Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
“resources” en hun zoeksystemen op internet
Eric Sieverts juni 2014 GO Opleidingen

2
doelstelling / leerdoelen
leerdoelen van deze cursus: U bent in staat de voor uw onderzoek meest geschikte bronnen te selecteren U kunt daarbij toe te passen zoeksystemen optimaal gebruiken U kunt anderen adviseren bij de keuze van informatiebronnen en het zoeken daarin Opdracht zoekactie verfijnen tot er bij de eerste 50 geen niet-relevante meer zitten, lettend op deze punten; gebruiken thesaurus of Word-synoniemen; truncatie 2

3
gedachtenbepaling vooraf
wat is een bron? is Google een bron? is het web een bron? NEE (althans voor deze cursus) Google is een zoekingang op heel veel bronnen het web is een medium waarop heel veel soorten bronnen beschikbaar zijn 3
 Google is een zoekingang op heel veel bronnen. het web is een medium waarop heel veel soorten bronnen beschikbaar zijn. 3.")
4
gedachtenbepaling vooraf
uitgangspunt voor de cursus: een bron is een collectie van een bepaald soort informatie die online beschikbaar is, waarbij de soort bepaald kan zijn door de vorm (krantenartikelen, video's, blogs, tweets, plaatjes, ...), en/of door de inhoud (medische informatie, nieuws, wetenschap, ...) 4
, en/of door de inhoud (medische informatie, nieuws, wetenschap, ...) 4.")
5
gedachtenbepaling vooraf
om in "bronnen" te kunnen zoeken / ze te raadplegen, maken we gebruik van zoeksystemen of zoekingangen in die zin is Yahoo! een zoekingang op een veelheid aan bronnen. in die zin is IceRocket een zoekingang op weblogs. in die zin is een zoekingang op wetenschappelijke bronnen. 5

6
programma 9:30 / welkom, introductie
(0) inleiding, bronnen, zoekingangen (1) boeken, artikelen, wetenschap ca. 10:45 / thee- en koffiepauze (2) feiten, naslag, vertaling (3) nieuws, kranten, tijdschriften (4) “oud” nieuws ca. 12:30 / lunchpauze (5) weblogs, feeds, (6) tweets, social (7) multimedia / AV ca. 15:00 / thee- en koffiepauze (8) algemene versus gespecialiseerde zoekingangen, diepe web, persoonlijke zoekmachines (9) beoordelen van bronnen (10) bijblijven 6
 inleiding, bronnen, zoekingangen. (1) boeken, artikelen, wetenschap. ca. 10:45 / thee- en koffiepauze. (2) feiten, naslag, vertaling. (3) nieuws, kranten, tijdschriften. (4) oud nieuws. ca. 12:30 / lunchpauze. (5) weblogs, feeds, (6) tweets, social. (7) multimedia / AV. ca. 15:00 / thee- en koffiepauze. (8) algemene versus gespecialiseerde zoekingangen, diepe web, persoonlijke zoekmachines. (9) beoordelen van bronnen. (10) bijblijven. 6.")
7
bekend verondersteld verschil tussen soorten diensten op internet
typerende aanbieders op internet domeinenstructuur en url-opbouw verschillende soorten zoekstrategieën en -doelen verschil/toepassing gidsen versus zoekmachines werking en geavanceerde opties van zoekmachines betekenis van recall en precision betekenis diepe/onzichtbare web wijze van ranking zoekmachines, werking PageRank startpagina voor zoekhulpmiddelen 7

8
soorten informatiebronnen
naar aard van informatie wetenschappelijke informatie naslagwerken nieuwsberichten krantenartikelen (digitale) boeken ... naar “medium” webpagina’s pdf’s images videos weblogs rss-feeds tweets ... ander onderscheid: primair - secundair - tertiair KNMI - weer-startpagina - StartNederland doorzoekbaarheid alleen metadata full-text Opdracht zoekactie verfijnen tot er bij de eerste 50 geen niet-relevante meer zitten, lettend op deze punten; gebruiken thesaurus of Word-synoniemen; truncatie 8
 boeken. ... naar medium webpagina’s. pdf’s. images. videos. weblogs. rss-feeds. tweets. ... ander onderscheid: primair - secundair - tertiair. KNMI - weer-startpagina - StartNederland. doorzoekbaarheid. alleen metadata - full-text. Opdracht zoekactie verfijnen tot er bij de eerste 50 geen niet-relevante meer zitten, lettend op deze punten; gebruiken thesaurus of Word-synoniemen; truncatie. 8.")
9
soorten informatiebronnen
niet al zulke combinaties zijn zinvol/mogelijk web- pagina pdf image video weblog tweet rss-feed wetenschap naslag nieuws kranten eBooks ... Opdracht zoekactie verfijnen tot er bij de eerste 50 geen niet-relevante meer zitten, lettend op deze punten; gebruiken thesaurus of Word-synoniemen; truncatie 9

10
informatiebronnen en hun zoekingangen (de zoektools)
kun je alles (ook) met Google vinden? welke Googles (en Bing’s) zijn er allemaal? (image-, blog-, video-, news-, book-, scholar-, groups-search, maar meeste ook geïntegreerd in gewone Google) kun je met die Googles alles vinden? welke alternatieven zijn er voor die Googles? zie bijv. trovando.it of wiinkz alternatieven voor het diepe (en betaalde) web Opdracht zoekactie verfijnen tot er bij de eerste 50 geen niet-relevante meer zitten, lettend op deze punten; gebruiken thesaurus of Word-synoniemen; truncatie 10
 met Google vinden welke Googles (en Bing’s) zijn er allemaal (image-, blog-, video-, news-, book-, scholar-, groups-search, maar meeste ook geïntegreerd in gewone Google) kun je met die Googles alles vinden welke alternatieven zijn er voor die Googles zie bijv. trovando.it of wiinkz alternatieven voor het diepe (en betaalde) web. Opdracht zoekactie verfijnen tot er bij de eerste 50 geen niet-relevante meer zitten, lettend op deze punten; gebruiken thesaurus of Word-synoniemen; truncatie. 10.")
