Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Ontsluiten en zoeken kunnen we het nog vinden? Eric Sieverts
Universiteitsbibliotheek Utrecht & Instituut voor Media- & Informatiemanagement Hogeschool van Amsterdam januari 2007

2
waarom ontsluiten we eigenlijk ?
we ontsluiten om te kunnen vinden dat is waar (want nodig) voor niet-digitaal materiaal dat is waar (want nodig?) voor digitaal niet-tekst materiaal is dat ook nog altijd waar voor digitaal materiaal? in een Google-maatschappij is het in elk geval niet meer strikt nodig Eric Sieverts | | |
 voor niet-digitaal materiaal. dat is waar (want nodig ) voor digitaal niet-tekst materiaal. is dat ook nog altijd waar voor digitaal materiaal in een Google-maatschappij is het in elk geval niet meer strikt nodig. Eric Sieverts | | |")
3
ontsluiting en vinden agenda: hoe wordt nu ontsloten?
ontsluiting en metadata in een web-omgeving klassieke principes en nieuwe inzichten ontsluiten voor browsen of voor zoeken de gebruiker aan de macht? wat te doen als handmatig ontsluiten te duur wordt? “user-generated tagging” automatisch classificeren alleen retrieval i.p.v. ontsluiting ? standaardisatie en toekomst van metadata dublin core rdf en xml semantisch web Eric Sieverts | | |

4
ontsluiting klassiek: digitaal: formele ontsluiting
inhoudelijke ontsluiting eveneens: formeel & inhoudelijk nu: metadata nu ook onder noemer : knowledge organisation systems (KOS) maar tevens beschikbaarstelling / toegankelijkheid: wijze van opslaan linking van documenten (door)zoekbaarheid …... digitaal: Eric Sieverts | | |
 maar tevens beschikbaarstelling / toegankelijkheid: wijze van opslaan. linking van documenten. (door)zoekbaarheid. …... digitaal: Eric Sieverts | | |")
5
terminologie van KOSsen
classificatie systematische ordening van "objecten" in boom- structuur (elk object kan in principe maar op één plaats staan) thesaurus woordsysteem met voorkeurstermen (+ verwijzingen) waartussen hiërarchische relaties (meestal veel "losse boompjes") (postcoördinatie: elk object kan met meer woorden gekarakteriseerd) taxonomie meestal: enkelvoudige zuiver hiërarchische structuur (eenvoudig soort classificatie), inclusief zijn "content" semantisch netwerk “alle” woorden uit de taal, waartussen velerlei soorten getypeerde relaties ontologie woordsysteem waarin “kennis van de wereld” (oorspronkelijk uit wereld van kunstmatige intelligentie); als thesaurus, maar met meer soorten getypeerde relaties; in context van semantisch web in de praktijk vaak in het algemeen gebruikt voor allerlei van bovenstaande types van systemen Eric Sieverts | | |
 thesaurus woordsysteem met voorkeurstermen (+ verwijzingen) waartussen hiërarchische relaties (meestal veel losse boompjes ) (postcoördinatie: elk object kan met meer woorden gekarakteriseerd) taxonomie meestal: enkelvoudige zuiver hiërarchische structuur (eenvoudig soort classificatie), inclusief zijn content semantisch netwerk alle woorden uit de taal, waartussen velerlei soorten getypeerde relaties. ontologie woordsysteem waarin kennis van de wereld (oorspronkelijk uit wereld van kunstmatige intelligentie); als thesaurus, maar met meer soorten getypeerde relaties; in context van semantisch web in de praktijk vaak in het algemeen. gebruikt voor allerlei van bovenstaande types van systemen. Eric Sieverts | | |")
6
visualisatie van de structuur van KOSsen
is een belangrijk terrein van onderzoek, zowel ten behoeve van navigatie als van ondersteuning bij het zoekproces voorbeeld voor een classificatie/taxonomie: de structuur van de OpenDirectory

7
visualisatie van een “soort” thesaurus:
de Roget-thesaurus

8
visualisatie van semantisch netwerk: “wordnet”

9
visualisatie van een deel van een “business”-ontologie

10
ontsluiting in een web-omgeving - thesaurus
Henk Magrijn (MIM/HVA): een thesaurus is een postcoördinatieve informatietaal, die bestaat uit een geordende verzameling van uit natuurlijke taal, op basis van zoveel mogelijk enkelvoudige begripseenheden, gekozen termen, waarvan de vorm, en de onderlinge semantische relaties zijn vastgelegd een thesaurus is geschikter voor zoeken dan voor browsen Eric Sieverts | | |
: een thesaurus is een. postcoördinatieve informatietaal, die bestaat uit. een geordende verzameling van. uit natuurlijke taal, op basis van zoveel mogelijk enkelvoudige begripseenheden, gekozen termen, waarvan. de vorm, en de. onderlinge semantische relaties zijn vastgelegd. een thesaurus is geschikter voor zoeken dan voor browsen. Eric Sieverts | | |")
11
ontsluiting in een web-omgeving - thesaurus
ten behoeve van gemak van zoeksysteem verwijzingen op basis van: Gelijkwaardigheid (synoniemen) Aves Vogels Use Vogels UF Aves >> automatisch daarop kunnen zoeken Hiërarchie (ruimere en specifiekere begrippen) [geslacht/soort, geheel/deel] Vogels Zangvogels NT Zangvogels NT Kanaries BT Dieren BT Vogels TT Dieren >> generiek (hiërarchisch) op begrippen kunnen zoeken Eric Sieverts | | |
 Aves Vogels. Use Vogels UF Aves. >> automatisch daarop kunnen zoeken. Hiërarchie (ruimere en specifiekere begrippen) [geslacht/soort, geheel/deel] Vogels Zangvogels NT Zangvogels NT Kanaries BT Dieren BT Vogels. TT Dieren. >> generiek (hiërarchisch) op begrippen kunnen zoeken. Eric Sieverts | | |")
12
ontsluiting in een web-omgeving - thesaurus
Voor zoekgemak, -effectiviteit en -kwaliteit: denk wel om de zuiverheid van de relaties! Alleen bij geslacht/soort, geheel/deel dus niet bijvoorbeeld: Objecten - producten Vogels NT Eieren Objecten - activiteiten Vogels NT Voortplanting Abstract - concreet Voortplanting NT Eieren Et cetera Eric Sieverts | | |

13
ontsluiting in een web-omgeving - gebruiksgemak in een Google-wereld
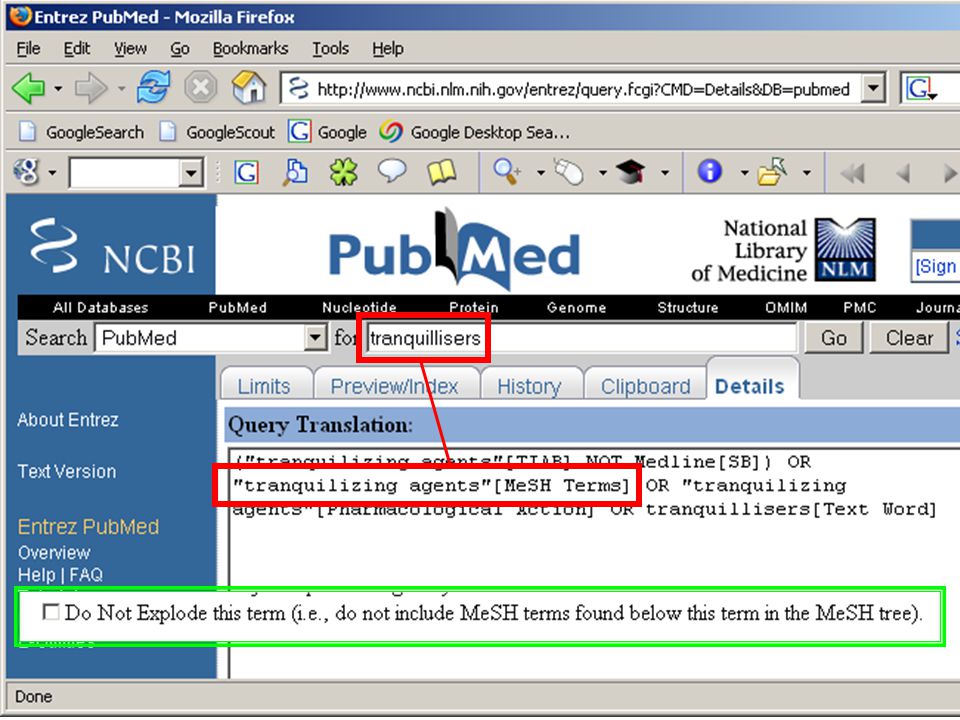
zoekvraag automatisch vertalen naar juiste term(en): met behulp van “user thesaurus” (heel veel synoniem-relaties) mapping van thesaurustermen met semantisch netwerk (ook voor vak-jargon?) dialoog-systeem dat gebruiker meer informatie over zijn vraag ontfutselt, of andere taaltechnologie probeert systeem de juiste zoektermen te vinden bij door gebruiker ingetikte zoekwoorden automatisch generiek zoeken voorbeeld: Pubmed database op internet Eric Sieverts | | |
: met behulp van. user thesaurus (heel veel synoniem-relaties) mapping van thesaurustermen met semantisch netwerk (ook voor vak-jargon ) dialoog-systeem dat gebruiker meer informatie over zijn vraag ontfutselt, of. andere taaltechnologie. probeert systeem de juiste zoektermen te vinden bij door gebruiker ingetikte zoekwoorden. automatisch generiek zoeken voorbeeld: Pubmed database op internet. Eric Sieverts | | |")
15
ontsluiting in een web-omgeving - classificatie
doel van classificatie: zodanig orde brengen in een verzameling objecten, informatie, …., dat iemand er de weg in kan vinden fysieke of virtuele plaatsing en ordening van objecten, documenten, informatie, bestanden, ….. een classificatie is handiger voor browsen dan voor zoeken, zeker in een web-omgeving Eric Sieverts | | |

