Download de presentatie
De presentatie wordt gedownload. Even geduld aub

1
Gegevensbanken Fundamenten van geheugen; Bestandsorganisatie; Hashing Bettina Berendt

2
Fundamenten van geheugen; Bestandsorganisatie; Hashing: Motivatie & Samenvatting

3
Waar zijn we? Les # wie wat 1 ED intro, ER
2 ED EER, (E)ER naar relationeel schema 2 ED relationeel model 3 KV Relationele algebra & relationeel calculus 4,5 KV SQL 6 KV Programma's verbinden met gegevensbanken 7 KV Functionele afhankelijkheden & normalisatie 8 KV PHP 9 BB Beveiliging van gegevensbanken 10 BB Geheugen en bestandsorganisatie 11 BB Externe hashing 12 BB Indexstructuren 13 BB Queryverwerking 14,15 BB Transactieverwerking en concurrentiecontrole 16 BB Data mining en data warehousing 17 ED XML, NoSQL Fysisch model / vragen Efficientie en veiligheid zijn niet-functionele vereisten (HOE doet een systeem iets) vs. Functionele vereisten (WAT doet een systeem)
ER naar relationeel schema. 2 ED relationeel model. 3 KV Relationele algebra & relationeel calculus. 4,5 KV SQL. 6 KV Programma s verbinden met gegevensbanken. 7 KV Functionele afhankelijkheden & normalisatie. 8 KV PHP. 9 BB Beveiliging van gegevensbanken. 10 BB Geheugen en bestandsorganisatie. 11 BB Externe hashing. 12 BB Indexstructuren. 13 BB Queryverwerking. 14,15 BB Transactieverwerking en concurrentiecontrole. 16 BB Data mining en data warehousing. 17 ED XML, NoSQL. Fysisch model / vragen. Efficientie en veiligheid zijn niet-functionele vereisten (HOE doet een systeem iets) vs. Functionele vereisten (WAT doet een systeem)")
4
Is nu alles meteen overal?
Hoe ver moet je lopen? Is nu alles meteen overal? 127 km L <-> K

5
Hedendagse archiven: Alles kan per Internet met 1 click …

6
… maar achter het scherm …
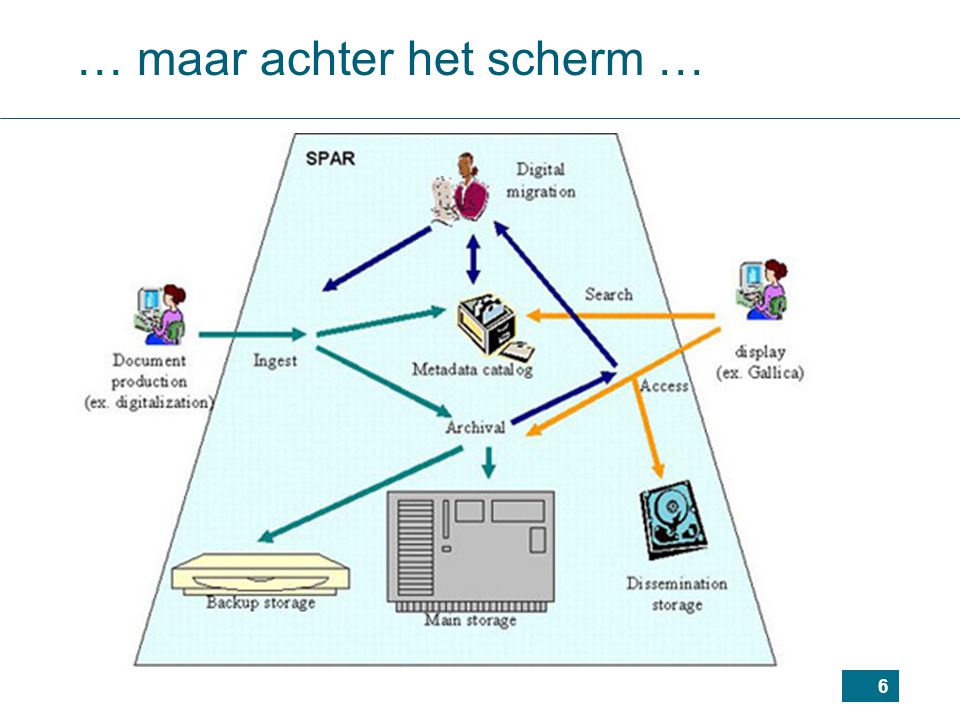
7
... en daarachter … Bv. Project Système de Préservation et d'Archivage Réparti (Bibliothèque Nationale de France): Verwacht: 200 Terabyte (toegangsgeheugen), Petabyte (hoofd-archief-geheugen) Schijven, banden, banden-robots: Internet Archive:
, 8 Petabyte (hoofd-archief-geheugen) Schijven, banden, banden-robots: Internet Archive:")
8
Hoe ver moet je lopen? (2)
127 km L <-> K

