Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
retrieval en ontsluiting taaltechnologische aanpak voor zoekproblemen
eric sieverts instituut voor media en informatie management hogeschool van amsterdam

2
waarin uiten zoekstrategische problemen zich?
(in variabele mate in zeer uiteenlopende soorten systemen, zoals bibliografische databases, full-text bestanden, het web, ….) onvoldoende recall met zoekvraag mis je te veel relevante informatie onvoldoende precisie zoekvraag levert (te) veel niet-relevante informatie
 onvoldoende recall. met zoekvraag mis je te veel relevante informatie. onvoldoende precisie. zoekvraag levert (te) veel niet-relevante informatie.")
3
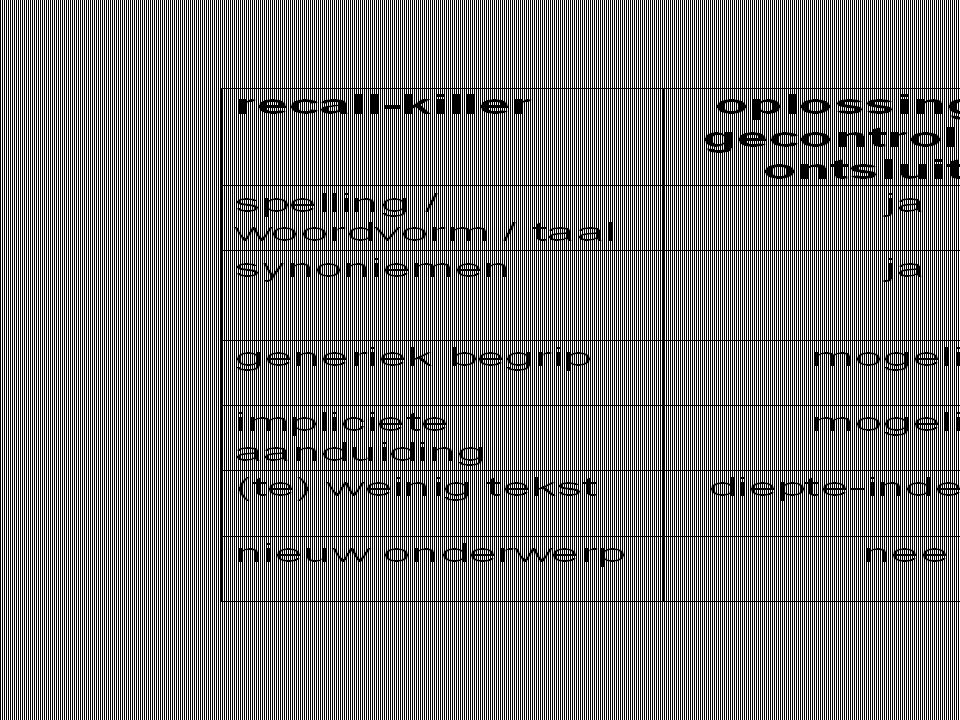
oorzaken voor lage recall (de recall-killers)
inherent aan free-text zoeken in documenten: variatie in gebruikte woorden (spelling, woordvorm, taal) in tekst staan synoniemen, impliciete aanduidingen, … variëteit aan woorden voor generieke begrippen term-armoede van documenten (catalogus) schuld van de zoeker: verkeerde zoekterm (spelling, betekenis) te weinig varianten met OR gecombineerd te veel zoek-elementen met AND gecombineerd
 in tekst staan synoniemen, impliciete aanduidingen, … variëteit aan woorden voor generieke begrippen. term-armoede van documenten (catalogus) schuld van de zoeker: verkeerde zoekterm (spelling, betekenis) te weinig varianten met OR gecombineerd. te veel zoek-elementen met AND gecombineerd.")
4
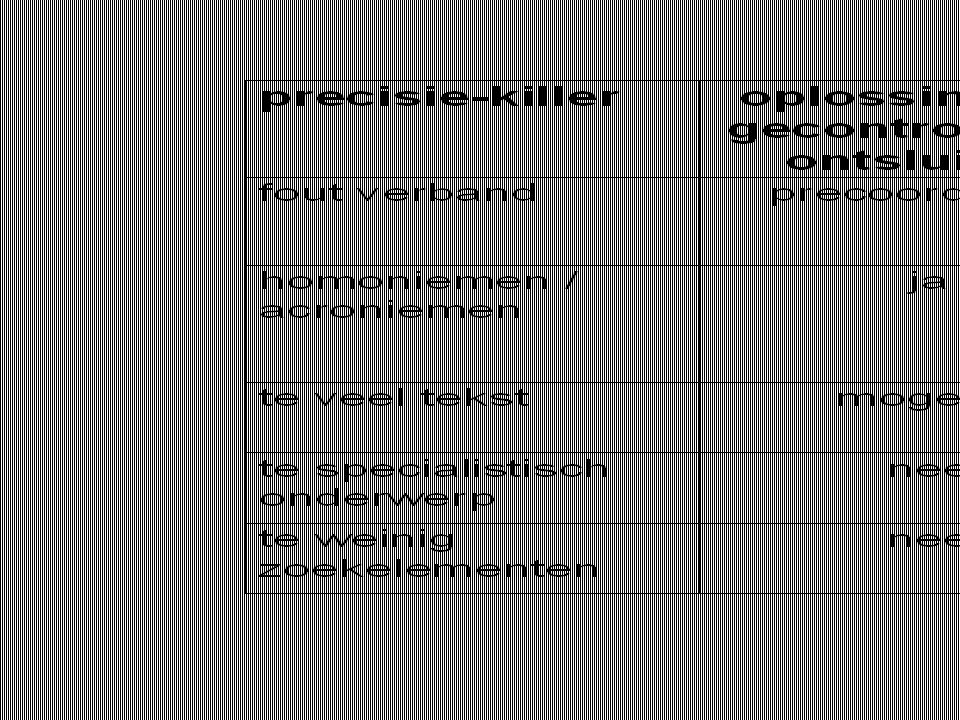
oorzaken voor lage precisie (de precisie-killers)
inherent aan free-text zoeken in documenten : verkeerde verbanden tussen ge-AND-e termen niet eenduidige betekenis (homoniemen, acroniemen) term-rijkdom van full-text documenten (laag term-gewicht) schuld van de zoeker : verkeerde zoekterm (te algemeen) te weinig concepten met AND gecombineerd
 term-rijkdom van full-text documenten (laag term-gewicht) schuld van de zoeker : verkeerde zoekterm (te algemeen) te weinig concepten met AND gecombineerd.")