16
ontsluiting in een web-omgeving - classificatie
Henk Magrijn (MIM/HVA): Classificatie (als activiteit) is het bij elkaar brengen van zaken die iets met elkaar gemeen hebben en het scheiden van zaken die van elkaar verschillen Een classificatie (als "ding") is een precoördinatieve informatietaal, die bestaat uit een geordende verzameling van termen die al dan niet complexe onderwerpen beschrijven, waarvan de vorm, en de onderlinge semantische en syntactische relaties zijn vastgelegd Eric Sieverts | | |
: Classificatie (als activiteit) is het bij elkaar brengen van zaken die iets met elkaar gemeen hebben en het scheiden van zaken die van elkaar verschillen. Een classificatie (als ding ) is een. precoördinatieve informatietaal, die bestaat uit. een geordende verzameling van. termen. die al dan niet complexe onderwerpen beschrijven, waarvan. de vorm, en de. onderlinge semantische en syntactische relaties zijn vastgelegd. Eric Sieverts | | |")
17
ontsluiting in een web-omgeving - classificatie
jarenlange gebruikspraktijk wijst uit dat je er naar moet streven je aan de volgende theoretische bouwregels te houden: eenheid van verdelingskarakteristiek onderverdeling van een klasse moet gebaseerd zijn op één en hetzelfde criterium co-extensie van een klasse met haar subklassen gezamenlijke omvang van de subklassen moet gelijk zijn aan de omvang van de klasse die onderverdeeld is modulatie of gradatie verdeling van een klasse in subklassen moet geleidelijk verlopen collocatie rangschikkingsvolgorde van subklassen van dezelfde klasse (presentatie): naaste buren, naaste verwanten Eric Sieverts | | |
: naaste buren, naaste verwanten. Eric Sieverts | | |")
18
ontsluiting in een web-omgeving - classificatie
eenheid van verdelingskarakteristiek en co-extensie niet: 123 auto's personenauto's raceauto's vrachtauto's rode auto's trapauto's speelgoedauto's dieselauto's maar??: 687.1 kleding herenkleding dameskleding kinderkleding sportkleding gelegenheidskleding beroepskleding beschermende kleding 687.2 schoeisel indelingscriteria: doelgroep, gebruik, mate van bescherming Eric Sieverts | | |

19
ontsluiting in een web-omgeving - classificatie
voorbeeld van "modulatie" niet: Dieren Parkieten wel: Dieren Vogels Zangvogels Parkieten mogelijke "collocatie"-volgorde evolutionair (opening, middenspel, eindspel) chronologisch (15e eeuw, 16e eeuw, 17e eeuw, ..) gebruiksfrequentie alfabetisch etc. als de gebruiker het maar "door heeft" Eric Sieverts | | |
 chronologisch (15e eeuw, 16e eeuw, 17e eeuw, ..) gebruiksfrequentie. alfabetisch. etc. als de gebruiker het maar door heeft Eric Sieverts | | |")
20
ontsluiting in een web-omgeving - taxonomie
een classificatie (als "ding"), in een aanklikbare presentatie van categorieën, die specifiek aansluiten op de onderwerpen, doelstellingen, taken, werkprocessen, beschikbare content, van het bedrijf / de organisatie en met omschrijvingen gekarakteriseerd worden, Eric Sieverts | | |
, in een aanklikbare presentatie van categorieën, die specifiek aansluiten op de. onderwerpen, doelstellingen, taken, werkprocessen, beschikbare content, van het bedrijf / de organisatie. en met omschrijvingen gekarakteriseerd worden, Eric Sieverts | | |")
21
ontsluiting in een web-omgeving - taxonomie
vaak ook: inclusief de volgens die systematiek ingedeelde "content" combinatie met thesaurus-achtig woordsysteem om gebruiker ook via zoekproces naar juiste categorie te leiden soms ook: "meer-dimensionaal" voor meer invalshoeken zie voorbeeld van Verity Eric Sieverts (MIM-HvA) DIO (10/11/2004)
 DIO (10/11/2004)")
23
ontsluiting in een web-omgeving - taxonomie / classificatie
stappen bij bouwen van taxonomie/classificatie doel bepalen onderwerpen verzamelen homogene groepen maken (ordenen in klassen) collocatievolgorde bepalen < tot hier in elk geval > combinatievolgorde vaststellen ("economie-frankrijk" of andersom) notatie toekennen (indien nodig) ...… presentatie van klassen en hun “content” categorieën via hyperlinks aan te klikken en doorgelinkt content vrijwel altijd dynamisch vanuit database of content management systeem gegenereerd Eric Sieverts | | |
 collocatievolgorde bepalen < tot hier in elk geval > combinatievolgorde vaststellen ( economie-frankrijk of andersom) notatie toekennen (indien nodig) ...… presentatie van klassen en hun content categorieën via hyperlinks aan te klikken en doorgelinkt. content vrijwel altijd dynamisch vanuit database of content management systeem gegenereerd. Eric Sieverts | | |")
24
linking als ontsluiting
linking wordt een steeds belangrijker vorm van ontsluiting, want: links brengen je naar (andere) gerelateerde informatie en “relaties” zijn een algemeen verschijnsel in elk soort informatiesysteem tussen begrippen zagen we die al (bijv. thesaurus) maar ook direct tussen "objecten" (bijv. hyperlinks, literatuurreferenties, relationele database) Eric Sieverts | | |
 gerelateerde informatie. en relaties zijn een algemeen verschijnsel in elk soort informatiesysteem. tussen begrippen zagen we die al. (bijv. thesaurus) maar ook direct tussen objecten (bijv. hyperlinks, literatuurreferenties, relationele database) Eric Sieverts | | |")
25
hyperlinks hyperlinks in een web-omgeving hebben
ook invloed op klassieke ontsluiting: maken presentatie en gebruik van taxonomieën en classificaties veel makkelijker (gewoon links aanklikken) je hoeft niet zo heel streng te zijn met klassieke regels voor bouw van de systemen (klasse op meer plaatsen in boomstructuur: variabele combinatievolgorde, aanklikbare dwarsverbanden) Eric Sieverts | | |
 je hoeft niet zo heel streng te zijn met klassieke regels voor bouw van de systemen. (klasse op meer plaatsen in boomstructuur: variabele combinatievolgorde, aanklikbare dwarsverbanden) Eric Sieverts | | |")
28
literatuurreferenties (reference linking)
link van bibliografisch record in database naar digitale full-text link van literatuurreferentie in full-text artikel naar full-text van aangehaalde referentie link van literatuurreferentie in citatie-index naar bibliografisch record van aangehaalde (geciteerde) referentie ……. Eric Sieverts | | |
 referentie. ……. Eric Sieverts | | |")
29
bibliografische metadata
full-text

30
referentie bij full-text
(of andere vorm) van aangehaald artikel
 van. aangehaald artikel.")
31
literatuurreferenties (reference linking)
veel recente ontwikkelingen in technieken hiervoor onder meer: doi / crossref (van club grote uitgevers) sfx (van bibliotheekautomatiseerder) openURL (open source / metadata based) sfx en openURL gericht op mogelijkheid om bij een object meer gerelateerde "services" aan te bieden voor meer informatie zie: Eric Sieverts | | |
 sfx (van bibliotheekautomatiseerder) openURL (open source / metadata based) sfx en openURL gericht op mogelijkheid om bij een object meer gerelateerde services aan te bieden. voor meer informatie zie: Eric Sieverts | | |")
32
voorbeeld van keuzemenu bij tijdschrift- artikel link alleen als
er digitaal abonnement is link alleen als er geen digitaal en wel papieren abonnement is link alleen als er geen abonnement is links naar mogelijke additionele informatie naar keuze