11
boeken & (wetenschappelijke) artikelen
Google Books Hathitrust Digital Library (open book scan project) Delpher (gedigitaliseerde boeken -en kranten- van de KB en NL-univ.) Amazon (ook reviews, inhoud, boek-boek citaties) Worldcat (catalogus van bibliotheken met postcode-functie) Librarything (catalogus van boeken van bezitters) GoodReads (reviews, recommandatie, vrienden, ...) Picarta Bibliotheek.nl DOAB (directory of open access books) Open Textbook Library (open access leerboeken) enz. artikelen (e.d.) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 11
 Delpher (gedigitaliseerde boeken -en kranten- van de KB en NL-univ.) Amazon (ook reviews, inhoud, boek-boek citaties) Worldcat (catalogus van bibliotheken met postcode-functie) Librarything (catalogus van boeken van bezitters) GoodReads (reviews, recommandatie, vrienden, ...) Picarta. Bibliotheek.nl. DOAB (directory of open access books) Open Textbook Library (open access leerboeken) enz. artikelen (e.d.) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. 11.")
12
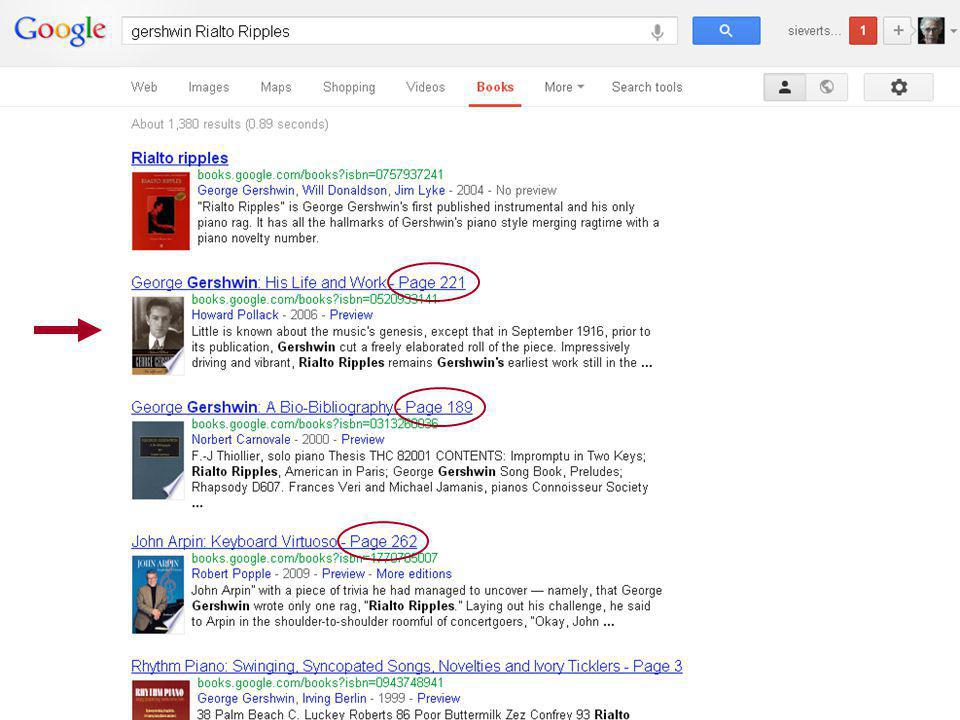
boeken: Google Books van kaft tot kaft gescand (en doorzoekbaar!)
sterk voor ontdekken van niet-hoofdinhoud van boeken vaak beperkt doorbladerbaar (no preview / snippet view / limited preview / full preview) content via uitgevers en via grote bibliotheken probleem met copyrighted materiaal uit bibliotheken vergeleken met Amazon search inside: meer oud, minder recent ook ‘My Library’ optie vb NL-boeken niet alleen uit Gent en KB, ook uit US/UK nu ook enkele ‘magazines’ metadata op about-this-book-pagina bibliotheken linken vanuit catalogus (bijv. Picarta) 12
 content via uitgevers en via grote bibliotheken. probleem met copyrighted materiaal uit bibliotheken. vergeleken met Amazon search inside: meer oud, minder recent. ook ‘My Library’ optie vb. NL-boeken niet alleen uit Gent en KB, ook uit US/UK. nu ook enkele ‘magazines’ metadata op about-this-book-pagina. bibliotheken linken vanuit catalogus (bijv. Picarta) 12.")