5
klassieke oplossing : gebruik van: classificatie / taxonomie
thesaurus waarop berust het feit dat we denken dat dit een oplossing biedt? formaliseert betekenis uniformeert term-rijkdom (dus term-gewicht) legt inhoudelijke relaties tussen onderwerpen/termen kan verband leggen tussen facetten van onderwerp (precoordinatie)
 legt inhoudelijke relaties tussen onderwerpen/termen. kan verband leggen tussen facetten van onderwerp. (precoordinatie)")
6
nadelen van klassieke oplossing
gebrek aan flexibiliteit (schrik van de vak-specialist) je moet (kunstmatige) informatietaal gebruiken (schrik van de ergonoom) duur omdat mensen termen moeten toekennen (schrik van de manager)
 je moet (kunstmatige) informatietaal gebruiken. (schrik van de ergonoom) duur omdat mensen termen moeten toekennen. (schrik van de manager)")
7
taaltechnologische alternatieven
best-match zoeken met relevantie-ordening truncatie, woordstemming, fuzzy search semantische kennis toevoegen zoekresultaat in "domeinen/contexten” laten clusteren genereren van suggesties voor aanvullende zoektermen terugkoppeling van zoekersoordeel

8
relevance ranking factoren
1. meer van de gevraagde termen in een document 2. gevraagde termen op belangrijke plek in document (titel, koppen, eerste paar regels, ….) 3. gevraagde termen komen in document herhaald voor 4. gevraagde termen staan in document dicht bij elkaar 5. termen in document staan in zelfde volgorde als in vraag 6. zeldzame termen krijgen zwaarder gewicht dan algemene 7. hoeveelheid hyperlinks die naar document verwijst 8. hoe vaak een document / site wordt "bezocht" google bewijst dat dat op het web goed werkt, maar ook op een intranet?
 3. gevraagde termen komen in document herhaald voor. 4. gevraagde termen staan in document dicht bij elkaar. 5. termen in document staan in zelfde volgorde als in vraag. 6. zeldzame termen krijgen zwaarder gewicht dan algemene. 7. hoeveelheid hyperlinks die naar document verwijst. 8. hoe vaak een document / site wordt bezocht google bewijst dat dat op het web goed werkt, maar ook op een intranet")
9
relevance ranking factoren
1. meer termen 2. termen in titel/kop/begin 3. termen herhaald 4. termen dicht bij elkaar 5. termen in volgorde 6. zeldzame termen zwaarder 7. hyperlinks naar document 8. bezoek aan document meer concepten ge-AND hoger term-gewicht juiste verband belang specifieke term (kwaliteit) [alleen als er links zijn] (kwaliteit)
 [alleen als er links zijn] (kwaliteit)")
10
relevance ranking factoren
1. meer van de gevraagde termen in een document gevraagde termen op belangrijke plek in document (titel, koppen, eerste paar regels, …) 3. gevraagde termen komen in document herhaald voor 4. gevraagde termen staan in document dicht bij elkaar 5. termen in document staan in zelfde volgorde als in vraag 6. zeldzame termen krijgen zwaarder gewicht dan algemene 7. hoeveelheid hyperlinks die naar document verwijst 8. hoe vaak een document / site wordt "bezocht" allemaal gericht op hogere relevantie voor "de eerste tien", dus op precisie
 3. gevraagde termen komen in document herhaald voor. 4. gevraagde termen staan in document dicht bij elkaar. 5. termen in document staan in zelfde volgorde als in vraag. 6. zeldzame termen krijgen zwaarder gewicht dan algemene. 7. hoeveelheid hyperlinks die naar document verwijst. 8. hoe vaak een document / site wordt bezocht allemaal gericht op hogere relevantie. voor de eerste tien , dus op precisie.")
11
truncatie / stemming / fuzzy
trunceren computer computeronderwijs stemming computer computing, computation, computed, computers communism community, communication ?? sieverts sievert ?? fuzzy duivendak duijvendak, duyvendak serajevo sarajevo chebychev chebyshev, chebyschef kok kop, kak, ... ??

12
truncatie / stemming / fuzzy
trunceren computer computeronderwijs stemming computer computing, computation, computed, computers communism community, communication ?? sieverts sievert ?? fuzzy duivendak duijvendak, duyvendak serajevo sarajevo chebychev chebyshev, chebyschef kok kop, kak, ... ?? compenseert variatie in woordvorm & spelling betere recall maar pas op voor ongewenste effecten !!

