruggezet is naar A Invariant geldt initieel, en blijft gelden Bij terminatie: k = r+1; en dus ...

14
Tijd van mergesort Wat is de tijd van een enkele mergeoperatie? Als we twee stukken van lengte r mergen: O(r) (want…) Analyse van mergesort hier wat informeler – kijk naar de “berekeningsboom”

15
log n niveau’s

16
Tijd van mergesort O(n log n)
")
17
Verdeel en heers paradigma Idee is:
Quicksort Verdeel en heers paradigma Idee is: Kies een element uit de array, zeg x Splits de array in drie stukken: Alles in 1e stuk is £ x 2e stuk is het element x Alles in 3e stuk is ³ x (of >) Sorteer recursief het eerste stuk Sorteer recursief het derde stuk Klaar!
 Sorteer recursief het eerste stuk. Sorteer recursief het derde stuk. Klaar!")
18
Opmerking In onze beschrijving gaan we er van uit dat alle elementen verschillend zijn Als er gelijke elementen zijn, werkt het ook, maar moet je iets beter opletten in de analyse (zelfde code kan gebruikt worden) Datastructuren
 Datastructuren.")
19
Quicksort: Eén PArtition Datastructuren

20
Splitsen Partition(A,p,r)
{Input is array A met indexwaardes van p tot en met r} {Output: waarde q met p £ q £ r zodat A[p..r] een permutatie is van input, en als p £ i < q dan geldt A[i] £ A[q] en als q < i £ r dan geldt A[i] > A[q]} … Methode partitioneert array A[p…r] Returnwaarde is plek waar “splitselement” terechtgekomen is Splitselement heet pivot en nemen we nu als element dat op A[r] staat

21
Partition Code in boek is subtiel pivot p i i+1 j-1 j r Allemaal £
Gebied waar we nog aan werken

22
Pseudocode Partition Partition(A,p,r) pivot = A[r]; i = p – 1;
for j = p to r – 1 do {*} if A[j] £ pivot then i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; Invariant: bij * geldt voor elke k, p £ k £ r: Als p £ k £ i, dan A[k] £ pivot Als i+1 £ k £ j – 1, dan A[k] > pivot Als k=r, dan A[k]=pivot
![Pseudocode Partition Partition(A,p,r) pivot = A[r]; i = p – 1;](http://slideplayer.nl/slide/2205668/8/images/22/Pseudocode+Partition+Partition%28A%2Cp%2Cr%29+pivot+%3D+A%5Br%5D%3B+i+%3D+p+%E2%80%93+1%3B.jpg "for j = p to r – 1 do. {*} if A[j] £ pivot. then. i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; Invariant: bij * geldt voor elke k, p £ k £ r: Als p £ k £ i, dan A[k] £ pivot. Als i+1 £ k £ j – 1, dan A[k] > pivot. Als k=r, dan A[k]=pivot.")
23
Pseudocode Partition Partition(A,p,r) pivot = A[r]; i = p – 1;
for j = p to r – 1 do {*} if A[j] £ pivot then i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; Invariant: bij * geldt voor elke k, p £ k £ r: Als p £ k £ i, dan A[k] £ pivot Als i+1 £ k £ j – 1, dan A[k] > pivot Als k=r, dan A[k]=pivot Merk op: Initieel geldt invariant: triviaal Invariant blijft gelden Bij terminatie …
![Pseudocode Partition Partition(A,p,r) pivot = A[r]; i = p – 1;](http://slideplayer.nl/slide/2205668/8/images/23/Pseudocode+Partition+Partition%28A%2Cp%2Cr%29+pivot+%3D+A%5Br%5D%3B+i+%3D+p+%E2%80%93+1%3B.jpg "for j = p to r – 1 do. {*} if A[j] £ pivot. then. i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; Invariant: bij * geldt voor elke k, p £ k £ r: Als p £ k £ i, dan A[k] £ pivot. Als i+1 £ k £ j – 1, dan A[k] > pivot. Als k=r, dan A[k]=pivot. Merk op: Initieel geldt invariant: triviaal. Invariant blijft gelden. Bij terminatie …")
24
En dan verwisselen we A[i+1] en A[r]
Partition na de loop Allemaal £ Allemaal > p r i i+1 En dan verwisselen we A[i+1] en A[r] Allemaal £ Allemaal > i+1 p r
![En dan verwisselen we A[i+1] en A[r]](http://slideplayer.nl/slide/2205668/8/images/24/En+dan+verwisselen+we+A%5Bi%2B1%5D+en+A%5Br%5D.jpg "Partition na de loop. Allemaal £ Allemaal > p. r. i. i+1. En dan verwisselen we A[i+1] en A[r] Allemaal £ Allemaal > i+1. p. r.")
25
Looptijd partition Partition(A,p,r) pivot = A[r]; i = p – 1;
for j = p to r – 1 do {*} if A[j] £ pivot then i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; Lineair: Q(r-p+1) Inspectie van loopstructuur
![Looptijd partition Partition(A,p,r) pivot = A[r]; i = p – 1;](http://slideplayer.nl/slide/2205668/8/images/25/Looptijd+partition+Partition%28A%2Cp%2Cr%29+pivot+%3D+A%5Br%5D%3B+i+%3D+p+%E2%80%93+1%3B.jpg "for j = p to r – 1 do. {*} if A[j] £ pivot. then. i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; Lineair: Q(r-p+1) Inspectie van loopstructuur.")
26
Quicksort: Twee CODE EN EERSTE ANALYSE Datastructuren