16
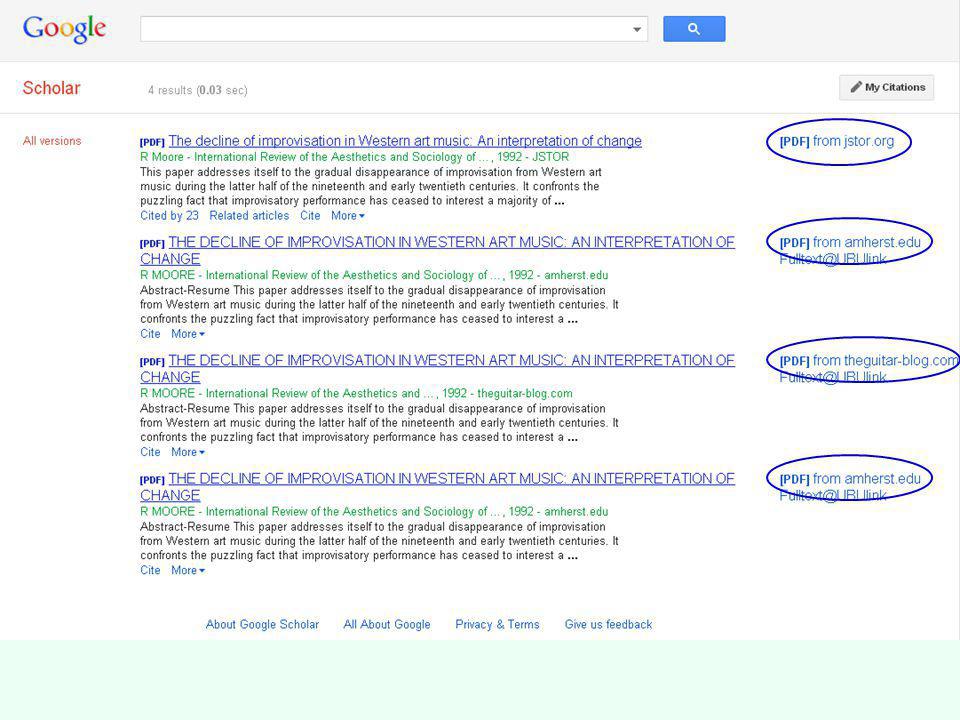
boeken & (wetenschappelijke) artikelen (2)
artikelen (e.d.) Google Scholar (artikelen, rapporten, proefschriften, ...) sEURch / UvA-library (zoeksystemen van EUR / UvA) ScienceDirect (artikelen van Elsevier) OAIster / BASE (uit academische repositories / Open Access) NARCIS ( proefschriften, publicaties [veel artikelen] uit NL) DOAJ (artikelen in Open Access tijdschriften) SciELO (Spaans/Portugees talige wetenschappelijke artikelen) Magportal (ook -Engelstalige- publiekstijdschriften) DeepDyve (wetenschappelijke artikelen "te huur") enz. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 16
 Google Scholar (artikelen, rapporten, proefschriften, ...) sEURch / UvA-library (zoeksystemen van EUR / UvA) ScienceDirect (artikelen van Elsevier) OAIster / BASE (uit academische repositories / Open Access) NARCIS ( proefschriften, publicaties [veel artikelen] uit NL) DOAJ (artikelen in Open Access tijdschriften) SciELO (Spaans/Portugees talige wetenschappelijke artikelen) Magportal (ook -Engelstalige- publiekstijdschriften) DeepDyve (wetenschappelijke artikelen te huur ) enz. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. 16.")
17
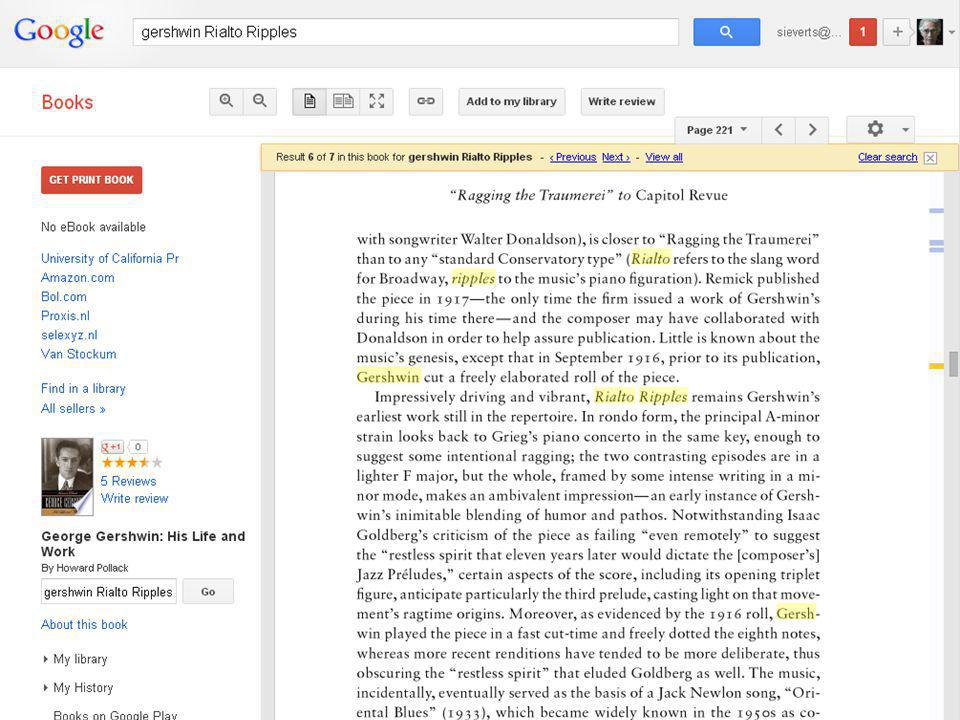
wetenschap: Google Scholar
> 100 miljoen wetenschappelijke publicaties verschil full record en aanwezigheid als ‘citation’ verschil full-text links en bibliografische links concurrent voor Web of Science, Scopus, Picarta, OAIster, DOAJ, Ingenta gericht geïndexeerd in vele bronnen (uitgevers, abstract-databases, universiteiten, repositories, ...) met citaties! aantallen citaties mede gebruikt voor ranking (waardoor recente publicaties relatief laag scoren) .... >> 17
 met citaties! aantallen citaties mede gebruikt voor ranking. (waardoor recente publicaties relatief laag scoren) .... >> 17.")