33
als handmatig ontsluiten (door specialist) te duur wordt
gebruikers het werk laten doen (“user generated tagging”) automatisch classificeren / verrijken retrieval i.p.v. ontsluiting Eric Sieverts | | |
 automatisch classificeren / verrijken. retrieval i.p.v. ontsluiting. Eric Sieverts | | |")
34
de (eind)gebruiker aan de macht?
nieuwe hype onder de noemer van WEB 2.0 tagging social bookmarking folksonomies .... (zelf “trefwoorden” toekennen) Eric Sieverts | | |
 Eric Sieverts | | |")
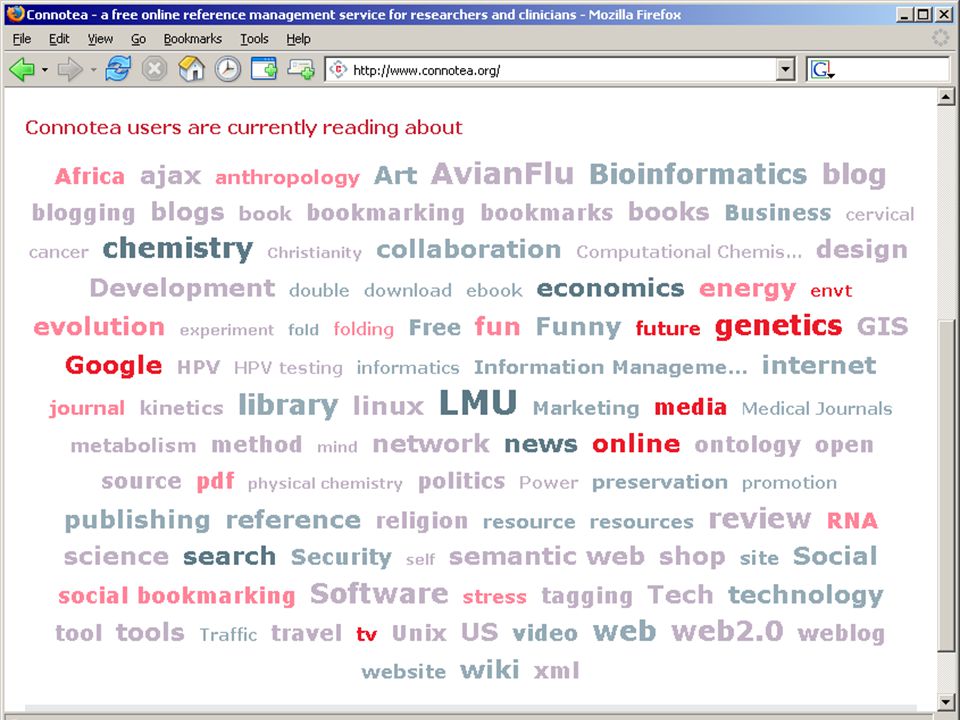
35
de (eind)gebruiker aan de macht?
bij web-2.0 diensten kan iedereen zijn eigen tags (= trefwoorden) toekennen aan: webpagina's als bookmarks (del.icio.us, connotea, furl, yahoo-myweb, ...) om zoekmachine te "tunen" (wink, yoono, ...) nieuws (digg) foto's en video's (flickr, youtube) blogposts (overal) .... Eric Sieverts | | |
 toekennen aan: webpagina s. als bookmarks (del.icio.us, connotea, furl, yahoo-myweb, ...) om zoekmachine te tunen (wink, yoono, ...) nieuws (digg) foto s en video s (flickr, youtube) blogposts (overal) .... Eric Sieverts | | |")
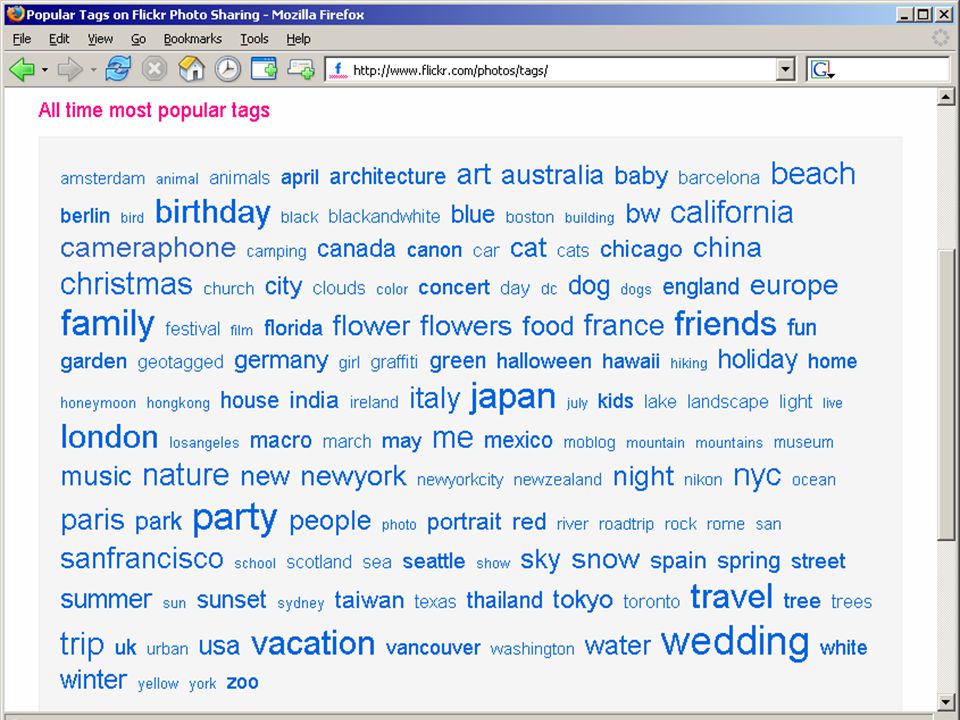
36
de (eind)gebruiker aan de macht?
waarom is tagging leuk? iedereen bepaalt zelf hoe iets te karakteriseren ("people powered") gebruiker kent eigen jargon het beste gericht op samenwerking ("collaboration, sharing, ...") visualisatie met "tag clouds" waarom is tagging niks? geen enkele standaardisatie en controle nu vooral nog voor "populaire" toepassingen tag clouds tonen alleen wat de grote massa leuk vindt Eric Sieverts | | |
 gebruiker kent eigen jargon het beste. gericht op samenwerking ( collaboration, sharing, ... ) visualisatie met tag clouds waarom is tagging niks geen enkele standaardisatie en controle. nu vooral nog voor populaire toepassingen. tag clouds tonen alleen wat de grote massa leuk vindt. Eric Sieverts | | |")
40
de (eind)gebruiker aan de macht?
kan tagging interessant worden? voor publiekstoepassingen is het dat al voor bedrijfsmatige toepassing misschien: binnen (tijdelijke) samenwerkingsverbanden met zelfde "woordgebruik" als informatie-professional supervisie houdt over consistentie van gebruikte terminologie (maar staat dat niet haaks op de gedachte achter tagging?) bij “mapping” op thesaurus Eric Sieverts | | |
 samenwerkingsverbanden met zelfde woordgebruik als informatie-professional supervisie houdt over consistentie van gebruikte terminologie. (maar staat dat niet haaks op de gedachte achter tagging ) bij mapping op thesaurus. Eric Sieverts | | |")
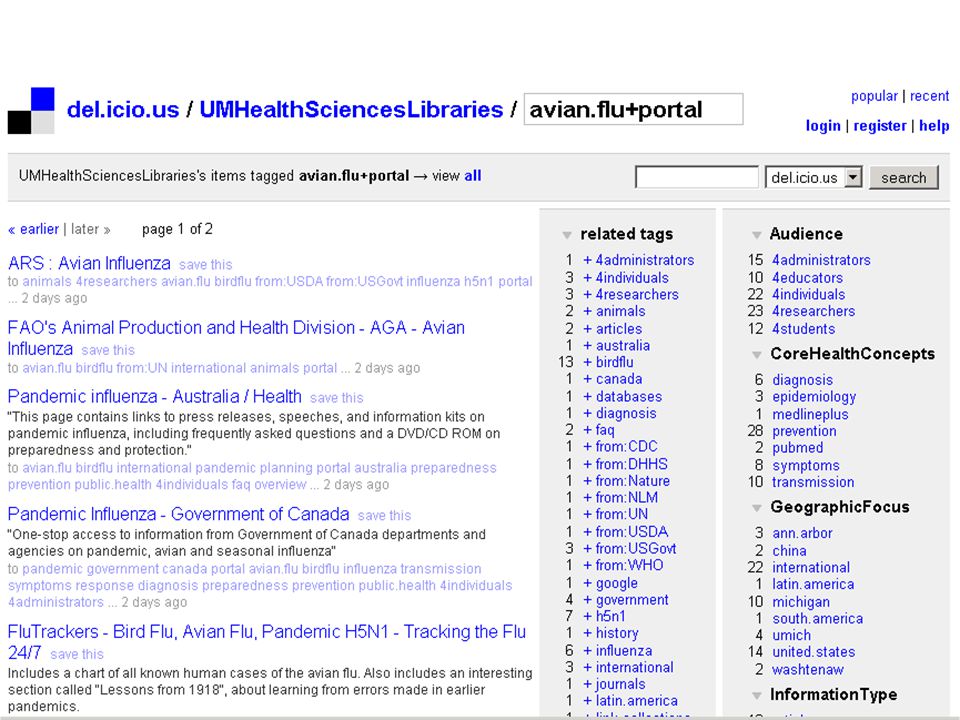
41
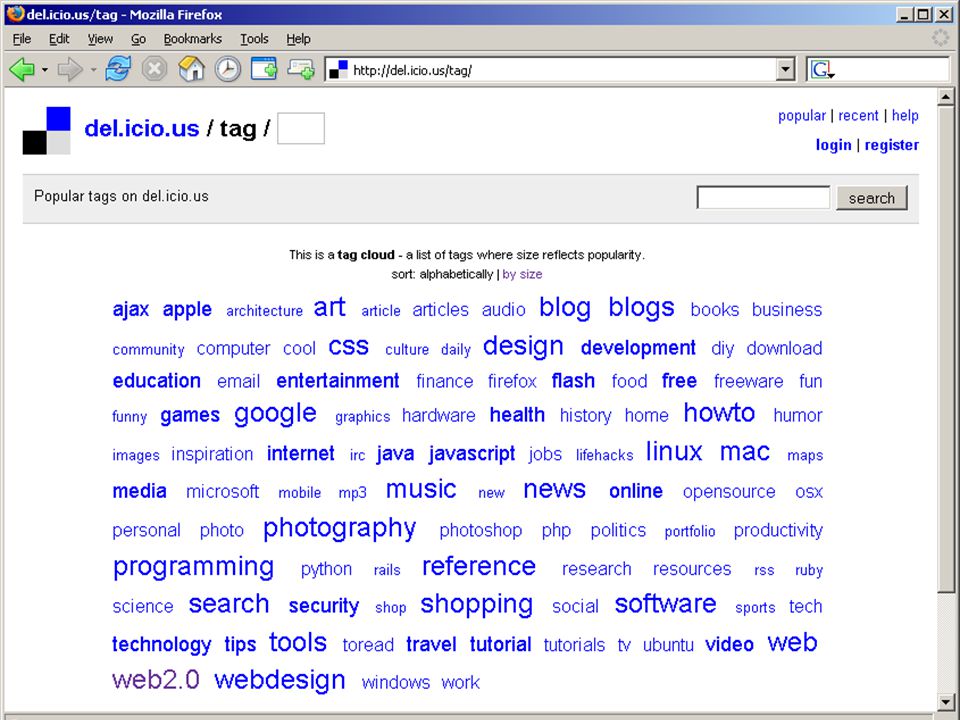
professionele toepassing van tagging via del.icio.us