9
Waarom? 3 principes voor database design
Ruimtelijke organisatie is belangrijk, of: We kunnen niet aan de fysica ontsnappen Wat nodig is, is afhankelijk van wat je ermee wilt doen Omgaan met beperkingen: “... Ik weet op dit moment niet waar het is, maar ik heb dat thuis opgeschreven ...”

10
Agenda Geheugens Bestandsorganisatie: blokken en records
Toegang tot en bewerkingen op bestanden Soorten bestanden Hashing – basisidee

11
Agenda Geheugens Bestandsorganisatie: blokken en records
Toegang tot en bewerkingen op bestanden Soorten bestanden Hashing – basisidee

12
Geheugenhiërarchieën
ge- heugen niveau kost volati- liteit snel- heid capa- citeit Wat gebeurt hier? Primair Cache memory / static RAM Verwerking Hoofdgeheugen / dynamic RAM Flash memory Secun- dair Magnetische schijven Opslag Backup; Archie- veren Tertiair Optisch (CD, DVD) Magnetische banden
 Magnetische banden.")
13
Meest belangrijk voor gegevensbanken …

14
Schijf, cilinder, spoor schijven- pakket

15
Spoor en blok Blok : onderdeel van een spoor (“track“)
gefixeerd tijdens initialisatie Spoor : gefixeerd in de hardware

16
Hoe een gege-ven vinden?
3. Blok 2. Spoor 1. Cilinder

17
Verwerking & opslag: het knelpunt
Buffer adres in het hoofdgeheugen lezen Hardware adres op schijf: Cilinder#, spoor#, blok# schrijven localiseren Fysische locatie op de schijf Processorgeheugenknelpunt: Jaarlijks worden processoren gemiddeld 60% sneller, terwijl de toegangstijd tot het geheugen maar daalt met een 7% per jaar. Deze kloof wordt dus steeds groter en steeds knellender. Hoofdknelpunt voor database toepassingen: gegevens op schijven localiseren ! TODO: check the numbers! Terugvinden ist mehr „recovery“ Cijfers uit: 27 maart 2012

18
Parameters m.b.t. performantie
Relevante tijden: juiste cilinder zoeken : seek time (vb.: 4-10 msec) kop mechanisch bewegen : traag juiste blok zoeken: rotational delay ("latency") (vb.: 3 msec) schijf moet doordraaien tot blok onder leeskop staat gegevenstransport : block transfer rate (vb.: 50 Mbytes/sec) gegevens in blok lezen en naar buffer kopiëren Deze tijden >> verwerkingstijd van gegevens Bestanden zo structureren dat deze tijden geminimaliseerd worden! bv. opeenvolgende blokken lezen : slechts één keer seek time & latency
 kop mechanisch bewegen : traag. juiste blok zoeken: rotational delay ( latency ) (vb.: 3 msec) schijf moet doordraaien tot blok onder leeskop staat. gegevenstransport : block transfer rate (vb.: 50 Mbytes/sec) gegevens in blok lezen en naar buffer kopiëren. Deze tijden >> verwerkingstijd van gegevens. Bestanden zo structureren dat deze tijden geminimaliseerd worden! bv. opeenvolgende blokken lezen : slechts één keer seek time & latency.")
19
Buffering Bij lezen / schrijven van opeenvolgende blokken: gebruik van meerdere ("alternerende") buffers bv. bij lezen: info in een buffer verwerken terwijl andere buffer gevuld wordt verwerking meestal klaar voor volgende buffer vol is blok 1 blok 2 blok 3 blok 4 vul A vul B vul A vul B blok 1 blok 2 blok 3 blok 4 Meestal: book: it IS the case; reality: can be different ( Ruckeln im Video) verwerk A verwerk B verwerk A verwerk B tijd
 verwerk A. verwerk B. verwerk A. verwerk B. tijd.")
20
Organisatie en toegang – voorbeeld/vraag
Waar kunnen we hoe snel beantwoorden: Wie kwam laatst? Is Victor Konen hier?