18
wetenschap: Google Scholar
.... advanced search beperkt, nog veel fouten door computer-generated metadata van zoekresultaat naar volledige tekst vaak een probleem (niet aanwezig, alleen tegen betaling) soms veel versies van artikel (waaronder wel gratis) wel zichtbaar welke artikelen gratis versie hebben koppeling aan bibliotheekbezit, Google Scholar library programme voegt links naar eigen bezit toe geen info over bronnen, updates 18
 soms veel versies van artikel (waaronder wel gratis) wel zichtbaar welke artikelen gratis versie hebben. koppeling aan bibliotheekbezit, Google Scholar library programme voegt links naar eigen bezit toe. geen info over bronnen, updates. 18.")
19
als dit artikel interessant is,
open access als dit artikel interessant is, dan deze 23 recentere waarschijnlijk ook ## citaties/ aangehaald abonnement univ. utrecht

21
Maak nu de opdrachten van onderdeel 1

22
boeken & (wetenschappelijke) artikelen (3)
artikelen (e.d.) vakspecifiek zoeken (gratis zoekingangen; vaak alleen de metadata) geneeskunde: Pubmed , PLoS-one economie: RepEc computerkunde, informatica: CiteSeer onderwijs: ERIC (hoge energie-) fysica: SPIRES-HEP, ArXiv bibliotheekwetenschap: LISTA filosofie: International Philosophical Bibliography transport: TRID enz. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 22 22
 vakspecifiek zoeken. (gratis zoekingangen; vaak alleen de metadata) geneeskunde: Pubmed , PLoS-one. economie: RepEc. computerkunde, informatica: CiteSeer. onderwijs: ERIC. (hoge energie-) fysica: SPIRES-HEP, ArXiv. bibliotheekwetenschap: LISTA. filosofie: International Philosophical Bibliography. transport: TRID. enz. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp")
23
2. feiten & naslag encyclopedieën e.d. vragen & antwoorden
wikipedia overzicht in Yahoo Directory overzicht in Open Directory internet movie database vragen & antwoorden Quora Yahoo-answers (FAQs: internet FAQ consortium ) woordenboeken, vertaaldiensten e.d. dataverzamelingen ... Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 23
 woordenboeken, vertaaldiensten e.d. dataverzamelingen. ... Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. 23.")
24
wikipedia in >280 talen
levert “wisdom of the crowds” altijd “wisdom”? goed voor “feitelijke” onderwerpen veel detailonderwerpen (>20 miljoen lemma’s, >1 miljoen NL) soms nuttig om relevante eigen publicaties / boeken uit eigen collectie als referenties aan lemma toe te voegen toch wel beleid & beheer: stewards, administrators met Google site-commando kun je alle taalversies tegelijk doorzoeken: zoekwoord site:wikipedia.org Qwika: wikipedia metasearch (1158 wiki's in 12 talen, incl. computer-vertaling) 24
 soms nuttig om relevante eigen publicaties / boeken uit eigen collectie als referenties aan lemma toe te voegen. toch wel beleid & beheer: stewards, administrators. met Google site-commando kun je alle taalversies tegelijk doorzoeken: zoekwoord site:wikipedia.org. Qwika: wikipedia metasearch (1158 wiki s in 12 talen, incl. computer-vertaling) 24.")
25
2. feiten & naslag (2) encyclopedieën e.d. vragen & antwoorden
woordenboeken, vertaaldiensten e.d. answers.com (voert een metasearch uit) Roget thesaurus Acronymfinder Bartleby Google Translate Mijn Woordenboek synoniemen Synoniemen.net overzicht in Open Directory overzicht in Open Directory Nederlands dataverzamelingen enz. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 25
 Roget thesaurus. Acronymfinder. Bartleby. Google Translate. Mijn Woordenboek synoniemen. Synoniemen.net. overzicht in Open Directory. overzicht in Open Directory Nederlands. dataverzamelingen. enz. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. 25.")