43
automatisch classificeren - stappen in het proces
meestal: systeem analyseert trainingsdocumenten systeem wordt getraind door matchen van trainingsdocumenten met “klassen” (of handmatig opstellen van kennisregels) systeem analyseert nieuwe documenten systeem matcht nieuwe documenten met “klassen” systeem moet bijleren bij probleemgevallen Eric Sieverts | | |
 systeem analyseert nieuwe documenten. systeem matcht nieuwe documenten met klassen systeem moet bijleren bij probleemgevallen. Eric Sieverts | | |")
44
automatisch classificeren
technieken voor analyse van documenten statistiek van document wordt “vingerafdruk” gemaakt door extractie van meest karakteristieke woorden op basis van relatieve woordfrequenties (tfidf : term-frequentie x inverse document frequentie; in document vaker voorkomende termen die verder zeldzaam zijn) Eric Sieverts | | |
 Eric Sieverts | | |")
45
automatisch classificeren
technieken voor analyse van documenten statistiek regels op basis van vaste - handmatig ingestelde - regels bepaalt de computer welke termen karakteristiek zijn voor (bepaalde aspecten van) de inhoud van een document omdat ze in de titel staan omdat ze met hoofdletters zijn geschreven omdat ze in een vastgelegd rijtje woorden voorkomen vanwege XML-tags …... Eric Sieverts | | |
 de inhoud van een document. omdat ze in de titel staan. omdat ze met hoofdletters zijn geschreven. omdat ze in een vastgelegd rijtje woorden voorkomen. vanwege XML-tags. …... Eric Sieverts | | |")
46
automatisch classificeren
technieken voor analyse van documenten statistiek regels taaltechnologie / linguistische analyse op basis van taalregels herkent de computer samengestelde begrippen, wat zelfstandige naamwoorden zijn, enz. vooral ten behoeve van "normalisatie”: Morfologisch: manager, gemanaged Compounds: hockeytoernooi, hockeystick Syntactisch: energiebesparing, besparing van energie Semantisch: transport, vervoer Eric Sieverts | | |

47
automatisch classificeren
technieken voor analyse van documenten statistiek regels taaltechnologie / linguistische analyse in de praktijk worden meestal combinaties van deze drie basistechnieken toegepast Eric Sieverts | | |

48
automatisch classificeren - training van systeem
thesaurus trainingsdocumenten analyse module trainings module Joop van Gent, Irion “vinger- afdrukken” Eric Sieverts | | |

49
automatisch classificeren - training van systeem
thesaurus trainingsdocumenten verrijking van thesaurus analyse module trainings module Joop van Gent, Irion “vinger- afdrukken” Eric Sieverts | | |

50
automatisch classificeren - matchen trainingsdocument met klasse
handmatig (per document door “documentalist”) automatisch (op basis van al eerder aan documenten toegekende klassen; het was ooit al eens door iemand ontsloten / ingedeeld) Eric Sieverts | | |
 automatisch. (op basis van al eerder aan documenten toegekende klassen; het was ooit al eens door iemand ontsloten / ingedeeld) Eric Sieverts | | |")
51
automatisch classificeren - vastlegging karakteristieken
karakteristieken voor klassen / thesaurustermen kunnen zijn vastgelegd: in “black-box” (geheel automatisch) in formele “kennis”-regels automatisch gegenereerd en handmatig aan te passen geheel handmatig vastgelegd Eric Sieverts | | |
 in formele kennis -regels. automatisch gegenereerd en handmatig aan te passen. geheel handmatig vastgelegd. Eric Sieverts | | |")
52
automatisch classificeren - classificeren met systeem
nieuwe documenten verrijkte thesaurus analyse module classificatie module verrijkte documenten “vinger- afdrukken” Joop van Gent, Irion Eric Sieverts | | |

53
automatisch classificeren - matchen van documenten met klassen
vergelijking van vingerafdruk van (nieuw) document met vingerafdrukken van alle klassen (thesaurustermen) matching bijvoorbeeld met “vector-model” ingestelde drempelwaarden bepalen vaak betrouwbaarheid van toekenning denk ook hier aan 80/20-achtige regels hoeveelheid handmatig te verwerken twijfelgevallen omgekeerd evenredig met mate van betrouwbaarheid Eric Sieverts | | |
 document met vingerafdrukken van alle klassen (thesaurustermen) matching bijvoorbeeld met vector-model ingestelde drempelwaarden bepalen vaak. betrouwbaarheid van toekenning. denk ook hier aan 80/20-achtige regels. hoeveelheid handmatig te verwerken twijfelgevallen omgekeerd evenredig met mate van betrouwbaarheid. Eric Sieverts | | |")
55
automatisch classificeren - enkele voorwaarden
uit ervaringen bij Irion (Joop van Gent) zijn nodig: een goede thesaurus/taxonomie, met niet te veel categorieën (< 5000) en niet te veel lagen (< 4) (gebruik voor specifiekere begrippen full-text retrieval) zo veel mogelijk “orthogonale” categorieën (geen overlap) gelaagdheid in balans (klassieke modulatie-eis) een representatieve trainingsset in het juiste formaat voldoende groot (>5 documenten per klasse) voldoende distributief (voor elke klasse even veel documenten) losse xml- of txt- documenten een representatieve testset Eric Sieverts | | |
 zijn nodig: een goede thesaurus/taxonomie, met niet te veel categorieën (< 5000) en niet te veel lagen (< 4) (gebruik voor specifiekere begrippen full-text retrieval) zo veel mogelijk orthogonale categorieën (geen overlap) gelaagdheid in balans (klassieke modulatie-eis) een representatieve trainingsset in het juiste formaat. voldoende groot (>5 documenten per klasse) voldoende distributief (voor elke klasse even veel documenten) losse xml- of txt- documenten. een representatieve testset. Eric Sieverts | | |")
56
retrieval en ontsluiting
kunnen we niet gewoon de digitale tekst doorzoeken? (het Google-paradigma) maar: free-text zoeken impliceert allerlei zoekproblemen wat zijn die problemen? welke retrieval- en taal-technologische oplossingen zijn daar al voor? Eric Sieverts | | |
 maar: free-text zoeken impliceert allerlei zoekproblemen. wat zijn die problemen welke retrieval- en taal-technologische oplossingen zijn daar al voor Eric Sieverts | | |")
57
waarin uiten zoekproblemen zich?
(in variabele mate in uiteenlopende soorten systemen - bibliografische databases, full-text bestanden, het web, … ) onvoldoende recall met zoekvraag mis je te veel relevante informatie onvoldoende precisie zoekvraag levert (te) veel niet-relevante informatie Eric Sieverts | | |
 onvoldoende recall. met zoekvraag mis je te veel relevante informatie. onvoldoende precisie. zoekvraag levert (te) veel niet-relevante informatie. Eric Sieverts | | |")
58
oorzaken voor lage recall (recall-killers)
inherent aan free-text zoeken in documenten: variatie in gebruikte woorden (spelling, woordvorm, taal) in tekst staan synoniemen, impliciete aanduidingen, … variëteit aan woorden voor generieke begrippen term-armoede van documenten (catalogus) zoeker "doet het fout": verkeerde zoekterm (spelling, betekenis) te weinig varianten met OR gecombineerd te veel zoek-elementen met AND gecombineerd Eric Sieverts | | |
 in tekst staan synoniemen, impliciete aanduidingen, … variëteit aan woorden voor generieke begrippen. term-armoede van documenten (catalogus) zoeker doet het fout : verkeerde zoekterm (spelling, betekenis) te weinig varianten met OR gecombineerd. te veel zoek-elementen met AND gecombineerd. Eric Sieverts | | |")
59
oorzaken voor lage precisie (precisie-killers)
inherent aan free-text zoeken in documenten : verkeerde relatie tussen ge-AND-e termen niet eenduidige betekenis (homoniemen, acroniemen) term-rijkdom van full-text documenten (laag term-gewicht) zoeker "doet het fout" : verkeerde zoekterm (betekenis, te algemeen) te weinig concepten met AND gecombineerd Eric Sieverts | | |
 term-rijkdom van full-text documenten (laag term-gewicht) zoeker doet het fout : verkeerde zoekterm (betekenis, te algemeen) te weinig concepten met AND gecombineerd. Eric Sieverts | | |")
60
klassieke oplossing gebruik van: taxonomie
thesaurus waarop berust het feit dat we denken dat dit een oplossing biedt? formaliseert betekenissen uniformeert term-rijkdom (dus term-gewicht) legt semantische relaties tussen onderwerpen/termen kan syntactisch verband leggen tussen facetten van onderwerp (precoördinatie) Eric Sieverts | | |
 legt semantische relaties tussen onderwerpen/termen. kan syntactisch verband leggen tussen facetten van onderwerp (precoördinatie) Eric Sieverts | | |")
61
nadelen van klassieke oplossing
gebrek aan flexibiliteit (schrik van de gebruiker/vakspecialist, maar niet meer bij folksonomy / tagging) je moet (kunstmatige) informatietaal gebruiken (schrik van de ergonoom, maar daar zijn wel oplossingen voor) duur omdat mensen termen moeten toekennen (schrik van de manager) Eric Sieverts | | |
 je moet (kunstmatige) informatietaal gebruiken. (schrik van de ergonoom, maar daar zijn wel oplossingen voor) duur omdat mensen termen moeten toekennen. (schrik van de manager) Eric Sieverts | | |")
62
(taal)technologische alternatieven
best-match zoeken met relevantie-ordening truncatie, woordstemming, fuzzy search semantische kennis toevoegen zoekresultaat in "domeinen/contexten” laten clusteren genereren van suggesties voor aanvullende zoektermen terugkoppeling van zoekersoordeel Eric Sieverts | | |

