Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Methodologie & Statistiek I Principes van statistisch toetsen 5.1

2
U kunt deze presentatie ook op uw eigen PC afspelen!
Gebruikmaken van internet: Education Health sciences Presentations of lectures “op dit moment ……. beschikbaar Opening --- Hoofdstuk 5 (Principes van …) Powerpointviewer downloaden”
 Powerpointviewer downloaden")
3
Deze diapresentatie werd vervaardigd door Michel Janssen
van de Capaciteitsgroep Methodologie en Statistiek. De presentatie mag alleen worden gecopieerd voor eigen gebruik door studenten en medewerkers van de Universiteit Limburg in Maastricht. Met eventuele op- en aanmerkingen kunt u terecht bij: Universiteit Maastricht Capaciteitsgroep M&S Tjaart Imbos Postbus 616 6200 MD Maastricht

4
Methodologie & Statistiek I Principes van statistisch toetsen 5.1
21 januari 2002

5
Principes van statistisch toetsen
Noodzakelijk voor een goed begrip van andere statistische onderwerpen

6
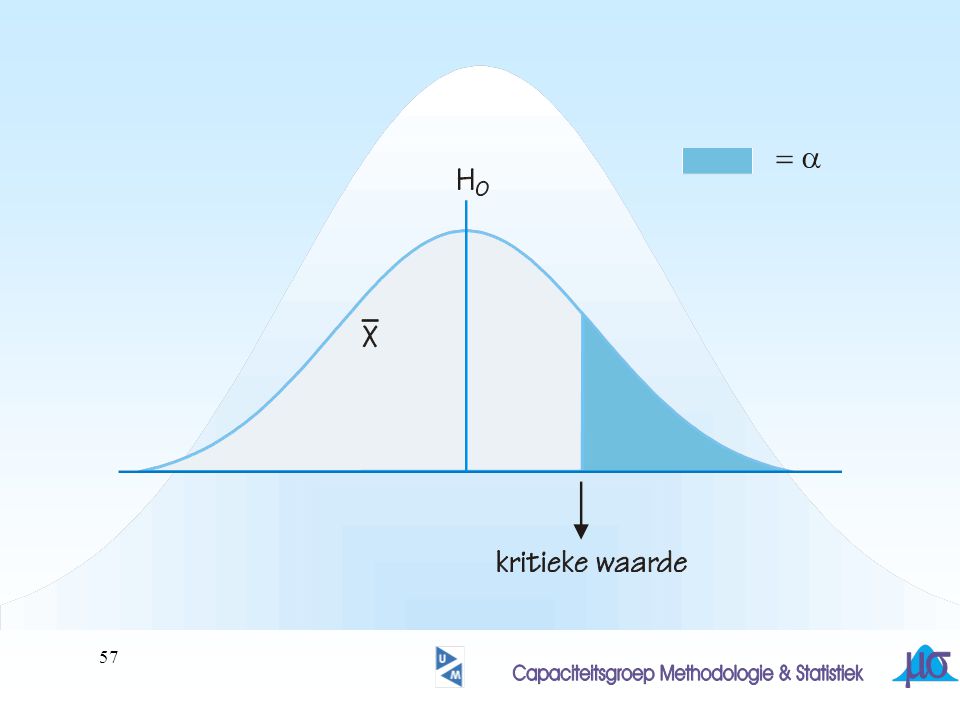
Statistische toetsing
z-toets t-toets Nulhypothese Alternatieve hypothese p-waarde Significantie-niveau Kritiek gebied Kritieke waarde Verwerpingsgebied Acceptatiegebied Type I fout (a) Type II fout (b) Onderscheidend vermogen Kernbegrippen
 Type II fout (b) Onderscheidend vermogen. Kernbegrippen.")
7
Veronderstelde voorkennis
Standaardiseren (hoofdstuk 2 & 4) Normale verdeling (hoofdstuk 4) Gedrag van gemiddelden (hoofdstuk 4) Verdeling van steekproefgemiddelden (hoofdstuk 4)
 Normale verdeling (hoofdstuk 4) Gedrag van gemiddelden (hoofdstuk 4) Verdeling van steekproefgemiddelden. (hoofdstuk 4)")
8
Bedoeling van verklarende statistiek:
op grond van steekproefgrootheid uitspraak doen omtrent populatieparameter steekproefgrootheid <>populatieparameter fractie gemiddelde standaarddeviatie correlatiecoefficient regressie-coefficient etc.

9
centrale limietstelling
Als uit een willekeurige populatie met m en s2, steekproeven van omvang n worden getrokken, dan is de verdeling van steekproefgemiddelden bij benadering normaal verdeeld met gemiddelde= m en variantie= s2 /n de benadering wordt beter bij toenemende n!