27
Quicksort Quicksort(A, p, r) {Sorteert het deel van de array A[p…r]} if p < r then q = Partition(A, p, r) Quicksort(A, p, q-1) Quicksort(A, q+1, r)
![Quicksort Quicksort(A, p, r) {Sorteert het deel van de array A[p…r]} if p < r. then. q = Partition(A, p, r)](http://slideplayer.nl/slide/2205668/8/images/27/Quicksort+Quicksort%28A%2C+p%2C+r%29+%7BSorteert+het+deel+van+de+array+A%5Bp%E2%80%A6r%5D%7D+if+p+%3C+r.+then.+q+%3D+Partition%28A%2C+p%2C+r%29.jpg "Quicksort(A, p, q-1) Quicksort(A, q+1, r)")
28
r p q Allemaal £ Allemaal > p r

29
Hoeveel tijd kost Quicksort?
In het slechtste geval gaat het erg langzaam… Bekijk een gesorteerde rij: We splitsen in stukken van grootte n – 1; 1; 0 En de volgende keer in stukken van grootte n-2; 1; 0 Etc. Dus: cn+ c(n-1)+ c(n-2)+ c(n-3) + … +3c+2c+c = c n(n+1)/2 stappen Op een gesorteerde rij: O(n2) stappen
+ c(n-2)+ c(n-3) + … +3c+2c+c = c n(n+1)/2 stappen. Op een gesorteerde rij: O(n2) stappen.")
30
Analyse met recurrente betrekkingen
Schrijf: T(n) is aantal stappen van Quicksort op gesorteerd array met n elementen T(n) = T(n-1)+T(0) + O(n) = T(n-1)+ O(n) = O(n2) Andere constantes Met inductie naar n
 is aantal stappen van Quicksort op gesorteerd array met n elementen. T(n) = T(n-1)+T(0) + O(n) = T(n-1)+ O(n) = O(n2) Andere constantes. Met inductie naar n.")
31
Quicksort voor aartsoptimisten
Als we echt geluk hebben, splitst Quicksort altijd precies middendoor en gaan we in recursie op twee stukken van hooguit n/2 elementen Zelfde analyse als bij Mergesort geeft O(n lg n) tijd
 tijd.")
32
log n niveau’s

33
Beste geval analyse van Quicksort met recurrente betrekkingen
Stel T(n) is het beste geval van de looptijd van Quicksort op een array met n elementen T(n) £ 2*T(n /2) + O(n) (*) T(n) = O(n lg n) Volgt uit (*) met inductie Zo kan je ook Mergesort analyseren
 is het beste geval van de looptijd van Quicksort op een array met n elementen. T(n) £ 2*T(n /2) + O(n) (*) T(n) = O(n lg n) Volgt uit (*) met inductie. Zo kan je ook Mergesort analyseren.")
34
Quicksort voor optimisten (niet noodzakelijk aartsoptimisten)
Stel nu dat we altijd verdelingen hebben die de array splitsen in twee stukken die verhouding 9 – 1 hebben T(n) = T(9n / 10)+ T(n / 10) + O(n) Recursieboom heeft log10/9 n = O(lg n) lagen Per laag O(n) dus in zo’n geval eveneens O(n lg n) Maar … hoe vaak gebeurt dat?
 = T(9n / 10)+ T(n / 10) + O(n) Recursieboom heeft log10/9 n = O(lg n) lagen. Per laag O(n) dus in zo’n geval eveneens O(n lg n) Maar … hoe vaak gebeurt dat")
35
Hoe vaak doen we een goede splitsing?
In 80% van de gevallen splitsen we 9-1 of beter… Ingewikkelde analyse geeft O(n lg n) tijd gemiddeld over alle mogelijke permutaties van input als alle getallen verschillend zijn (doen we niet)
 tijd gemiddeld over alle mogelijke permutaties van input als alle getallen verschillend zijn (doen we niet)")
36
Drie Randomized Quicksort Datastructuren