63
relevance ranking factoren
1. meer van de gevraagde termen in een document gevraagde termen op belangrijke plek in document (titel, koppen, eerste paar regels, ….) 3. gevraagde termen komen in document herhaald voor 4. gevraagde termen staan in document dicht bij elkaar 5. termen in document staan in zelfde volgorde als in vraag 6. zeldzame termen krijgen zwaarder gewicht dan algemene 7. hoeveelheid hyperlinks die naar document verwijst 8. hoe vaak een document wordt "bezocht" google bewijst dat dat op het web goed werkt, maar ook op een intranet? Eric Sieverts | | |
 3. gevraagde termen komen in document herhaald voor. 4. gevraagde termen staan in document dicht bij elkaar. 5. termen in document staan in zelfde volgorde als in vraag. 6. zeldzame termen krijgen zwaarder gewicht dan algemene. 7. hoeveelheid hyperlinks die naar document verwijst. 8. hoe vaak een document wordt bezocht google bewijst dat dat op het web goed werkt, maar ook op een intranet Eric Sieverts | | |")
64
relevance ranking factoren
1. meer termen 2. termen in titel/kop/begin 3. termen herhaald 4. termen dicht bij elkaar 5. termen in volgorde 6. zeldzame termen zwaarder 7. hyperlinks naar document 8. bezoek aan document meer concepten ge-AND hoger term-gewicht juiste verband belang specifieke term (kwaliteit) [alleen als er links zijn] (kwaliteit) Eric Sieverts | | |
 [alleen als er links zijn] (kwaliteit) Eric Sieverts | | |")
65
relevance ranking factoren
1. meer van de gevraagde termen in een document 2. gevraagde termen op belangrijke plek in document (titel, koppen, eerste paar regels, ….) 3. gevraagde termen komen in document herhaald voor 4. gevraagde termen staan in document dicht bij elkaar 5. termen in document staan in zelfde volgorde als in vraag 6. zeldzame termen krijgen zwaarder gewicht dan algemene 7. hoeveelheid hyperlinks die naar document verwijst 8. hoe vaak een document wordt "bezocht" allemaal gericht op hogere relevantie voor "de eerste tien", dus op precisie Eric Sieverts | | |
 3. gevraagde termen komen in document herhaald voor. 4. gevraagde termen staan in document dicht bij elkaar. 5. termen in document staan in zelfde volgorde als in vraag. 6. zeldzame termen krijgen zwaarder gewicht dan algemene. 7. hoeveelheid hyperlinks die naar document verwijst. 8. hoe vaak een document wordt bezocht allemaal gericht op hogere relevantie. voor de eerste tien , dus op precisie. Eric Sieverts | | |")
66
trunkatie / stemming / fuzzy zoeken
trunceren computer computeronderwijs stemming computer computing, computation, computers communism community, communication ?? sieverts sievert ?? fuzzy duivendak duijvendak serajevo sarajevo chebychev chebyshev, chebyschef, kok kop, kak, ... ?? Eric Sieverts | | |

67
trunkatie / stemming / fuzzy zoeken
trunceren computer computeronderwijs stemming computer computing, computation, computers communism community, communication sieverts sievert fuzzy duivendak duijvendak neetelenbosch netelenbos kok kop, kak, … compenseert variatie in woordvorm & spelling betere recall maar pas op voor ongewenste effecten !! Eric Sieverts | | |

68
semantische kennis in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen (woorden binnen bepaalde "semantische afstand" van zoekwoord) bijvoorbeeld: irion-21 Eric Sieverts | | |
 door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen (woorden binnen bepaalde semantische afstand van zoekwoord) bijvoorbeeld: irion-21. Eric Sieverts | | |")
69
visualisatie van “wordnet”

70
verbeteren van precisie
semantische kennis in semantisch netwerk worden verbanden gelegd tussen inhoudelijk verwante woorden (in één of meer talen) door omgeving van woord in het netwerk kan betekenis worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen leveren om query te expanderen verbeteren van precisie verbeteren van recall maar semantisch netwerk voor specialistisch domein moet je zelf nog bouwen ! Eric Sieverts | | |
 door omgeving van woord in het netwerk kan betekenis. worden onderscheiden (in document en in query) omgeving van woord in het netwerk kan termen. leveren om query te expanderen. verbeteren van precisie. verbeteren van recall. maar semantisch netwerk. voor specialistisch domein. moet je zelf nog bouwen ! Eric Sieverts | | |")
71
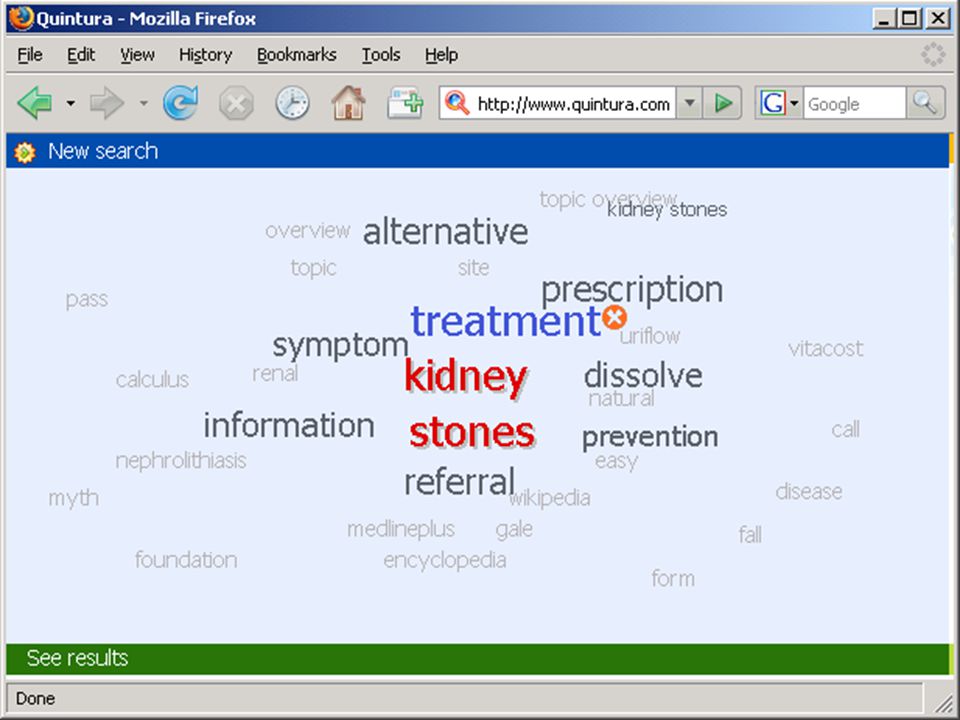
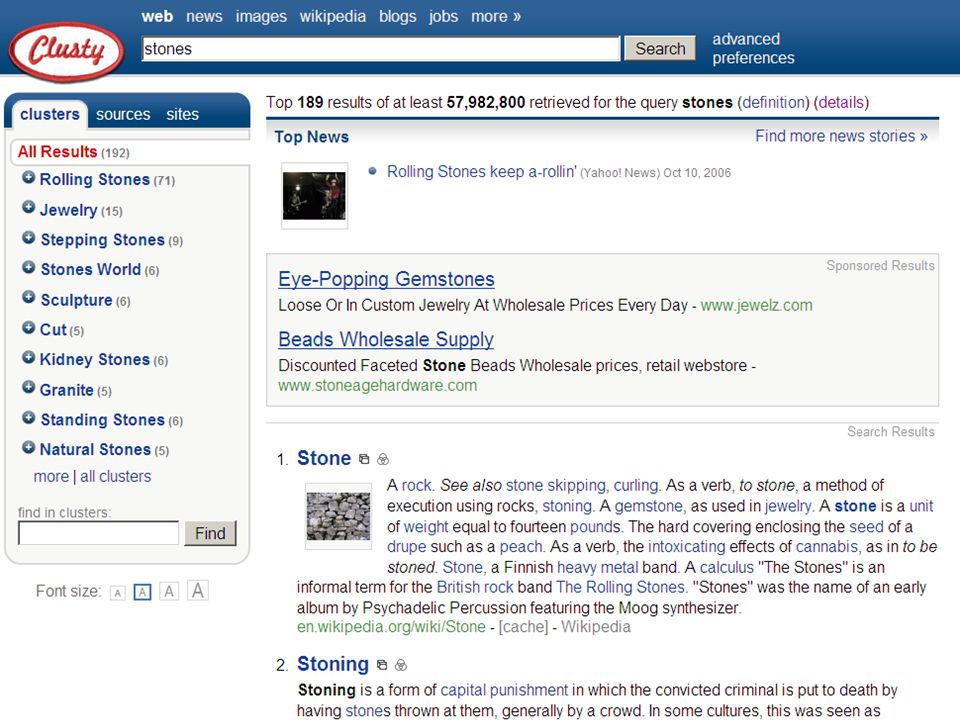
automatisch clusteren/classificeren
op grond van kennisregels (en bestaande “taxonomie”) in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen op grond van statistiek of patronen Ask, Clusty, Quintura, Collarity, …. Autonomy Eric Sieverts | | |
 in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen. op grond van statistiek of patronen. Ask, Clusty, Quintura, Collarity, …. Autonomy. Eric Sieverts | | |")
82
automatisch clusteren/classificeren
op grond van kennisregels (en bestaande “taxonomie”) in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen op grond van statistiek of patronen Ask, Clusty, Quintura, Collarity, …. Autonomy kiezen van juiste betekenis of context betere precisie werkt niet gegarandeerd altijd goed Eric Sieverts | | |
 in feite toepassing automatische classificatie, waarbij klassen als verdelingscriterium dienen. op grond van statistiek of patronen. Ask, Clusty, Quintura, Collarity, …. Autonomy. kiezen van juiste betekenis of context. betere precisie. werkt niet gegarandeerd. altijd goed. Eric Sieverts | | |")
83
termen extraheren bijv.: Scirus database van Elsevier
computer haalt karakteristieke (andere) woorden/begrippen uit eerste N zoekresultaten (statistiek - tfidf) gebruiker kiest daaruit termen om de zoekactie in te perken of uit te breiden bijv.: Scirus database van Elsevier Aquabrowser (o.a. bij Bibliotheek.nl) Eric Sieverts | | |
 woorden/begrippen uit eerste N zoekresultaten. (statistiek - tfidf) gebruiker kiest daaruit termen om de zoekactie in te perken of uit te breiden. bijv.: Scirus database van Elsevier. Aquabrowser (o.a. bij Bibliotheek.nl) Eric Sieverts | | |")
86
OR