10
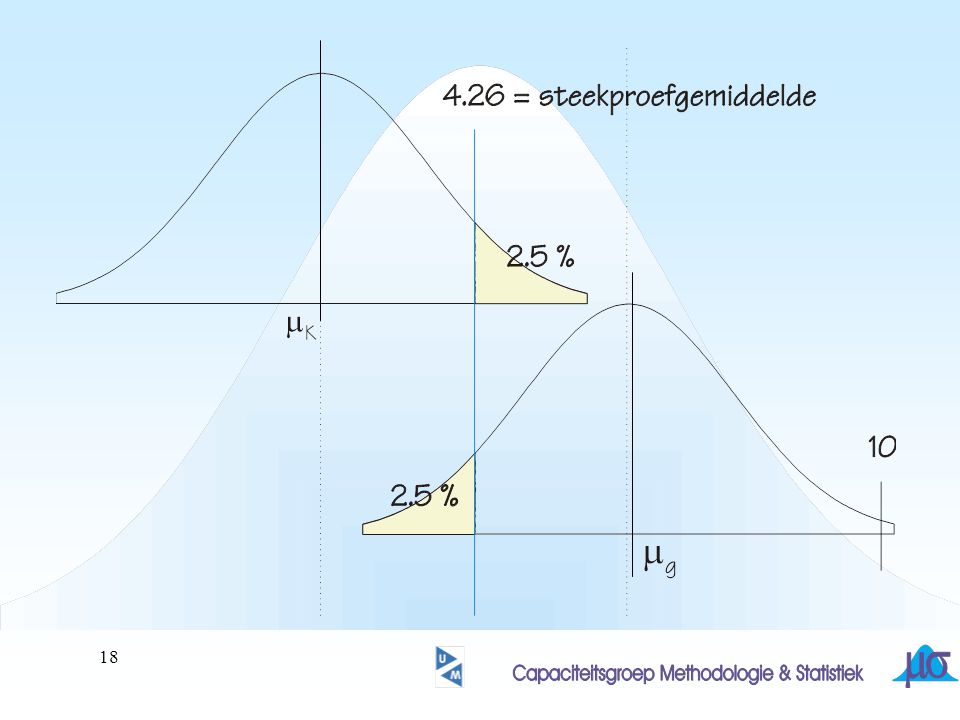
voorbeeld Gegeven: Van 25 personen werd een reactie-tijd gemeten:
de gemiddelde, gemeten, waarde = 4.26 Uit de literatuur is bekend dat dit soort reactietijden normaliter exponentieel verdeeld zijn met m=3 Opm: Bij een exponentiele verdeling geldt m=s Gevraagd: Is de steekproef afkomstig uit de genoemde populatie?