37
Hoe zorgen we ervoor dat we heel vaak goed splitsen
Idee 1: maak eerst een random permutatie van de input Geeft O(n lg n) Analyse ingewikkeld Idee 2 (beter): gebruik niet A[r] als pivot, maar gebruik een random element als pivot Geeft ook O(n lg n) Analyse eenvoudiger Ietsje sneller
 Analyse ingewikkeld. Idee 2 (beter): gebruik niet A[r] als pivot, maar gebruik een random element als pivot. Geeft ook O(n lg n) Analyse eenvoudiger. Ietsje sneller.")
38
Randomized-Partition
Randomized-Partition(A,p,r) Kies uniform een random getal i uit de verzameling {p, p+1, …, r} Verwissel A[r] en A[i] Partition(A,p,r) Elk element in A heeft dezelfde kans om als pivot-element gebruikt te worden
 Kies uniform een random getal i uit de verzameling {p, p+1, …, r} Verwissel A[r] en A[i] Partition(A,p,r) Elk element in A heeft dezelfde kans om als pivot-element gebruikt te worden.")
39
Randomized-Quicksort pseudocode
Randomized-Quicksort(A, p, r) {Sorteert het deel van de array A[p…r]} if p < r then q = Randomized-Partition(A,p,r) Randomized-Quicksort(A, p, q-1) Randomized-Quicksort(A, q+1, r)
 {Sorteert het deel van de array A[p…r]} if p < r. then. q = Randomized-Partition(A,p,r) Randomized-Quicksort(A, p, q-1) Randomized-Quicksort(A, q+1, r)")
40
Analyse Randomized Quicksort
Verschillende manieren om de verwachtte tijd uit te rekenen Netjes: stel recurrente betrekking op, en los die op (zie o.a. sheets) Vandaag: telargument waarbij we kijken naar “hoe vaak doet een element mee in een partition”?
 Vandaag: telargument waarbij we kijken naar hoe vaak doet een element mee in een partition")
41
Tijd is O(som partition-lengtes)
Kijk naar recursieboom Totale tijd is O(som van alle lengtes van alle deelstukken waar we een partitie op doen) = O(som over alle elementen van aantal keren dat het element in een partitie mee doet)
 = O(som over alle elementen van aantal keren dat het element in een partitie mee doet)")
42
Verwachtte tijd Totale verwachtte tijd is O(verwachte som van alle lengtes van alle deelstukken waar we een partitie op doen) = O(som over alle elementen van verwachtte aantal keren dat het element in een partitie mee doet) = n* O(verwachtte aantal keren dat een element in een partitie meedoet)
 = n* O(verwachtte aantal keren dat een element in een partitie meedoet)")
43
Afschatten van verwachtte aantal keren dat een element in een partitie meedoet
Is O(log n) Hoe laten we dit zien? Kijk element x, en kijk naar het formaat van het stuk waar x in zit. Begint met formaat n Iedere keer een beetje kleiner Als formaat 1 is zijn we klaar Hoe vaak is het verwachtte aantal keren dat het kleiner wordt? We laten zien: O(log n)
 Hoe laten we dit zien Kijk element x, en kijk naar het formaat van het stuk waar x in zit. Begint met formaat n. Iedere keer een beetje kleiner. Als formaat 1 is zijn we klaar. Hoe vaak is het verwachtte aantal keren dat het kleiner wordt We laten zien: O(log n)")
44
Kans is ½ dat stuk hooguit ¾ van oude lengte heeft
Als we een stuk hebben met r elementen zijn er r/2 keuzes voor de pivot die zorgen dat de volgende keer het grootste stuk hooguit ¾ * r lang is