13
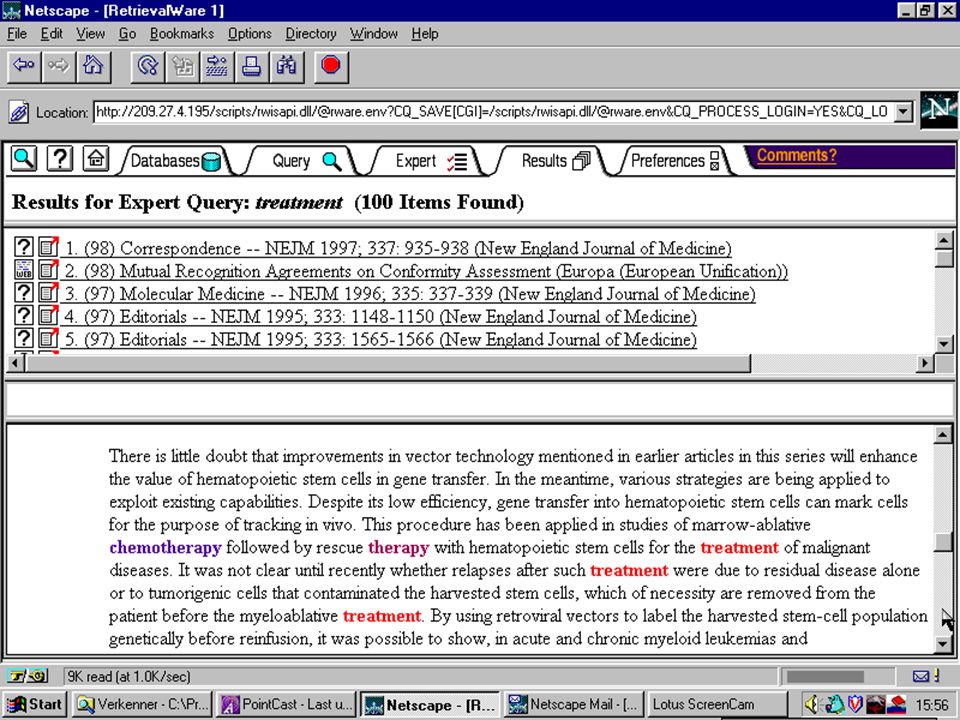
semantische kennis in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query mee te expanderen (woorden binnen bepaalde "semantische afstand" van zoekwoord) voorbeeld: retrievalware van convera twenty-one van irion
 door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query mee te expanderen (woorden binnen bepaalde semantische afstand van zoekwoord) voorbeeld: retrievalware van convera. twenty-one van irion.")
14
visualisatie van “wordnet”

15
bepaalde gewenste betekenissen van zoekterm geselecteerd

18
semantische kennis verbeteren van precisie verbeteren van recall
in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) omgeving van woord in het netwerk kan betekenissen onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen verbeteren van precisie verbeteren van recall maar semantisch netwerk voor specialistisch domein moet je zelf nog bouwen
 omgeving van woord in het netwerk kan betekenissen. onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen. leveren om query te expanderen. verbeteren van precisie. verbeteren van recall. maar semantisch netwerk. voor specialistisch domein. moet je zelf nog bouwen.")
19
automatisch clusteren/classificeren
op grond van kennisregels (en bestaande “taxonomie”) in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen op grond van statistiek of patronen Ask, Clusty, Collarity, …. Autonomy
 in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen. op grond van statistiek of patronen. Ask, Clusty, Collarity, …. Autonomy.")
20
custom search folders

21
toekenning document aan taxonomy-term gebaseerd op rules base, zoals bijvoorbeeld bij product van Verity

26
automatisch clusteren/classificeren
op grond van kennisregels (en bestaande “taxonomie”) [vroeger:] NorthernLight “custom search folders” Verity filters/topics op grond van statistiek of patronen AltaVista (3 jaar geleden) Ask, Wisenut, Vivisimo Autonomy kiezen van juiste betekenis of context betere precisie werkt niet gegarandeerd altijd goed
 [vroeger:] NorthernLight custom search folders Verity filters/topics. op grond van statistiek of patronen. AltaVista (3 jaar geleden) Ask, Wisenut, Vivisimo. Autonomy. kiezen van juiste betekenis of context. betere precisie. werkt niet gegarandeerd. altijd goed.")