21
Gegevens & verwerking: organisatie vs. toegang
Onderscheid: Bestandsorganisatie file organization organisatie van bestand in records, blokken, toegangsstructuren + verdeling van de records over het hulpgeheugen (= sec./tert. geheugen) Toegangsmethode access method groep operaties / programma’s die toelaten om het bestand te bewerken Niet elke toegangsmethode mogelijk voor eender welke bestandsorganisatie Naargelang van organisatie ook verschil in efficiëntie Stack photo!
 Toegangsmethode access method. groep operaties / programma’s die toelaten om het bestand te bewerken. Niet elke toegangsmethode mogelijk voor eender welke bestandsorganisatie. Naargelang van organisatie ook verschil in efficiëntie. Stack photo!")
22
Agenda Geheugens Bestandsorganisatie: blokken en records
Toegang tot en bewerkingen op bestanden Soorten bestanden Hashing – basisidee

23
Formaat van records Record = bij elkaar horende groep gegevens
"eenheid" van informatie Recordlengte: vast : alle records zelfde lengte variabel : verschillende records kunnen verschillende lengtes hebben mogelijke redenen: veld(en) van variabele lengte velden(en) met meerdere waarden ("repeating groups") optionele velden verschillende recordtypes (gemengd bestand) vereist: scheidingstekens tussen velden indicatie van type veld
 van variabele lengte. velden(en) met meerdere waarden ( repeating groups ) optionele velden. verschillende recordtypes (gemengd bestand) vereist: scheidingstekens tussen velden. indicatie van type veld.")
24
Formaat: voor-beelden

25
Records in blokken plaatsen (1)
Waarom? Blok: blok is de entiteit voor plaatsgebruik op schijf gegevenstransport tussen schijf en geheugen Hoe? Plaatsing van records: "unspanned" : 1 record steeds volledig binnen 1 blok overschot aan einde van blok gaat verloren vooral nuttig voor korte records met vaste lengte weinig verloren ruimte records beginnen op vaste posities in blok "spanned" - overspannend: record kan over meerdere blokken uitgespreid zijn noodzakelijk indien een record langer dan een blok kan zijn minder verloren ruimte ingewikkelder organisatie