45
Tellerij klaar Hoe vaak kan je n met ¾ vermenigvuldigen totdat je onder de 1 bent? log4/3 n keer = O(log n) Wat is het verwachtte aantal keren dat je een experiment met kans ½ moet doen totdat je s keer succes hebt? 2s Dus verwachtte aantal keren dat element in partitie meedoet is hooguit 2 log4/3 n = O(log n) keer Dus: verwachtte tijd Quicksort O(n log n) Andere analyse (wel in sheets, niet vandaag): 2n ln n
 keer. Dus: verwachtte tijd Quicksort O(n log n) Andere analyse (wel in sheets, niet vandaag): 2n ln n.")
46
Analyse Randomized-Partition
Slechtste geval: weer O(n2) T(n) = max0£ q£ n-1 T(q)+T(n-q-1)+O(n) Verwachtte tijd: analyse doen we hier aannemend dat alle elementen verschillend zijn (anders klopt ‘t ook, overigens) We doen de analyse hier met behulp van de sommatiefactormethode Eerst: vergelijking looptijd en aantal vergelijkingen
 T(n) = max0£ q£ n-1 T(q)+T(n-q-1)+O(n) Verwachtte tijd: analyse doen we hier aannemend dat alle elementen verschillend zijn (anders klopt ‘t ook, overigens) We doen de analyse hier met behulp van de sommatiefactormethode. Eerst: vergelijking looptijd en aantal vergelijkingen.")
47
Looptijd vs aantal vergelijkingen
Stel Quicksort doet X vergelijkingen. Dan gebruikt het O(n+X) tijd Partition doet altijd minstens 1 vergelijking Want we roepen Partition alleen aan op stukken met minstens 2 elementen Partition doet O(aantal vergelijkingen in partition) werk … We gaan nu het verwachtte aantal vergelijkingen tellen dat Quicksort doet op een array met n verschillende elementen. Noem dit getal C(n)
 tijd. Partition doet altijd minstens 1 vergelijking. Want we roepen Partition alleen aan op stukken met minstens 2 elementen. Partition doet O(aantal vergelijkingen in partition) werk. … We gaan nu het verwachtte aantal vergelijkingen tellen dat Quicksort doet op een array met n verschillende elementen. Noem dit getal C(n)")
48
Deze waardes noemen we D(n).
Technisch detail We volgen de analyse uit Concrete Mathematics. Die gebruikt twee vergelijkingen per recursieve aanroep extra. Deze waardes noemen we D(n). D(0)=C(0)=0; als n>0 dan is D(n)>C(n) Als we dus voor D(n) een bovengrens hebben, geeft dat ook een bovengrens voor C(n) Uiteindelijke waarde is dus iets beter (scheelt niet veel) Zo volgen we Knuth
. D(0)=C(0)=0; als n>0 dan is D(n)>C(n) Als we dus voor D(n) een bovengrens hebben, geeft dat ook een bovengrens voor C(n) Uiteindelijke waarde is dus iets beter (scheelt niet veel) Zo volgen we Knuth.")
49
Aantal vergelijkingen (Randomized)-Partition
Partition(A,p,r) pivot = A[r]; i = p – 1; for j = p to r – 1 do {*} if A[j] £ pivot then i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; n-1 vergelijkingen op een array met n elementen Concrete Mathematics neemt hier n+1 vergelijkingen
 pivot = A[r]; i = p – 1; for j = p to r – 1 do. {*} if A[j] £ pivot. then. i ++; Verwissel A[i] en A[j] Verwissel A[i+1] en A[r]; return i+1; n-1 vergelijkingen op een array met n elementen. Concrete Mathematics neemt hier n+1 vergelijkingen.")
50
Analyse D(n) (1) D(0) = 0 D(1) = 2 D(n) = n+1 + ????
Elk van de splitsingen heeft dezelfde kans: 0,1,n-1 1,1,n-2 2,1,n-3 … n-2, 1, 1 n-1, 1, 0