27
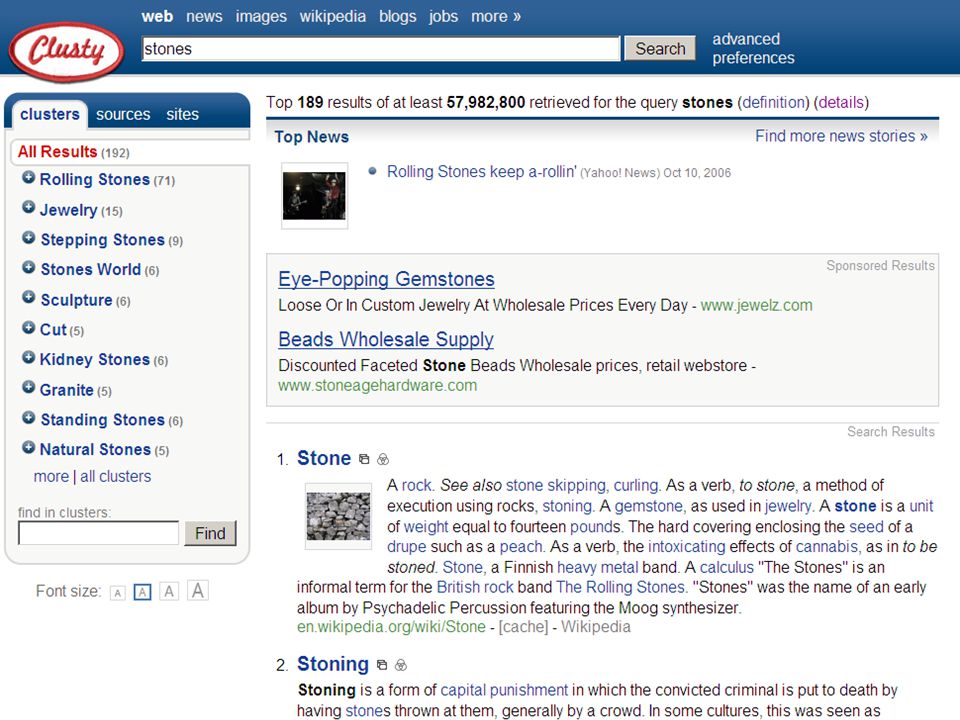
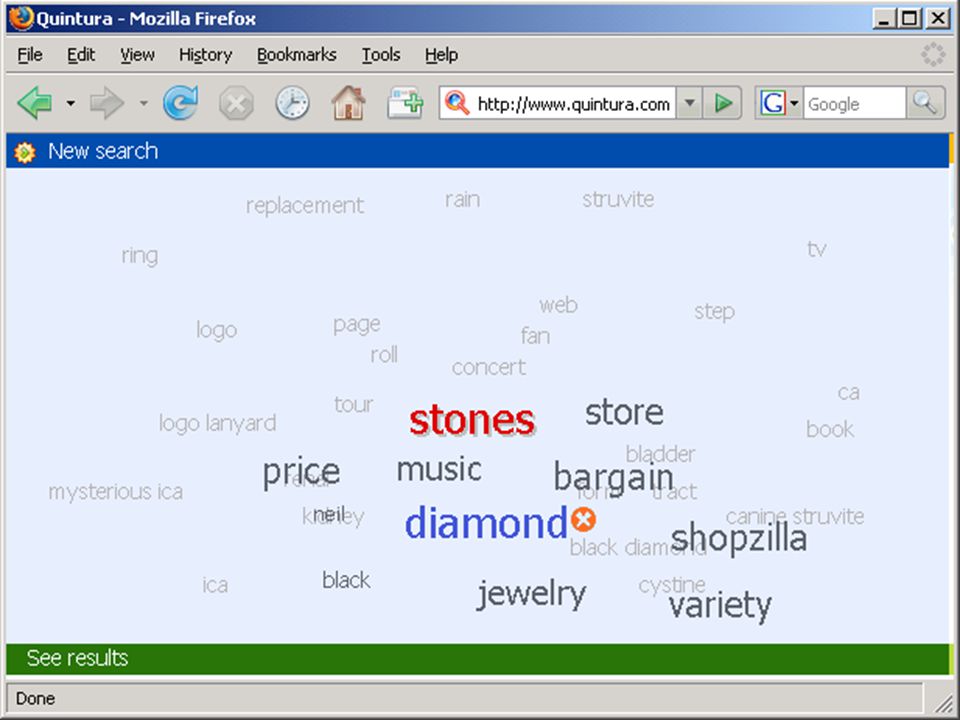
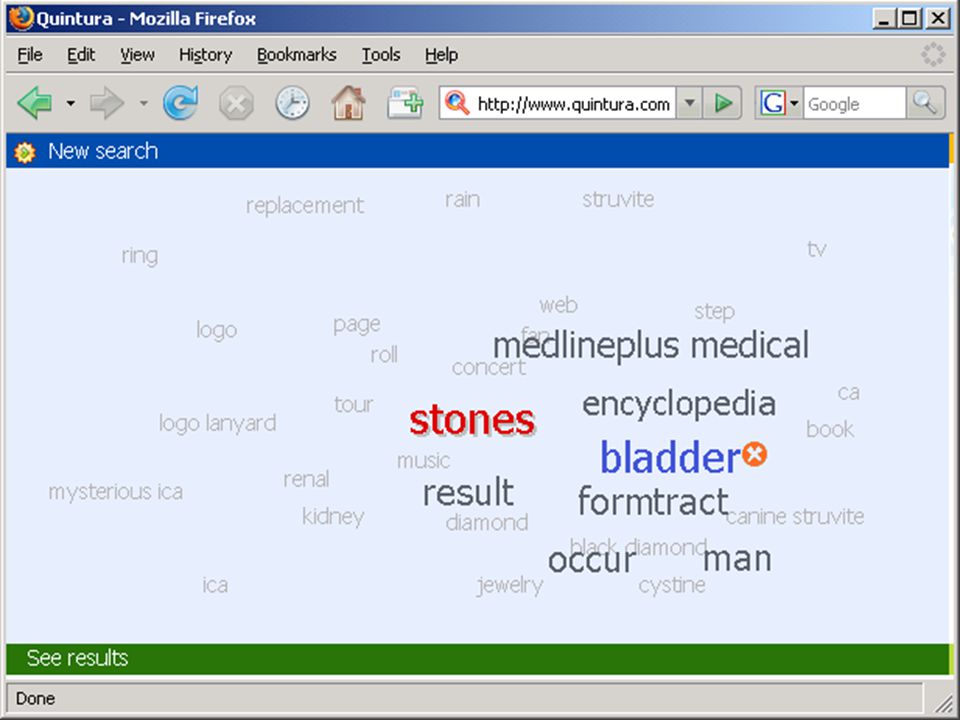
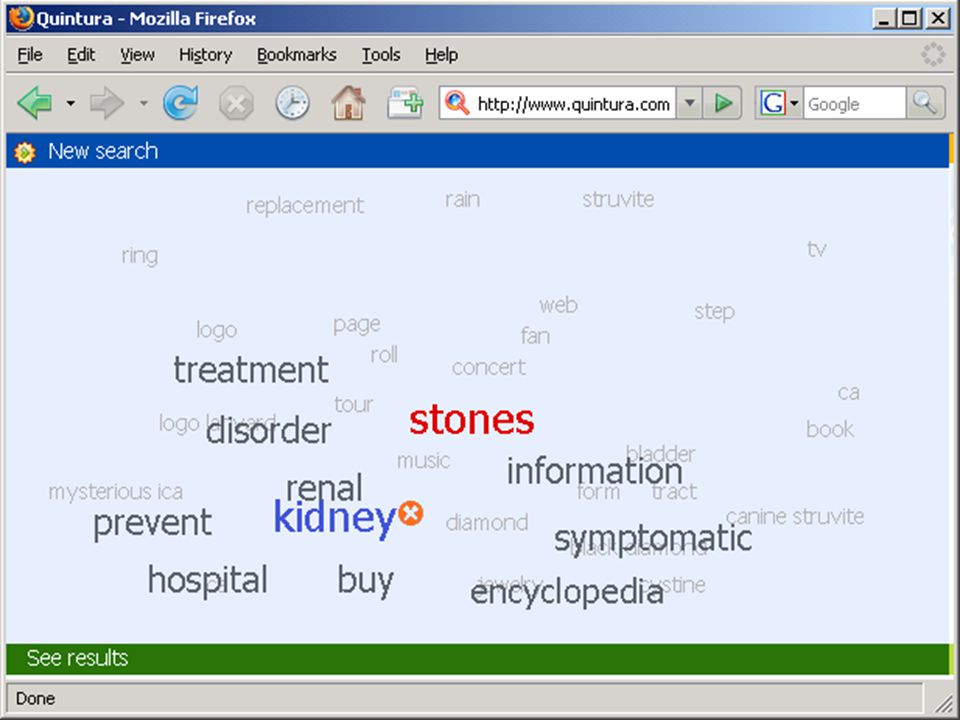
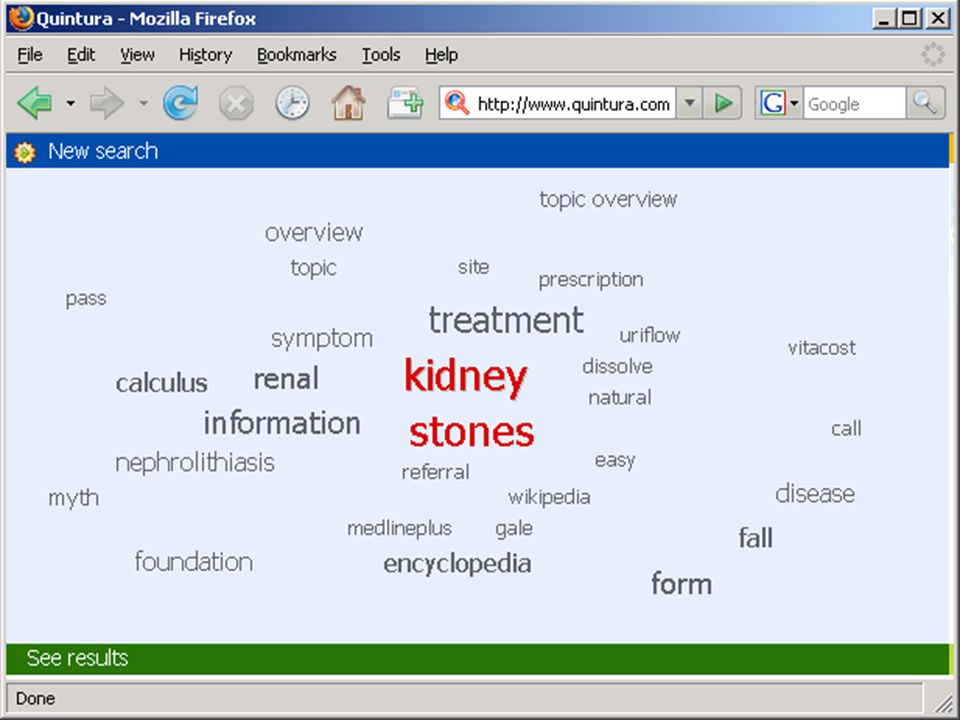
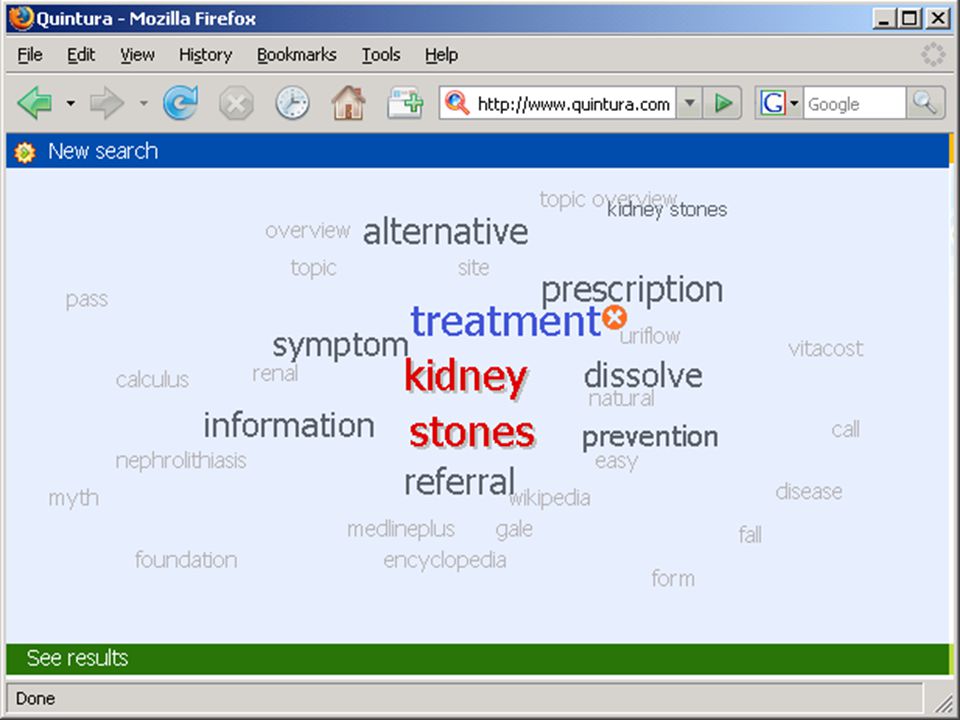
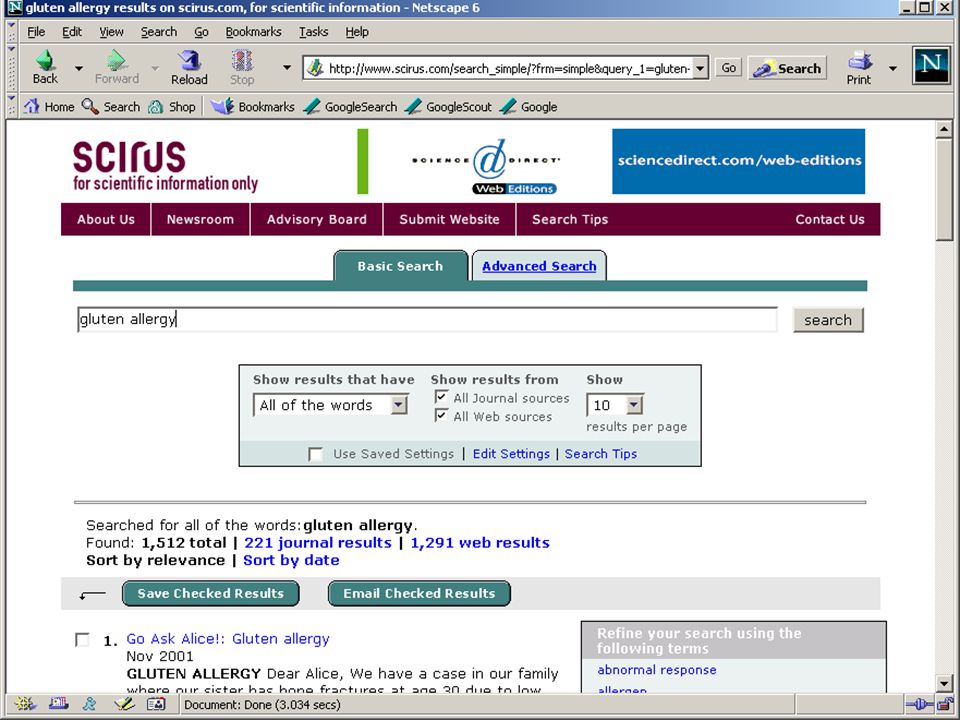
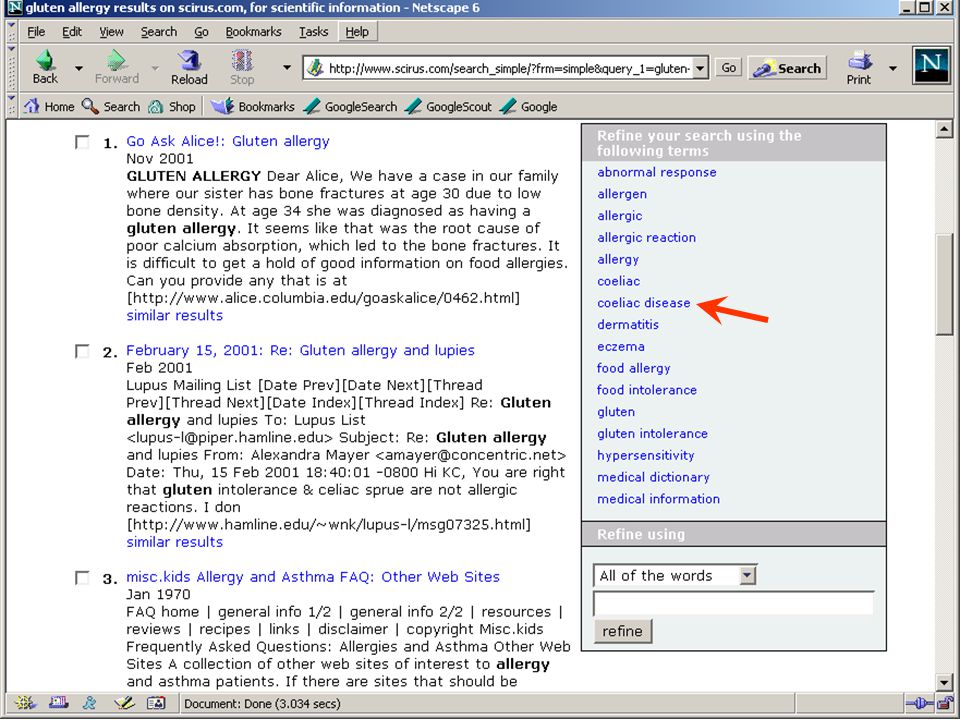
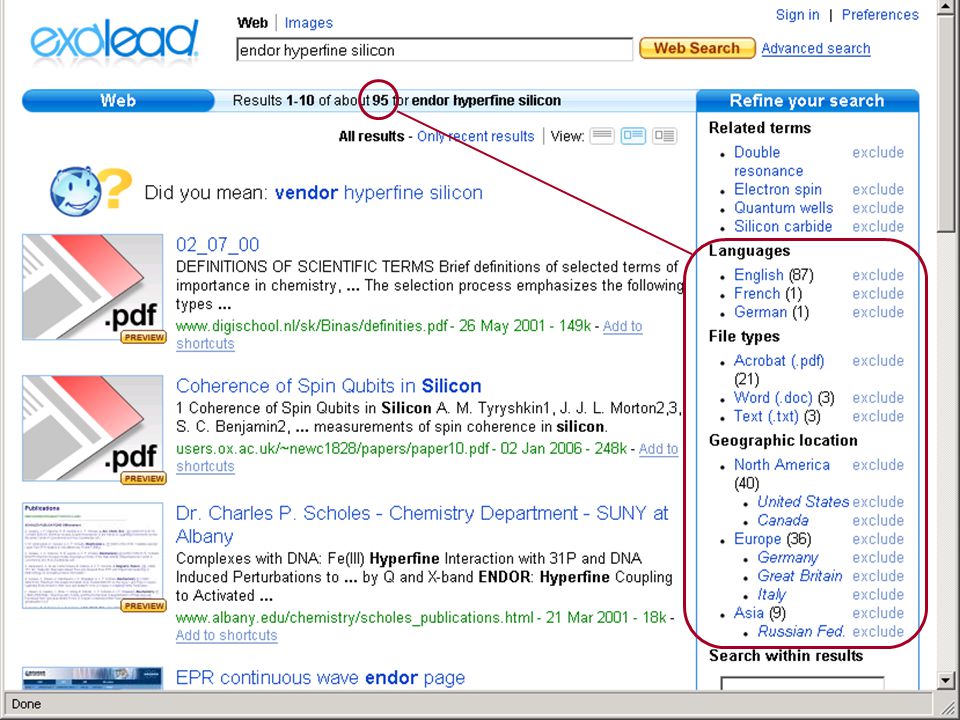
termen extraheren computer haalt karakteristieke (andere) woorden/begrippen uit eerste N documenten van zoekresultaat (statistiek - tfidf) gebruiker kiest daaruit termen om zoekactie in te perken (soms ook termen uit te sluiten, of juist resultaat met OR uit te breiden) bijv.: Quintura (frontend voor Yahoo) Scirus database van Elsevier aquabrowser (o.a. bij bibliotheek.nl)