26
2. feiten & naslag (3) ... dataverzamelingen
linked (open) data (niet makkelijk bruikbaar voor eindgebruikers): data.overheid.nl, UK-open-data, EU-open-data, data.gov (US), open-data-site-finder, ... statistieken: statline, eurostat, UNdata, worldbank, oecd, ... visualisatietool: Google Public Data Explorer wetenschappelijke datasets: DANS dataportal (NL), Narcis-data, dataverse-network, Re3data, datacite (metasearch), ... algemene dataset-zoekmachines: datamarket, knoema, quandl, zanran zoekmachine voor naslagwerkpagina’s + berekeningen Wolfram Alpha Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp Maak nu de opdrachten van onderdeel 2 26
 data (niet makkelijk bruikbaar voor eindgebruikers): data.overheid.nl, UK-open-data, EU-open-data, data.gov (US), open-data-site-finder, ... statistieken: statline, eurostat, UNdata, worldbank, oecd, ... visualisatietool: Google Public Data Explorer. wetenschappelijke datasets: DANS dataportal (NL), Narcis-data, dataverse-network, Re3data, datacite (metasearch), ... algemene dataset-zoekmachines: datamarket, knoema, quandl, zanran. zoekmachine voor naslagwerkpagina’s + berekeningen Wolfram Alpha. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. Maak nu de opdrachten van onderdeel")
27
3. nieuws, kranten, tijdschriften
Google News, Yahoo News, Bing News, ... BBC , CNN e.d. nu.nl € LexisNexis, € Factiva sites van kranten en tijdschriften overzicht Engelstalig wereldwijd: world-newspapers.com overzicht Nederlandse kranten: kranten.startnederland.nl overzicht Nederlandse tijdschriften: tijdschrift.startnederland.nl Newslink-magazines .... [weblogs & tweets: zie 5 en 6] [video/tv-nieuws: zie 7] Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 27

28
gespecialiseerd: Google News
Engelstalig nieuws uit 4500 bronnen + aparte versies in andere talen dan Engels: chinees (1000 bronnen) duits (700 bronnen) frans (500 bronnen) hebreeuws (100 bronnen) italiaans (250 bronnen) japans (600 bronnen) koreaans (550 bronnen) nederlands (>400 bronnen) portugees (200 bronnen) spaans (700 bronnen) enz. Maak nu de opdrachten van onderdeel 3 28
 duits (700 bronnen) frans (500 bronnen) hebreeuws (100 bronnen) italiaans (250 bronnen) japans (600 bronnen) koreaans (550 bronnen) nederlands (>400 bronnen) portugees (200 bronnen) spaans (700 bronnen) enz. Maak nu de opdrachten van onderdeel")
29
4. archief & oud nieuws web archive ("way-back-machine")
(oude versies van websites, terug tot 1996, ingang via -oude- url) historische nederlandse kranten (versnipperd aanbod) Delpher (gedigitaliseerde kranten KB -samen met boeken) landelijke krantendatabank (ook papieren collecties) Los: Groene Amsterdammer (>1877), Leeuwarder Courant (>1752) historische buitenlandse kranten British newspapers historic American newspapers / Google news archive digitized Australian newspapers internationaal overzicht € LexisNexis ‘echte archieven’ via archiefzoeker.nl, archivegrid, ... Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp Maak nu de opdrachten van onderdeel 4 29
 historische nederlandse kranten (versnipperd aanbod) Delpher (gedigitaliseerde kranten KB -samen met boeken) landelijke krantendatabank (ook papieren collecties) Los: Groene Amsterdammer (>1877), Leeuwarder Courant (>1752) historische buitenlandse kranten. British newspapers historic American newspapers / Google news archive. digitized Australian newspapers. internationaal overzicht. € LexisNexis. ‘echte archieven’ via archiefzoeker.nl, archivegrid, ... Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. Maak nu de opdrachten van onderdeel")
30
5. blogs & rss-feeds Google blogsearch Icerocket Technorati
(Exalead >> achteraf inperken op blogs ) denk aan verschil tussen ingang op individuele berichten en ingang op blogs of feeds als geheel wie citeert wie? (google blogsearch) filtermogelijkheid op “autoriteit” ?=? belang, kwaliteit, .... filter op termen binnen je feedreader blogs of onderwerp volgen met blogsalert? #hashtags Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 30
 denk aan verschil tussen ingang op individuele berichten en ingang op blogs of feeds als geheel. wie citeert wie (google blogsearch) filtermogelijkheid op autoriteit = belang, kwaliteit, .... filter op termen binnen je feedreader. blogs of onderwerp volgen met blogsalert #hashtags. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. 30.")
31
5. blogs & rss-feeds zoeken naar RSS feeds (meer dan alleen blogs)
CTRLQ: RSS Searchhub: overzicht (op "makeuseof") voor vinden van feeds van bepaalde bron / website voor vinden van feeds waarin bepaald onderwerp centraal staat Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp Maak nu de opdrachten van onderdeel 5 31
 voor vinden van feeds van bepaalde bron / website. voor vinden van feeds waarin bepaald onderwerp centraal staat. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. Maak nu de opdrachten van onderdeel")
32
6. tweets en social search (1)
Twitter in 140 tekens vaak met verkorte links vaak met foto- of video-link vaak met hashtags (#afgesprokentrefwoord) Twitter als continue informatiebron: volg de "juiste" personen die interessante nieuwtjes, rapporten, artikelen via Twitter delen zoeken twitter (ook advanced search) topsy snapbird (alle tweets van 1 persoon waarvan je twitternaam kent) twicsy (foto's op twitter) ... Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 32 32
 Twitter als continue informatiebron: volg de juiste personen die interessante nieuwtjes, rapporten, artikelen via Twitter delen. zoeken. twitter (ook advanced search) topsy. snapbird (alle tweets van 1 persoon waarvan je twitternaam kent) twicsy (foto s op twitter) ... Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp")
33
6. tweets en social search (2)
veel Twitter hulptools archief van al weer gewiste tweets van politici: politwoops (ook nl) twubs (bijv. bij congres) : volg in real-time alles met bepaalde hashtag en voeg die tag automatisch toe aan eigen berichten ... links uit tweets automatisch bewaren als social bookmarks via packrati.us >> delicious, pinboard, diigo, ... Facebook "graph-search" voor gestructureerd zoeken (in Engelstalig interface) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 33 33
 twubs (bijv. bij congres) : volg in real-time alles met bepaalde hashtag en voeg die tag automatisch toe aan eigen berichten. ... links uit tweets automatisch bewaren als social bookmarks. via packrati.us >> delicious, pinboard, diigo, ... Facebook graph-search voor gestructureerd zoeken. (in Engelstalig interface) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp")
34
Facebook Graph Search alles wat gebruikers registreren, wordt gestructureerd opgeslagen in Facebook's graph (met gestandaardiseerde betekenis), waardoor ook gestructureerd gezocht kan worden
, waardoor ook gestructureerd gezocht kan worden.")