51
Analyse D(n) (2) D(0)= 0 D(1)= 2
D(n) = n+1 + 1/n*Sk=0n-1 D(k) + 1/n*Sk=0n-1 D(n-k-1) Elk van de splitsingen heeft dezelfde kans: 0,1,n-1 1,1,n-2 2,1,n-3 … n-2, 1, 1 n-1, 1, 0 Of: D(n) = n+1 + (2/n)*Sk=0n-1 D(k) voor n>0
 = n+1 + 1/n*Sk=0n-1 D(k) + 1/n*Sk=0n-1 D(n-k-1) Elk van de splitsingen heeft dezelfde kans: 0,1,n-1. 1,1,n-2. 2,1,n-3. … n-2, 1, 1. n-1, 1, 0. Of: D(n) = n+1 + (2/n)*Sk=0n-1 D(k) voor n>0.")
52
- Deze hadden we Maal n nemen Vergelijkingen aftrekken
Zelfde vergl. voor n-1 - Vergelijkingen aftrekken Na vereenvoudigen

53
Stelsel vergelijkingen
D(0)=0 nD(n) = (n+1)D(n-1)+ 2n Dit stelsel kunnen we met sommatiefactormethode oplossen Idee is: vermenigvuldig formule met sommatiefactor sn waarbij sn = (an-1an-2…a1)/(bnbn-1…b2) als anD(n)=bnD(n-1)+cn Want dan is snbn=sn-1an-1 En dan krijg je voor E(n)=snanD(n) de formule E(n)=E(n-1)+sncn Wat een somformule voor E en daarna voor D geeft…
=0. nD(n) = (n+1)D(n-1)+ 2n. Dit stelsel kunnen we met sommatiefactormethode oplossen. Idee is: vermenigvuldig formule met sommatiefactor sn waarbij. sn = (an-1an-2…a1)/(bnbn-1…b2) als anD(n)=bnD(n-1)+cn. Want dan is snbn=sn-1an-1. En dan krijg je voor E(n)=snanD(n) de formule E(n)=E(n-1)+sncn. Wat een somformule voor E en daarna voor D geeft…")
54
D(0)=0 nD(n) = (n+1)D(n-1)+ 2n an = n bn = n+1 : dit hadden we cn = 2n
Definitie toepassen: Alles maal sn: (*) (**) Def.: (*) en (**) geven:
 (**) Def.: (*) en (**) geven:")
55
dus Want E(0)=0 We hadden dus
=0 We hadden dus")
56
Aantal vergelijkingen randomized quicksort
Randomized-Quicksort doet verwacht ongeveer 2(n+1)ln n vergelijkingen
ln n vergelijkingen.")
57
Nieuw onderzoek Recent werk: quicksort met meer dan 1 pivotelement ... Is soms nèt iets sneller Datastructuren

58
ADT versus Datastructuur
is een systematische manier van organiseren van data en toegang verlenen tot diezelfde data. Abstract data type is een model van een datastructuur waarin gespecificeerd is: type van de data operaties ter ondersteuning van de datastructuur de types van de parameters van deze operaties Een abstract data type concentreert zich op functionaliteit, niet op tijd. Vandaag: Heap (is ADT), Array-implementatie van Heap Datastructuren
, Array-implementatie van Heap. Datastructuren.")
59
Heap “Hoop”, zoals in “een steenhoop” Datastructuur, gebruikt voor sorteren en priority queue Een heap is eigenlijk een boom, maar kan heel efficient in een array worden weergegeven Datastructuren voor “echte” bomen komen later

60
“Bijna volledige binaire boom” Vervult de “heap-eigenschap”
Wat bedoelen we hiermee?

61
Binaire boom Binaire boom: Volledige binaire boom:
Iedere knoop heeft 0, 1 of 2 kinderen Volledige binaire boom: Behalve op het onderste niveau heeft elke knoop 2 kinderen Een knoop kan hebben: Ouder (PARENT) Linkerkind (LEFT) Rechterkind (RIGHT)
 Linkerkind (LEFT) Rechterkind (RIGHT)")
62
Bijna volledige binaire boom
Alle niveau’s helemaal gevuld, behalve ‘t onderste dat een eindje van links af gevuld is, en daarna niet meer Volledige bb mag ook

63
Twee termen Diepte van knoop: afstand naar wortel Hoogte van knoop x: maximale afstand naar blad onder x

64
Heap-eigenschap Elke knoop x in de heap heeft een waarde A[x] Max-heap eigenschap: voor alle knopen i (behalve natuurlijk de wortel van de boom) geldt: A[PARENT(i)] ³ A[i] Min-heap eigenschap: voor alle knopen i (behalve natuurlijk de wortel van de boom) geldt: A[PARENT(i)] £ A[i]
![Heap-eigenschap Elke knoop x in de heap heeft een waarde A[x]](http://slideplayer.nl/slide/2205668/8/images/64/Heap-eigenschap+Elke+knoop+x+in+de+heap+heeft+een+waarde+A%5Bx%5D.jpg "Max-heap eigenschap: voor alle knopen i (behalve natuurlijk de wortel van de boom) geldt: A[PARENT(i)] ³ A[i] Min-heap eigenschap: voor alle knopen i (behalve natuurlijk de wortel van de boom) geldt: A[PARENT(i)] £ A[i]")
65
16 10 14 9 3 8 7 2 4 1 Max-heap