11
als.... de steekproef afkomstig is uit de genoemde
populatie met m= s= 3

12
als.... dan... de steekproef afkomstig is uit de genoemde
populatie met m= s= 3 dan... is het gevonden gemiddelde (= 4.26) een exemplaar uit de verdeling van gemiddelden van steekproeven met n= 25
 een exemplaar uit de. verdeling van gemiddelden. van steekproeven met n= 25.")
13
als.... dan... en die verdeling is bekend!!!!!!
de steekproef afkomstig is uit de genoemde populatie met m= s= 3 dan... is het gevonden gemiddelde (= 4.26) een exemplaar uit de verdeling van gemiddelden van steekproeven met n= 25 en die verdeling is bekend!!!!!!
 een exemplaar uit de. verdeling van gemiddelden. van steekproeven met n= 25. en die verdeling is bekend!!!!!!")
14
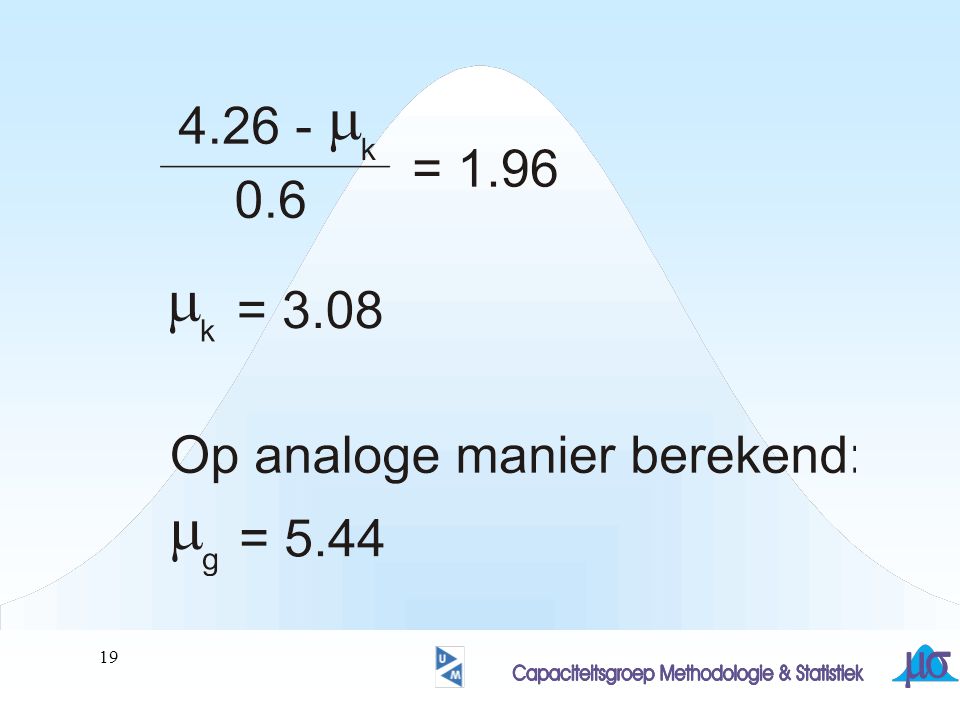
gemiddelden van steekproeven (n=25)
uit een willekeurige populatie met m= s=3 (s2= 9) vormen bij benadering een normale verdeling met m= 3 en s2= 9/25 dus s= 3/5 blijft de vraag hoe waarschijnlijk de gevonden waarde (=4.26) is m= 3 s= 0.6
 vormen bij benadering een. normale verdeling. met m= 3 en s2= 9/25 dus s= 3/5. blijft de vraag hoe waarschijnlijk. de gevonden waarde (=4.26) is. m= 3. s= 0.6.")
15
CONCLUSIE??? X-gemiddeld is normaal verdeeld: m= 3 en s= 3/5= 0.6
P(X-gemiddeld>4.26)= P(X-gemiddeld<4.26) P(z<( )/0.6)= P(z<2.1)= = 1.79% CONCLUSIE???
= P(X-gemiddeld<4.26) P(z<( )/0.6)= P(z<2.1)= = 1.79% CONCLUSIE")
16
redenering andersom Gegeven:
Steekproef van 25 stuks met gemiddelde= 4.26 Gevraagd: Welke waarden van m (bij een s=3) zijn aannemelijk …. kunnen dit gemiddelde opleveren? 10 ? ? ?
 zijn aannemelijk …. kunnen dit gemiddelde opleveren")
17
X-gemiddeld is normaal verdeeld:
m= 10 en s= 3/5= 0.6 P(X-gemiddeld<4.26)= P(z<( )/0.6)= P(z< )= m=10 komt dus niet in aanmerking!! We gaan op zoek naar de kleinste en de grootste waarden van m die een steekproefgemiddelde van 4.26 kunnen opleveren