35
6. tweets en social search (3)
“Real time / social search engines” social-searcher, socialmention, whostalkin, … (tweets + blogs + facebook + …) Google personal results / Google+ ("search plus your world") Forumdiscussies omgili, (boardtracker), ... Google groups (ook oude nieuwgroep-discussies) voor methoden van onderzoek: zie adviezen van Henk van Ess in "de digitale detective" (2012) How to: use social media in newsgathering (2012) zie ook: 50 Top Tools for Social Media Monitoring (2013) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp Maak nu de opdrachten van onderdeel 6 35 35
 Google personal results / Google+ ( search plus your world ) Forumdiscussies. omgili, (boardtracker), ... Google groups (ook oude nieuwgroep-discussies) voor methoden van onderzoek: zie adviezen van Henk van Ess in de digitale detective (2012) How to: use social media in newsgathering (2012) zie ook: 50 Top Tools for Social Media Monitoring (2013) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. Maak nu de opdrachten van onderdeel")
36
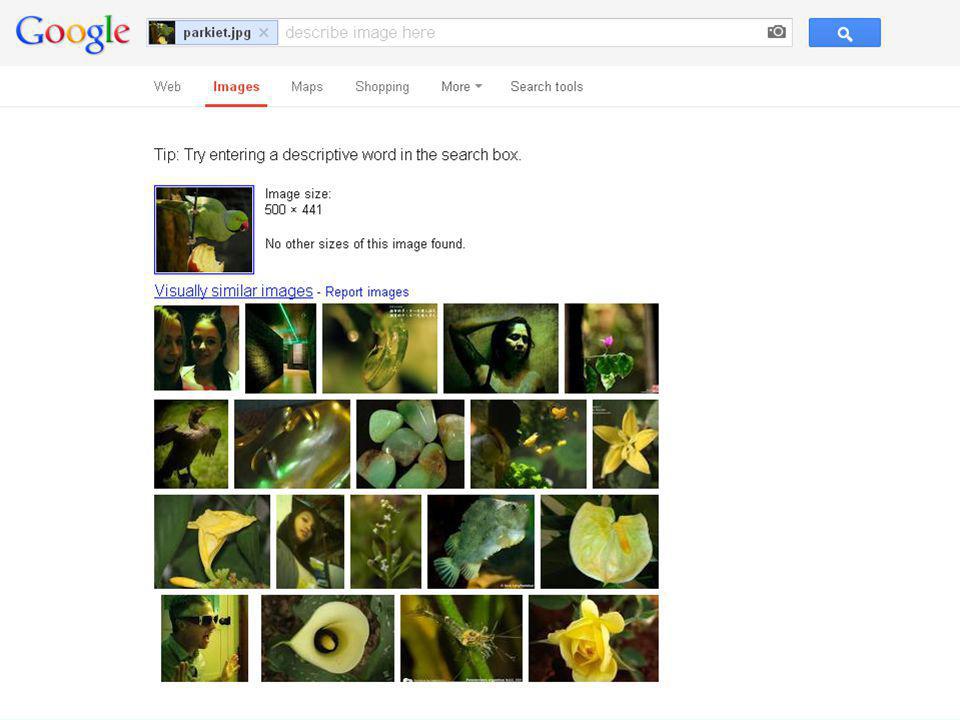
7. multimedia images video audio
Google-image (simpele beeldherkenning; ook foto’s uit Picasa) Yahoo-image (ook veel foto’s uit Flickr) Bing-image Ask-image Exalead-image (veel verschillen in zoekresultaten door verschillen in “tekstzoekvelden”) Flickr (zoekt vooral op tags; ondersteunt “Creative Commons” ) Andere uploadsites: Pbase, Smugsmug, Photobucket, Zoom, Zenfolio Google (search by image), Tineye (zoekt -bijna- exacte copieën) Retrievr (voorbeeldzoeken met beeldherkenning op Flickr) speciale sites (beeldbank nationaal archief, wikimedia commons, ...) geografische ingang (panoramio [google-maps], worldc.am [instagram], ...) video audio Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 36
 Yahoo-image (ook veel foto’s uit Flickr) Bing-image. Ask-image. Exalead-image. (veel verschillen in zoekresultaten door verschillen in tekstzoekvelden ) Flickr (zoekt vooral op tags; ondersteunt Creative Commons ) Andere uploadsites: Pbase, Smugsmug, Photobucket, Zoom, Zenfolio. Google (search by image), Tineye (zoekt -bijna- exacte copieën) Retrievr (voorbeeldzoeken met beeldherkenning op Flickr) speciale sites (beeldbank nationaal archief, wikimedia commons, ...) geografische ingang (panoramio [google-maps], worldc.am [instagram], ...) video. audio. Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. 36.")