66
Heapsort Gebruikt de Heap datastructuur met implementatie in array Heap

67
Implementatie van een heap
1 16 3 2 10 14 7 5 4 9 3 8 7 6 8 2 4 1 10 9 16 14 10 8 7 9 3 2 4 1

68
Implementatie van een heap
Gebruik een array A[1] is de wortel A[2], A[3] de achteenvolgende elementen op hoogte 1 A[4], A[5], A[6], A[7] voor hoogte 2, A[2r], … A[2r+1-1] voor hoogte r PARENT(i) Return ë i/2 û ; LEFT(i) Return 2i; RIGHT(i) Return 2i+1;
 Return ë i/2 û ; LEFT(i) Return 2i; RIGHT(i) Return 2i+1;")
69
Array implementatie 1 16 3 2 PARENT(i) Return ë i/2 û ; LEFT(i) Return 2i; RIGHT(i) Return 2i+1; 10 14 5 4 9 3 8 7 6 7 8 2 4 1 10 9 16 14 10 8 7 9 3 2 4 1
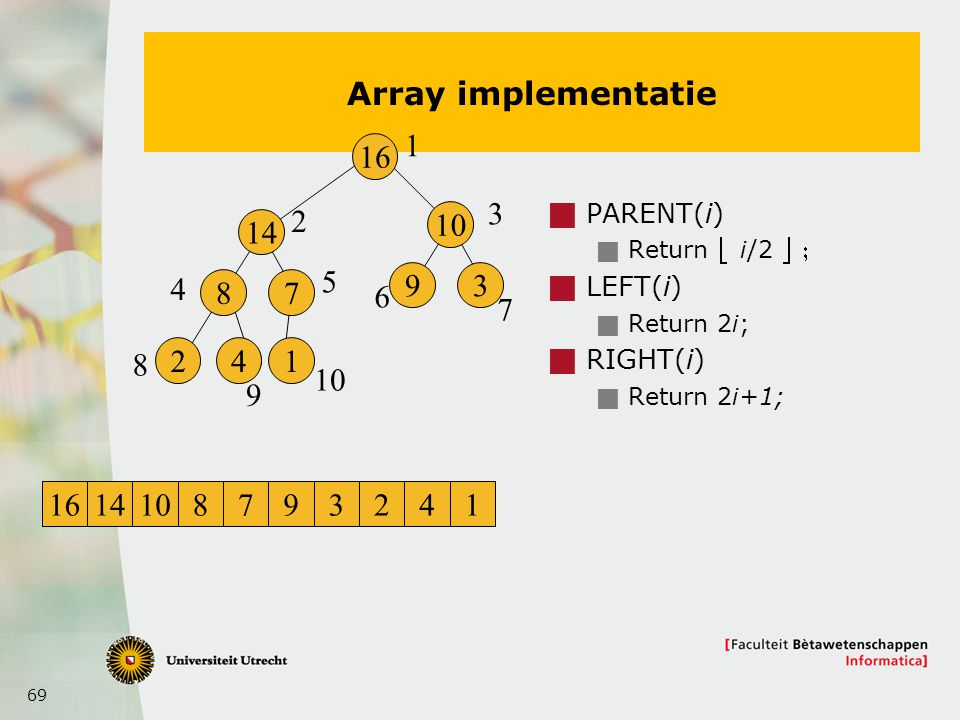
70
“Operaties” op Max-Heap
Build-Max-Heap Maak een heap van een ongeordende array elementen Max-Heap-Insert Voeg een nieuw element toe aan een heap Heap-Extract-Max Haal het grootste element uit de heap en lever dat op Heap-Increase-Key Verhoog de waarde van een element Heap-Maximum Lever de waarde van het grootste element op (zonder iets te veranderen) NB: Notatie boek is wat slordig (verwart ADT en implementatie, maar ik volg ‘m toch)
 NB: Notatie boek is wat slordig (verwart ADT en implementatie, maar ik volg ‘m toch)")
71
Min-heaps Net als Max-heaps met min en max (etc.) omgedraaid
 omgedraaid")
72
Als we deze operaties geimplementeerd hebben, kunnen we sorteren
Build-Max-Heap(A) For i=0 to n-1 do B[n-i] = Heap-Extract-Max(A)
 For i=0 to n-1 do. B[n-i] = Heap-Extract-Max(A)")
73
Belangrijke subroutine: Max-Heapify
Max-heapify(A,i) {Input-aanname: de binaire boom met wortel LEFT(i) en de binaire boom met wortel RIGHT(i) zijn max-heaps} {Output: permutatie, zodat de binaire boom met wortel i is een max-heap}
 {Input-aanname: de binaire boom met wortel LEFT(i) en de binaire boom met wortel RIGHT(i) zijn max-heaps} {Output: permutatie, zodat de binaire boom met wortel i is een max-heap}")
74
1 16 3 2 10 4 5 4 9 3 8 7 6 7 8 2 5 1 10 9 Idee: als i groter (³) is dan beide kinderen: OK, klaar Anders, verwissel met grootste kind en ga dan corrigeren op de plek van ‘t grootste kind