26
Records in blokken plaatsen (2)
")
27
Hoeveel blokken zijn nodig voor een bestand van records?
Karakteristieken van records en blokken bloklengte: B (bytes) recordlengte: R (bytes) Unspanned als B > R : blocking factor bfr : # records / blok = B / R als B geen veelvoud van R is: aan het einde van een blok B - ( bfr * R ) vrije bytes Spanned (bij variable lengte) bfr : gemiddelde nr. van records/blok Gewoon geen vrije bytes aan het einde van een blok Overal nodig: r : # records in bestand b = (r / bfr) blokken Ginge interaktiv, ist aber so‘n bisschen pillepalle
 recordlengte: R (bytes) Unspanned. als B > R : blocking factor bfr : # records / blok = B / R als B geen veelvoud van R is: aan het einde van een blok B - ( bfr * R ) vrije bytes. Spanned. (bij variable lengte) bfr : gemiddelde nr. van records/blok. Gewoon geen vrije bytes aan het einde van een blok. Overal nodig: r : # records in bestand. b = (r / bfr) blokken. Ginge interaktiv, ist aber so‘n bisschen pillepalle.")
28
Taak Een bestand heeft r = EMPLOYEE records van vaste lengte. Elk record heeft de volgende velden: Name (30 bytes), Ssn (9 bytes), Department_code (9 bytes), Address (40 bytes), Phone (9 bytes), Birth_date (8 bytes), Gender (1 byte), Job_code (4 bytes), Salary (4 bytes). Een extra byte wordt gebruikt als deletion marker (markering voor het wissen). De gegevens worden opgeslaan op een schijf met bloklengte B = 512 bytes, blokwijzerlengte P = 6 bytes en recordwijzerlengte PR = 7 bytes. Veronderstel een unspanned recordorganisatie, en bereken de recordlengte R in bytes = 115 de blocking factor bfr = 4 het aantal van blokken b = het aantal van schijftoegangen (= hoeveel blokken worden gelezen) bij het zoeken bij Ssn = 5000 (gemiddeld) / gesorteerd log_ = 14
, Ssn (9 bytes), Department_code (9 bytes), Address (40 bytes), Phone (9 bytes), Birth_date (8 bytes), Gender (1 byte), Job_code (4 bytes), Salary (4 bytes). Een extra byte wordt gebruikt als deletion marker (markering voor het wissen). De gegevens worden opgeslaan op een schijf met bloklengte B = 512 bytes, blokwijzerlengte P = 6 bytes en recordwijzerlengte PR = 7 bytes. Veronderstel een unspanned recordorganisatie, en bereken. de recordlengte R in bytes = 115. de blocking factor bfr = 4. het aantal van blokken b = het aantal van schijftoegangen (= hoeveel blokken worden gelezen) bij het zoeken bij Ssn = 5000 (gemiddeld) / gesorteerd log_ = 14.")
29
+ - + - Plaatsing van logisch opeenvolgende blokken (1) Aaneensluitend
Opeenvolgende blokken fysisch aaneensluitend = "contiguous allocation" bestand overlopen (bv. meerdere blokken lezen) gaat snel (met 2 buffers) tussenvoegen van blokken is moeilijk Geketend "linked allocation" elk blok bevat wijzer naar volgend blok uitbreiden van bestand gaat gemakkelijker gehele bestand overlopen gaat trager + - + Overlopen = scan -
 gaat snel (met 2 buffers) tussenvoegen van blokken is moeilijk. Geketend. linked allocation elk blok bevat wijzer naar volgend blok. uitbreiden van bestand gaat gemakkelijker. gehele bestand overlopen gaat trager Overlopen = scan. -")
30
Plaatsing van logisch opeenvolgende blokken (2)
Combinatie: Clusters van aaneensluitende blokken ook wel "file segments" genoemd Elke cluster bevat wijzer naar volgende cluster Indexering: "indexed allocation" een of meer indexblokken : bevatten enkel wijzers naar de blokken met de echte gegevens Combinaties mogelijk

31
Agenda Geheugens Bestandsorganisatie: blokken en records
Toegang tot en bewerkingen op bestanden Soorten bestanden Hashing – basisidee