87
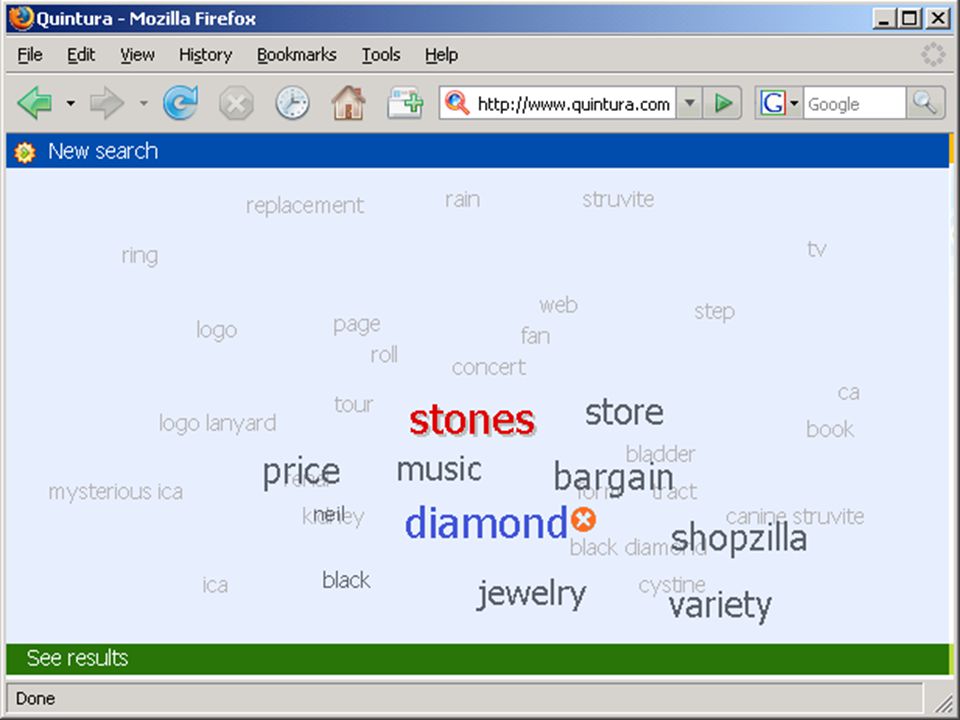
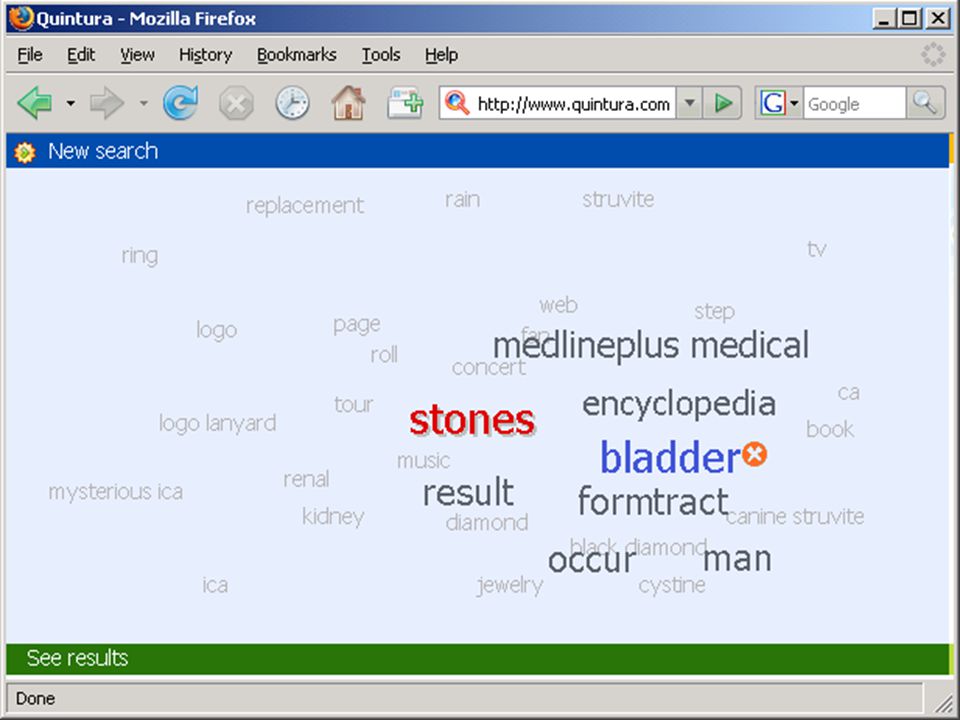
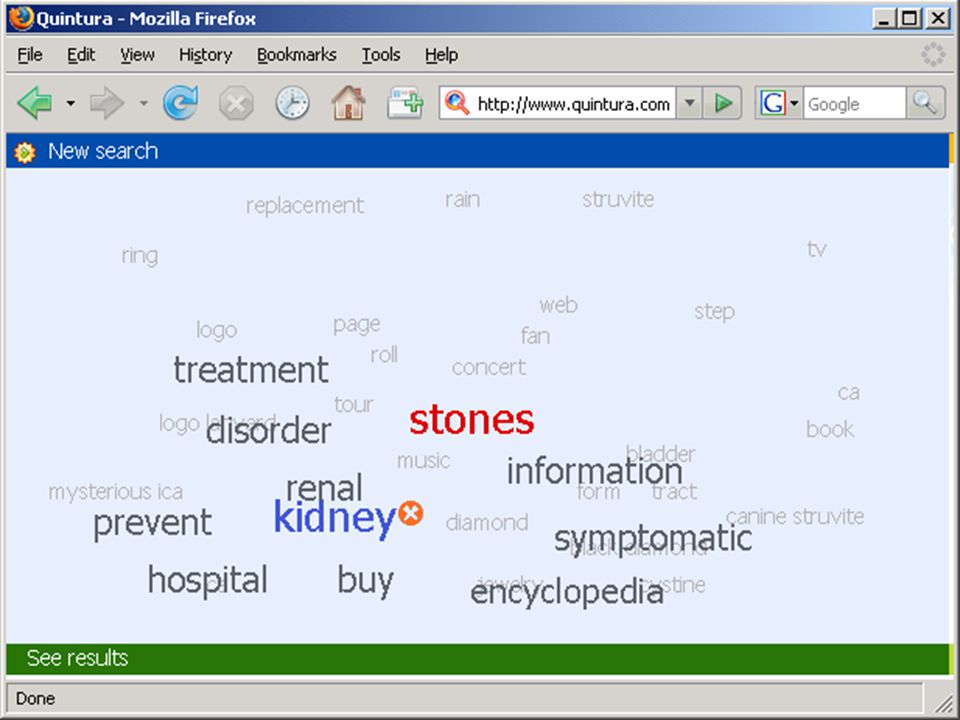
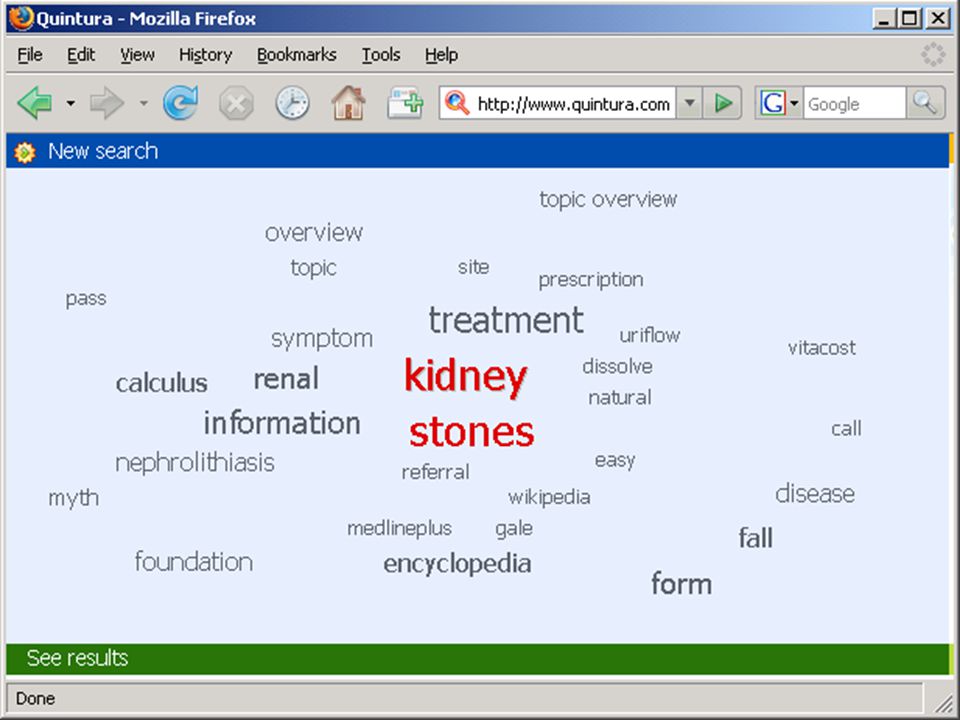
wolk van termen in Aquabrowser:
die termen kunnen uit statistische analyse, woordenlijst, thesaurus, semantisch netwerk o.i.d. komen

88
ook zogenaamd "parametrisch" zoeken,
waarbij zoekresultaat al wordt opgedeeld aan de hand van daarin aanwezige "geformaliseerde metadata"

90
inperken op juiste betekenis of context verbetert precisie
termen extraheren computer haalt karakteristieke (andere) woorden/begrippen uit eerste N zoekresultaten (statistiek - tfidf) gebruiker kiest daaruit termen om de zoekactie in te perken of uit te breiden bijv.: Scirus database van Elsevier Aquabrowser (o.a. bij Bibliotheek.nl) inperken op juiste betekenis of context verbetert precisie uitbreiden met meer “synoniemen” verbetert recall Eric Sieverts | | |
 woorden/begrippen uit eerste N zoekresultaten. (statistiek - tfidf) gebruiker kiest daaruit termen om de zoekactie in te perken of uit te breiden. bijv.: Scirus database van Elsevier. Aquabrowser (o.a. bij Bibliotheek.nl) inperken op juiste betekenis of context. verbetert precisie. uitbreiden met meer synoniemen verbetert recall. Eric Sieverts | | |")
91
terugkoppeling gebruiker klikt bij relevante hit op “more like this”
computer zoekt op grond van daarin aanwezige termen of patronen naar daarop lijkende documenten bijv.: Scirus, Google Autonomy gebruiker markeert relevante hits zoektermen of patronen die in die documenten voorkomen krijgen hoger gewicht bij toekomstige zoekacties krijgen documenten met die termen of patronen een hogere berekende relevantie bijv.: Autonomy Eric Sieverts | | |