 is dan beide kinderen: OK, klaar Anders, verwissel met grootste kind en ga dan corrigeren op de plek van ‘t grootste kind.")
75
1 16 3 2 10 4 5 4 9 3 8 7 6 7 2 5 1 1 8 16 10 3 2 10 8 5 4 9 3 4 7 6 7 8 2 5 1 10
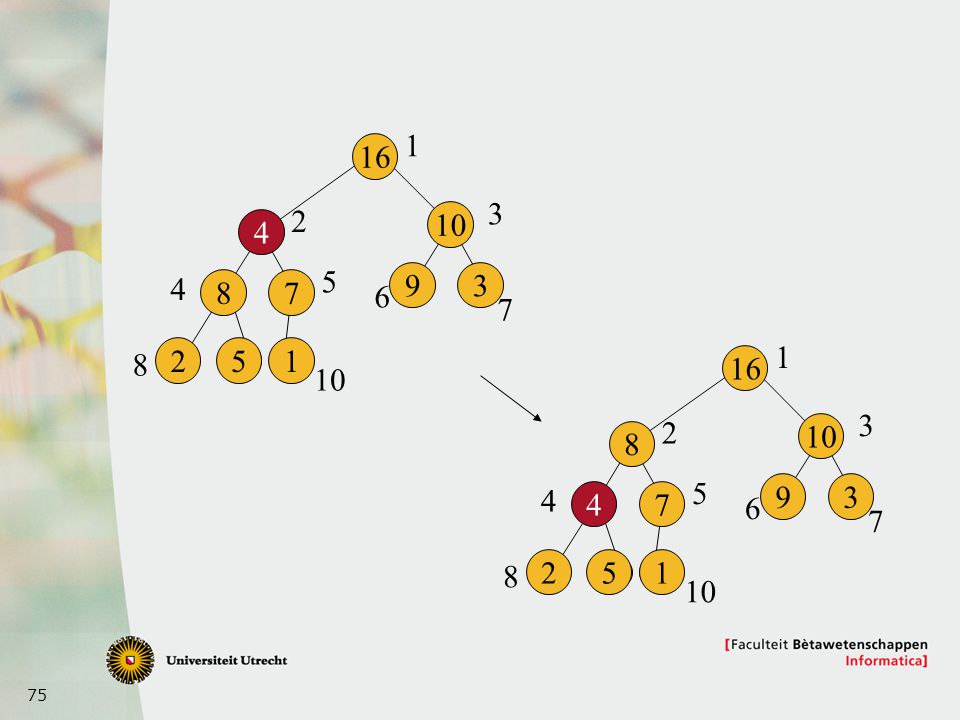
76
Max-heapify Max-Heapify(A,i) links = LEFT(i) rechts = RIGHT(i)
if (links £ heap-size[A] and A[links] > A[i]) then grootste = links else grootste = i if (rechts £ heap-size[A] and A[rechts] > A[grootste]) then grootste = rechts if (grootste ¹ i) then Verwissel A[i] en A[grootste] Max-Heapify(A,grootste)
 then grootste = links. else grootste = i. if (rechts £ heap-size[A] and A[rechts] > A[grootste]) then grootste = rechts. if (grootste ¹ i) then. Verwissel A[i] en A[grootste] Max-Heapify(A,grootste)")
77
Analyse Max-Heapify Correct? Looptijd: O(diepte van i) De diepte van een knoop is nooit meer dan log n, als heap-size(A)=n Dus: O(log n)
")
78
Build-Max-Heap Build-Max-Heap(A) {Input: ongesorteerde rij getallen A[1…lengte(A)]} {Output: A is een permutatie van input die aan max-heap eigenschap voldoet}
![Build-Max-Heap Build-Max-Heap(A) {Input: ongesorteerde rij getallen A[1…lengte(A)]}](http://slideplayer.nl/slide/2205668/8/images/78/Build-Max-Heap+Build-Max-Heap%28A%29+%7BInput%3A+ongesorteerde+rij+getallen+A%5B1%E2%80%A6lengte%28A%29%5D%7D.jpg "{Output: A is een permutatie van input die aan max-heap eigenschap voldoet}")
79
Build-Max-Heap Build-Max-Heap(A) {Input: ongesorteerde rij getallen A[1…lengte(A)]} {Output: A is een permutatie van input die aan max-heap eigenschap voldoet} heap-size[A] = lengte(A); for i= ë lengte(A)/2 û downto 1 do Max-Heapify(A,i) That’s all en ‘t klopt ook nog!
![Build-Max-Heap Build-Max-Heap(A) {Input: ongesorteerde rij getallen A[1…lengte(A)]}](http://slideplayer.nl/slide/2205668/8/images/79/Build-Max-Heap+Build-Max-Heap%28A%29+%7BInput%3A+ongesorteerde+rij+getallen+A%5B1%E2%80%A6lengte%28A%29%5D%7D.jpg "{Output: A is een permutatie van input die aan max-heap eigenschap voldoet} heap-size[A] = lengte(A); for i= ë lengte(A)/2 û downto 1 do. Max-Heapify(A,i) That’s all en. ‘t klopt ook nog!")