37
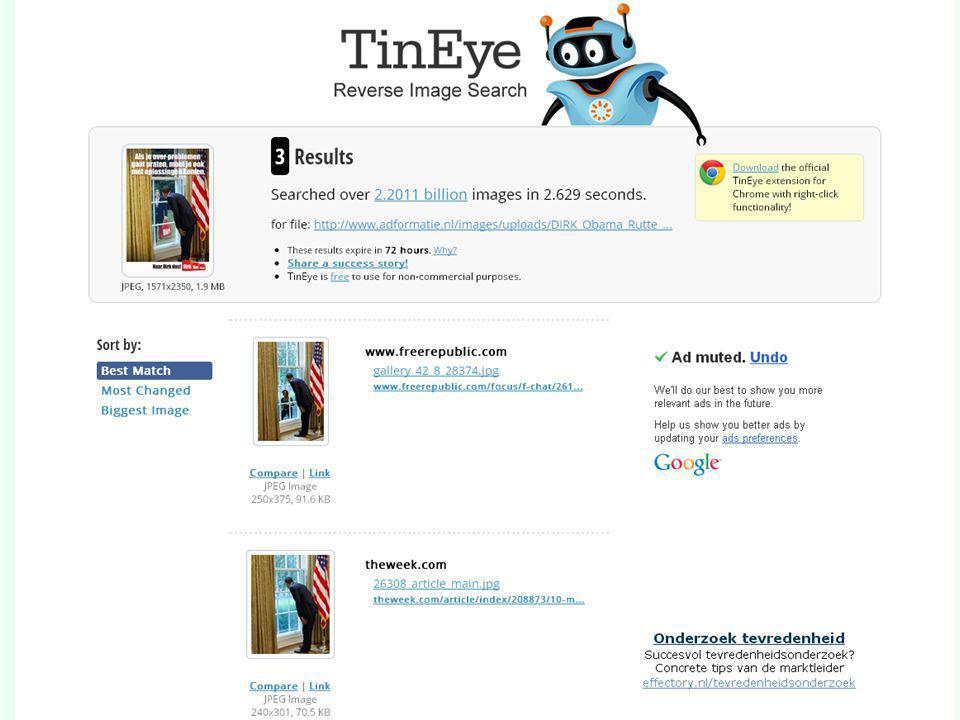
voorbeeld

40
7. multimedia (2) images video audio
YouTube (groei: 70 uur/minuut, ook "filters") Youtube Edu channel Blinkx (omroepen - 35 miljoen uur video, spraakherkenning?) VoxaleadNews (met spraakherkenning - in meer talen - ook NL!) Bing-video (niet makkelijk te vinden vanuit basis-scherm) Google-video (ook video’s uit YouTube; zoekt alleen in metadata) ScienceCinema (met spraakherkenning! gaat vooral over energie) TV-uitzendingen: Uitzending gemist (beperkte zoekfunctie) Beeld & Geluid (doorzoekt metadata; gebruik “uitgebreid zoeken”) Academia (selectie uit Beeld & Geluid voor hoger onderwijs; betaald) audio VoxaleadNews (met spraakherkenning - in meer talen - ook NL) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp 40 Maak nu de opdrachten van onderdeel 7
 Youtube Edu channel. Blinkx (omroepen - 35 miljoen uur video, spraakherkenning ) VoxaleadNews (met spraakherkenning - in meer talen - ook NL!) Bing-video (niet makkelijk te vinden vanuit basis-scherm) Google-video (ook video’s uit YouTube; zoekt alleen in metadata) ScienceCinema (met spraakherkenning! gaat vooral over energie) TV-uitzendingen: Uitzending gemist (beperkte zoekfunctie) Beeld & Geluid (doorzoekt metadata; gebruik uitgebreid zoeken ) Academia (selectie uit Beeld & Geluid voor hoger onderwijs; betaald) audio. VoxaleadNews (met spraakherkenning - in meer talen - ook NL) Opdrachten: vergelijk opbrengst Engels versus Nederlands voor algemeen en nieuwsonderwerp. 40. Maak nu de opdrachten van onderdeel 7.")
41
8. gespecialiseerde versus algemene zoekingangen
selectief & vaak “dieper” dan algemene zoekmachine interne zoekfunctie van individuele site kant en klare onderwerpsgerichte zoekingangen Worldwidescience (wetenschap algemeen) Findlaw (rechten USA) WebMD / Medscape (geneeskunde) Google-finance (financiële gegevens + nieuws) Searchgov (metasearch Amerikaanse overheidssites) ..... homemade met : Google CSE, Blekko (slashtags) zelf selecteren welke sites (url’s) in zoekmachine moeten worden meegenomen 41
 Findlaw (rechten USA) WebMD / Medscape (geneeskunde) Google-finance (financiële gegevens + nieuws) Searchgov (metasearch Amerikaanse overheidssites) homemade met : Google CSE, Blekko (slashtags) zelf selecteren welke sites (url’s) in zoekmachine moeten worden meegenomen. 41.")
42
ingangen op diepe web toegang tot het diepe web
“handmatig” (elke database afzonderlijk doorzoeken) geen universele overzichten meer beschikbaar voor "wetenschap" al eerder verzamelzoeksystemen genoemd “halfautomatisch” (doorzocht via desktop metasearch engine) copernic-agent (metasearch vanaf eigen PC) “automatisch” (gegevens uit bepaalde database/bron zitten ook al -allemaal?- in algemene zoekmachines) bijv. catalogus UB Wageningen Automatisch bv bij NIWI (NOD?) Maak nu de opdrachten van onderdeel 8 42
 geen universele overzichten meer beschikbaar. voor wetenschap al eerder verzamelzoeksystemen genoemd. halfautomatisch (doorzocht via desktop metasearch engine) copernic-agent (metasearch vanaf eigen PC) automatisch (gegevens uit bepaalde database/bron zitten ook al -allemaal - in algemene zoekmachines) bijv. catalogus UB Wageningen. Automatisch bv bij NIWI (NOD ) Maak nu de opdrachten van onderdeel")
43
9. vergelijken en beoordelen van (zoekingangen van) bronnen
wat voor soort materiaal zit er in primaire (c.q. full-text) vs. secundaire informatie naslag / nieuws / onderzoekresultaten / statistieken / websites / artikelen / boeken / rapporten / ... welk onderwerpsgebied welke doelgroep (niveau) hoeveel zit erin (aantal items, dekkingsgraad, ...) vaak moeilijk te bepalen door verschillen in functionaliteit en onbetrouwbare aantallen voor zoekresultaten uit zoekmachines hoe goed werkt het zoeksysteem (functionaliteit, gebruiksgemak, selectiviteit, ...) wat is de kwaliteit van de content zie bijvoorbeeld JISC Academic Database Assessment Tool bekijk: bron zelf / Wikipedia / leveranciers / JISC 43
 vs. secundaire informatie. naslag / nieuws / onderzoekresultaten / statistieken / websites / artikelen / boeken / rapporten / ... welk onderwerpsgebied. welke doelgroep (niveau) hoeveel zit erin (aantal items, dekkingsgraad, ...) vaak moeilijk te bepalen door verschillen in functionaliteit en. onbetrouwbare aantallen voor zoekresultaten uit zoekmachines. hoe goed werkt het zoeksysteem. (functionaliteit, gebruiksgemak, selectiviteit, ...) wat is de kwaliteit van de content. zie bijvoorbeeld JISC Academic Database Assessment Tool. bekijk: bron zelf / Wikipedia / leveranciers / JISC. 43.")