= P(z<( )/0.6)= P(z< )= m=10 komt dus niet in aanmerking!! We gaan op zoek naar. de kleinste en de grootste. waarden van m die een. steekproefgemiddelde van kunnen opleveren.")
20
3.08 5.44
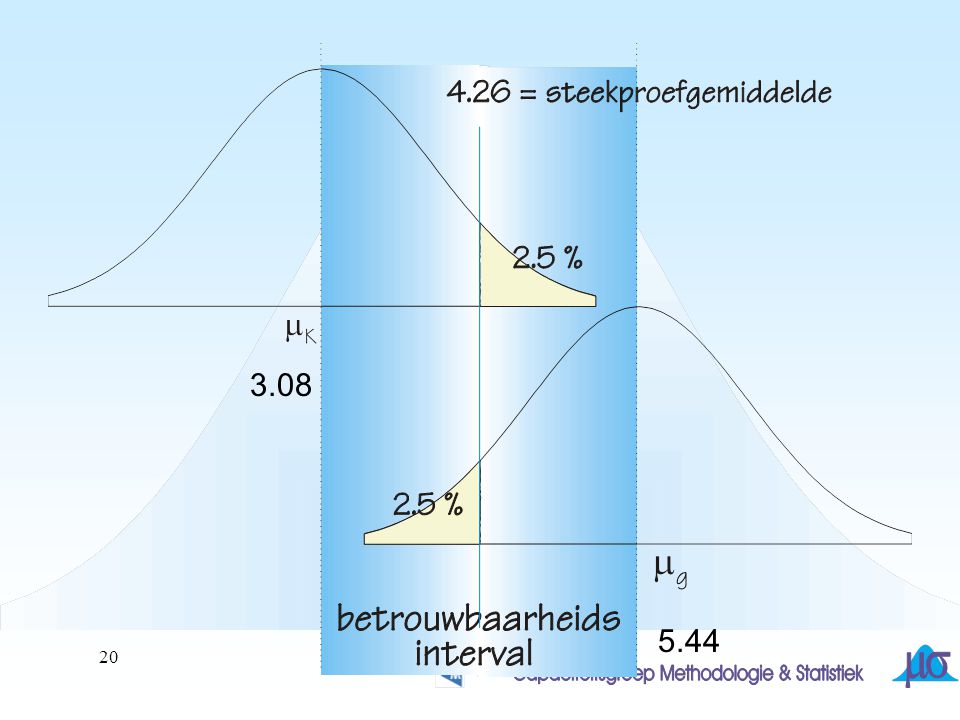
21
3.08 95% 5.44

22
? Zo kan ook het 90% betrouwbaarheidsinterval worden berekend
en het 99% betrouwbaarheids interval en het …….. Welk bi-interval is breder: het 90% of het 99% ? Het 95% betrouwbaarheids-interval is een waardenbereik dat met een waarschijnlijkheid van 95% de waarde m bevat

23
? eerder gebruikt voorbeeld Gegeven:
Van 25 personen werd een reactie-tijd gemeten: de gemiddelde, gemeten, waarde = 4.26 Uit de literatuur is bekend dat dit soort reactietijden normaliter exponentieel verdeeld zijn met m=3 Opm: Bij een exponentiele verdeling geldt m=s Gevraagd: Is de steekproef afkomstig uit de genoemde populatie?

24
bepaal het 95% betrouwbaarheidsinterval

25
? Het 95% betrouwbaarheidsinterval bevat de waarden 3.08 …… 5.44
De waarde van m (=3) maakt geen deel uit van dit interval. Het is dus niet waarschijnlijk dat de beschouwde steekproef afkomstig is uit de genoemde populatie Hoe groot is de kans dat deze uitspraak fout is? Anders gezegd: Hoe groot is de kans dat m wel in het interval ligt? ?
 maakt geen deel uit. van dit interval. Het is dus niet waarschijnlijk dat. de beschouwde steekproef afkomstig is uit. de genoemde populatie. Hoe groot is de kans dat deze uitspraak. fout is Anders gezegd: Hoe groot is de kans dat m wel in het. interval ligt")
26
2 BENADERINGEN GEZIEN A uitgaande van een bepaalde m (en s) de
verdeling van X-gemiddelden berekend en vervolgens gekeken hoe extreem het steekproefgemiddelde in die verdeling is. B uitgaande van het steekproefgemiddelde een betrouwbaarheidsinterval bepaald en gekeken of m in dit gebied ligt.