80
Correctheid Build-Max-Heap
Invariant: aan het begin van de for-loop is elke knoop i+1, … n de wortel van een max-heap Initieel: klopt, want boompjes van 1 knoop Onderweg: vanwege Max-Heapify… (bespreken details) Terminatie: leuk, want i=0, dus knoop 1 is wortel van max-heap, dus hele array is max-heap for i= ë lengte(A)/2 û downto 1 do Max-Heapify(A,i)
 Terminatie: leuk, want i=0, dus knoop 1 is wortel van max-heap, dus hele array is max-heap. for i= ë lengte(A)/2 û downto 1 do. Max-Heapify(A,i)")
81
Tijdsanalyse Build-Max-Heap
Eenvoudige analyse geeft O(n log n) Voor iedere i tussen 1 en n/2 doen we O(log n) werk Meer precieze analyse geeft O(n) Werk voor knoop i is O(hoogte(i)) De hoogte van de boom is ë log n û (basis 2) Er zijn én / 2h+1ù knopen met hoogte h in de boom Gebruik dat Details op bord
 Voor iedere i tussen 1 en n/2 doen we O(log n) werk. Meer precieze analyse geeft O(n) Werk voor knoop i is O(hoogte(i)) De hoogte van de boom is ë log n û (basis 2) Er zijn én / 2h+1ù knopen met hoogte h in de boom. Gebruik dat. Details op bord.")
82
for i = lengte(A) downto 2 do
Heapsort Build-Max-Heap(A) for i = lengte(A) downto 2 do {A[1] is het maximum} {A[1…heap-size[A]} is een heap, de elementen na heap-size[A] zijn gesorteerd maar niet langer in de heap} {Invariant: i = heapsize[A]} Verwissel A[1] en A[i]; Heapsize[A] --; Max-Heapify[A];
 for i = lengte(A) downto 2 do. {A[1] is het maximum} {A[1…heap-size[A]} is een heap, de elementen na heap-size[A] zijn gesorteerd maar niet langer in de heap} {Invariant: i = heapsize[A]} Verwissel A[1] en A[i]; Heapsize[A] --; Max-Heapify[A];")
83
Analyse Correct, want … O(n log n) tijd want…
 tijd want…")
84
Next: Andere operaties op heaps ...

Verwante presentaties




 DoelgroepVerzondenOntvangen% LG wonen en dagbesteding.>")







 –Analyse –Oplossen.>")