44
beoordelingscriteria voor websites
web-gerelateerde factoren beoordeel domeinnaam (bijv.: edu, edu.au, edu.sg, edu.ng, edu.lb, ac.uk, gov, gov.uk, gov.hk, gov.au, gov.on.ca, gob.es, gob.mx, gob.ve, gob.ec, ...) Alexa rank van website (hoeveelheid web traffic); tools daarvoor: Google pagerank van website (bepaald door aantal en aard van backlinks); tools daarvoor: zoek de "backlinks" zelf Google: met link: commando - erg incompleet OpenSiteExplorer: erg compleet - betaalde dienst Alexa: toont 5 belangrijkste backlinks wie is eigenaar van domeinnaam; tools daarvoor: 44
 Alexa rank van website (hoeveelheid web traffic); tools daarvoor: Google pagerank van website (bepaald door. aantal en aard van backlinks); tools daarvoor: zoek de backlinks zelf. Google: met link: commando - erg incompleet. OpenSiteExplorer: erg compleet - betaalde dienst. Alexa: toont 5 belangrijkste backlinks. wie is eigenaar van domeinnaam; tools daarvoor:")
45
beoordelingscriteria voor websites
Nog wat algemene factoren: Goede opmaak Aanduiding maker/auteur (“about us”) Aanduiding postadres, telefoonnummer Aanduiding doel/doelgroep Geen reclame en pop-ups Heldere navigatie Interne zoekfunctie Voldoende snelheid server Backlinks door gezaghebbende organisaties Up to date? Zinnige datering inhoud Geen grof taalgebruik Geen kinderlijk taalgebruik Geen storende taalfouten Zelfs als alles in orde lijkt, bij gevoelige onderwerpen toch nog uitkijken Maak nu de opdrachten van onderdeel 9 45
 Aanduiding postadres, telefoonnummer. Aanduiding doel/doelgroep. Geen reclame en pop-ups. Heldere navigatie. Interne zoekfunctie. Voldoende snelheid server. Backlinks door gezaghebbende organisaties. Up to date Zinnige datering inhoud. Geen grof taalgebruik. Geen kinderlijk taalgebruik. Geen storende taalfouten. Zelfs als alles in orde lijkt, bij gevoelige onderwerpen toch nog uitkijken. Maak nu de opdrachten van onderdeel")
46
10. bijblijven met bronnen
Weblogs: Resourceblog InfoDocket (Gary Price) SearchEngineLand (Sullivan, Sherman) InternetNews/WebSearchGuide (Gwen Harris) Phil Bradley's weblog “Spion” op bronnenlijst (Copernic Tracker, WatchThatPage, …) RSS-feed op lijsten indien aanwezig Pandia FreePint 46
 SearchEngineLand (Sullivan, Sherman) InternetNews/WebSearchGuide (Gwen Harris) Phil Bradley s weblog. Spion op bronnenlijst (Copernic Tracker, WatchThatPage, …) RSS-feed op lijsten indien aanwezig. Pandia. FreePint. 46.")
47
bijblijven met behulp van RSS
Rich Site Summary / Really Simple Syndication voor sites met (on)regelmatig nieuwe actuele inhoud, bijvoorbeeld nieuwsbrieven, weblogs (+ ook sommige databases) lezen, beheren als ware het maakt gebruik van xml-structuur vereist software (reader), bijv. Feedreader, Feeddemon, Shrook, … of online lezen bijv. bij Netvibes, Bloglines, Digg reader toevoegen van een ‘feed’: op pagina url onder oranje (soms blauw) rss- of xml-logo copiëren en in reader plakken drie nauwverwante formats: rss/atom/rdf (readers multiformat) zoeken van berichten: Google Blogsearch, Technorati, IceRocket, real-time search [zie eerder] zoeken van feeds: CTRLQ, RSSsearchhub [zie eerder] 47
regelmatig nieuwe actuele inhoud, bijvoorbeeld nieuwsbrieven, weblogs (+ ook sommige databases) lezen, beheren als ware het . maakt gebruik van xml-structuur. vereist software (reader), bijv. Feedreader, Feeddemon, Shrook, … of online lezen bijv. bij Netvibes, Bloglines, Digg reader. toevoegen van een ‘feed’: op pagina url onder oranje (soms blauw) rss- of xml-logo copiëren en in reader plakken. drie nauwverwante formats: rss/atom/rdf (readers multiformat) zoeken van berichten: Google Blogsearch, Technorati, IceRocket, real-time search [zie eerder] zoeken van feeds: CTRLQ, RSSsearchhub [zie eerder] 47.")
Verwante presentaties









: de collectie Fysieke collectie: boeken en naslagwerken / tijdschriften / AVM / scripties Digitale.>")