27
Er is een praktisch probleem!
meestal is s van de populatie niet bekend “behelpen” met de standaarddeviatie (=s) van de steekproef: s is schatter van s! s kan als gevolg van het toeval kleiner of groter zijn dan s. Extra onzekerheid wordt geintroduceerd. daarom… voor X-gemiddeld niet de normale verdeling, maar de t-verdeling gebruiken
 van de steekproef: s is schatter van s! s kan als gevolg van het toeval. kleiner of groter zijn dan s. Extra onzekerheid wordt geintroduceerd. daarom… voor X-gemiddeld niet de normale verdeling, maar de t-verdeling gebruiken.")
28
normale verdeling vs t-verdeling met 3 df 95

29
normale verdeling vs t-verdeling met 25 df
95

30
95% betrouwbaarheidsinterval
z-interval t-interval

31
betrouwbaarheidsinterval
? betrouwbaarheidsinterval op basis van s: z-interval op basis van s: t-interval z-interval smaller/breder dan t-interval? middelpunt z-interval? middelpunt t-interval? z-interval is constant qua breedte t-interval ook constant ?

32
Een docent registreerde jarenlang de resultaten die
studenten scoorden op een bepaalde toets. Hij berekende: m= 72 en s= 12. De docent beweert dat de huidige lichting van 36 studenten (met een gemiddelde van 75.2) niet tot de beschreven populatie behoort, maar tot een populatie met m 72. Dus m<72 of m> 72. Met zekerheid valt niets te zeggen over die bewering! Gebruik een onbetrouwbaarheid van 5%.
 niet tot. de beschreven populatie behoort, maar tot. een populatie met m 72. Dus m<72 of m> 72. Met zekerheid valt niets te zeggen over die bewering! Gebruik een onbetrouwbaarheid van 5%.")
33
De docent heeft gelijk: m 72: alternatieve hypothese
De docent heeft ongelijk: m = 72: nulhypothese De nulhypothese (H0) is juist totdat hij niet langer houdbaar is en wordt verworpen ten gunste van de alternatieve hypothese (H1 of HA) Als: H0 juist is (m= 72 met s= 12) Dan: is het steekproefgemiddelde een exemplaar uit de NV(72, 12/6) 95%-bi: ?????????????
 is juist totdat hij niet langer houdbaar is en wordt verworpen ten gunste van de. alternatieve hypothese (H1 of HA) Als: H0 juist is (m= 72 met s= 12) Dan: is het steekproefgemiddelde. een exemplaar uit de NV(72, 12/6) 95%-bi:")
34
CONCLUSIE ????? De docent heeft gelijk: m 72: alternatieve hypothese
De docent heeft ongelijk: m = 72: nulhypothese De nulhypothese (H0) is juist totdat hij niet langer houdbaar is en wordt verworpen ten gunste van de alternatieve hypothese (H1 of HA) Als: H0 juist is (m= 72 met s= 12) Dan: is het steekproefgemiddelde een exemplaar uit de NV(72, 12/6) 95%-bi: … (75.2) … 79.12 CONCLUSIE ?????
 is juist totdat hij niet langer houdbaar is en wordt verworpen ten gunste van de. alternatieve hypothese (H1 of HA) Als: H0 juist is (m= 72 met s= 12) Dan: is het steekproefgemiddelde. een exemplaar uit de NV(72, 12/6) 95%-bi: … (75.2) … CONCLUSIE")
35
De alternatieve hypothese is tweezijdig
(het verwerpingsgebied is tweezijdig) Men spreekt van tweezijdig toetsen. In zo’n geval wordt aan beide zijden de helft van a gebruikt Uitgangspunt was het steekproefgemiddelde
 Men spreekt van tweezijdig toetsen. In zo’n geval wordt aan beide zijden. de helft van a gebruikt. Uitgangspunt was. het steekproefgemiddelde.")
36
Het probleem kan ook op een andere manier
worden aangepakt… Daarbij wordt niet uitgegaan van het gevonden steekproef gemiddelde maar van het veronderstelde (= nulhypothese) populatiegemiddelde. Kies weer voor a = 5%
 populatiegemiddelde. Kies weer voor a = 5%")
37
De verdeling van de gemiddelden van steekproeven met n= 36 uit een populatie met m = 72 en s = 12 ?