32
Bewerkingen op bestanden
2 groepen bewerkingen: Opvragen van gegevens (zonder aanpassing) enkel lezen Aanpassen van gegevens lezen + schrijven nodig Selectie van records selectiecriterium aangeboden door besturingssysteem meestal zeer eenvoudig DBMS moet ingewikkeld criterium omzetten naar meerdere eenvoudige criteria SELECT * UPDATE EMP FROM EMP SET SALARY = WHERE (NAME LIKE “%BART%“ OR AGE > 30) SELECT * FROM EMP WHERE (NAME LIKE “%BART%“ OR AGE > 30)
 enkel lezen. Aanpassen van gegevens. lezen + schrijven nodig. Selectie van records. selectiecriterium aangeboden door besturingssysteem meestal zeer eenvoudig. DBMS moet ingewikkeld criterium omzetten naar meerdere eenvoudige criteria. SELECT * UPDATE EMP. FROM EMP SET SALARY = WHERE. (NAME LIKE %BART% OR AGE > 30) SELECT * FROM EMP. WHERE. (NAME LIKE %BART% OR AGE > 30)")
33
Typische operaties die een besturingssysteeem aanbiedt (1)
OPEN: maakt bestand klaar voor verwerking kent buffers toe, ... RESET: zet bestandswijzer naar begin bestand FIND (LOCATE): zoek eerste record dat aan criterium voldoet kopieer het blok dat dat record bevat naar de buffer zet bestandswijzer naar dat record (= "huidig" record) READ (GET): ken huidig record aan programmavariabele toe (soms) verplaats bestandswijzer evt. nieuw blok inlezen
: zoek eerste record dat aan criterium voldoet. kopieer het blok dat dat record bevat naar de buffer. zet bestandswijzer naar dat record (= huidig record) READ (GET): ken huidig record aan programmavariabele toe. (soms) verplaats bestandswijzer. evt. nieuw blok inlezen.")
34
Typische operaties die een besturingssysteeem aanbiedt (2)
FINDNEXT: zoek volgende record dat aan criterium voldoet, maak het het huidige record DELETE: wis huidig record (eerst in buffer, dan in bestand) MODIFY: wijzig huidig record (eerst in buffer, daarna naar bestand geschreven) INSERT: lees juiste blok in buffer in, voeg record aan dat blok toe (eerst in buffer, later in bestand) CLOSE: ruim buffers op, ... Soms gecombineerde bewerkingen SCAN : FIND of FINDNEXT + READ Set-at-a-time operaties, bv.: FINDORDERED
 MODIFY: wijzig huidig record (eerst in buffer, daarna naar bestand geschreven) INSERT: lees juiste blok in buffer in, voeg record aan dat blok toe (eerst in buffer, later in bestand) CLOSE: ruim buffers op, ... Soms gecombineerde bewerkingen. SCAN : FIND of FINDNEXT + READ. Set-at-a-time operaties, bv.: FINDORDERED.")
35
Belangrijke parameters m.b.t. bestandsverwerking
Bestandsactiviteit (file activity) # records dat gebruikt wordt door een toepassing / totaal # records van het bestand Bestandsveranderingsgraad (file volatility) # records dat in een bepaalde periode een verandering ondergaat / totaal # records van het bestand Bestandsverloop of vervangingsgraad (file turnover) # records dat in een bepaalde periode vervangen wordt door nieuwe records / totaal # records van het bestand Bestandsgroei (file growth) toename van # records gedurende een bepaalde periode / het oorspronkelijk totaal # records Mbt = met betrekking tot; ivm = in verband met; verhouding = relation; t.o.v. = ten opzichte van verhouding van # records dat gebruikt wordt door een toepassing t.o.v. totaal # records van het bestand Het totaal nummer
 # records dat gebruikt wordt door een toepassing / totaal # records van het bestand. Bestandsveranderingsgraad (file volatility) # records dat in een bepaalde periode een verandering ondergaat / totaal # records van het bestand. Bestandsverloop of vervangingsgraad (file turnover) # records dat in een bepaalde periode vervangen wordt door nieuwe records / totaal # records van het bestand. Bestandsgroei (file growth) toename van # records gedurende een bepaalde periode / het oorspronkelijk totaal # records. Mbt = met betrekking tot; ivm = in verband met; verhouding = relation; t.o.v. = ten opzichte van. verhouding van # records dat gebruikt wordt door een toepassing t.o.v. totaal # records van het bestand. Het totaal nummer.")
36
Agenda Geheugens Bestandsorganisatie: blokken en records
Toegang tot en bewerkingen op bestanden Soorten bestanden Hashing – basisidee Step 4.2 Choose file organizations To determine an efficient file organization for each base table. File organizations include Heap, Hash, Indexed Sequential Access Method (ISAM), B+-Tree, and Clusters. Some DBMSs (particularly PC-based DBMS) have fixed file organization that you cannot alter. Example of what can be configured + how:
, B+-Tree, and Clusters. Some DBMSs (particularly PC-based DBMS) have fixed file organization that you cannot alter. Example of what can be configured + how:")
37
3 soorten bestanden Ongeordend Geordend Hashed
NB: Deze informatie staat in de file header, samen met: Informatie om schijfadressen van blokken te bepalen Formaatinformatie (veldlengtes, -volgorde, scheidingstekens, …) Recordorganisatie (spanned/unspanned)…
 Recordorganisatie (spanned/unspanned)…")
38
Ongeordende bestanden: idee

39
+ - - Ongeordende bestanden: operaties Toevoegen: Opzoeken: Weglaten:
achteraan in laatste blok Opzoeken: volledig bestand lineair doorzoeken Weglaten: record zoeken ( blok) record weglaten in buffer (evt. markeren zonder te wissen), buffer in blok terugschrijven na veel weglatingen veel verloren ruimte reorganisatie Gebruik: Meestal slechts als voorlopig bestand op een gegeven moment : “extern sorteren” geordend bestand - -
 record weglaten in buffer (evt. markeren zonder te wissen), buffer in blok terugschrijven. na veel weglatingen veel verloren ruimte reorganisatie. Gebruik: Meestal slechts als voorlopig bestand. op een gegeven moment : extern sorteren geordend bestand. - -")
40
Omwille van de nadelen bij opzoeken en weglaten ...
na veel weglatingen veel verloren ruimte reorganisatie Gebruik van ongeordende bestanden: Meestal slechts als voorlopig bestand op een gegeven moment : “extern sorteren” geordend bestand