92
metadata webtechnologie dublin core rdf semantic web
Eric Sieverts | | |

93
metadata en web-technologie
html opmaaktaal voor web-documenten maakt het mogelijk aan elk web-document (in browser niet getoonde) metadata mee te geven HTML-syntax: welke tag te gebruiken en welke attributen daarbij: <META NAME="...." CONTENT="...." LANG="...." SCHEME="...."> “name“ (veldnaam) "content“ (veldinhoud) "lang" (taal van de content) "scheme“ (toegepaste standaard voor de content) Eric Sieverts | | |
 metadata mee te geven. HTML-syntax: welke tag te gebruiken en welke attributen daarbij: <META NAME= .... CONTENT= .... LANG= .... SCHEME= .... > name (veldnaam) content (veldinhoud) lang (taal van de content) scheme (toegepaste standaard voor de content) Eric Sieverts | | |")
94
metadata en web-technologie
waarom metadata in web-pagina’s? betere vindbaarheid met zoekmachines (niet voor Google, wel voor andere of lokaal geconfigureerde) betere karakterisering in lijst met zoekresultaten via “description” (te gebruiken voor korte beschrijving) in principe ook mogelijkheid voor herkenning van aard, status, belang, "kind-veiligheid", etc. van webpagina (in praktijk niet echt van de grond gekomen) mogelijk alternatief voor echt “catalogiseren” van digitaal materiaal Eric Sieverts | | |
 betere karakterisering in lijst met zoekresultaten via description (te gebruiken voor korte beschrijving) in principe ook mogelijkheid voor herkenning van aard, status, belang, kind-veiligheid , etc. van webpagina (in praktijk niet echt van de grond gekomen) mogelijk alternatief voor echt catalogiseren van digitaal materiaal. Eric Sieverts | | |")
95
metadata en web-technologie
probleem met metadata in web-pagina’s: voor het web als geheel is geen enkele vorm van standaardisatie voorgeschreven oplossing: laat specifieke gebruikersgroepen vrijwillig standaardiseren bibliotheek- & informatiewereld: “dublin core” (en zelfs buiten echte bibliotheekwereld geadopteerd) Eric Sieverts | | |
 Eric Sieverts | | |")
96
dublin core metadata syntax & semantiek van "properties" (name-attribuut) afspraken over gebruik van "Dublin Core" ( ) met 15 "velden" voor formele en inhoudelijke elementen inhoudelijk (onderwerp) formeel (inhoud) formeel (intellectueel eigendom) formeel (fysieke weergave) title source creator date subject language publisher type description relation contributor format coverage rights identifier intussen ook nog 3 aanvullingen: audience, provenance, rightsHolder voorbeelden: <META NAME="DC.Creator" CONTENT="Eric Sieverts"> <META NAME="DC.Subject" CONTENT="metadata"> <META NAME="DC.Type" CONTENT="text/html"> Eric Sieverts | | |
 formeel (inhoud) formeel (intellectueel eigendom) formeel (fysieke weergave) title. source. creator. date. subject. language. publisher. type. description. relation. contributor. format. coverage. rights. identifier. intussen ook nog 3 aanvullingen: audience, provenance, rightsHolder. voorbeelden: <META NAME= DC.Creator CONTENT= Eric Sieverts > <META NAME= DC.Subject CONTENT= metadata > <META NAME= DC.Type CONTENT= text/html > Eric Sieverts | | |")
97
dublin core metadata - verfijningen
verfijningen van syntax en semantiek van "properties": via qualificaties/"element refinements" van Dublin Core bij "coverage": specificatie of het plaats- of tijd-aanduiding is <META NAME="DC.Coverage.Spatial" CONTENT="Frankrijk"> <META NAME="DC.Coverage.Temporal" CONTENT="1914"> bij "relation": specificatie van aard van relatie tussen bij elkaar horende webpagina's (of andere objecten) <META NAME="DC.Relation.IsPartOf" CONTENT="......"> <META NAME="DC.Relation.HasPart" CONTENT="......"> <META NAME="DC.Relation.IsVersionOf" CONTENT="......"> <META NAME="DC.Relation.HasVersion" CONTENT="......"> Eric Sieverts | | |
 <META NAME= DC.Relation.IsPartOf CONTENT= > <META NAME= DC.Relation.HasPart CONTENT= > <META NAME= DC.Relation.IsVersionOf CONTENT= > <META NAME= DC.Relation.HasVersion CONTENT= > Eric Sieverts | | |")
98
dublin core metadata - inhoud
voor semantiek van metadata-inhoud: geen standaardisatie opgelegd wel gebruikte standaard in "scheme"-attribuut opgeven voorbeelden <META NAME="DC.Date" CONTENT=" " SCHEME="ISO8601"> <META NAME="DC.Subject" CONTENT="hay fever" SCHEME="MeSH"> <META NAME="DC.Language" CONTENT="nl" SCHEME="ISO639-1"> <META NAME="DC.Source" CONTENT=" " SCHEME="ISBN"> Eric Sieverts | | |

99
dublin core in bibliotheek-omgeving
in digitale bibliotheekomgeving streeft men vrijwillig (!) naar toepassing van DC-standaardisatie toepassing vooral bedoeld voor compatibiliteit en uitwisseling in beperkte kring, of zelfs alleen maar voor lokaal gebruik DC wordt zelfs regelmatig toegepast zonder dat het direct om web-pagina's gaat (bijv. Open Archive Initiative; zie OAIster) DC is veel eenvoudiger dan "echte" bibliotheek-standaarden (MARC, ISBD, ...) [maar er zijn wel mappings met MARC] "element refinements" vaak aangepast aan lokale wensen gebruik van verschillende standaarden naast elkaar mogelijk rdf (resource description framework) is algemeen formalisme dat zelfs geheel daarop gericht is Eric Sieverts | | |
 naar toepassing van DC-standaardisatie. toepassing vooral bedoeld voor compatibiliteit en uitwisseling in beperkte kring, of zelfs alleen maar voor lokaal gebruik. DC wordt zelfs regelmatig toegepast zonder dat het direct om web-pagina s gaat (bijv. Open Archive Initiative; zie OAIster) DC is veel eenvoudiger dan echte bibliotheek-standaarden (MARC, ISBD, ...) [maar er zijn wel mappings met MARC] element refinements vaak aangepast aan lokale wensen. gebruik van verschillende standaarden naast elkaar mogelijk. rdf (resource description framework) is algemeen formalisme dat zelfs geheel daarop gericht is. Eric Sieverts | | |")
100
Resource Description Framework
RDF is gespecificeerd voor (vooral) XML-omgeving om betekenis/semantiek aan documenten te kunnen toevoegen XML-tags (gedefinieerd via dtd of schema) kunnen al betekenis geven aan onderdelen van document-inhoud zelf RDF maakt dat op meer gestandaardiseerde en beter georganiseerde wijze betekenis kan worden meegegeven Eric Sieverts | | |
 XML-omgeving om betekenis/semantiek aan documenten te kunnen toevoegen. XML-tags (gedefinieerd via dtd of schema) kunnen al betekenis geven aan onderdelen van document-inhoud zelf. RDF maakt dat op meer gestandaardiseerde en beter georganiseerde wijze betekenis kan worden meegegeven. Eric Sieverts | | |")
101
Resource Description Framework
RDF definieert een infrastructuur om zulke semantiek gestandaardiseerd te definiëren waarbij documenten zelf-verklarend worden zodanig dat computers hun betekenis kunnen afleiden waarbij verwezen wordt naar computerleesbare beschrijvingen van de semantiek en de standaarden die ze gebruiken zodat samenwerking en (her)gebruik van elders ontwikkelde standaarden mogelijk wordt Eric Sieverts | | |
gebruik van elders ontwikkelde standaarden mogelijk wordt. Eric Sieverts | | |")
102
het rdf-model bedoeld voor beschrijven van bronnen (resources / objecten) die identificeerbaar zijn via een uniform resource identifier (URI) middels eigenschappen (property-types / attributen) die een waarde (value) kunnen hebben property-types definiëren relaties tussen values en resources voorbeeld: "Jan is de auteur van document1" 1. document1 is als resource gedefinieerd via een URI (bijv. een URL) document1 heeft een property-type "auteur" die property-type heeft de waarde "Jan" dus eigenlijk: document1 heeft als auteur Jan Eric Sieverts | | |
 die een waarde (value) kunnen hebben. property-types definiëren relaties tussen values en resources. voorbeeld: Jan is de auteur van document1 1. document1 is als resource gedefinieerd via een URI (bijv. een URL) document1 heeft een property-type auteur die property-type heeft de waarde Jan dus eigenlijk: document1 heeft als auteur Jan. Eric Sieverts | | |")
103
het rdf-model een "value" hoeft niet alleen een woord of getal te zijn
(zoals "Jan"), maar mag zelf ook weer "resource" wezen 1. ook "Jan" moet dan als resource gedefinieerd zijn 2. ook "Jan" kan dan weer een aantal property-types hebben (bijv. naam, mailadres, instituut, ....) 3. ook die property-types kunnen weer waarden hebben Eric Sieverts | | |
, maar mag zelf ook weer resource wezen. 1. ook Jan moet dan als resource gedefinieerd zijn. 2. ook Jan kan dan weer een aantal property-types hebben (bijv. naam, mailadres, instituut, ....) 3. ook die property-types kunnen weer waarden hebben. Eric Sieverts | | |")
104
het rdf-model dat wordt in rdf-syntax dan iets ingewikkelds als:
<rdf:RDF xmlns:rdf=" xmlns=" <rdf:Description rdf:about=" <author> <rdf:Description rdf:about=" <name>John Smith</name> <affiliation>Home Inc.</affiliation> </rdf:Description> </author> </rdf:RDF> xml namespace verwijzingen, o.a. naar definitie voor RDF rdf:description wordt gebruikt voor identificatie van de resources (kan ook verwijzen naar html-document) en daarbinnen de elementen Eric Sieverts | | |
 en daarbinnen de elementen. Eric Sieverts | | |")
105
het rdf-model dublin core metadata worden in rdf-syntax iets als:
<rdf:RDF xmlns:rdf=" xmlns:dc=" <rdf:Description rdf:about=" <dc:title>Minicursus RDF</dc:title> <dc:description>In dit document wordt uitgelegd hoe rdf werkt </dc:description> <dc:date> </dc:date> <dc:format>text/ppt</dc:format> <dc:language>nl</dc:language> <dc:publisher>HvA - MIM</dc:publisher> <dc:contributor>Eric Sieverts</dc:contributor> </rdf:Description> </rdf:RDF> Eric Sieverts | | |