38
De verdeling van de gemiddelden van steekproeven met n= 36 uit een populatie met m = 72 en s = 12 ? Normale verdeling met m = 72 en s = 12/6= 2

39
KW-L= 68.08 KW_R= 75.92

40
conclusie??? 75.2 KW-L= 68.08 KW_R= 75.92

41
Dit was twee-zijdig toetsen
via betrouwbaarheidsinterval via kritieke gebied Nu eenzijdig toetsen alleen via kritieke gebied

42
Het probleem luidde…. Een docent registreerde jarenlang de resultaten die studenten scoorden op een bepaalde toets. Hij berekende: m= 72 en s= 12. De docent beweert dat de huidige lichting van 36 studenten (met een gemiddelde van 75.2) niet tot de beschreven populatie behoort, maar tot een populatie met m 72. Dus m<72 of m> 72.
 niet tot. de beschreven populatie behoort, maar tot. een populatie met m 72. Dus m<72 of m> 72.")
43
Het nieuwe probleem luidt
Een docent registreerde jarenlang de resultaten die studenten scoorden op een bepaalde toets. Hij berekende: m= 72 en s= 12. De docent beweert dat de huidige lichting van 36 studenten (met een gemiddelde van 75.2) beter is dan de studenten uit de populatie met m= 72. M.a.w. de steekproef is getrokken uit een populatie met m > 72
 beter is. dan de studenten uit de populatie met m= 72. M.a.w. de steekproef is getrokken uit een. populatie met m > 72.")
44
De alternatieve hypothese is eenzijdig
(het verwerpingsgebied is eenzijdig) (het kritieke gebied ligt aan een kant) Men spreekt van eenzijdig toetsen. In zo’n geval wordt de hele a aan een zijde gebruikt. In dit geval is sprake van rechtseenzijdig toetsen omdat de waarden van m onder HA rechts van m0 liggen
 (het kritieke gebied ligt aan een kant) Men spreekt van eenzijdig toetsen. In zo’n geval wordt de hele a aan een. zijde gebruikt. In dit geval is sprake van. rechtseenzijdig toetsen. omdat de waarden van m onder HA. rechts van m0 liggen.")
45
Ook hier vormt de bewering van de docent
de alternatieve hypothese: HA: m > 72 Hieruit wordt de nulhypothese afgeleid: H0 : m < (samengestelde nulhypothese) Bij het toetsen kan maar EEN waarde voor m0 worden gebruikt. Welke ?????
 Bij het toetsen kan maar EEN waarde voor. m0 worden gebruikt. Welke")
46
Ook hier vormt de bewering van de docent
de alternatieve hypothese: HA: m > 72 Hieruit wordt de nulhypothese afgeleid: H0 : m < (samengestelde nulhypothese) Bij het toetsen kan maar EEN waarde voor m0 worden gebruikt. De waarde die het dichtst bij mA ligt. dus: m0 = 72
 Bij het toetsen kan maar EEN waarde voor. m0 worden gebruikt. De waarde die het dichtst bij mA ligt. dus: m0 = 72.")
47
? Bereken de kritieke waarde

48
De kritieke waarde (kw) is gelijk aan:
 is gelijk aan:")
49
De kritieke waarde (kw) is gelijk aan:
conclusie?

50
De docent vond een steekproefwaarde
(gemiddelde van 36 studs) van 75.2. Deze waarde ligt niet in het verwerpingsgebied Bij een a van 5% moet H0 dus niet worden verworpen Wat zou de conclusie zijn geweest van een onderzoeker die werkte met a = 10%
 van Deze waarde ligt niet in het verwerpingsgebied. Bij een a van 5% moet. H0 dus niet worden verworpen. Wat zou de conclusie zijn geweest van. een onderzoeker die werkte met a = 10%")
51
? gelet op de steekproefgegevens wordt met een vooraf gekozen risico a
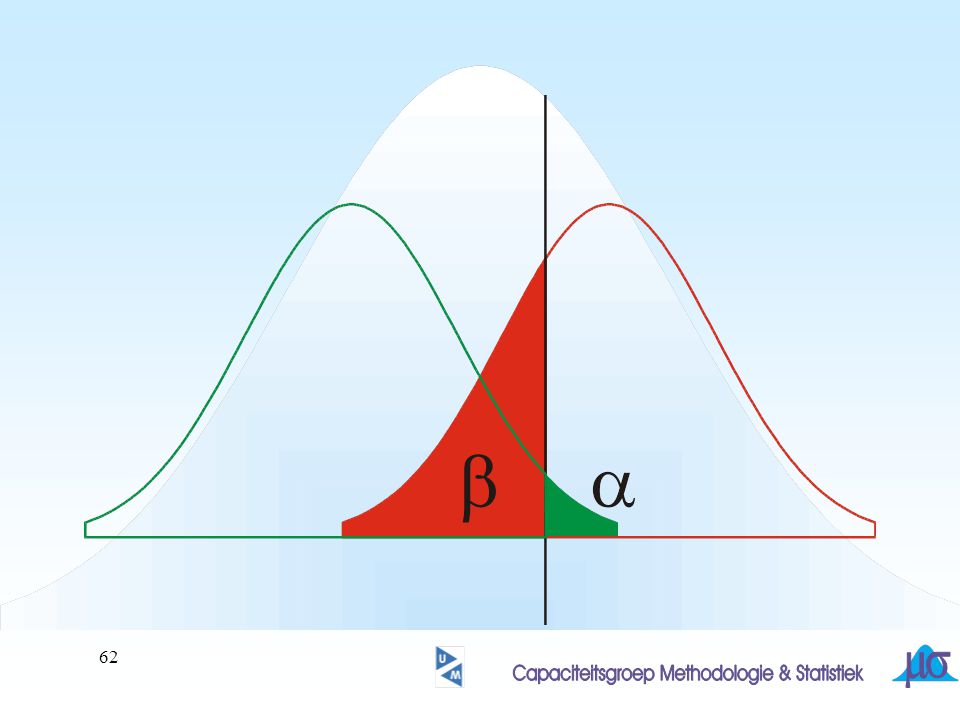
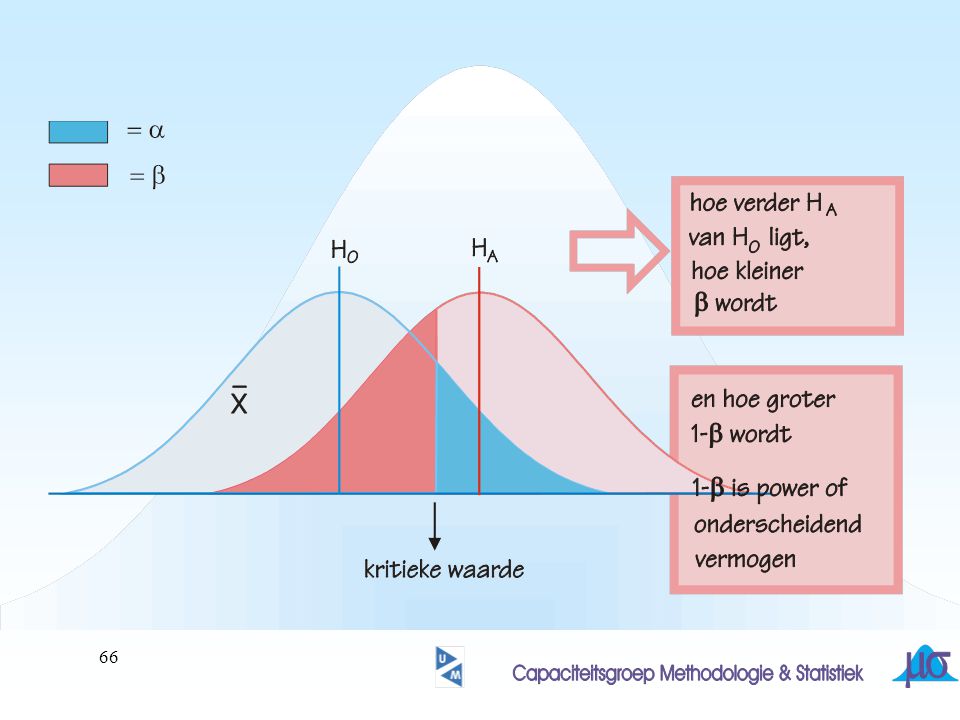
H0 verworpen of niet verworpen. Ook als H0 juist is zou het gevonden resultaat in de steekproef kunnen leiden tot verwerping van H0 Hoe groot was dat risico in het voorbeeld? ? Waarom dat risico dan niet heel klein gekozen?