 bijv.: Quintura (frontend voor Yahoo) Scirus database van Elsevier. aquabrowser (o.a. bij bibliotheek.nl)")
39
OR

40
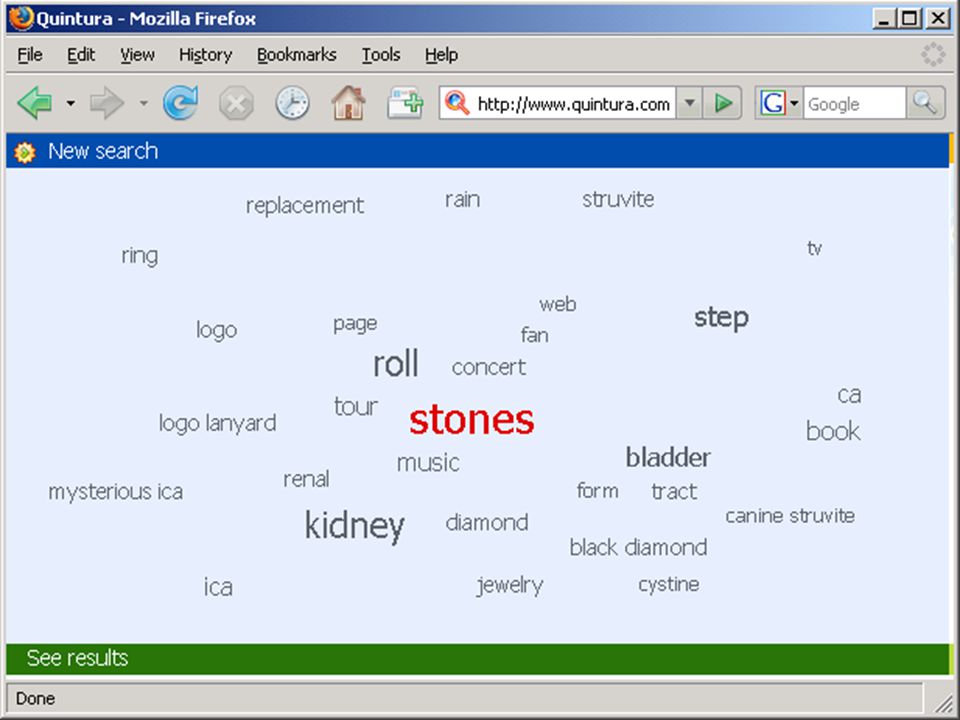
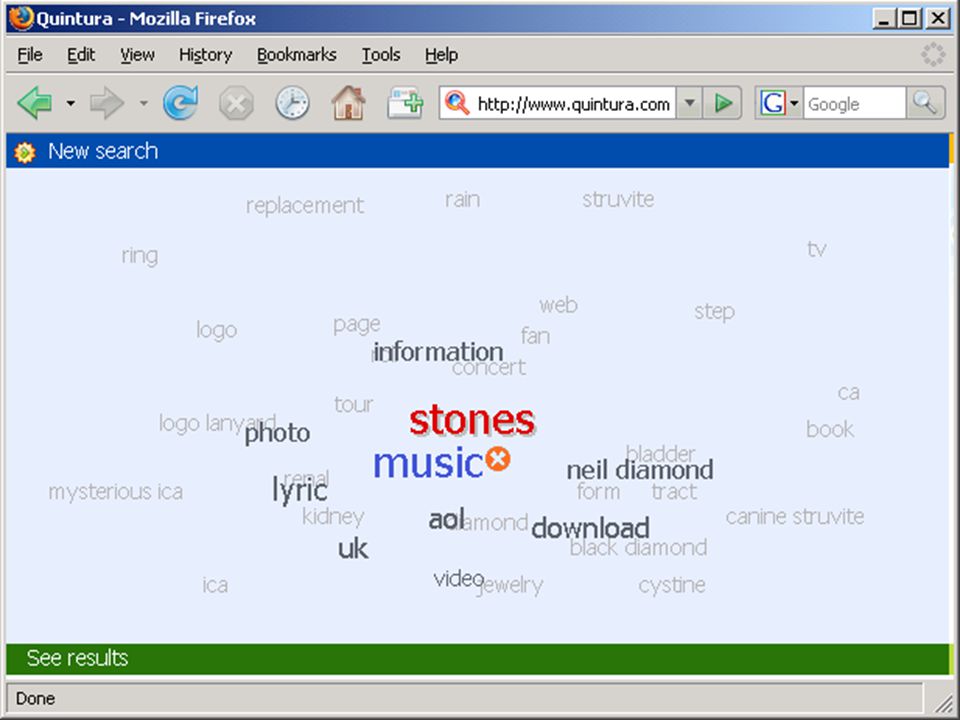
wolk van termen in Aquabrowser:
die termen kunnen uit statistische analyse, woordenlijst, thesaurus, semantisch netwerk o.i.d. komen

41
ook zogenaamd "parametrisch" zoeken,
waarbij zoekresultaat al wordt opgedeeld aan de hand van daarin aanwezige "geformaliseerde metadata"

43
termen extraheren inperken op juiste betekenis of context
computer haalt karakteristieke (andere) woorden/begrippen uit eerste N documenten van zoekresultaat (statistiek - tfidf) gebruiker kiest daaruit termen om zoekactie in te perken (soms ook termen uit te sluiten, of juist resultaat met OR uit te breiden) bijv.: Quintura (frontend voor Yahoo) Scirus database van Elsevier aquabrowser (o.a. bij bibliotheek.nl) inperken op juiste betekenis of context betere precisie uitbreiden met meer “synoniemen” verbetert recall
 woorden/begrippen uit eerste N documenten van zoekresultaat (statistiek - tfidf) gebruiker kiest daaruit termen om zoekactie in te perken (soms ook termen uit te sluiten, of juist resultaat met OR uit te breiden) bijv.: Quintura (frontend voor Yahoo) Scirus database van Elsevier. aquabrowser (o.a. bij bibliotheek.nl) inperken op juiste betekenis of context. betere precisie. uitbreiden met meer synoniemen verbetert recall.")
44
terugkoppeling gebruiker klikt bij relevante hit op “more like this”
computer zoekt op grond van daarin aanwezige termen of patronen naar daarop lijkende documenten bijv.: Scirus, Google Autonomy gebruiker markeert relevante hits zoektermen of patronen die in die documenten voorkomen krijgen hoger gewicht bij toekomstige zoekacties krijgen documenten met die termen of patronen een hogere berekende relevantie bijv.: Autonomy

45
terugkoppeling kiezen van juiste betekenis of context
gebruiker klikt bij relevante hit op “more like this” computer zoekt op grond van daarin aanwezige termen of patronen naar daarop lijkende documenten bijv.: Scirus, Google Autonomy gebruiker markeert relevante hits zoektermen of patronen die in die documenten voorkomen krijgen hoger gewicht bij toekomstige zoekacties krijgen documenten met die termen of patronen een hogere berekende relevantie bijv.: Autonomy kiezen van juiste betekenis of context (o.a. via verbeteren van relevance ranking) betere precisie
 betere precisie.")
Verwante presentaties





 in. Je heeft geen AND of OR functie te gebruiken. De woorden worden vanzelf verbonden met AND in de zoekmotor. •Het.>")
 Zoekresultaat uitbreiden door gebruik van meerdere EBSCO-databases Universiteitsbibliotheek verder = klikken.>")

 LEVV, november 2006.>")