106
rdf en namespaces RDF is bedoeld om bestaande, elders ontwikkelde, semantische systemen te kunnen (her)gebruiken via de vermelde zogenaamde “namespaces” kunnen die worden geïdentificeerd (en zijn ze via een URL vindbaar) een namespace is dus een “web-verwijzing” naar een te gebruiken semantiek dat maakt modulariteit mogelijk, zodat je tegelijk meer, elkaar aanvullende systemen kunt gebruiken bijv.: "Dublin Core" (DC) naast "Learning Object Metadata" (LOM) dat maakt hergebruik eenvoudig en aantrekkelijk, want in je eigen dtd/schema hoef je geen metadata meer op te nemen als elders al een geschikte beschrijving bestaat Eric Sieverts | | |
 een namespace is dus een web-verwijzing naar een te gebruiken semantiek. dat maakt modulariteit mogelijk, zodat je tegelijk meer, elkaar aanvullende systemen kunt gebruiken. bijv.: Dublin Core (DC) naast Learning Object Metadata (LOM) dat maakt hergebruik eenvoudig en aantrekkelijk, want in je eigen dtd/schema hoef je geen metadata meer op te nemen als elders al een geschikte beschrijving bestaat. Eric Sieverts | | |")
107
rdf en semantisch web rdf is ook de basis voor het idee van een semantisch web daarbij gaat het er echter om ook echt - computer-herkenbaar - betekenis te kunnen toekennen aan gebruikt vocabulair in metadata Eric Sieverts | | |

108
Semantic Web LayerCake (Berners-Lee, 99;Swartz-Hendler, 2001)
door W3C gespecificeerd meer-lagen model voor semantisch web waarin aan informatie automatisch betekenis kan worden toegekend Semantic Web LayerCake (Berners-Lee, 99;Swartz-Hendler, 2001)
")
109
rdf en semantisch web W3C's meer-lagen model voor semantisch web
in DTD is bijv. wel een tag <product> gedefinieerd, maar hoe weten anderen (of een computer) dat, en hoe weten die wat dat betekent? xml, dtd’s, namespaces betekenis van xml-tags alleen op lokaal niveau bekend ascii, unicode, url, .. technische basisstructuren Eric Sieverts | | |
 dat, en hoe weten die wat dat betekent xml, dtd’s, namespaces. betekenis van xml-tags alleen. op lokaal niveau bekend. ascii, unicode, url, .. technische basisstructuren. Eric Sieverts | | |")
110
zo ziet een web-pagina in natuurlijke taal
er voor een machine uit

111
met XML kun je “betekenisvolle tags” aan stukken
van de tekst toevoegen < > < > < > < > < > CV name education work private

112
maar XML is nog geen computer-toegankelijke betekenis; voor een machine zien die tags er ook gewoon uit als: .... < CV > < name > <education> <work> <private> < > < > < > < > < > CV name education work private

113
rdf, rdf-schema’s (dc, …)
rdf en semantisch web W3C's meer-lagen model voor semantisch web met rdf zijn documenten wel zelf-verklarend en weten anderen (ook computers) hoe metadata-schema in elkaar zit en wat tags betekenen, maar nog altijd niet wat de inhoud betekent rdf, rdf-schema’s (dc, …) metadata-formalismen wel bekend, maar geen betekenis xml, dtd’s, namespaces betekenis van xml-tags alleen op lokaal niveau bekend ascii, unicode, url, .. technische basisstructuren Eric Sieverts | | |
 hoe metadata-schema in elkaar zit en wat tags betekenen, maar nog altijd niet wat de inhoud betekent. rdf, rdf-schema’s (dc, …) metadata-formalismen wel. bekend, maar geen betekenis. xml, dtd’s, namespaces. betekenis van xml-tags alleen. op lokaal niveau bekend. ascii, unicode, url, .. technische basisstructuren. Eric Sieverts | | |")
114
rdf, rdf-schema’s (dc, …)
rdf en semantisch web W3C's meer-lagen model voor semantisch web ontologieën betekenis toekennen aan vocabulair op door computer interpreteerbare wijze rdf, rdf-schema’s (dc, …) metadata-formalismen wel bekend, maar geen betekenis xml, dtd’s, namespaces betekenis van xml-tags alleen op lokaal niveau bekend ascii, unicode, url, .. technische basisstructuren Eric Sieverts | | |
 metadata-formalismen wel. bekend, maar geen betekenis. xml, dtd’s, namespaces. betekenis van xml-tags alleen. op lokaal niveau bekend. ascii, unicode, url, .. technische basisstructuren. Eric Sieverts | | |")
115
ontologieën en semantisch web
wat betekenen “ontologieën” hier ? begrip oorspronkelijk afkomstig uit de filosofie en daarna ook uit de wereld van de kunstmatige intelligentie: in ontologie wordt kennis van (een stukje van) de wereld vastgelegd het dient als "kennis-representatie" wordt in semantisch web-wereld zeer ruim opgevat: in het algemeen aanduiding voor allerlei soorten ontsluitings-systemen wel essentieel: ontologie moet computerleesbaar, -interpreteerbaar en -verwerkbaar beschikbaar zijn (er zijn dus formele beschrijvingstalen voor nodig) Eric Sieverts | | |
 de wereld vastgelegd. het dient als kennis-representatie wordt in semantisch web-wereld zeer ruim opgevat: in het algemeen aanduiding voor allerlei soorten ontsluitings-systemen. wel essentieel: ontologie moet computerleesbaar, -interpreteerbaar en -verwerkbaar beschikbaar zijn. (er zijn dus formele beschrijvingstalen voor nodig) Eric Sieverts | | |")
116
ontologieën en semantisch web
hoe maakt men dat ontologieën computer-interpreteerbaar zijn ? daarvoor worden op dit moment standaarden en beschrijvingstalen ontwikkeld; bijvoorbeeld: OWL web ontology language ( belangrijk ook: mappings/concordanties tussen kennis-representaties Eric Sieverts | | |

117
ontologieën en semantisch web
voorbeelden van ontologieën: in kunst-documentatiesysteem vanuit één systeem namespace-verwijzingen naar: Art & Architecture Thesaurus (thesaurus) IconClass (beeld-classificatie) WordNet (semantisch netwerk) Union List of Artist Names (authority list) AAT Wordnet equivalenties (concordantie) Dublin Core voor annotaties (metadata-systeem) uiteindelijk doel: met betere precisie en recall kunnen zoeken naar (afbeeldingen en/of beschrijvingen van) kunstwerken Eric Sieverts | | |
 IconClass (beeld-classificatie) WordNet (semantisch netwerk) Union List of Artist Names (authority list) AAT Wordnet equivalenties (concordantie) Dublin Core voor annotaties (metadata-systeem) uiteindelijk doel: met betere precisie en recall kunnen zoeken naar. (afbeeldingen en/of beschrijvingen van) kunstwerken. Eric Sieverts | | |")
119
annotating with a concept : term disambiguation

120
typisch semantisch web voorbeeld: zoeken naar plaatje
© Guus Schreiber UvA / VU A person searches for photos of an “orange ape” An image collection of animal photographs contains snapshots of orang-utans. The search engine finds the photos, despite the fact that the words “orange” and “ape” do not appear in annotations Eric Sieverts | | |

121
rdf annotatie van een web-bron
© Guus Schreiber UvA / VU Eric Sieverts | | |

122
semantische annotatie

123
de "species ontology" © Guus Schreiber UvA / VU
Eric Sieverts | | |

124
Semantic Web Principles
Everything is on the web People, places, times, things all have URIs Partial information is assumed The web privileges scalability over integrity and there’s always more and new stuff to find Trust models are critical It’s not all true Creating a critical mass of semantic content In the end, this will be the critical success factor Minimalist design Make the simple things simple, and the complex things possible. Standardize no more than is necessary. Common data model To support interoperability and knowledge sharing Adapted from Eric Miller, W3C

125
wat moet er verder nog gebeuren?
W3C's meer-lagen model voor semantisch web lagen hierboven, die uiteindelijk tot betrouwbaarheid van de zo gepresenteerde informatie en kennis moeten leiden, moeten in de toekomst nog ontwikkeld worden ontologieën betekenis toekennen aan vocabulair op door computer interpreteerbare wijze rdf, rdf-schema’s (dc, …) metadata-formalismen wel bekend, maar geen betekenis xml, dtd’s, namespaces betekenis van xml-tags alleen op lokaal niveau bekend ascii, unicode, url, .. technische basisstructuren Eric Sieverts | | |
 metadata-formalismen wel. bekend, maar geen betekenis. xml, dtd’s, namespaces. betekenis van xml-tags alleen. op lokaal niveau bekend. ascii, unicode, url, .. technische basisstructuren. Eric Sieverts | | |")
126
Moving to the future of the web
Semantic Web LayerCake (Berners-Lee, 99;Swartz-Hendler, 2001)
")
Verwante presentaties






 • Gebruikt.>")


 Marc de Graauw 20001 Presentatie XML Marc de Graauw 2 maart 2000.>")



 Module 4 College “Big Picture” Universiteitsbibliotheek UM 2002, 10 juni.>")