53
correct

54
correct fout type I

55
correct fout type II correct fout type I

56
correct b correct a

58
H0 niet verwerpen H0 verwerpen

59
Deel van verdeling onder H0 in kritieke gebied
Deel van verdeling onder HA in acceptatie gebied

60
FOUT ! Deel van verdeling onder H0 in kritieke gebied
Deel van verdeling onder HA in acceptatie gebied

61
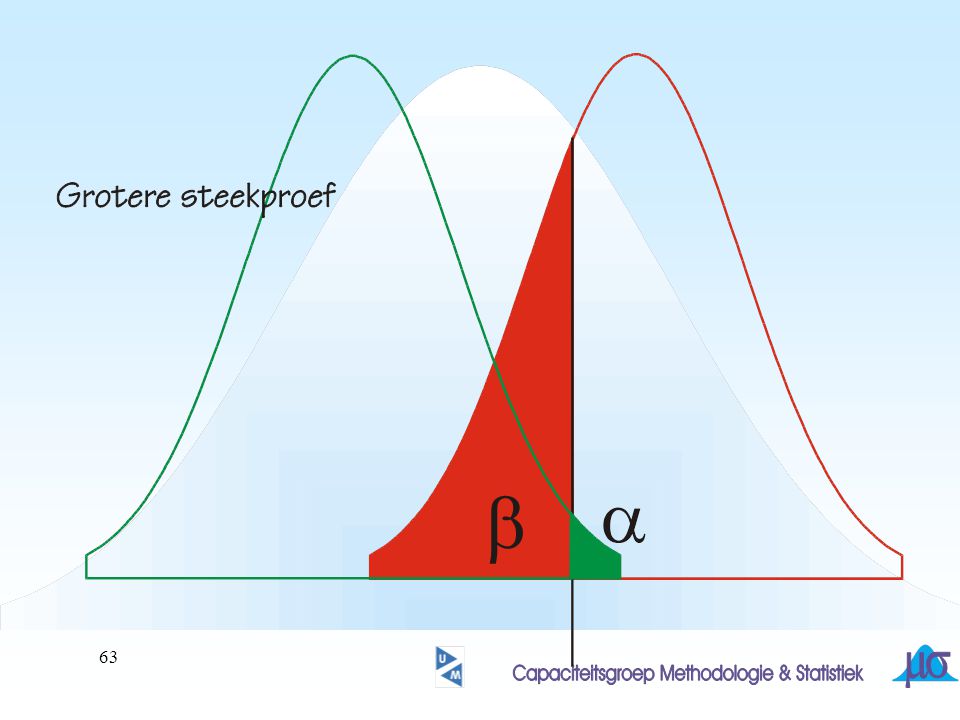
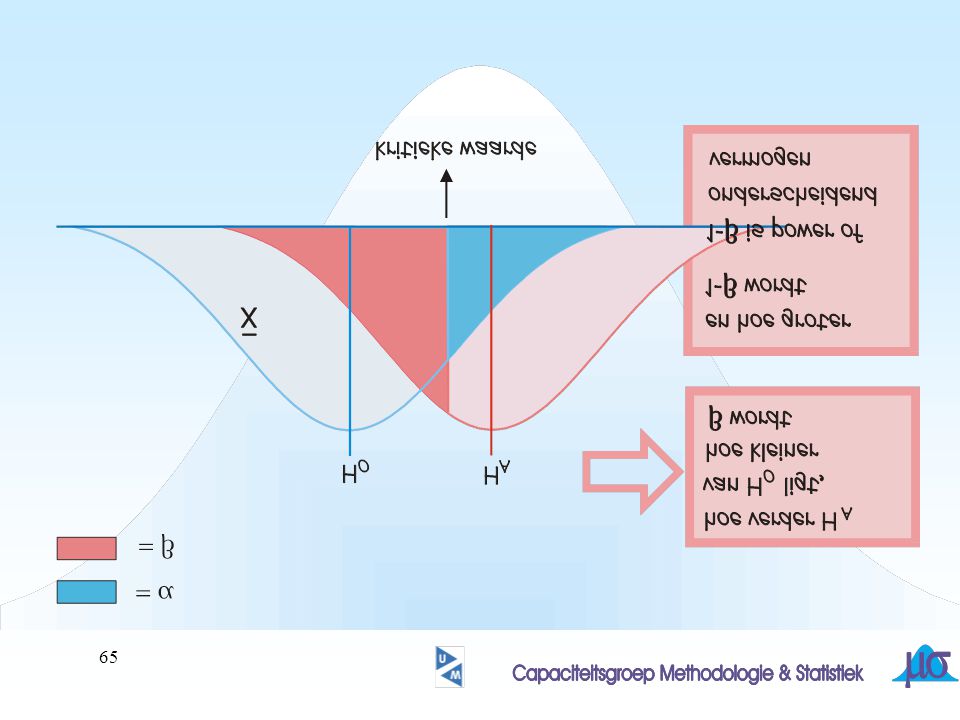
? wanneer wordt gekozen voor een kleinere a, wordt b groter!
hoe kan bij gelijkblijvende a, b worden verkleind ?

64
Deel van verdeling onder H0 in kritieke gebied
Deel van verdeling onder HA in acceptatie gebied

67
een eerder gebruikt voorbeeld...
De kritieke waarde (kw) is gelijk aan: 75.29 Bereken b en 1-b als HA gelijk is aan 77 Z= >> b= 19.63% >> 1-b= 80.37%
 is gelijk aan: Bereken b en 1-b als HA gelijk is aan 77. Z= >> b= 19.63% >> 1-b= 80.37%")
68
in woorden... Z= -0.855 >> b= 19.63% >> 1-b= 80.37%
Als de werkelijke m gelijk is aan 77 zal een steekproef uit die populatie met een kans van 80.37% leiden tot verwerping van H0 deze kans is voor elke waarde van HA uit te rekenen….

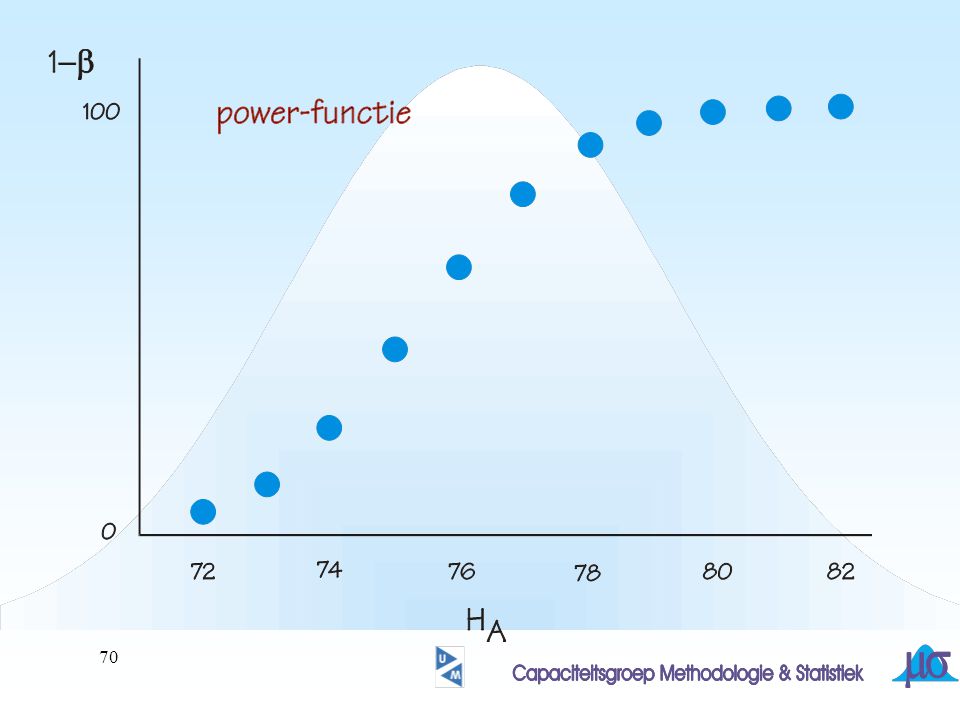
69
mA z b b In een grafiek mA uitzetten tegen 1-b: powerfunctie

71
hoe stijler de helling, hoe ‘scherper’ de toets hoe is deze helling te beinvloeden????