41
Geordende bestanden: idee
Kitchen%2C_Drawers_%283%29.jpg/180px-Frankfurt- Kitchen%2C_Drawers_%283%29.jpg

42
+ + + Geordende bestanden: eigenschappen en operaties (1)
Geordend volgens sleutelveld Voordelen: lezen van records in sleutelvolgorde : zeer efficiënt binair zoeken mogelijk aanpassen in sleutelvolgorde gaat snel + + +

43
Geordende bestanden: voorbeeld
Geordend volgens sleutelveld

44
Geordende bestanden: binair zoeken
Alfred, Bob ? l := 1; u := b; {b = aantal blokken} verderzoeken := true; gevonden := false; zolang u >= l en verderzoeken : i := (l+u) div 2; lees blok i in buffer; als k < sleutel van eerste record in buffer dan u := i-1 anders als k > sleutel laatste record in buffer dan l := i+1 anders als record met sleutel k in buffer dan verderzoeken := false; gevonden := true; anders verderzoeken := false .
 div 2; lees blok i in buffer; als k < sleutel van eerste record in buffer dan. u := i-1. anders als k > sleutel laatste record in buffer dan l := i+1. anders als record met sleutel k in buffer dan. verderzoeken := false; gevonden := true; anders verderzoeken := false. .")
45
Zoeken

46
- - - - Geordende bestanden: operaties (2)
zoeken op een ander veld dan sleutel blijft tijdrovend toevoegen vereist verplaatsing van records weglaten vereist ook verplaatsing van records, behalve met markering aanpassen van records traag indien die niet in sleutelvolgorde worden aangeboden - - -

47
Hashed bestanden: idee
De rode? De rode!

48
Hashing-bestandsorganisatie
Methode om uit recordsleutel meteen recordadres in bestand te vinden: hashing Principe van hashing: hash-functie beeldt waarde k (getal, string, ...) af op adres f(k) goede hashfunctie "spreidt" waarden zoveel mogelijk over verschillende adressen botsing ("collision") : f(k1) = f(k2) met k1 k2 Interne hashing: gegevens en hashfunctie zijn in centraal geheugen voorgesteld Externe hashing: gegevens (evt. ook hashfunctie zelf) opgeslagen in een bestand
 af op adres f(k) goede hashfunctie spreidt waarden zoveel mogelijk over verschillende adressen. botsing ( collision ) : f(k1) = f(k2) met k1 k2. Interne hashing: gegevens en hashfunctie zijn in centraal geheugen voorgesteld. Externe hashing: gegevens (evt. ook hashfunctie zelf) opgeslagen in een bestand.")
49
Hashing: idee x-HASHTB12.svg.png

50
Voor- en nadelen van de bestandssoorten (tabel nog niet volledig afgewerkt!)
toevoegen Opzoeken weglaten doorlopen en/of aanpassen sleutelVO Zoeken en/of aanpassen niet- sleutelVO INSERT FIND DELETE FINDOR- DERED s DERED ns Ongeordend + - - (afhank. v. blokken- plaatsing, aanwezig- heid van wismarkers) Geordend - (opschuiven!) - (zie toevoegen) + (als er geen verandering van recordlengte is) - (elke keer zoeken!!) hashed
 Geordend. - (opschuiven!) - (zie toevoegen) + (als er geen verandering van recordlengte is) - (elke keer zoeken!!) hashed.")
51
Vooruitblik Geheugens Bestandsorganisatie: blokken en records
Toegang tot en bewerkingen op bestanden Soorten bestanden Hashing – basisidee Meer over hashing, indexstructuren

52
Bronnen Deze slides zijn gebaseerd op Henk Olivié‘s slides voor Gegevensbanken 2009 en op Elmasri & Navathe, Fundamentals of Database Systems, Addison Wesley / Pearson, 5e editie 2007. De voorbeelden voor hashing komen uit andere presentaties, zie notities op slides Alle kopieën zonder bronspecificatie: Elmasri & Navathe, Fundamentals of Database Systems, Addison Wesley / Pearson, 5e editie 2007. Verdere figuren: bronnen zie “Powerpoint comments field” Alle overige fouten zijn de mijne ;-) Bedankt iedereen!
 Bedankt iedereen!")
Verwante presentaties



 23 januari 2013 Bodegraven.>")
>")












 Quiz Night !>")