72
Overzicht van het toetsen tot nu toe:
twee-zijdig m.b.v. betrouwbaarheidsinterval m.b.v. kritieke gebied een-zijdig m.b.v kritieke gebied

73
Overzicht van het toetsen tot nu toe:
twee-zijdig m.b.v. betrouwbaarheidsinterval m.b.v. kritieke gebied een-zijdig m.b.v kritieke gebied In plaats van te kijken naar kritieke waarde kun je ook kijken naar de p-waarde van de toetsingsgrootheid

74
1. maak gebruik van het kritieke waarde/gebied
construeer nulhypothese (eenzijdig/tweezijdig?) bepaal ombetrouwbaarheid a kies een toetsingsgrootheid T (gemiddelde? Omvang steekproef) d. bepaal de verdeling van T e. bereken kritieke gebied f. bereken toetsingsgrootheid T* in de steekproef g. trek conclusie: T* ligt in het kritieke gebied (= verwerpen) of niet (= niet verwerpen)
 bepaal ombetrouwbaarheid a. kies een toetsingsgrootheid T. (gemiddelde Omvang steekproef) d. bepaal de verdeling van T. e. bereken kritieke gebied. f. bereken toetsingsgrootheid T* in de. steekproef. g. trek conclusie: T* ligt in het kritieke gebied (= verwerpen) of niet (= niet verwerpen)")
75
2. Bepaal de p-waarde van de toetsingsgrootheid
construeer nulhypothese (eenzijdig/tweezijdig?) bepaal ombetrouwbaarheid a kies een toetsingsgrootheid T (gemiddelde? Omvang steekproef) d. Bepaal de verdeling van T e. bereken toetsingsgrootheid T* in de steekproef f. bepaal de overschrijdingskans p van T* g. trek conclusie: p < a: (= verwerpen) p > a: (= niet verwerpen)
 bepaal ombetrouwbaarheid a. kies een toetsingsgrootheid T. (gemiddelde Omvang steekproef) d. Bepaal de verdeling van T. e. bereken toetsingsgrootheid T* in de. steekproef. f. bepaal de overschrijdingskans p van T* g. trek conclusie: p < a: (= verwerpen) p > a: (= niet verwerpen)")
76
De twee manieren gedemonstreerd m.b.v. een
eerder gebruikt voorbeeld Een docent registreerde jarenlang de resultaten die studenten scoorden op een bepaalde toets. Hij berekende: m= 72 en s= 12. De docent beweert dat de huidige lichting van 36 studenten (met een gemiddelde van 75.2) beter is dan de studenten uit de populatie met m= 72. M.a.w. de steekproef is getrokken uit een populatie met m > 72
 beter is. dan de studenten uit de populatie met m= 72. M.a.w. de steekproef is getrokken uit een. populatie met m > 72.")
77
1. Toetsen m.b.v. kritieke gebied
Nulhypothese: m = 72: rechtseenzijdig Onbetrouwbaarheid: a= 5% Toetsingsgrootheid T: gemiddelden van steekproef van 36 stuks Verdeling van T: NV(72, 2) Kritieke gebied: en groter Bereken T*: 75.2 Trek conclusie: T* niet in verwerpings- bied: H0 niet verwerpen
 Kritieke gebied: en groter. Bereken T*: Trek conclusie: T* niet in verwerpings- bied: H0 niet verwerpen.")
78
2. Toetsen m.b.v. p-waarde Nulhypothese: m = 72: rechtseenzijdig
Onbetrouwbaarheid: a= 5% Toetsingsgrootheid T: gemiddelden van steekproef van 36 stuks Verdeling van T: NV(72, 2) Bereken T*: 75.2 (>> z= 1.6) Bepaal overschrijdingskans: 5.48% Trek conclusie: p-waarde van T* is groter dan a: H0 niet verwerpen
 Bereken T*: 75.2 (>> z= 1.6) Bepaal overschrijdingskans: 5.48% Trek conclusie: p-waarde van T* is groter dan a: H0 niet verwerpen.")
79
SAMENVATTING Twee toetsen voor een gemiddelde:
z-toets (s) en t-toets (s) Betrouwbaarheidsintervallen (z en t) Toetsen: beslissen in onzekerheid eenzijdig <–>tweezijdig BI <–> kritieke gebied kritieke gebied <–> p-waarde 4. Fout van de eerste soort: a-fout Fout van de tweede soort: b-fout Hoofdstuk 5: sleutelhoofdstuk Hoofdstuk 6: toetsen voor twee gemiddelden: z-toets en t-toets
 en t-toets (s) Betrouwbaarheidsintervallen (z en t) Toetsen: beslissen in onzekerheid. eenzijdig <–>tweezijdig. BI <–> kritieke gebied. kritieke gebied <–> p-waarde. 4. Fout van de eerste soort: a-fout. Fout van de tweede soort: b-fout. Hoofdstuk 5: sleutelhoofdstuk. Hoofdstuk 6: toetsen voor twee gemiddelden: z-toets en t-toets.")
80
succes !

Verwante presentaties







 DoelgroepVerzondenOntvangen% LG wonen en dagbesteding.>")













